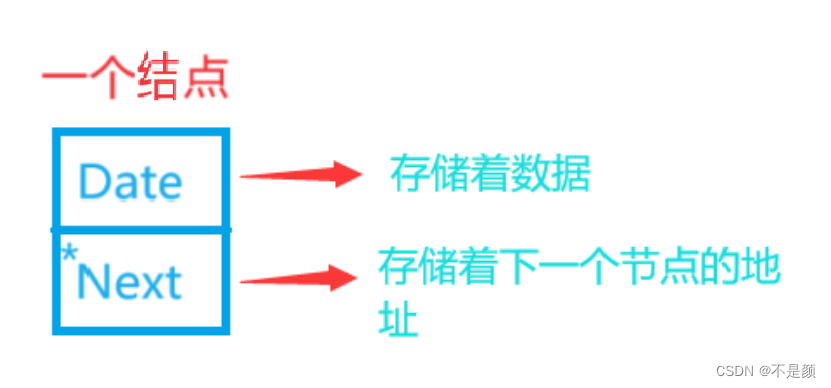
单链表
单链表是一种链式存取的数据结构,用一组地址任意的存储单元存放线性表中的数据元素。链表中的数据是以结点来表示的,每个结点的构成:元素(数据元素的映象) +指针(指示后继元素存储位置),元素就是存储数据的存储单元,指针就是连接每个结点的地址数据。
如图是一个结点
多个结点加上head(头结点)指针(指向了第一个结点的位置)就构成了单链表,最后一个结点的Next指向了空,其中结点的数据存放并不是连续的,像数组那样,但是只要使用Next指针,一样可以达到逻辑上的连续

数组模拟
在这里我们用数组模拟单链表
创建一个e[N]数组存储每个结点的数据
创建一个ne[N]数组存储下一个结点的位置,在数组模拟中,也就是对应的数组下标
创建一个idx,表示用到了数组的哪个位置,最开始为0
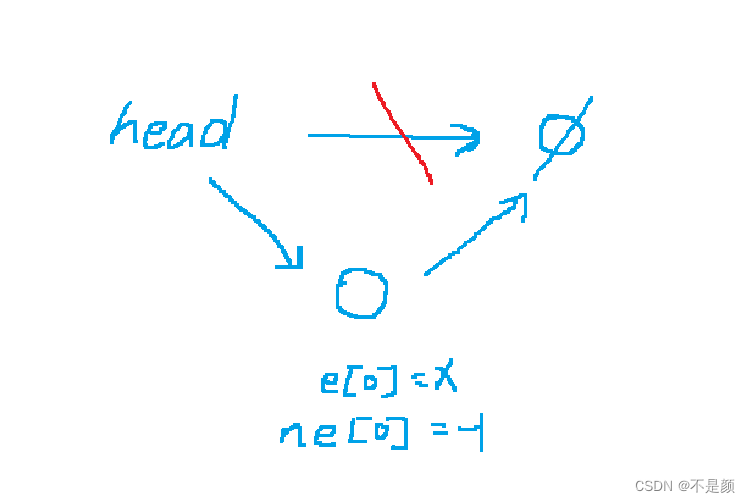
首先当链表中还没有数据时,头结点应该指向空(NULL),如图

我们把空用数字-1来代替,因为数组中是没有-1下标的,所以最开始头结点指向了-1
void unit() //初始化链表
{
head = -1;
idx = 0;
}好,那现在往链表中添加结点,但是这有两种情况,一种是在头结点后添加. 一种是往已有结点添加
我们先来实现第一种,我们添加的结点就要指向-1,因为他是链表中最后一个结点,那头结点就要存储我们这个结点的数组的下标,也就是这个结点的位置0,如图
void add_head(int x)
{
e[idx] = x; //存储的值
eo[idx] = head; //head最开始为-1
head = idx++; //head指向了 0
}好,如果是第二种,往第k个结点后添加结点,第一个结点的下标为0,所以第k个结点的下标为k-1
如图

得
void add_k(int k, int x)
{
e[idx] = x;
eo[idx] = eo[k]; //这个结点指向了k结点指向的下一个结点的坐标
eo[k] = idx++; //k结点指向我们新添加的结点
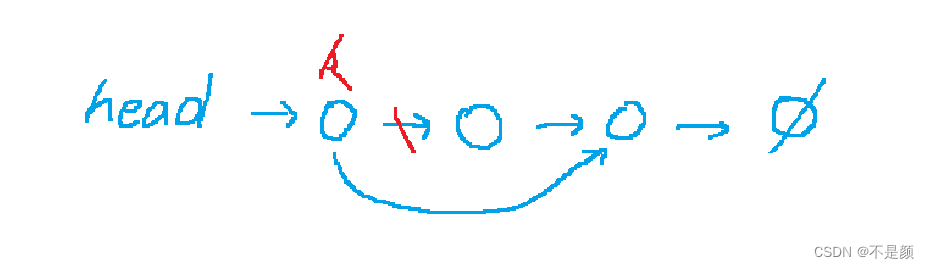
}将某一个结点删除,一是将头结点后的结点删除,二是将k结点后面的结点删除,不是真正的删除它在数组中的存在,而是链表中访问不到它了
来看第一种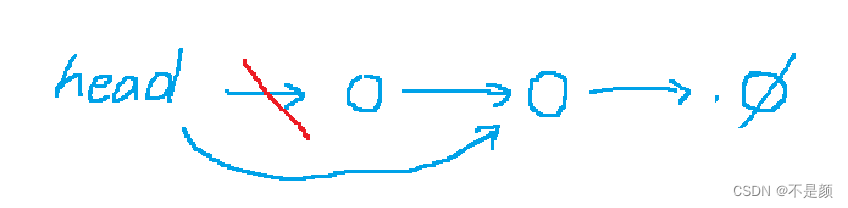
void remove_head()
{
head = eo[head];
}第二种
以上的添加和删除节点中的k,在传入参数时为原数据的-1,因为下标是从0开始的,而结点是从一开始
,如果传入时,传入的不是k-1,那么要在函数内对k--
好已经有了初始化链表函数,删除函数,添加结点函数,来道题
题目
实现一个单链表,链表初始为空,支持三种操作:
向链表头插入一个数;
删除第 k 个插入的数后面的数;
在第 k 个插入的数后插入一个数。
现在要对该链表进行 M 次操作,进行完所有操作后,从头到尾输出整个链表。注意:题目中第 k 个插入的数并不是指当前链表的第 k 个数。例如操作过程中一共插入了 n 个数,则按照插入的时间顺序,这 n 个数依次为:第 1 个插入的数,第 2 个插入的数,…第 n 个插入的数。
输入格式
第一行包含整数 M,表示操作次数。
接下来 M 行,每行包含一个操作命令,操作命令可能为以下几种:H x,表示向链表头插入一个数 x。
D k,表示删除第 k 个插入的数后面的数(当 k 为 0 时,表示删除头结点)。
I k x,表示在第 k 个插入的数后面插入一个数 x(此操作中 k 均大于 0)。
输出格式
共一行,将整个链表从头到尾输出。数据范围
1≤M≤100000
所有操作保证合法。输入样例:
10 H 9 I 1 1 D 1 D 0 H 6 I 3 6 I 4 5 I 4 5 I 3 4 D 6输出样例:
6 4 6 5
代码
#include <iostream>
using namespace std;
const int N = 10010;
int e[N], eo[N];
int idx,head;
void unit()
{
head = -1;
idx = 0;
}
/*
void add_head(int x) //因为题目中插入的k是>0的,所以没有在头结点后插入这步操作
{
e[idx] = x;
eo[idx] = head;
head = idx++;
}
*/
void add_k(int k, int x)
{
e[idx] = x;
eo[idx] = eo[k];
eo[k] = idx++;
}
void remove_head()
{
head = eo[head];
}
void remove_k(int k)
{
eo[k] = eo[eo[k]];
}
int main(void)
{
unit();
int M;
cin >> M;
while (M--)
{
char op;
int k=0, x=0;
cin >> op;
if (op == 'H')
{
cin >> x;
add_head(x);
}
else if (op == 'D')
{
cin >> k;
if (!k)
{
remove_head();
}
else
{
remove_k(k - 1);
}
}
else
{
cin >> k >> x;
if (!k)
{
add_head(x);
}
else
{
add_k(k - 1, x);
}
}
}
//遍历链表
for (int i = head; i != -1;i=eo[i])
{
cout << e[i] << " ";
}
}








