vector模拟实现
基本结构

// 可以是不同类型, 用类模板
template <class T>
class vector
{
public:
// 源码里面成员变量的类型用的是迭代器,
// 所以, 先定义迭代器类型
typedef T* iterator;
typedef const T* const_iterator;
private:
iterator _start = nullptr; // 相当于string类中的 _str
iterator _finish = nullptr; // 相当于string类中的 _size
iterator _endofstorage = nullptr; // 相当于string类中的 _capacity
}
- 成员变量先给缺省值, 便于后面的构造函数 和 拷贝构造函数
- 迭代器是 T* , 跟string类中 迭代器是 char* 是一样的道理
天选之子
构造
- 默认构造函数
vector()
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
}
由于我们给成员变量都给了缺省值, 那么👇👇👇
vector()
{
}
- 开空间 + 初始化
开空间 + 初始化也是resize干的事情, 那么我们就可以直接复用
vector(int n, const T& val = T()) // 缺省值给T的默认构造出来的对象
{
resize(n, val);
}
- 迭代器区间初始化
从上一篇文章得出: 同类型, 不同类型, 数组的区间都可以进行初始化. 迭代器多样化 ⇒ 套用模版
⇒ 进而我们得出: 在模版中可以套用模版
template <class InputIterator>
vector(InputIterator first, InputIterator last)
{
int n = last - first;
resize(n);
int i = 0;
while (first != last)
{
_start[i++] = *first;
first++;
}
}
拷贝构造
vector(const vector<T>& tem)
{
// 找一块新空间 -- 外部深拷贝
_start = new T[tem.capacity()];
// memcpy(_start, tem._start, tem.capacity); -- 内部浅拷贝, 是错误的
for (int i = 0; i < tem.size(); i++) // 内部深拷贝
{
_start[i] = tem[i];
}
// 更新size 和 capacity
_finish = _start + tem.size();
_endofstorage = _start + tem.capacity();
}
- 不能使用memcpy来进行拷贝数据的原因 && 外部和内部的深拷贝图示


析构
~vector()
{
// 释放空间
delete[] _start;
// 置空
_start = _finish = _endofstorage = nullptr;
}
operator=
// 现代写法 -- 传值传参, 巧借拷贝构造
T& operator=(const T tem)
{
swap(tem);
return *this;
}
空间
reserve
void reserve(size_t n)
{
assert(n > 0);
if (n > capacity())
{
size_t sz = size(); // 应该先保存一份sz <== _start会发生变化
T* tem = new T[n];
// 拷贝数据
// memcpy(tem._start, _start, n); // 内部浅拷贝
for (int i = 0; i < size(); i++)
{
tem[i] = _start[i]; //调用了T的赋值, 从而实现深拷贝
}
// 更新_start
delete[] _start;
_start = tem;
// 更新size 和 capacity
_finish = _start + sz;
_endofstorage = _start + n;
}
}
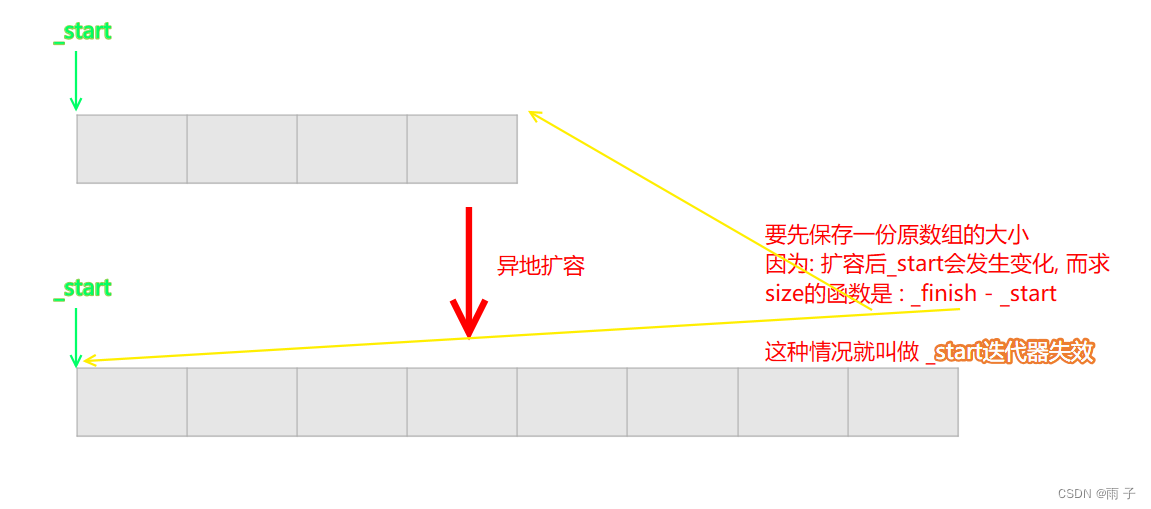
resize
void resize(size_t n, const T& val = T())
{
assert(n > 0);
// 缩
if (size() > n)
{
_finish = _start + n;
}
// 扩
else
{
reserve(n); // 先开n个空间
// 从_finish位置开始初始化
for (int i = size(); i < size() + n; i++)
{
_start[i] = val;
}
// 改变_finish
_finish = _finish + n;
}
}
size && capacity
const size_t size()const
{
return _finish - _start;
}
const size_t capacity()const
{
return _endofstorage - _start;
}
增
insert
void insert(iterator pos, const T& val = T())
{
assert(pos >= _start && pos <= _finish);
size_t len = pos - _start; // 在扩容前, 先保存一下pos的相对位置, 以免异地扩容, _start发生变化, 导致pos迭代器失效
// 是否扩容
if (_finish == _endofstorage)
{
// 考虑到首次插入
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
pos = _start + len; // 扩容后, 更新pos
}
// 往后挪动数据
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
end--;
}
// 插入
*pos = val;
_finish = _finish + 1;
}
push_back
void push_back(const T& val = T())
{
是否扩容
//if (_finish == _endofstorage)
//{
// size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
// reserve(newcapacity);
//}
//*_finish = val;
//++_finish;
// 复用insert
insert(_finish, val);
}
删
erase
iterator erase(iterator pos)
{
assert(pos >= _start && pos < _finish);
// 往前挪动数据
iterator it = pos + 1 ;
while (it != _finish)
{
*(it - 1) = *it;
it++;
}
// 更新size
--_finish;
return pos;
}
pop_back
void pop_back()
{
// 复用erase, 传参_finish - 1
erase(--end());
}
查 && 改
swap
void swap(vector<T>& tem)
{
std::swap(_start, tem._start);
std::swap(_finish, tem._finish);
std::swap(_endofstorage, tem._endofstorage);
}
operator[]
T& operator[](size_t n)
{
return _start[n];
}
const T& operator[](size_t n)const
{
return _start[n];
}
源码
#pragma once
#include<assert.h>
#include<iostream>
namespace muyu
{
template <class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator begin()const
{
return _start;
}
const_iterator end()const
{
return _finish;
}
vector()
{
}
vector(int n, const T& val = T()) // 缺省值给 T的默认构造出来的对象
{
resize(n, val);
}
template <class InputIterator>
vector(InputIterator first, InputIterator last)
{
int n = last - first;
resize(n);
int i = 0;
while (first != last)
{
_start[i++] = *first;
first++;
}
}
vector(const vector<T>& tem)
{
// 找一块新空间 -- 外部深拷贝
_start = new T[tem.capacity()];
// memcpy(_start, tem._start, tem.capacity); -- 内部浅拷贝, 是错误的
for (int i = 0; i < tem.size(); i++) // 内部深拷贝
{
_start[i] = tem[i];
}
// 更新size 和 capacity
_finish = _start + tem.size();
_endofstorage = _start + tem.capacity();
}
~vector()
{
// 释放空间
delete[] _start;
// 置空
_start = _finish = _endofstorage = nullptr;
}
const size_t size()const
{
return _finish - _start;
}
const size_t capacity()const
{
return _endofstorage - _start;
}
void reserve(size_t n)
{
assert(n > 0);
if (n > capacity())
{
size_t sz = size(); // 应该先保存一份sz <== _start会发生变化
T* tem = new T[n];
// 拷贝数据
// memcpy(tem._start, _start, n); // 内部浅拷贝
for (int i = 0; i < size(); i++)
{
tem[i] = _start[i]; //调用了T的赋值, 从而实现深拷贝
}
// 更新_start
delete[] _start;
_start = tem;
// 更新size 和 capacity
_finish = _start + sz;
_endofstorage = _start + n;
}
}
void resize(size_t n, const T& val = T())
{
assert(n > 0);
if (size() > n)
{
_finish = _start + n;
}
else
{
reserve(n); // 先开n个空间
// 从_finish位置开始初始化
for (int i = size(); i < size() + n; i++)
{
_start[i] = val;
}
// 改变_finish
_finish = _finish + n;
}
}
void push_back(const T& val = T())
{
是否扩容
//if (_finish == _endofstorage)
//{
// size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
// reserve(newcapacity);
//}
//*_finish = val;
//++_finish;
insert(_finish, val);
}
void insert(iterator pos, const T& val = T())
{
assert(pos >= _start && pos <= _finish);
size_t len = pos - _start; // 在扩容前, 先保存一下pos的相对位置, 以免异地扩容, _start发生变化, 导致pos迭代器失效
// 是否扩容
if (_finish == _endofstorage)
{
size_t newcapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcapacity);
pos = _start + len; // 扩容后, 更新pos
}
// 往后挪动数据
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
end--;
}
// 插入
*pos = val;
_finish = _finish + 1;
}
T& operator[](size_t n)
{
return _start[n];
}
const T& operator[](size_t n)const
{
return _start[n];
}
void swap(vector<T>& tem)
{
std::swap(_start, tem._start);
std::swap(_finish, tem._finish);
std::swap(_endofstorage, tem._endofstorage);
}
iterator erase(iterator pos)
{
assert(pos >= _start && pos < _finish);
iterator it = pos + 1 ;
while (it != _finish)
{
*(it - 1) = *it;
it++;
}
--_finish;
return pos;
}
void pop_back()
{
// 复用erase, 传参_finish - 1
erase(--end());
}
// 现代写法 -- 传值传参, 巧借拷贝构造
T& operator=(const T tem)
{
swap(tem);
return *this;
}
private:
iterator _start = nullptr; // 相当于string类中的 _str
iterator _finish = nullptr; // 相当于string类中的 _size
iterator _endofstorage = nullptr; // 相当于string类中的 _capacity
};
}







