1.start item
1.start_item();
sequencer.wait_for_grant(prior);
this.pre_do(1);

需要指出,这里明确说明了wait_for_grant和send_request之间不能有任何延迟,所以在mid_do这个任务里千万不能有任何延迟。
task uvm_sequencer_base::wait_for_grant(uvm_sequence_base sequence_ptr,
int item_priority = -1,
bit lock_request = 0);
uvm_sequence_request req_s;
int my_seq_id;
if (sequence_ptr == null)
uvm_report_fatal("uvm_sequencer",
"wait_for_grant passed null sequence_ptr", UVM_NONE);
my_seq_id = m_register_sequence(sequence_ptr);
// If lock_request is asserted, then issue a lock. Don't wait for the response, since
// there is a request immediately following the lock request
if (lock_request == 1) begin
req_s = new();
req_s.grant = 0;
req_s.sequence_id = my_seq_id;
req_s.request = SEQ_TYPE_LOCK;
req_s.sequence_ptr = sequence_ptr;
req_s.request_id = g_request_id++;
req_s.process_id = process::self();
arb_sequence_q.push_back(req_s);
end
// Push the request onto the queue
req_s = new();
req_s.grant = 0;
req_s.request = SEQ_TYPE_REQ;
req_s.sequence_id = my_seq_id;
req_s.item_priority = item_priority;
req_s.sequence_ptr = sequence_ptr;
req_s.request_id = g_request_id++;
req_s.process_id = process::self();
arb_sequence_q.push_back(req_s);
m_update_lists();
// Wait until this entry is granted
// Continue to point to the element, since location in queue will change
m_wait_for_arbitration_completed(req_s.request_id);
// The wait_for_grant_semaphore is used only to check that send_request
// is only called after wait_for_grant. This is not a complete check, since
// requests might be done in parallel, but it will catch basic errors
req_s.sequence_ptr.m_wait_for_grant_semaphore++;//这个变量会用在send_request那里,发了一个减少一个,这里得到一个grant加一个
endtask
需要注意几点:
(1)uvm_sequence_base,相当于一个seq或者item的合集

(2) uvm_sequence_request
class uvm_sequence_request;
bit grant;
int sequence_id;
int request_id;
int item_priority;
process process_id;
uvm_sequencer_base::seq_req_t request;
uvm_sequence_base sequence_ptr;
endclass
(3)m_register_sequence,这个任务核心就是输出sequence_ptr的id,同时将sequence_ptr记录到自己定义的动态数组reg_sequence中
function int uvm_sequencer_base::m_register_sequence(uvm_sequence_base sequence_ptr);
if (sequence_ptr.m_get_sqr_sequence_id(m_sequencer_id, 1) > 0)
return sequence_ptr.get_sequence_id();
sequence_ptr.m_set_sqr_sequence_id(m_sequencer_id, g_sequence_id++);
reg_sequences[sequence_ptr.get_sequence_id()] = sequence_ptr;
return sequence_ptr.get_sequence_id();
endfunction
-------------------------------------------------------------------------------
m_get_sqr_sequence_id主要做的内容就是:定义了一个存放id的动态数组m_sqr_seq_ids,如果这个动态数组中存在输入的id,同时需要更新这个id,那就将这个id更新到对应item中
function int m_get_sqr_sequence_id(int sequencer_id, bit update_sequence_id);
if (m_sqr_seq_ids.exists(sequencer_id)) begin
if (update_sequence_id == 1) begin
set_sequence_id(m_sqr_seq_ids[sequencer_id]);
end
return m_sqr_seq_ids[sequencer_id];
end
if (update_sequence_id == 1)
set_sequence_id(-1);
return -1;
endfunction
------------------------------------------------------------------------------------
function void set_sequence_id(int id);//uvm_sequence_item中的任务
m_sequence_id = id;//这个m_sequence_id是item的id
endfunction
------------------------------------------------------------------------------------
function int get_sequence_id();//get_sequence_id是uvm_sequence_item中的任务
return (m_sequence_id);//就是返回当前item的id
endfunction
------------------------------------------------------------------------------------
reg_sequences是定义的uvm_sequence_base的动态数组->
protected uvm_sequence_base reg_sequences[int];
------------------------------------------------------------------------------------(4)
protected uvm_sequence_request arb_sequence_q[$];(5)
function void uvm_sequencer_base::m_update_lists();
m_lock_arb_size++;
endfunction(6)注意这里有几个变量,第一个变量是lock_arb_size,第二个变量是m_lock_arb_size变量,m_lock_arb_size这个变量在每次进行m_update_lists()任务的时候会加一次,在一开始的时候会将这两个值相当,随后去等执行m_update_lists()任务。注意这里的arb_completed,原型是 protected bit arb_completed[int]; 删除这个index相当于从仲裁的q(arb_completed)将仲裁完毕的id删除。
task uvm_sequencer_base::m_wait_for_arbitration_completed(int request_id);
int lock_arb_size;
// Search the list of arb_wait_q, see if this item is done
forever
begin
lock_arb_size = m_lock_arb_size;
if (arb_completed.exists(request_id)) begin
arb_completed.delete(request_id);
return;
end
wait (lock_arb_size != m_lock_arb_size);
end
endtask2.finish_item
finish_item();
(1)this.mid_do(item);
(2)sequencer.send_request(item);
(3)sequencer.wait_for_item_done();
(4)this.post_do(item);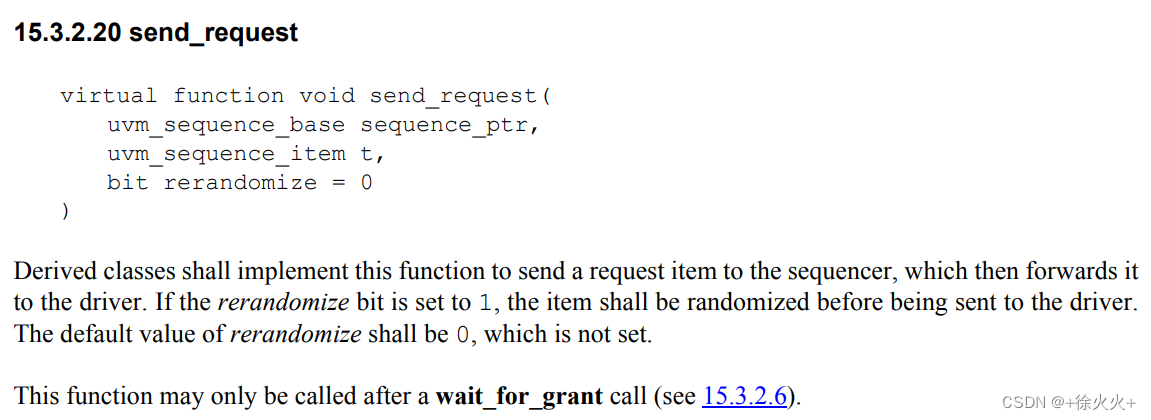
注意,实际上会存在三个fifo,一个fifo是 uvm_tlm_fifo #(REQ) m_req_fifo;另两个是
REQ m_last_req_buffer[$];
RSP m_last_rsp_buffer[$];
uvm_send实际上是不断的往m_req_fifo去放入内容。
function void uvm_sequencer_param_base::send_request(uvm_sequence_base sequence_ptr,
uvm_sequence_item t,
bit rerandomize = 0);
REQ param_t;
if (sequence_ptr == null) begin
uvm_report_fatal("SNDREQ", "Send request sequence_ptr is null", UVM_NONE);
end//没有的化报fatal
if (sequence_ptr.m_wait_for_grant_semaphore < 1) begin
uvm_report_fatal("SNDREQ", "Send request called without wait_for_grant", UVM_NONE);
end//注意,在上面wait_for_grant任务中得到一个grant就会加一个,这里减少
sequence_ptr.m_wait_for_grant_semaphore--;
if ($cast(param_t, t)) begin
if (rerandomize == 1) begin//如果给了随机的选项,需要进行随机
if (!param_t.randomize()) begin
uvm_report_warning("SQRSNDREQ", "Failed to rerandomize sequence item in send_request");
end
end
if (param_t.get_transaction_id() == -1) begin
param_t.set_transaction_id(sequence_ptr.m_next_transaction_id++);
end
m_last_req_push_front(param_t);//往别的q里去推
end else begin
uvm_report_fatal(get_name(),$sformatf("send_request failed to cast sequence item"), UVM_NONE);
end
param_t.set_sequence_id(sequence_ptr.m_get_sqr_sequence_id(m_sequencer_id, 1));
t.set_sequencer(this);
if (m_req_fifo.try_put(param_t) != 1) begin
uvm_report_fatal(get_full_name(), "Concurrent calls to get_next_item() not supported. Consider using a semaphore to ensure that concurrent processes take turns in the driver", UVM_NONE);
end
m_num_reqs_sent++;//记录send了多少内容
// Grant any locks as soon as possible
grant_queued_locks();
endfunctiongrant_queued_locks()任务有点复杂,没看完,留个坑
注意这个任务 ,前期会一直往m_last_req_buffer里push,注意这里是从前推入。这个q是uvm_sequencer_param_base类中定义的q,他的类型采用了参数化的类REQ,定义方式如下:
REQ m_last_req_buffer[$];
function void uvm_sequencer_param_base::m_last_req_push_front(REQ item);
if(!m_num_last_reqs)
return;
if(m_last_req_buffer.size() == m_num_last_reqs)
void'(m_last_req_buffer.pop_back());
this.m_last_req_buffer.push_front(item);
endfunction其中m_num_last_reqs这个变量是通过set_num_last_reqs任务实现的,也就是说m_last_req_buffer的buf含量最大是1024个。
function void uvm_sequencer_param_base::set_num_last_reqs(int unsigned max);
if(max > 1024) begin
uvm_report_warning("HSTOB",
$sformatf("Invalid last size; 1024 is the maximum and will be used"));
max = 1024;
end
//shrink the buffer if necessary
while((m_last_req_buffer.size() != 0) && (m_last_req_buffer.size() > max))
void'(m_last_req_buffer.pop_back());
m_num_last_reqs = max;
num_last_items = max;
endfunction这里就有个问题了,可以看到,实际上源码 并没有用m_last_req_buffer,而是用的是m_req_fifo,那这个buffer到底是做什么用的呢?其实查阅uvm手册可以发现,针对m_last_req_buffer的相关任务大多是以API的形式存在,所以个人理解还是封装了一下以便上层可以根据API实现更为负载的sequencer。
下面介绍结构和m_last_req_buffer/m_last_rsp_buffer相关的方法,可以在sequencer中实现。
(1)last_req,返回最后一个req,虽然叫last_req,但是实际可以返回任何顺序的。
function REQ last_req(int unsigned n = 0);
if(n > m_num_last_reqs) begin
uvm_report_warning("HSTOB",
$sformatf("Invalid last access (%0d), the max history is %0d", n,
m_num_last_reqs));
return null;
end
if(n == m_last_req_buffer.size())
return null;
return m_last_req_buffer[n];
endfunctionget_num_last_reqs,相当于返回m_last_req_buffer的size
function int unsigned uvm_sequencer_param_base::get_num_last_reqs();
return m_num_last_reqs;
endfunctionset_num_last_reqs,约束m_last_req_buffer的size,多的部分会被pop出去。
function void uvm_sequencer_param_base::set_num_last_reqs(int unsigned max);
if(max > 1024) begin
uvm_report_warning("HSTOB",
$sformatf("Invalid last size; 1024 is the maximum and will be used"));
max = 1024;
end
//shrink the buffer if necessary
while((m_last_req_buffer.size() != 0) && (m_last_req_buffer.size() > max))
void'(m_last_req_buffer.pop_back());
m_num_last_reqs = max;
num_last_items = max;
endfunctionm_last_rsp_buffer的方法和上面类似,但是方法名称有所不同,分别是last_rsp();set_num_last_rsps();get_num_last_rsps();



function int uvm_sequencer_param_base::get_num_rsps_received();
return m_num_rsps_received;//相当于m_last_rsp_buffer的size
endfunctionwait_for_item_done针对这个sequence_ptr,如果没有定义了transaction_id,那么仅仅需要等sequence_id,如果定义了的化,还需要多等一个 transaction_id。
task uvm_sequencer_base::wait_for_item_done(uvm_sequence_base sequence_ptr,
int transaction_id);
int sequence_id;
sequence_id = sequence_ptr.m_get_sqr_sequence_id(m_sequencer_id, 1);
m_wait_for_item_sequence_id = -1;
m_wait_for_item_transaction_id = -1;
if (transaction_id == -1)
wait (m_wait_for_item_sequence_id == sequence_id);
else
wait ((m_wait_for_item_sequence_id == sequence_id &&
m_wait_for_item_transaction_id == transaction_id));
endtask3.uvm_do做了上面的两部分:

4.driver,这里介绍和driver相关的两个方法:(1)get_next_item(2)try_next_item
需要注意的是,这两个方法都是是从前面说的m_req_fifo里去拿。
注意这里get_next_item任务,在执行这个任务的时候,get_next_item_called变量置为1,这个变量会在item_done的任务里再置为0,这个变量是为了避免多次get item,但是不执行item_done的情况。
task uvm_sequencer::get_next_item(output REQ t);
REQ req_item;
// If a sequence_item has already been requested, then get_next_item()
// should not be called again until item_done() has been called.
if (get_next_item_called == 1)
uvm_report_error(get_full_name(),
"Get_next_item called twice without item_done or get in between", UVM_NONE);
if (!sequence_item_requested)
m_select_sequence();
// Set flag indicating that the item has been requested to ensure that item_done or get
// is called between requests
sequence_item_requested = 1;
get_next_item_called = 1;
m_req_fifo.peek(t);
endtasktry_next_item
task uvm_sequencer::try_next_item(output REQ t);
int selected_sequence;
time arb_time;
uvm_sequence_base seq;
if (get_next_item_called == 1) begin
uvm_report_error(get_full_name(), "get_next_item/try_next_item called twice without item_done or get in between", UVM_NONE);
return;
end//前面就是做一些列的判断,防止出现多次get item的情况
// allow state from last transaction to settle such that sequences'
// relevancy can be determined with up-to-date information
wait_for_sequences();//这个任务实际上就是等一个时间片
// choose the sequence based on relevancy
selected_sequence = m_choose_next_request();//仲裁出到底使用哪个sequence
// return if none available
if (selected_sequence == -1) begin
t = null;
return;
end
// now, allow chosen sequence to resume
m_set_arbitration_completed(arb_sequence_q[selected_sequence].request_id);
seq = arb_sequence_q[selected_sequence].sequence_ptr;
arb_sequence_q.delete(selected_sequence);
m_update_lists();
sequence_item_requested = 1;
get_next_item_called = 1;
// give it one NBA to put a new item in the fifo
wait_for_sequences();
// attempt to get the item; if it fails, produce an error and return
if (!m_req_fifo.try_peek(t))
uvm_report_error("TRY_NEXT_BLOCKED", {"try_next_item: the selected sequence '",
seq.get_full_name(), "' did not produce an item within an NBA delay. ",
"Sequences should not consume time between calls to start_item and finish_item. ",
"Returning null item."}, UVM_NONE);
endtask具体看m_choose_next_request()任务
function int uvm_sequencer_base::m_choose_next_request();
int i, temp;
int avail_sequence_count;
int sum_priority_val;
integer avail_sequences[$];
integer highest_sequences[$];
int highest_pri;
string s;
avail_sequence_count = 0;
grant_queued_locks();
i = 0;
while (i < arb_sequence_q.size()) begin
if ((arb_sequence_q[i].process_id.status == process::KILLED) ||
(arb_sequence_q[i].process_id.status == process::FINISHED)) begin
`uvm_error("SEQREQZMB", $sformatf("The task responsible for requesting a wait_for_grant on sequencer '%s' for sequence '%s' has been killed, to avoid a deadlock the sequence will be removed from the arbitration queues", this.get_full_name(), arb_sequence_q[i].sequence_ptr.get_full_name()))
remove_sequence_from_queues(arb_sequence_q[i].sequence_ptr);
continue;
end
if (i < arb_sequence_q.size())
if (arb_sequence_q[i].request == SEQ_TYPE_REQ)
if (is_blocked(arb_sequence_q[i].sequence_ptr) == 0)
if (arb_sequence_q[i].sequence_ptr.is_relevant() == 1) begin
if (m_arbitration == UVM_SEQ_ARB_FIFO) begin
return i;//如果是默认的仲裁方式,实际上在这里就会返回ID号
end
else avail_sequences.push_back(i);
end
i++;
end//这个任务实际就是在seq不是lock的,同时这个seq是有效的(is_relevant=1)的情况下,如果不是fifo的仲裁方式的化,将arb_sequence_q中的索引值推入到avail_sequences中去。
// Return immediately if there are 0 or 1 available sequences
if (m_arbitration == UVM_SEQ_ARB_FIFO) begin
return -1;
end
if (avail_sequences.size() < 1) begin//这两个函数我理解只是做保护的
return -1;
end
if (avail_sequences.size() == 1) begin//size为1的时候立刻返回
return avail_sequences[0];
end
// If any locks are in place, then the available queue must
// be checked to see if a lock prevents any sequence from proceeding
if (lock_list.size() > 0) begin//这个函数没懂
for (i = 0; i < avail_sequences.size(); i++) begin
if (is_blocked(arb_sequence_q[avail_sequences[i]].sequence_ptr) != 0) begin
avail_sequences.delete(i);
i--;
end
end
if (avail_sequences.size() < 1)
return -1;
if (avail_sequences.size() == 1)
return avail_sequences[0];
end
// Weighted Priority Distribution
// Pick an available sequence based on weighted priorities of available sequences
//权重约束,这里我理解是把所有seq的权重加在一起得到一个总的门槛值,然后随机一个在门槛值和0之间的值,如果当前seq的权重大于这个随机值,就认为仲裁成功,在此后的循环过程中,新的seq的权重总是会加上之前seq的权重,把这个权重的和与门槛值进行比较。
if (m_arbitration == UVM_SEQ_ARB_WEIGHTED) begin
sum_priority_val = 0;
for (i = 0; i < avail_sequences.size(); i++) begin
sum_priority_val += m_get_seq_item_priority(arb_sequence_q[avail_sequences[i]]);
end
temp = $urandom_range(sum_priority_val-1, 0);
sum_priority_val = 0;
for (i = 0; i < avail_sequences.size(); i++) begin
if ((m_get_seq_item_priority(arb_sequence_q[avail_sequences[i]]) +
sum_priority_val) > temp) begin
return avail_sequences[i];
end
sum_priority_val += m_get_seq_item_priority(arb_sequence_q[avail_sequences[i]]);
end
uvm_report_fatal("Sequencer", "UVM Internal error in weighted arbitration code", UVM_NONE);
end
//这里相当于随机给一个
// Random Distribution
if (m_arbitration == UVM_SEQ_ARB_RANDOM) begin
i = $urandom_range(avail_sequences.size()-1, 0);
return avail_sequences[i];
end
// Strict Fifo
if ((m_arbitration == UVM_SEQ_ARB_STRICT_FIFO) || m_arbitration == UVM_SEQ_ARB_STRICT_RANDOM) begin
highest_pri = 0;
// Build a list of sequences at the highest priority
//这个for循环相当于找最大优先级的seq,把最大优先级的seq都放到highest_sequences,注意这里的delete动作,保证了只会存在最大优先级的seq
for (i = 0; i < avail_sequences.size(); i++) begin
if (m_get_seq_item_priority(arb_sequence_q[avail_sequences[i]]) > highest_pri) begin
// New highest priority, so start new list
highest_sequences.delete();
highest_sequences.push_back(avail_sequences[i]);
highest_pri = m_get_seq_item_priority(arb_sequence_q[avail_sequences[i]]);
end
else if (m_get_seq_item_priority(arb_sequence_q[avail_sequences[i]]) == highest_pri) begin
highest_sequences.push_back(avail_sequences[i]);
end
end
//如果是严格fifo,会把最大优先级的,同时最先进入fifo的,先给出出去
// Now choose one based on arbitration type
if (m_arbitration == UVM_SEQ_ARB_STRICT_FIFO) begin
return(highest_sequences[0]);
end
//如果不是严格fifo的化,就是在最大优先级的各个seq里去随机
i = $urandom_range(highest_sequences.size()-1, 0);
return highest_sequences[i];
end
//这个仲裁没看
if (m_arbitration == UVM_SEQ_ARB_USER) begin
i = user_priority_arbitration( avail_sequences);
// Check that the returned sequence is in the list of available sequences. Failure to
// use an available sequence will cause highly unpredictable results.
highest_sequences = avail_sequences.find with (item == i);
if (highest_sequences.size() == 0) begin
uvm_report_fatal("Sequencer",
$sformatf("Error in User arbitration, sequence %0d not available\n%s",
i, convert2string()), UVM_NONE);
end
return(i);
end
uvm_report_fatal("Sequencer", "Internal error: Failed to choose sequence", UVM_NONE);
endfunction
未完。。。。










