时代在发展,我们的知识,开发工具,以及相应的环境也随之进步,我们总是会趋向于向好的一面发展,期望我们自身能够更加优秀,更加高效,以及能够给周围的人带来更多的价值
那么在我们平日开发过程中,你们的开发模式,以及开发环境是如何演变的呢? 如下是我近一两年经历的变化,希望能给你们带来一些思考和收获
混沌之初还是主机环境
起初在接触 golang 之前还是在使用 C 语言在嵌入式板卡上进行开发,那个时候 U盘,串口,各种外设,板卡,桌面上应有尽有,开发和调试相对也是比较麻烦的
尤其是在将编译完毕之后的软件烧录到嵌入式板卡中时,会等待一定的时间,短则 10 几秒,长则几分钟不等,就在等待的这段时间,就能看到一些同事刷手机,刷着刷着就忘记了接下来要做的事情
开始做 golang 之后,每一个仓库的打包都是依赖于同一份 shell 脚本,大致流程是
- 拷贝相关配置到指定目录
- 拉取同名仓库的依赖,例如 proto 文件,proto 文件我们是放在了另外一个专门存放 proto 的仓库中
- 编译 proto
- 编辑项目程序
- 将可执行程序,以及相关配置文件做成 tar 包,并以时间命名再加上当时提交的的 commit 号前 8位
项目之初,各方面都还比较原始,优秀的框架也还没有人会

从 gitlab 上拿包转变成 cicd
前半年的开发模式都是自己在主机环境里面替换可执行程序
当然,这个可执行程序也是自己的开发机器上编译的,对于几个人同时开发同一个服务的时候,就会存在有人默默将自己本地可执行程序替换到开发环境上,导致影响他人,出现各种稀奇古怪的问题,排查一通,原来程序的版本都被换掉了

这段时间,如果是转测,我们是交付 tar 包
咱们开发就会从 gitlab 上拿 tar 包,给到测试人员,测试按照安装脚本来进行安装,然后查看日志无异常,则表示安装成功
慢慢的我们开始有了自己的流水线,但是交付的内容还是一个 tar 包,只不过,不需要开发将 tar 包发给测试了,而是测试自己去流水线上取包,安装即可
此处并没有给我们的整个流程带来多大的提效
开始使用 ansible 来进行提效
自然,我们上线的时候也能想象的到,对于每一个服务都是手动执行解压缩包,进入到安装目录,执行脚本安装服务
如果是一次升级涉及到多个服务,那么升级的成本那是相当大的,且如果升级出了问题,并没有立即回滚的机制,一般情况下会将问题排查出来,若无法得出结论,则会将上一次升级的包拿出来,再次升级一遍,结果就是升级失败了
那段时间,我们升级都是在晚上,顺利的话,也得凌晨升级完毕,若是出现异常的话,那么一晚上也就耗在这里了,非常的低效,有记录,有团队上线耗时 8小时,结果还失败了(如有雷同,纯属巧合)
经过多次的毒打,我们慢慢的开始思考提效,开始使用 ansible 去编写剧本
ansible 是一款 开源 IT 自动化 工具,能够自动执行置备、配置管理、应用部署、编排和许多其他手动 IT 流程
每次上线之前,都会编写好 ansible 剧本,在演练环境上进行演练后再上线
如果出现问题的话,仍然是使用 ansible 将上一个版本的升级包再重新升级一遍,达到回滚的效果
此处引入 ansible ,确实带来了极大的提效,但是还不够,对于回滚这一块,仍然是需要我们自己去准备每一个服务的上一个版本的包,以防万一

引入 k8s 将所有微服务全部容器化
使用 ansible 有一段时间了,认为整个环境仍然是不够爽的,还能不能更好一点,这样玩还是比较麻烦

慢慢的,我们演进到了 k8s,演进到 k8s 前提,不仅仅是得基本的 k8s 环境搭建完善,还需要做很多事情
k8s全称kubernetes,是为容器服务而生的一个可移植容器的编排管理工具
例如,简述一下我们的改造过程
-
需要能够一键搭建 k8s 集群环境
- 基本关于 k8s 中网络的部分全部要处理好
- 关于用到的数据库,缓存,消息队列,日志组件等等 都需要和这套 k8s 进行打通,去配置 k8s 的 coredns
- 以及关于学习和搭建 k8s 过程中遇到的所有问题都需要一一解决
-
需要对每个微服务仓库进行改造,加入对应的 Dockerfile
- 修改微服务源码,例如以前使用 etcd 做服务发现的地方,全部修改掉,换成直接使用 k8s 自身的服务发现机制
- 调整其他相关代码,让服务能够更好在 k8s 中运行
- 流水线上编译完毕之后,自动将微服务程序制作成对应的镜像文件,且按照提交分支,推到对应的制品仓库
- 这个时候,升级的话,还是要用 k8s 的 kubectl set image 的方式来进行升级,当然这个也是可以看到升级记录的
可是还不够爽,因为使用 kubectl set image 的方式,发现很多人刚接触 k8s 还是挺懵的,能不能有一个更加简单的工具来进行升级和回滚 k8s 中的微服务呢?😅
开始使用 helm
自然是有的,因此我们引入了 helm ,Helm 是 Kubernetes 的包管理器

引入了 helm 之后,同时对流水线进行改造,当做好微服务镜像之后,则开始做 helm 包,并且推到相应的制品库中
当然此处的改造也是需要去修改每一个微服务的仓库,需要加入 chart 相关的内容,不过多赘述了
那么对于我们开发的时候,就能够很简单,很轻易的就可以在环境上使用 helm 升级和回滚了
并且交付到测试的时候,也不用以前那么复杂了,只需要测试查看流水线版本,然后再测试的 k8s 集群中执行 helm upgrade 进行升级即可,若升级后 pod 不是 RUNING ,那么直接找开发查
将所有微服务容器化,且部署到 k8s 中,极大的简化了开发,测试,以及上线的成本,现在的上线过程相对以前可以说轻松太多了
现在只需要运维在线上根据升级文档执行 helm 命令升级即可,再也不需要繁琐的一个一个去解压和安装了
可是,这还是不够优雅,上线的时候,能不能做到不需要运维去手动敲命令?
必须可以,那就安排上,后来,我们再给线上环境升级中,也加入了流水线,运维上线,直接点流水线发布即可,若出现了异常,点击回滚即可,不要太方便
k8s 也带来了我们开发的不便
看到这里,有没有发现从头至尾,虽然效率在不断地提高,环境再一路变好,可以还是有一个问题始终没有解决
那就是我们开发模式的问题
虽然现在使用了 k8s ,但是开发者好像开发起来变得麻烦了许多,甚至有的开发开始抓瞎了,把很多开发都整不会了
Docker 是啥?k8s 是啥?容器化是啥?倒逼大家去适应这个环境和潮流,这是好事,慢慢的大家也学会了这些东西
可是使用 k8s ,每一个开发从编码,提交代码,审核代码,跑流水线,等流水线跑完全程出 helm 包,部署到指定环境上
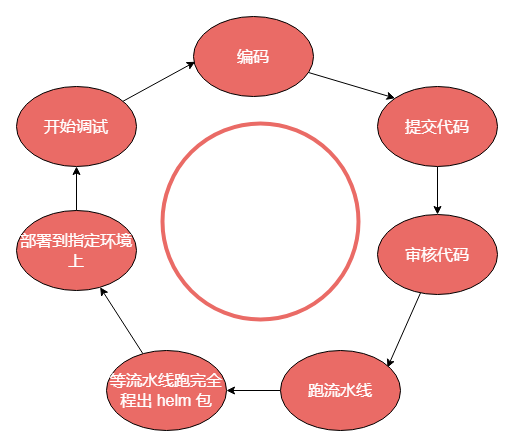
如果自己编写代码出现了问题,我们自然是要调试的,不可能开发写的代码总是一次过的,那么这个时候,又要去跑这个流程,调试一次的成本也太大了吧,这种方式真的也太傻了,这也是启用 k8s 之初,大家非常抗拒的原因之一
毕竟以前主机环境的时候,本地编译出可执行程序,就可以到环境中替换后,就可以查看效果,那么针对当前的问题,能不能解决呢?
使用 teleprecence,nocalhost,以及自己做镜像手动去环境中替换
必须是能解决滴
只要思想不滑坡,办法总比问题多, 慢慢的我们开始引入了 teleprecence ,Telepresence 是一款为k8s 微服务框架提供快速本地化开发功能的开源软件
这个是跑在 linux 里面的工具,可以让我们的微服务直接在本地开发,再也不要去兜圈圈了
Teleprecence 为什么可以让我们在本地开发呢?
Telepresence 在 k8s 集群中运行的Pod中部署双向网络代理,该 Pod 将 k8s 环境中的数据代理到本地进程
简单来说,我们在本地启动服务 A,使用 Teleprecence 拦截 k8s 集群环境 中对于该服务的流量,这样当其他服务和服务 A 有交互的时候,流量就可以达到我们本地启动的服务上来,具体的细节就不过多赘述
同理,由于 Teleprecence 没有可视化有好的 ui 界面,大家接受的程度较低,后续又引入了 nocalhost,和 teleprecence 原理类似
当然也有兄弟有能力自己本机做镜像,推到制品仓库后,直接去 k8s 集群中替换 deploy 的版本,来达到更新服务的目的
使用 istio 进行流量染色+okteto 辅助高效开发
演变到现在,本地可以直接拦截 k8s 集群中的流量的了,对于开发效率确实又提高了一个度,整个环境治理也慢慢有了起色,接受的人也越来越多,慢慢的又出现了一些新的问题
例如,咱们本地拦截 k8s 集群环境中某个服务的流量,那么如果是多个人同时开发同一个服务的时候,我们如何去解决呢?
有这几种方式来解决:
- 人手一套 k8s 集群,仅仅是 k8s 集群是人手一套,关于第三方组件可以共用,这种方式维护成本太高😎😎😎😎
-
仍然是一套主干 k8s 环境,我们给流量进行染色,哪怕同一个服务 A ,有 3 个人同时开发,那么这 3 个人可以为自己的服务加上另外一个标签,例如
- 服务 A,mode=zhangsan
- 服务 A,mode=lisi
- 服务 A,mode=wangwu
这个时候,多个人在同一套 k8s 环境中开发同一个服务,再也不怕冲突了

对于流量染色,我们是引入了 istio 来进行实现
istio 是一个完全开源的服务网格,以透明层的方式构建在现有分布式应用中
简单来说 istio 根据配置的路由去识别不同标签的流量,如果识别到是 服务 A,mode=zhangsan 的流量,就请求他
引入 oketo 也是因为这个工具用起来非常简单,傻瓜式开发
oketo 是 通过在K8s中来开发和测试代码的应用程序开发工具
第一次通过本地简单配置之后,在 goland 中使用 oketo up 即可在我们的 k8s 集群去拦截流量,而且,此处拦截的流量,也是会按照上述我们说的 mode 值去进行处理和识别
例如,流量染色简单原理我们可以这样来理解

这里,我们可以看到,运行在 k8s 集群环境中的默认每一个服务的 mode 都是 standard,表示是公共使用的服务
此时 zhangsan 到环境中去部署了自己版本的 服务 A,mode=zhangsan,和 服务C,mode=zhangsan
通过上图我们可以看到,当 zhangsan 的服务 A 去请求服务 B 的时候,发现没有 mode=zhangsan 的服务B,那么流量就会给到 mode=standard 的服务B,流量从服务B出来之后,发现有 mode=zhangsan 的服务 C,那么流量最后就会给到 服务 C mode=zhangsan 的服务上
哪怕,此时有个 lisi 来环境上部署自己的的 服务 C mode=lisi
那么,zhangsan 的流量也不会打到 lisi 的服务 C 中去,这样,就能够很好的解决,多个人,在同一个环境下修改同一个的服务的情况了
大家完全可以在同一套环境中,自己玩自己的,爽的一批
至此,咱们过去的环境治理就是这样,未来的改进脚步仍然在继续,不断优化,不断提升,持续改变,如果本篇文章对你还有点作用的话,欢迎点赞,收藏,评论哦
感谢阅读,欢迎交流,点个赞,关注一波 再走吧
欢迎点赞,关注,收藏
朋友们,你的支持和鼓励,是我坚持分享,提高质量的动力

好了,本次就到这里
技术是开放的,我们的心态,更应是开放的。拥抱变化,向阳而生,努力向前行。
我是阿兵云原生,欢迎点赞关注收藏,下次见~
文中提到的技术点,感兴趣的可以查看这些文章:
可以进入地址进行体验和学习:https://xxetb.xet.tech/s/3lucCI









