一、list定义
list本质是一个双向带头循环链表
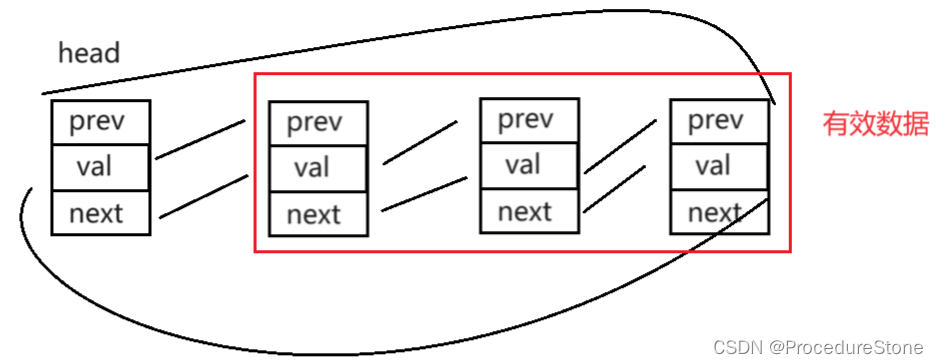
template<class T>
struct list_node
{
list_node* prev;
T val;
list_node* next;
};
template<class T>
class list
{
typedef list_node<T> node;
private:
node* head;
};
二、list的迭代器
不同于vector的迭代器,list的迭代器是一个类,原因是list是链式空间,普通指针的++,–不能访问到正确的地址,因此需要运算符重载++,–等。
template<class T, class ref, class ptr>
struct list_iterator
{
private:
typedef list_node<T> node;
typedef list_iterator<T, ref, ptr> self;
public:
node* _cur;
};
这里有一个重点,模板参数ref,ptr是干什么的?
在list类中是这样定义iterator
typedef list_iterator<T, T&, T*> iterator;
typedef list_iterator<T, const T&, const T*> const_iterator;
这表示 ref传的是T的引用,ptr传的是T的指针,这不是多此一举吗?
但偏偏list的源码也是这样的。

这是为什么呢?
我们将list_iterator封装为一个类,主要是想重载它的++,–等运算符,以便正确使用iterator;
下面这是list_literator的前置++,它的返回值应该是 list_iterator<T>&,但如果我使用的是const_iterator,它的返回值应该是const list_iterator<T>&,二者的区别仅仅只是返回值不同,但仅仅返回值不同,不能构成函数重载。这样仅仅想靠一个类list_iterator是不行的,那就只能再写一个类const_list_iterator.
返回值 operator++()
{
_cur = _cur->next;
return *this;
}
但如果传参时,T& | const T& 作为一个参数传递,就可以只写list_iterator,来完成iterator 和 const_iterator.虽然本质上还是创建了2个类,但创建的工作由编译器解决,我们只用手写一个类就够了。
template<class T, class ref, class ptr>
struct list_iterator
{
private:
typedef list_node<T> node;
typedef list_iterator<T, ref, ptr> self;
//iterator 则 ref = T&
//const_iterator 则 ref = const T&
public:
//成员变量
node* _cur = nullptr;
//迭代器:构造,++, *
list_iterator(node* it = nullptr)
{
_cur = it;
}
self& operator++()
{
_cur = _cur->_next;
return *this;
}
self& operator++(int)
{
self tmp(*this);
_cur = _cur->_next;
return tmp;
}
ref operator*() const
{
return _cur->_val;
}
};
ptr同理,它主要服务operator->()
ptr operator->() const
{
return &(_cur->_val);
}
注:这里有个小知识,operator的返回值可能让人感到疑惑。
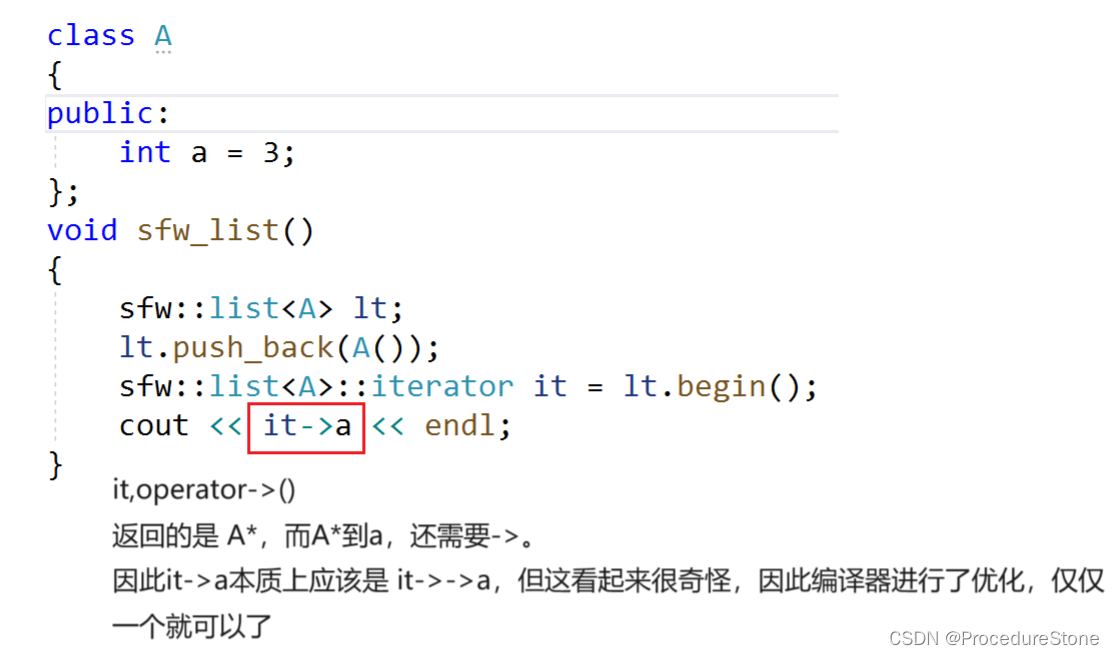
C++ 中的 operator-> 被用于重载类的成员访问操作符 ->。这个操作符通常用于访问类的成员函数和成员变量,而且在许多情况下,它应该返回一个指向类的成员的指针。这是因为 -> 操作符通常用于访问类的成员,而类的成员可以是函数或变量。
三、list的元素操作
list的插入删除,本质就是双向带头链表的插入删除,下面给出一些简单的模拟实现。
list(const T& t = T())
{
head = new node;
node* tmp = new node;
tmp->_val = t;
tmp->_next = head;
tmp->_prev = head;
head->_next = tmp;
head->_prev = tmp;
++_size;
}
list(const list<T>& t)
{
for (auto& e : t)
{
push_back(e);
}
}
~list()
{
iterator it = begin();
while (it != end())
{
it = erase(it);
}
delete head;
head = nullptr;
}
void swap(list<T>& lt)
{
std::swap(head, lt.head);
std::swap(size, lt.head);
}
list<T>& operator=(list<T> lt)
{
swap(lt);
}
//iterator
iterator begin()
{
return iterator(head->_next);
}
iterator end()
{
return iterator(head);
}
//capacity
size_t size()
{
return _size;
}
//modify
void push_back(const T& t = T())
{
insert(end(), t);
}
void push_front(const T& t = T())
{
insert(begin(), t);
}
void insert(iterator pos, const T& t)
{
node* cur = pos._cur;
node* prev = cur->_prev;
node* tmp = new node;
tmp->_val = t;
tmp->_prev = prev;
tmp->_next = cur;
prev->_next = tmp;
cur->_prev = tmp;
++_size;
}
void pop_back()
{
iterator it(head->_prev);
erase(it);
}
void pop_front()
{
erase(begin());
}
iterator erase(iterator pos)
{
node* cur = pos._cur;
node* prev = cur->_prev;
node* next = cur->_next;
prev->_next = next;
next->_prev = prev;
delete cur;
--_size;
return iterator(next);
}
list在使用时,一定要注意迭代器失效的问题。
四,list的优缺点
STL(标准模板库)中的 std::list 是一个双向链表(doubly linked list)的实现,它具有一些优点和缺点,适用于不同的使用情况。
优点:
-
插入和删除效率高:
std::list对于插入和删除操作非常高效,因为在双向链表中,插入和删除元素只需要改变相邻节点的指针,而不需要移动其他元素。 -
稳定的迭代器: 在插入和删除元素时,
std::list保持了迭代器的有效性。这意味着在遍历列表时进行插入或删除操作不会导致迭代器失效,这在其他容器中(如std::vector)是不成立的。 -
内存管理灵活: 由于链表的节点可以分散存储在内存中,
std::list具有一定的内存分配灵活性。这可以避免动态数组(如std::vector)可能会发生的重新分配和复制开销。
缺点:
-
随机访问效率低:
std::list不支持常数时间的随机访问,因为要遍历链表需要 O(n) 的时间复杂度。如果需要频繁的随机访问元素,std::vector更适合。 -
性能较差的缓存局部性: 由于链表节点在内存中是离散分布的,因此对于大型数据集,
std::list的性能可能受到缓存局部性的影响,而数组式容器更有可能利用好缓存。 -
不支持随机访问和下标访问:
std::list不支持像数组那样的随机访问或下标访问,这限制了其在某些应用中的使用。








