flink应用场景
 maven依赖
maven依赖
<properties>
<flink.version>1.17.0</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>有界流

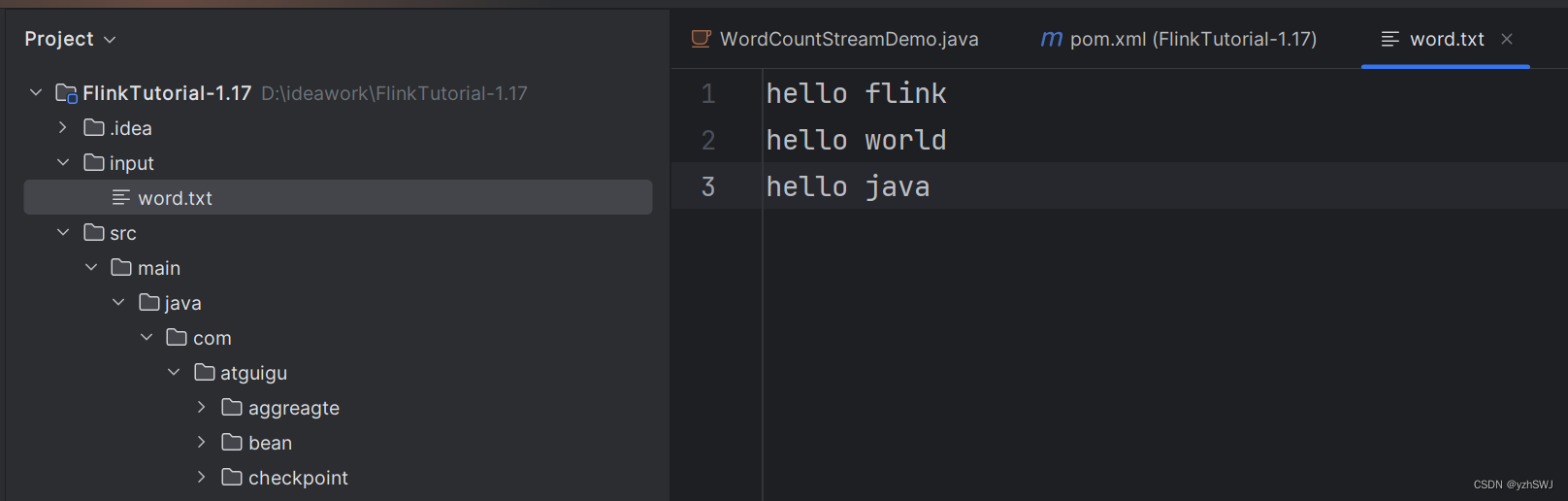
流处理
来一条计算一条,输出一次
package com.atguigu.wc;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* TODO DataStream实现Wordcount:读文件(有界流)
*
* @author cjp
* @version 1.0
*/
public class WordCountStreamDemo {
public static void main(String[] args) throws Exception {
// TODO 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// TODO 2.读取数据:从文件读
DataStreamSource<String> lineDS = env.readTextFile("input/word.txt");
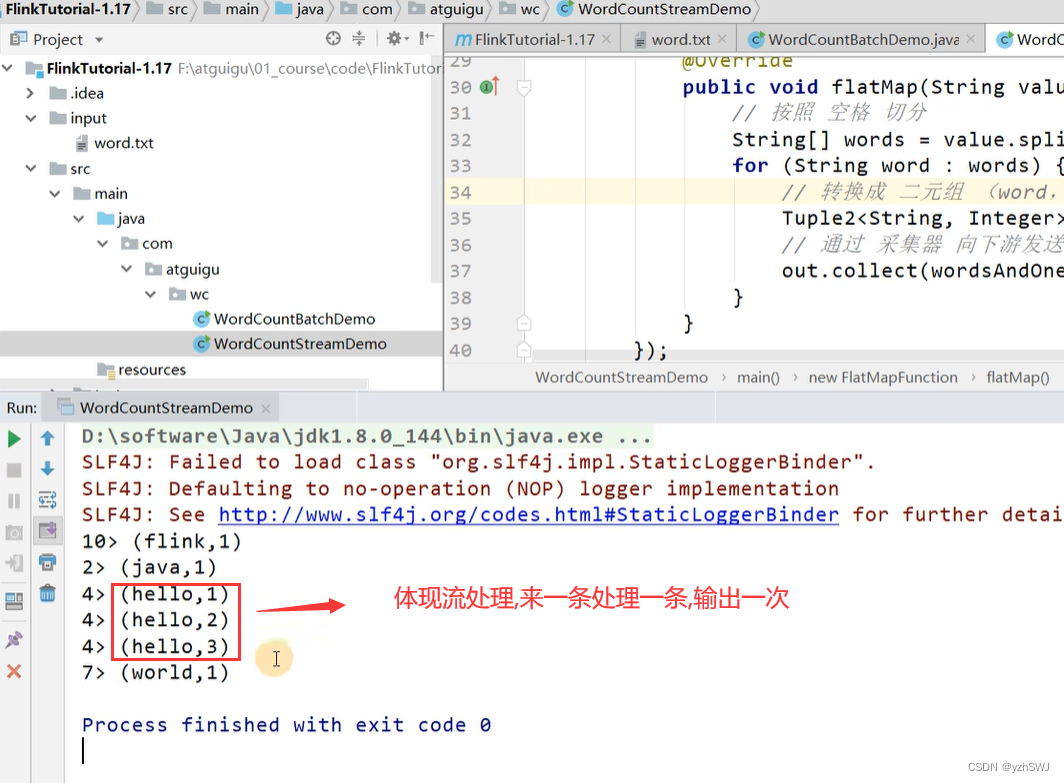
// TODO 3.处理数据: 切分、转换、分组、聚合
// TODO 3.1 切分、转换
SingleOutputStreamOperator<Tuple2<String, Integer>> wordAndOneDS = lineDS
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
// 按照 空格 切分
String[] words = value.split(" ");
for (String word : words) {
// 转换成 二元组 (word,1)
Tuple2<String, Integer> wordsAndOne = Tuple2.of(word, 1);
// 通过 采集器 向下游发送数据
out.collect(wordsAndOne);
}
}
});
// TODO 3.2 分组
KeyedStream<Tuple2<String, Integer>, String> wordAndOneKS = wordAndOneDS.keyBy(
new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
//取出 二元组 (word,1) 第一个元素
return value.f0;
}
}
);
// TODO 3.3 聚合 二元组 (word,1) 根据第二个元素聚合 索引 1
SingleOutputStreamOperator<Tuple2<String, Integer>> sumDS = wordAndOneKS.sum(1);
// TODO 4.输出数据
sumDS.print();
// TODO 5.执行:类似 sparkstreaming最后 ssc.start()
env.execute();
}
}
/**
* 接口 A,里面有一个方法a()
* 1、正常实现接口步骤:
* <p>
* 1.1 定义一个class B 实现 接口A、方法a()
* 1.2 创建B的对象: B b = new B()
* <p>
* <p>
* 2、接口的匿名实现类:
* new A(){
* a(){
* <p>
* }
* }
*/ 
无界流
package com.atguigu.wc;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* TODO DataStream实现Wordcount:读socket(无界流)
*
* @author cjp
* @version 1.0
*/
public class WordCountStreamUnboundedDemo {
public static void main(String[] args) throws Exception {
// TODO 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// IDEA运行时,也可以看到webui,一般用于本地测试
// 需要引入一个依赖 flink-runtime-web
// 在idea运行,不指定并行度,默认就是 电脑的 线程数
// StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(3);
// TODO 2. 读取数据: socket
DataStreamSource<String> socketDS = env.socketTextStream("hadoop102", 7777);
// TODO 3. 处理数据: 切换、转换、分组、聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socketDS
.flatMap(
(String value, Collector<Tuple2<String, Integer>> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
)
.setParallelism(2)
.returns(Types.TUPLE(Types.STRING,Types.INT))
// .returns(new TypeHint<Tuple2<String, Integer>>() {})
.keyBy(value -> value.f0)
.sum(1);
// TODO 4. 输出
sum.print();
// TODO 5. 执行
env.execute();
}
}
/**
并行度的优先级:
代码:算子 > 代码:env > 提交时指定 > 配置文件
*/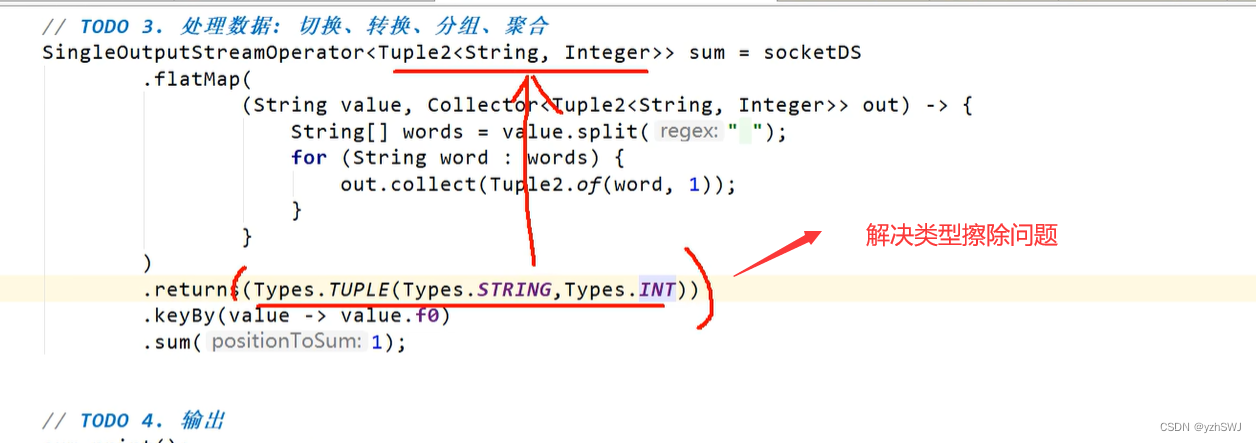
socket 发送数据
Flink部署


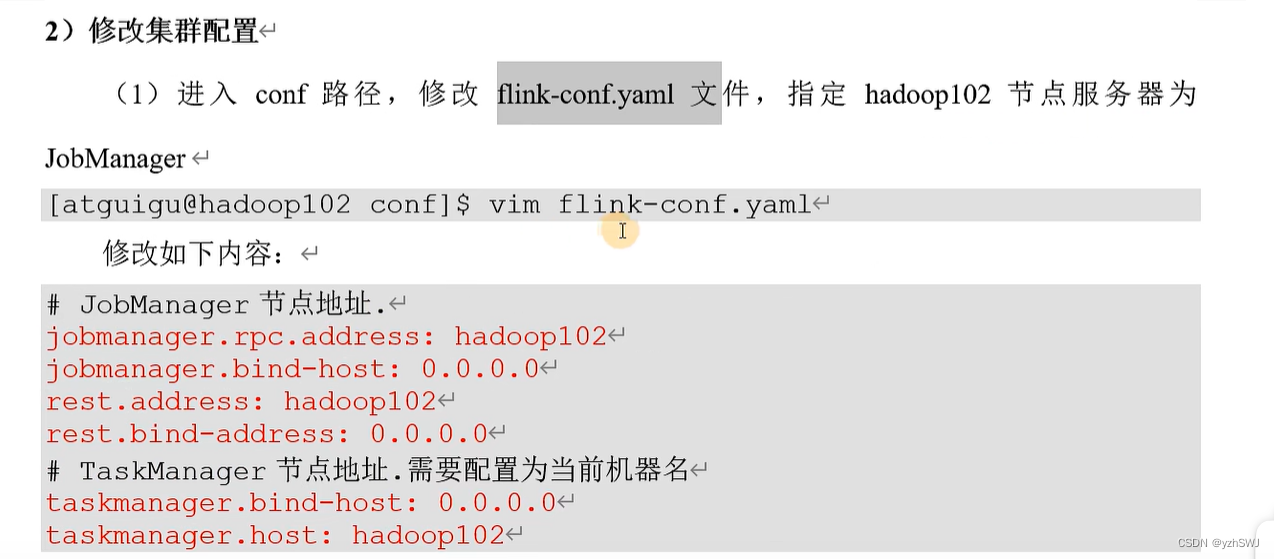


3)分发安装目录
(1)配置修改完毕后,将Flink安装目录发给另外两个节点服务器。
[atguigu@hadoop102 module]$ xsync flink-1.17.0/
(2)修改hadoop103的 taskmanager.host
[atguigu@hadoop103 conf]$ vim flink-conf.yaml
修改如下内容:
# TaskManager节点地址.需要配置为当前机器名
taskmanager.host: hadoop103
(3)修改hadoop104的 taskmanager.host
[atguigu@hadoop104 conf]$ vim flink-conf.yaml
修改如下内容:
# TaskManager节点地址.需要配置为当前机器名
taskmanager.host: hadoop104
(4)另外,在flink-conf.yaml文件中还可以对集群中的JobManager和TaskManager组件进行优化配置,主要配置项如下:
- jobmanager.memory.process.size:对JobManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1600M,可以根据集群规模进行适当调整。
- taskmanager.memory.process.size:对TaskManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1728M,可以根据集群规模进行适当调整。
- taskmanager.numberOfTaskSlots:对每个TaskManager能够分配的Slot数量进行配置,默认为1,可根据TaskManager所在的机器能够提供给Flink的CPU数量决定。所谓Slot就是TaskManager中具体运行一个任务所分配的计算资源。
- parallelism.default:Flink任务执行的并行度,默认为1。优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。
关于Slot和并行度的概念,我们会在下一章做详细讲解。
4)启动集群
(1)在hadoop102节点服务器上执行start-cluster.sh启动Flink集群:
[atguigu@hadoop102 flink-1.17.0]$ bin/start-cluster.sh
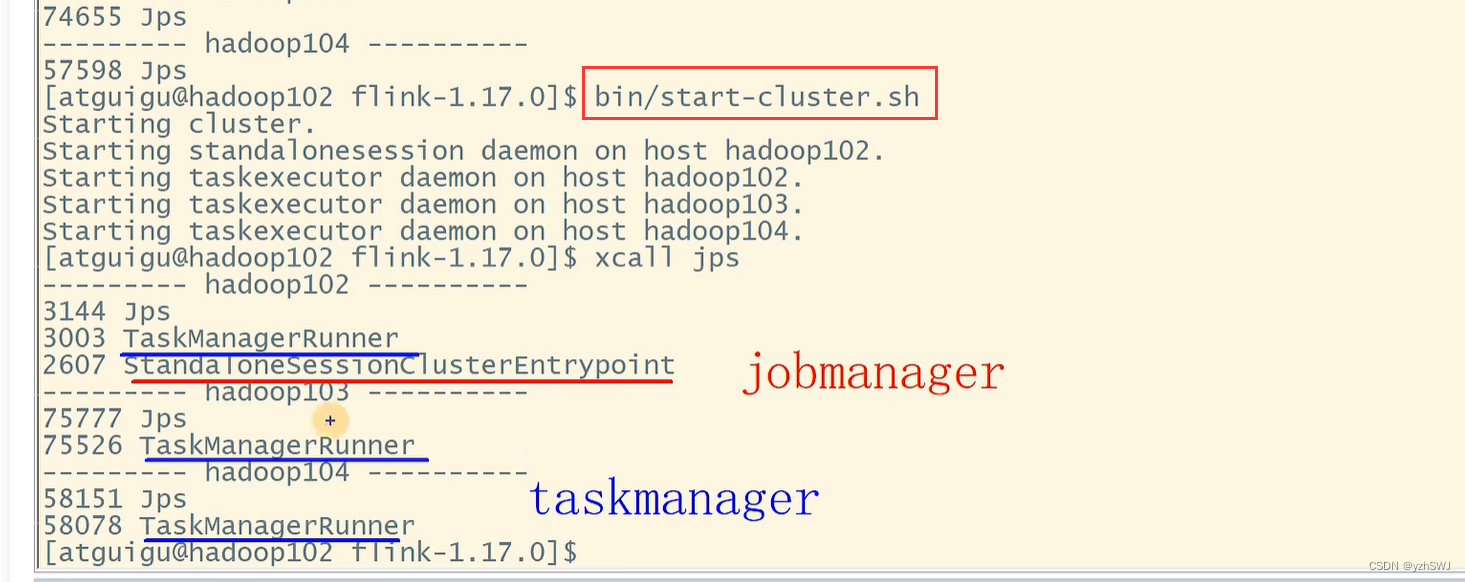
(2)查看进程情况:
[atguigu@hadoop102 flink-1.17.0]$ jpsall
=============== hadoop102 ===============
4453 StandaloneSessionClusterEntrypoint
4458 TaskManagerRunner
4533 Jps
=============== hadoop103 ===============
2872 TaskManagerRunner
2941 Jps
=============== hadoop104 ===============
2948 Jps
2876 TaskManagerRunner
5)访问Web UI
启动成功后,同样可以访问http://hadoop102:8081对flink集群和任务进行监控管理。
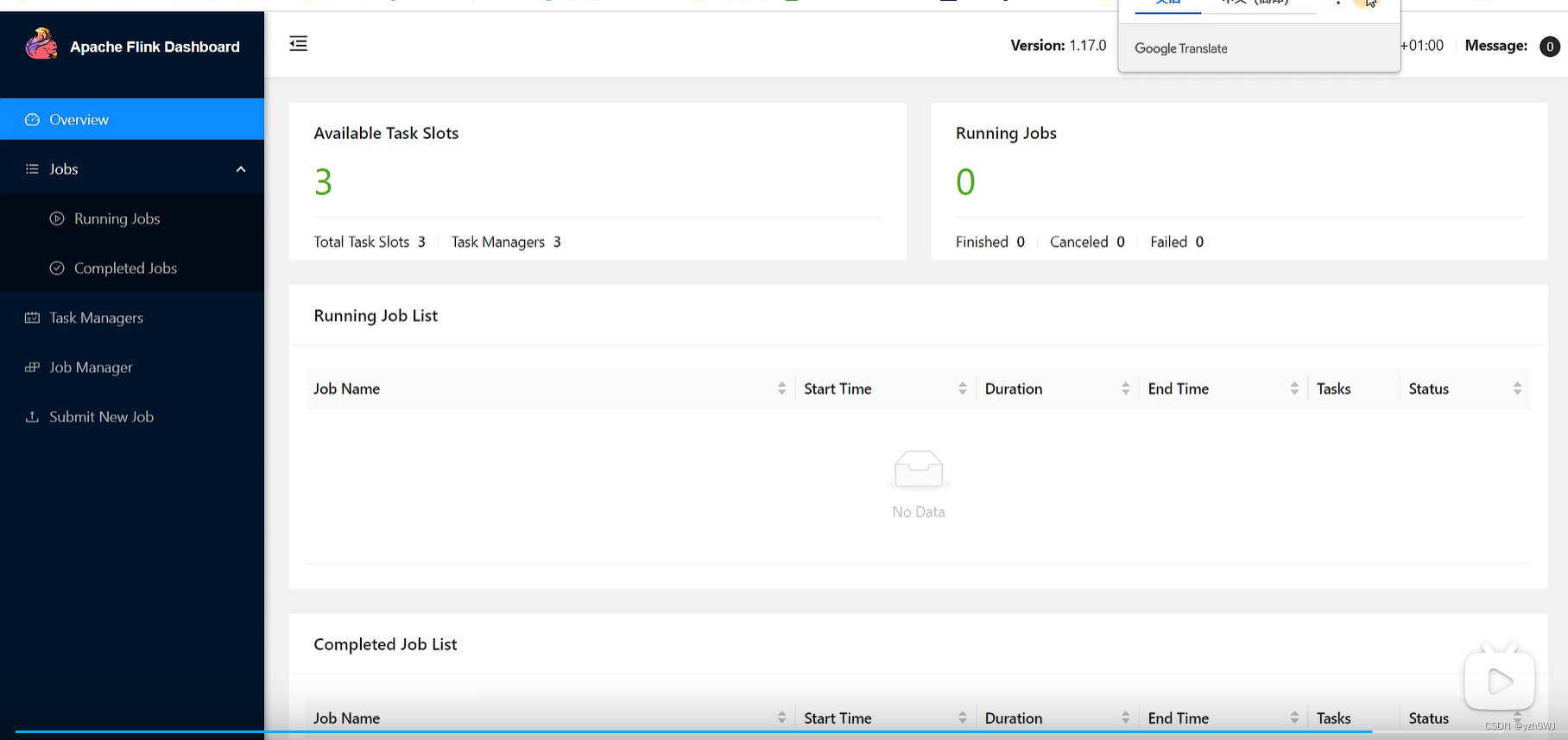
这里可以明显看到,当前集群的TaskManager数量为3;由于默认每个TaskManager的Slot数量为1,所以总Slot数和可用Slot数都为3。
3.2.2 向集群提交作业
在上一章中,我们已经编写读取socket发送的单词并统计单词的个数程序案例。本节我们将以该程序为例,演示如何将任务提交到集群中进行执行。具体步骤如下。
1)环境准备
在hadoop102中执行以下命令启动netcat。(scoket发送消息)
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
2)程序打包
(1)在我们编写的Flink入门程序的pom.xml文件中添加打包插件的配置,具体如下:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers combine.children="append">
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer">
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
(2)插件配置完毕后,可以使用IDEA的Maven工具执行package命令,出现如下提示即表示打包成功。
打包完成后,在target目录下即可找到所需JAR包,JAR包会有两个,FlinkTutorial-1.0-SNAPSHOT.jar和FlinkTutorial-1.0-SNAPSHOT-jar-with-dependencies.jar,因为集群中已经具备任务运行所需的所有依赖,所以建议使用FlinkTutorial-1.0-SNAPSHOT.jar。
3)在Web UI上提交作业
(1)任务打包完成后,我们打开Flink的WEB UI页面,在右侧导航栏点击“Submit New
Job”,然后点击按钮“+ Add New”,选择要上传运行的JAR包,如下图所示。
JAR包上传完成,如下图所示:
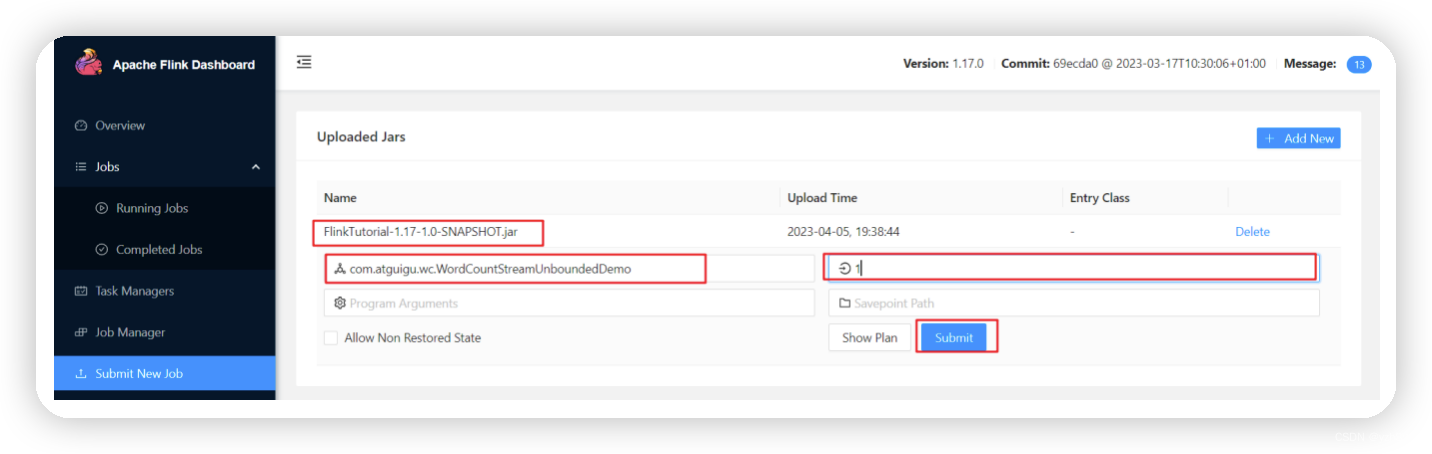
(2)点击该JAR包,出现任务配置页面,进行相应配置。
主要配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点路径等,如下图所示,配置完成后,即可点击按钮“Submit”,将任务提交到集群运行。
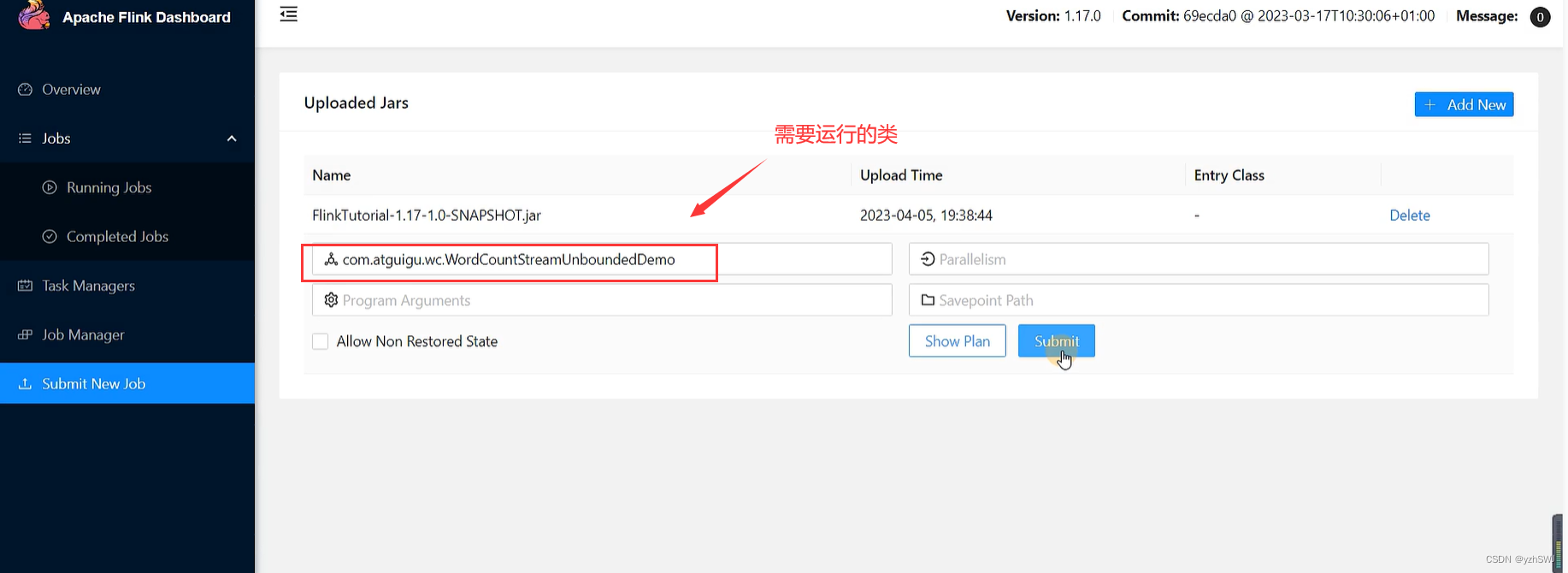
(3)任务提交成功之后,可点击左侧导航栏的“Running Jobs”查看程序运行列表情况。
(4)测试
①在socket端口中输入hello
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
hello
②先点击Task Manager,然后点击右侧的192.168.10.104服务器节点
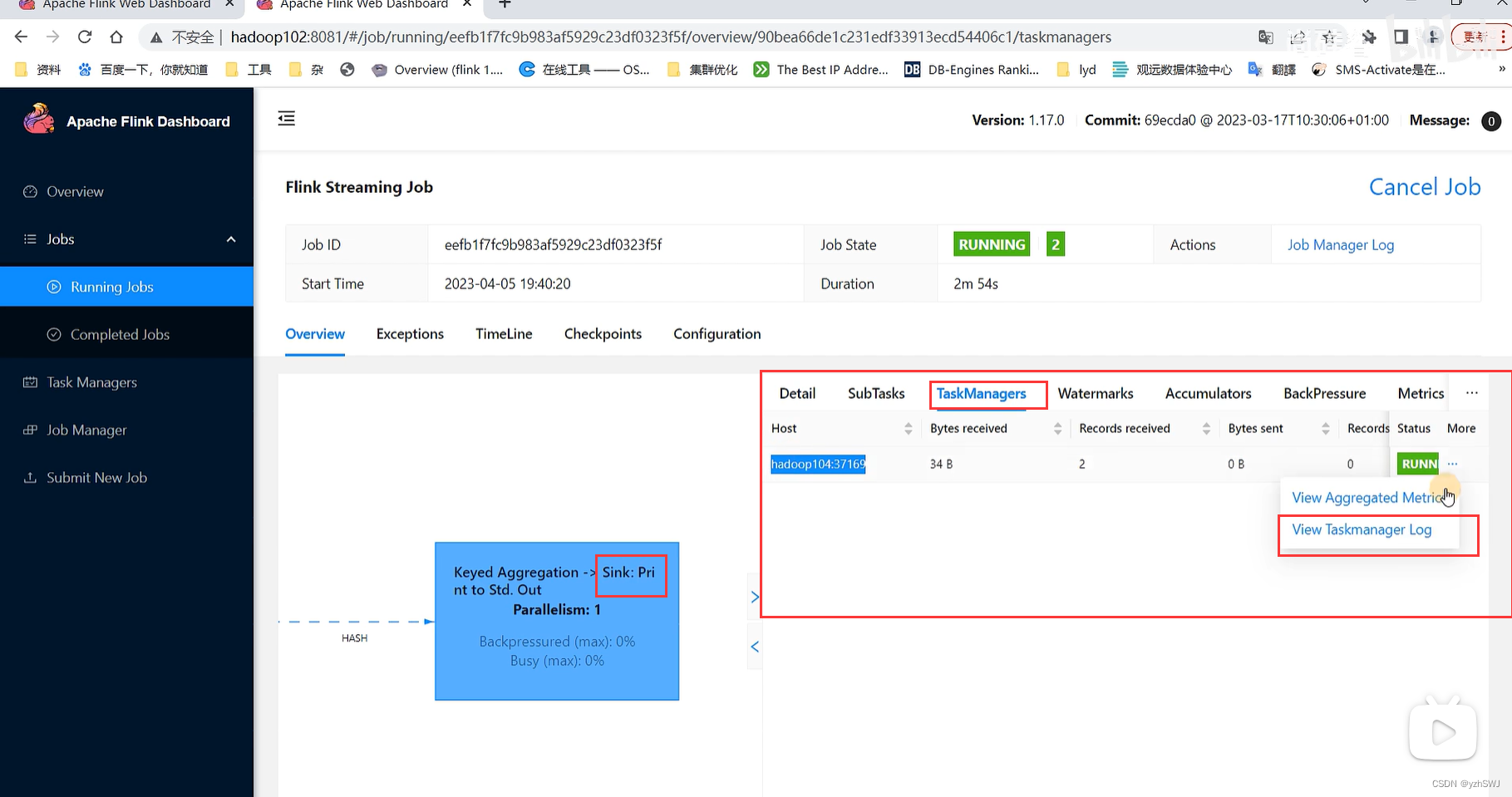
③点击Stdout,就可以看到hello单词的统计
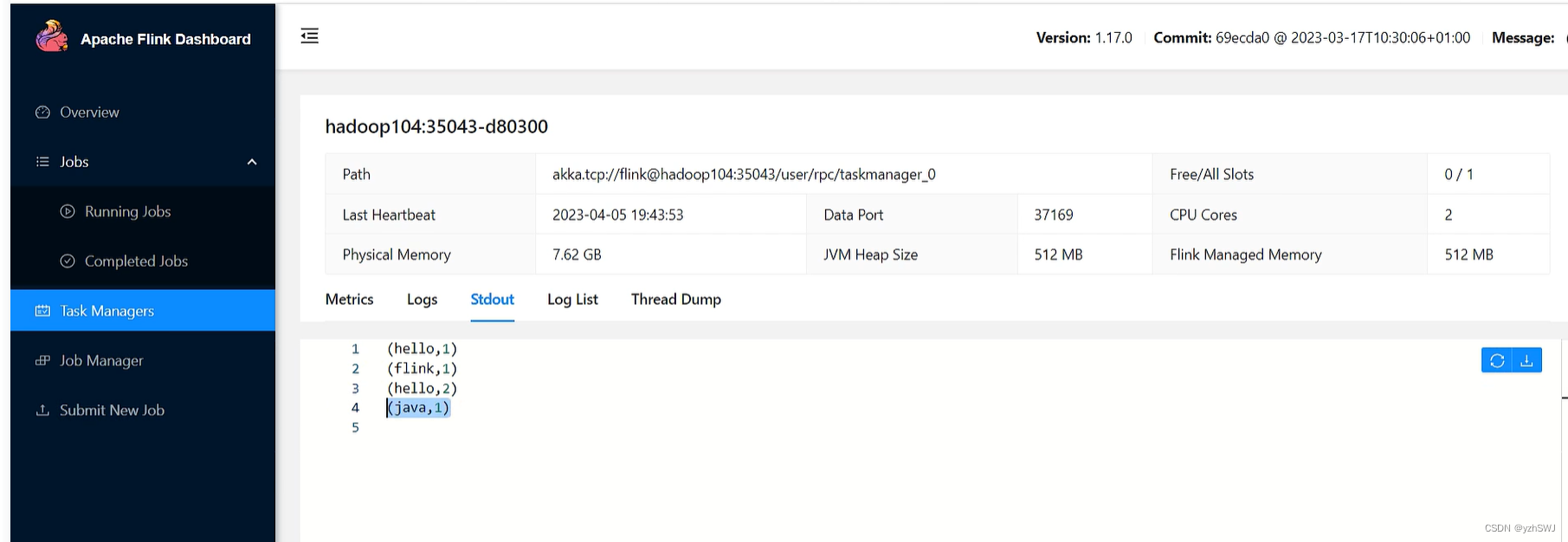
注意:如果hadoop104节点没有统计单词数据,可以去其他TaskManager节点查看。
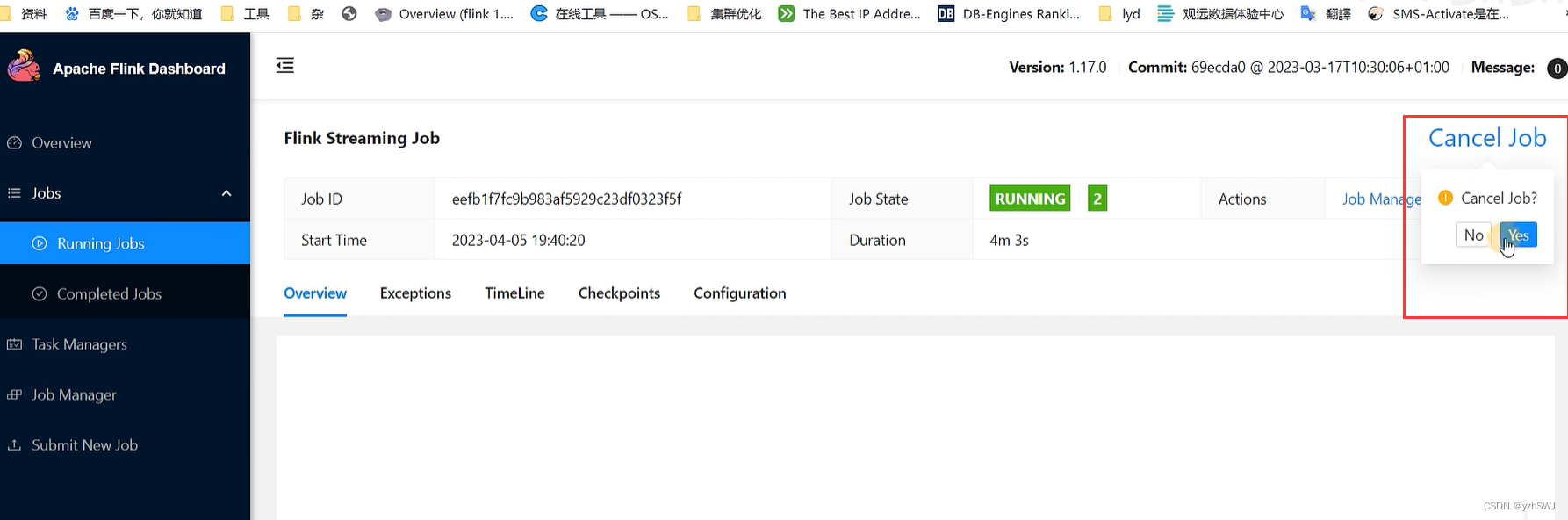
(4)点击该任务,可以查看任务运行的具体情况,也可以通过点击“Cancel Job”结束任务运行。
4)命令行提交作业
除了通过WEB UI界面提交任务之外,也可以直接通过命令行来提交任务。这里为方便起见,我们可以先把jar包直接上传到目录flink-1.17.0下
(1)首先需要启动集群。
[atguigu@hadoop102 flink-1.17.0]$ bin/start-cluster.sh
(2)在hadoop102中执行以下命令启动netcat。
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
(3)将flink程序运行jar包上传到/opt/module/flink-1.17.0路径。
(4)进入到flink的安装路径下,在命令行使用flink run命令提交作业。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run -m hadoop102:8081 -c com.atguigu.wc.SocketStreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
这里的参数 -m指定了提交到的JobManager,-c指定了入口类。
(5)在浏览器中打开Web UI,http://hadoop102:8081查看应用执行情况。
用netcat输入数据,可以在TaskManager的标准输出(Stdout)看到对应的统计结果。
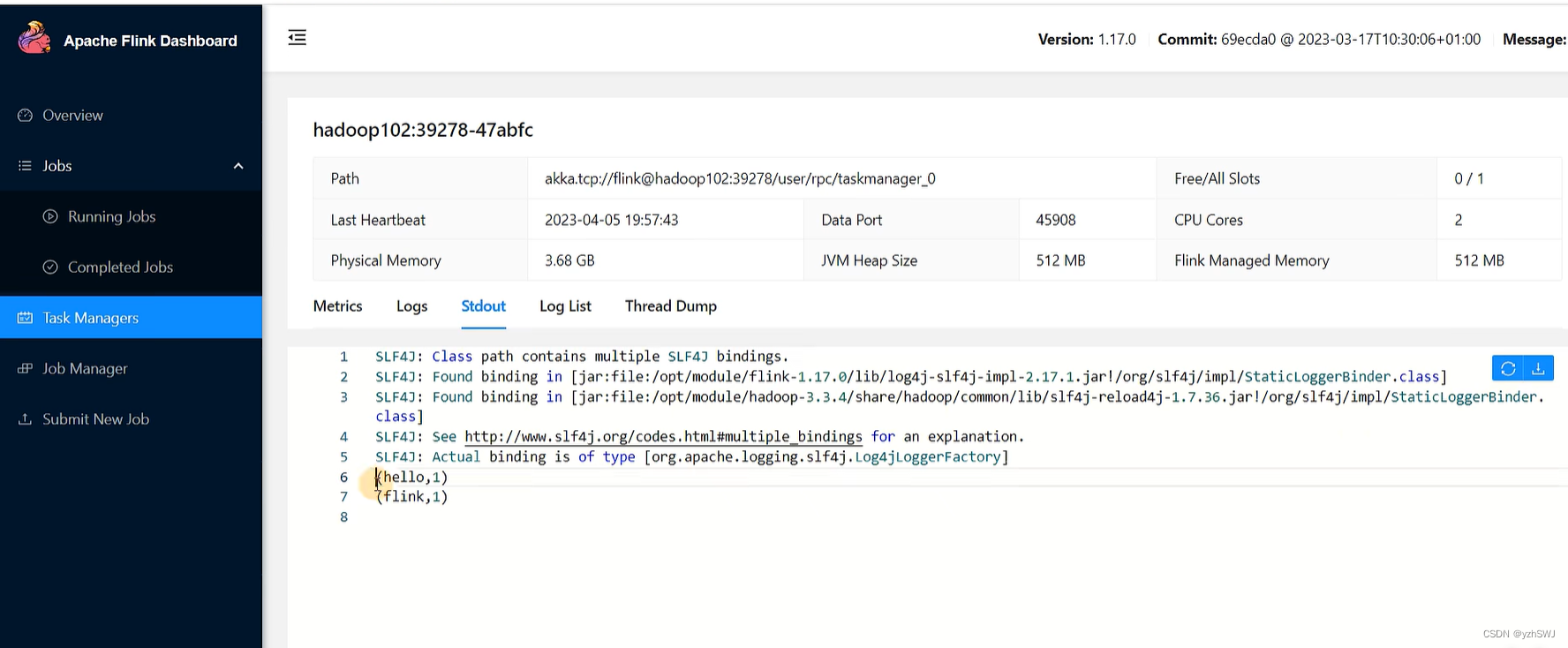
(6)在/opt/module/flink-1.17.0/log路径中,可以查看TaskManager节点。
[atguigu@hadoop102 log]$ cat flink-atguigu-standalonesession-0-hadoop102.out
(hello,1)
(hello,2)
(flink,1)
(hello,3)
(scala,1)
部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink为各种场景提供了不同的部署模式,主要有以下三种:会话模式(Session Mode)、单作业模式(Per-Job Mode)、应用模式(Application Mode)。
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的main方法到底在哪里执行——客户端(Client)还是JobManager。
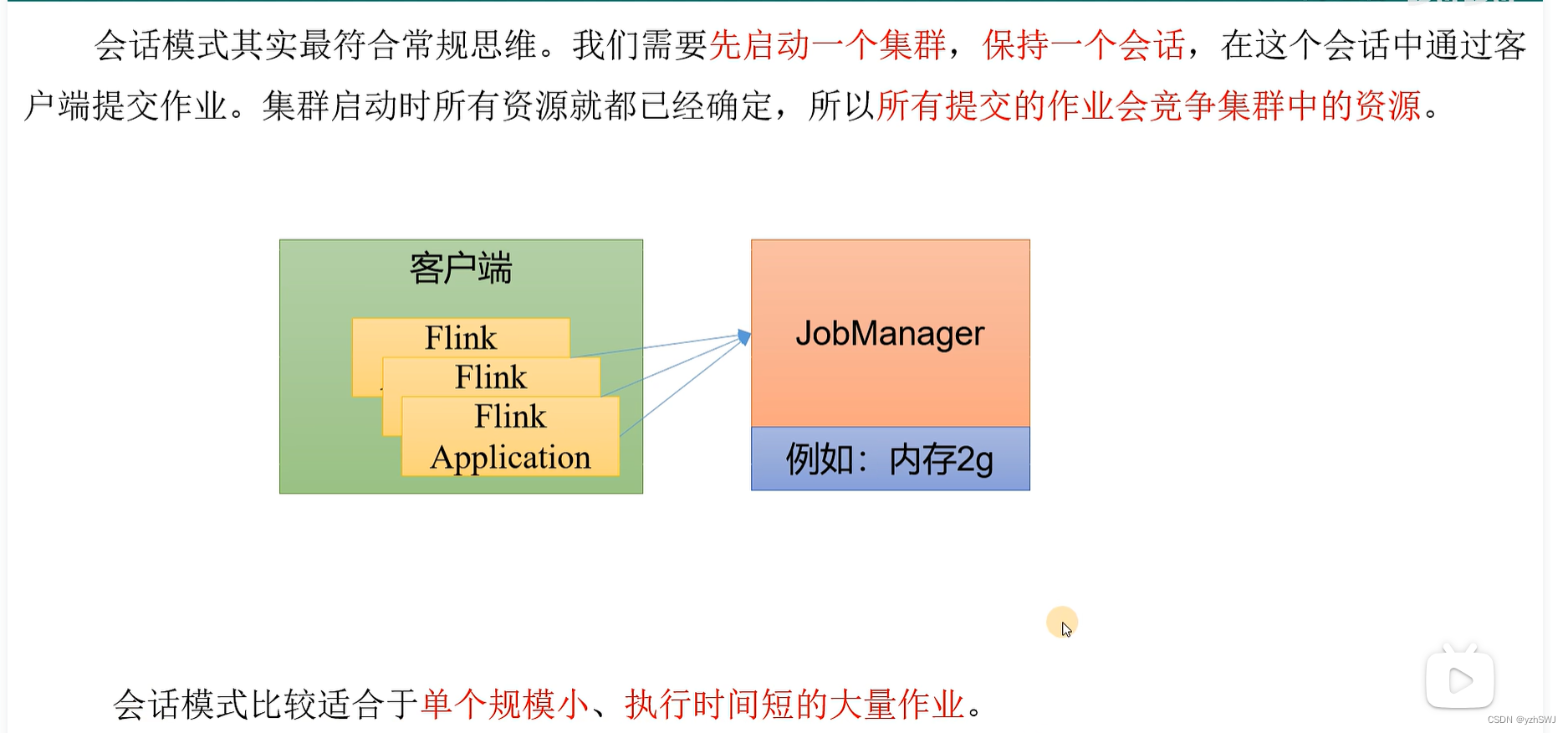
3.3.1 会话模式(Session Mode)
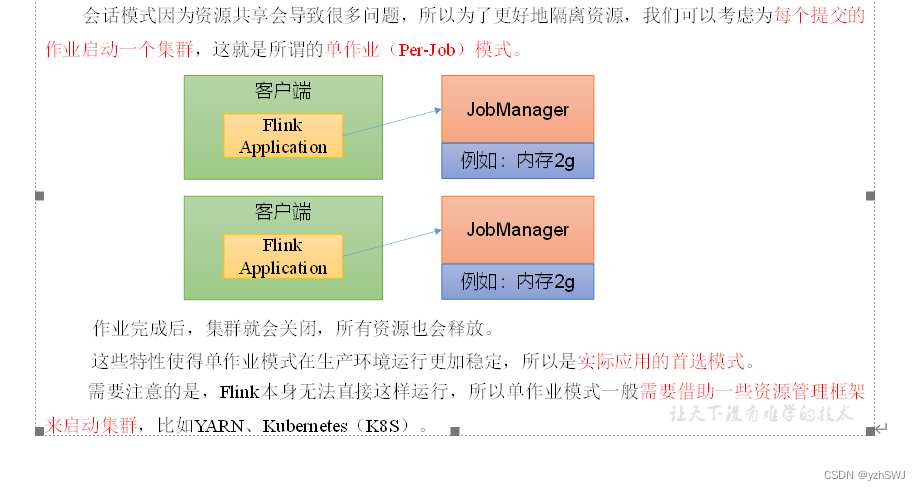
3.3.2 单作业模式(Per-Job Mode)
3.3.3 应用模式(Application Mode)


3.4.1 会话模式部署
我们在第3.2节用的就是Standalone集群的会话模式部署。
提前启动集群,并通过Web页面客户端提交任务(可以多个任务,但是集群资源固定)。
3.4.2 单作业模式部署
Flink的Standalone集群并不支持单作业模式部署。因为单作业模式需要借助一些资源管理平台。
3.4.3 应用模式部署
应用模式下不会提前创建集群,所以不能调用start-cluster.sh脚本。我们可以使用同样在bin目录下的standalone-job.sh来创建一个JobManager。
具体步骤如下:
(0)环境准备。在hadoop102中执行以下命令启动netcat。
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
(1)进入到Flink的安装路径下,将应用程序的jar包放到lib/目录下。
[atguigu@hadoop102 flink-1.17.0]$ mv FlinkTutorial-1.0-SNAPSHOT.jar lib/
(2)执行以下命令,启动JobManager。
[atguigu@hadoop102 flink-1.17.0]$ bin/standalone-job.sh start --job-classname com.atguigu.wc.SocketStreamWordCount
这里我们直接指定作业入口类,脚本会到lib目录扫描所有的jar包。
(3)同样是使用bin目录下的脚本,启动TaskManager。
[atguigu@hadoop102 flink-1.17.0]$ bin/taskmanager.sh start
(4)在hadoop102上模拟发送单词数据。
[atguigu@hadoop102 ~]$ nc -lk 7777
hello
(5)在hadoop102:8081地址中观察输出数据
(6)如果希望停掉集群,同样可以使用脚本,命令如下。
[atguigu@hadoop102 flink-1.17.0]$ bin/taskmanager.sh stop
[atguigu@hadoop102 flink-1.17.0]$ bin/standalone-job.sh stop
3.5 YARN运行模式(重点)
YARN上部署的过程是:客户端把Flink应用提交给Yarn的ResourceManager,Yarn的ResourceManager会向Yarn的NodeManager申请容器。在这些容器上,Flink会部署JobManager和TaskManager的实例,从而启动集群。Flink会根据运行在JobManger上的作业所需要的Slot数量动态分配TaskManager资源。
3.5.1 相关准备和配置
在将Flink任务部署至YARN集群之前,需要确认集群是否安装有Hadoop,保证Hadoop版本至少在2.2以上,并且集群中安装有HDFS服务。
具体配置步骤如下:
(1)配置环境变量,增加环境变量配置如下:
$ sudo vim /etc/profile.d/my_env.sh
HADOOP_HOME=/opt/module/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
注意这个地方`` 是 tab上面的飘号,在shell种表示执行命令符号,表示执行了 hadopp 空格 classpath 命令
export HADOOP_CLASSPATH=`hadoop classpath`
(2)启动Hadoop集群,包括HDFS和YARN。
[atguigu@hadoop102 hadoop-3.3.4]$ start-dfs.sh
[atguigu@hadoop103 hadoop-3.3.4]$ start-yarn.sh
(3)在hadoop102中执行以下命令启动netcat。
[atguigu@hadoop102 flink-1.17.0]$ nc -lk 7777
3.5.2 会话模式部署
YARN的会话模式与独立集群略有不同,需要首先申请一个YARN会话(YARN Session)来启动Flink集群。具体步骤如下:
1)启动集群
(1)启动Hadoop集群(HDFS、YARN)。
(2)执行脚本命令向YARN集群申请资源,开启一个YARN会话,启动Flink集群。
[atguigu@hadoop102 flink-1.17.0]$ bin/yarn-session.sh -nm test
可用参数解读:
- -d:分离模式,如果你不想让Flink YARN客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session也可以后台运行。
- -jm(--jobManagerMemory):配置JobManager所需内存,默认单位MB。
- -nm(--name):配置在YARN UI界面上显示的任务名。
- -qu(--queue):指定YARN队列名。
- -tm(--taskManager):配置每个TaskManager所使用内存。
注意:Flink1.11.0版本不再使用-n参数和-s参数分别指定TaskManager数量和slot数量,YARN会按照需求动态分配TaskManager和slot。所以从这个意义上讲,YARN的会话模式也不会把集群资源固定,同样是动态分配的。
YARN Session启动之后会给出一个Web UI地址以及一个YARN application ID,如下所示,用户可以通过Web UI或者命令行两种方式提交作业。
2022-11-17 15:20:52,711 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop104:40825 of application 'application_1668668287070_0005'.
JobManager Web Interface: http://hadoop104:40825
2)提交作业
(1)通过Web UI提交作业
这种方式比较简单,与上文所述Standalone部署模式基本相同。
2)通过命令行提交作业
① 将FlinkTutorial-1.0-SNAPSHOT.jar任务上传至集群。
② 执行以下命令将该任务提交到已经开启的Yarn-Session中运行。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run
-c com.atguigu.wc.SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
客户端可以自行确定JobManager的地址,也可以通过-m或者-jobmanager参数指定JobManager的地址,JobManager的地址在YARN Session的启动页面中可以找到。
③ 任务提交成功后,可在YARN的Web UI界面查看运行情况。hadoop103:8088。
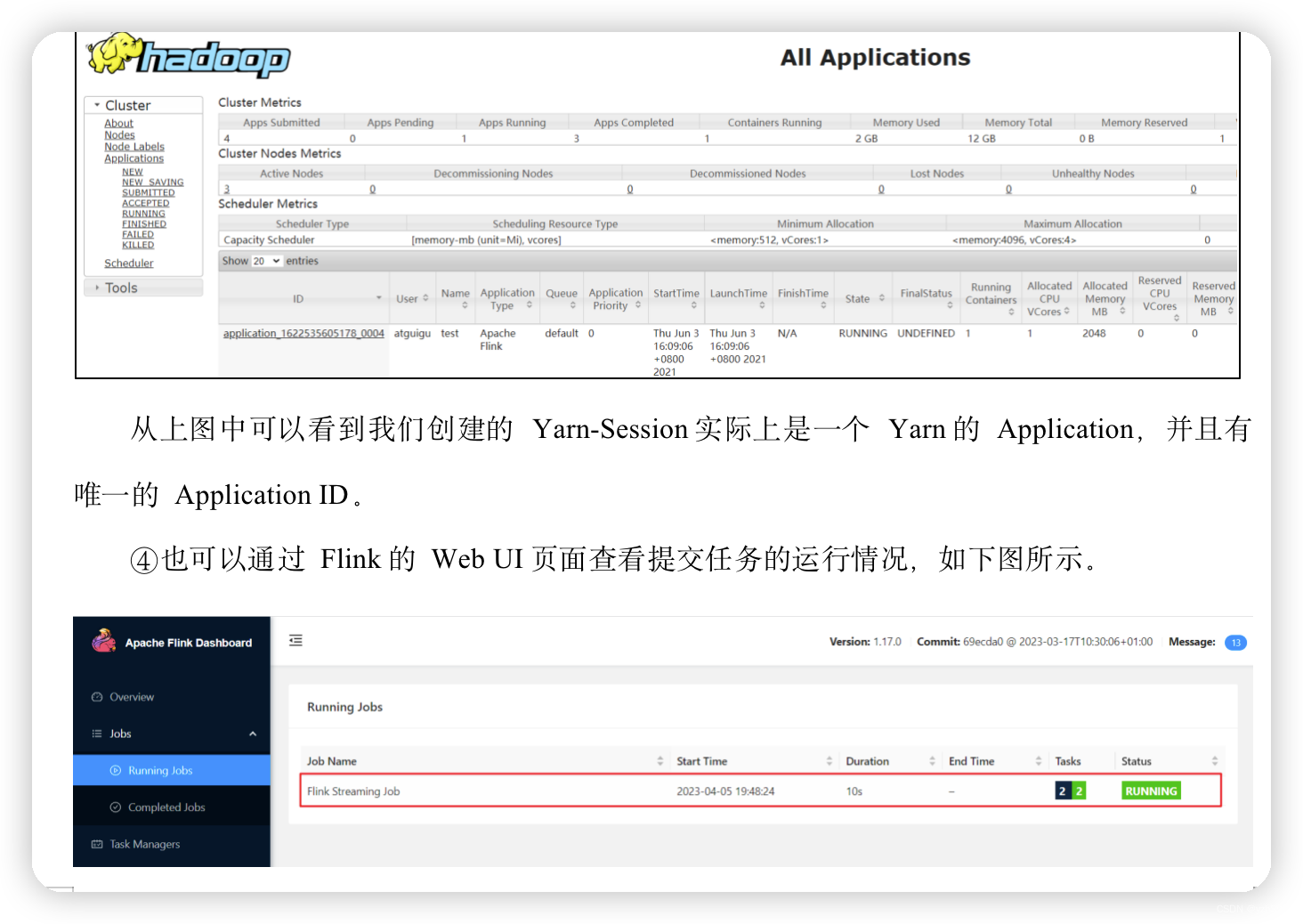
3.5.3 单作业模式部署
在YARN环境中,由于有了外部平台做资源调度,所以我们也可以直接向YARN提交一个单独的作业,从而启动一个Flink集群。
(1)执行命令提交作业。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run -d -t yarn-per-job -c com.atguigu.wc.SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
注意:如果启动过程中报如下异常。
Exception in thread “Thread-5” java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration ‘classloader.check-leaked-classloader’.
at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders
解决办法:在flink的/opt/module/flink-1.17.0/conf/flink-conf.yaml配置文件中设置
[atguigu@hadoop102 conf]$ vim flink-conf.yaml
classloader.check-leaked-classloader: false
(2)在YARN的ResourceManager界面查看执行情况。
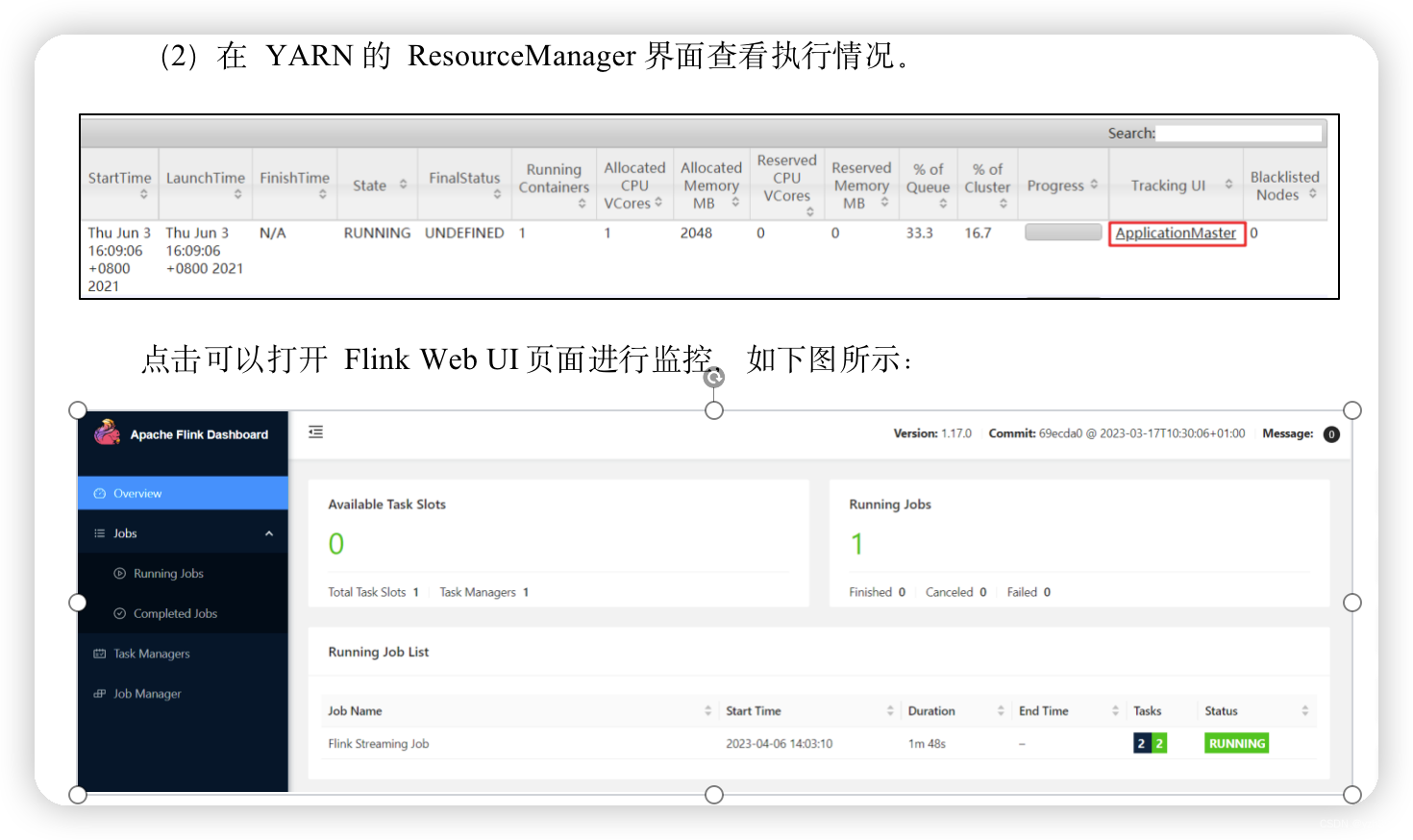
(3)可以使用命令行查看或取消作业,命令如下。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
[atguigu@hadoop102 flink-1.17.0]$ bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>
这里的application_XXXX_YY是当前应用的ID,<jobId>是作业的ID。注意如果取消作业,整个Flink集群也会停掉。
3.5.4 应用模式部署
应用模式同样非常简单,与单作业模式类似,直接执行flink run-application命令即可。
1)命令行提交
(1)执行命令提交作业。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run-application -t yarn-application -c com.atguigu.wc.SocketStreamWordCount FlinkTutorial-1.0-SNAPSHOT.jar
(2)在命令行中查看或取消作业。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
[atguigu@hadoop102 flink-1.17.0]$ bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>
2)上传HDFS提交
可以通过yarn.provided.lib.dirs配置选项指定位置,将flink的依赖上传到远程。
(1)上传flink的lib和plugins到HDFS上
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -mkdir /flink-dist
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -put lib/ /flink-dist
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -put plugins/ /flink-dist
(2)上传自己的jar包到HDFS
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -mkdir /flink-jars
[atguigu@hadoop102 flink-1.17.0]$ hadoop fs -put FlinkTutorial-1.0-SNAPSHOT.jar /flink-jars
(3)提交作业
[atguigu@hadoop102 flink-1.17.0]$ bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://hadoop102:8020/flink-dist" -c com.atguigu.wc.SocketStreamWordCount hdfs://hadoop102:8020/flink-jars/FlinkTutorial-1.0-SNAPSHOT.jar
这种方式下,flink本身的依赖和用户jar可以预先上传到HDFS,而不需要单独发送到集群,这就使得作业提交更加轻量了。
3.6 K8S 运行模式(了解)
容器化部署是如今业界流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(k8s),而Flink也在最近的版本中支持了k8s部署模式。基本原理与YARN是类似的,具体配置可以参见官网说明,这里我们就不做过多讲解了。
3.7 历史服务器
运行 Flink job 的集群一旦停止,只能去 yarn 或本地磁盘上查看日志,不再可以查看作业挂掉之前的运行的 Web UI,很难清楚知道作业在挂的那一刻到底发生了什么。如果我们还没有 Metrics 监控的话,那么完全就只能通过日志去分析和定位问题了,所以如果能还原之前的 Web UI,我们可以通过 UI 发现和定位一些问题。
Flink提供了历史服务器,用来在相应的 Flink 集群关闭后查询已完成作业的统计信息。我们都知道只有当作业处于运行中的状态,才能够查看到相关的WebUI统计信息。通过 History Server 我们才能查询这些已完成作业的统计信息,无论是正常退出还是异常退出。
此外,它对外提供了 REST API,它接受 HTTP 请求并使用 JSON 数据进行响应。Flink 任务停止后,JobManager 会将已经完成任务的统计信息进行存档,History Server 进程则在任务停止后可以对任务统计信息进行查询。比如:最后一次的 Checkpoint、任务运行时的相关配置。
1)创建存储目录
hadoop fs -mkdir -p /logs/flink-job
2)在 flink-config.yaml中添加如下配置
jobmanager.archive.fs.dir: hdfs://hadoop102:8020/logs/flink-job
historyserver.web.address: hadoop102
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://hadoop102:8020/logs/flink-job
historyserver.archive.fs.refresh-interval: 5000
3)启动历史服务器
bin/historyserver.sh start
4)停止历史服务器
bin/historyserver.sh stop
5)在浏览器地址栏输入:http://hadoop102:8082 查看已经停止的 job 的统计信息
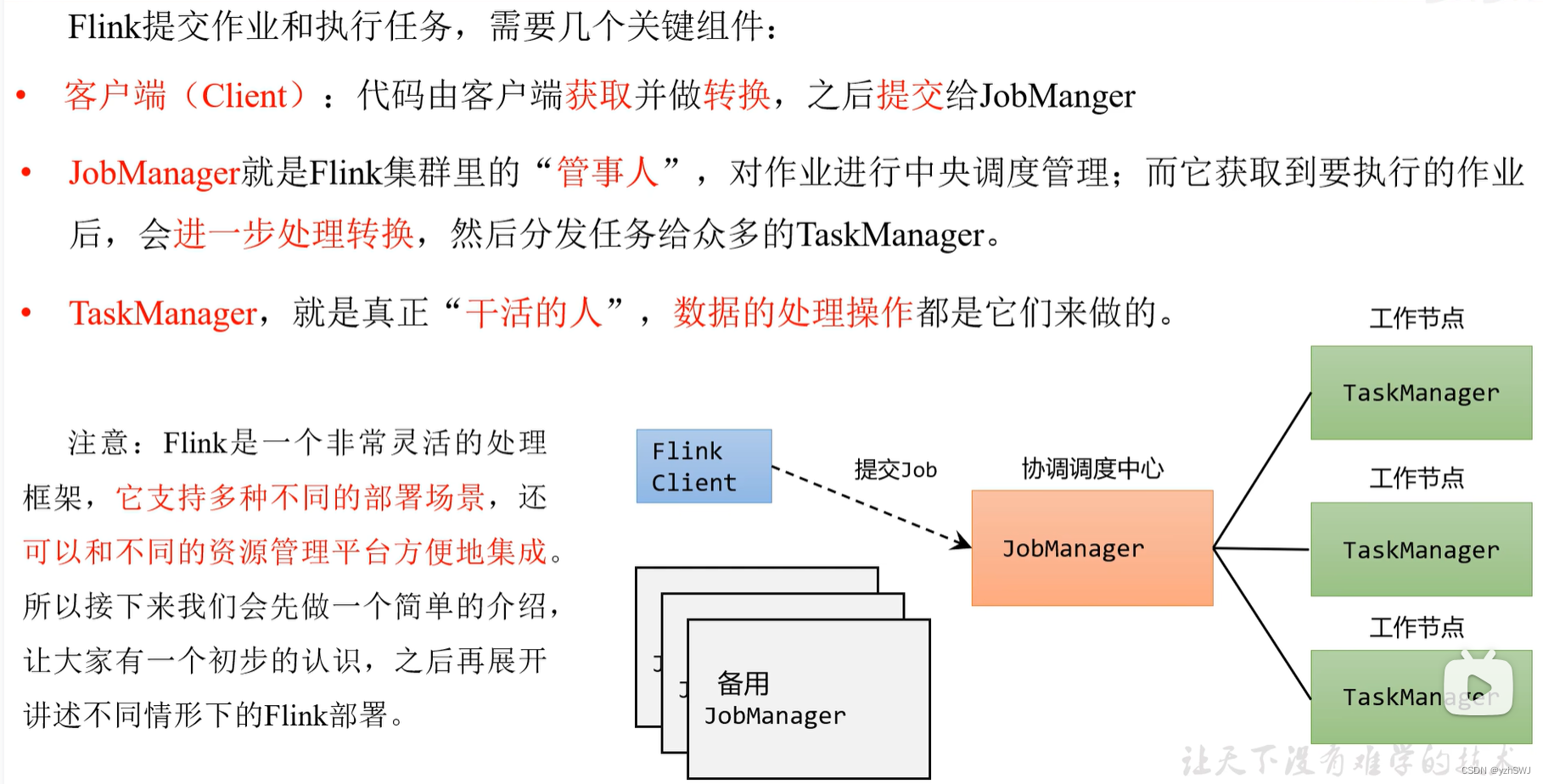
第4章 Flink运行时架构
4.1 系统架构
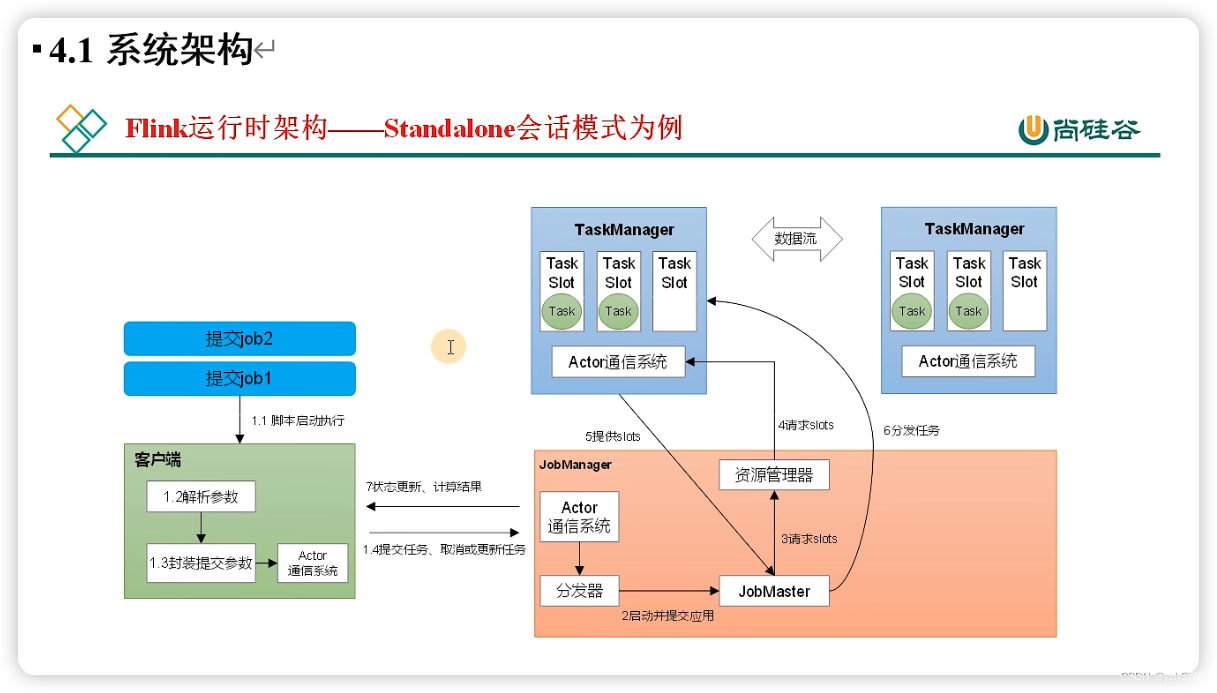
1)作业管理器(JobManager)
JobManager是一个Flink集群中任务管理和调度的核心,是控制应用执行的主进程。也就是说,每个应用都应该被唯一的JobManager所控制执行。
JobManger又包含3个不同的组件。
(1)JobMaster
JobMaster是JobManager中最核心的组件,负责处理单独的作业(Job)。所以JobMaster和具体的Job是一一对应的,多个Job可以同时运行在一个Flink集群中, 每个Job都有一个自己的JobMaster。需要注意在早期版本的Flink中,没有JobMaster的概念;而JobManager的概念范围较小,实际指的就是现在所说的JobMaster。
在作业提交时,JobMaster会先接收到要执行的应用。JobMaster会把JobGraph转换成一个物理层面的数据流图,这个图被叫作“执行图”(ExecutionGraph),它包含了所有可以并发执行的任务。JobMaster会向资源管理器(ResourceManager)发出请求,申请执行任务必要的资源。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的TaskManager上。
而在运行过程中,JobMaster会负责所有需要中央协调的操作,比如说检查点(checkpoints)的协调。
(2)资源管理器(ResourceManager)
ResourceManager主要负责资源的分配和管理,在Flink 集群中只有一个。所谓“资源”,主要是指TaskManager的任务槽(task slots)。任务槽就是Flink集群中的资源调配单元,包含了机器用来执行计算的一组CPU和内存资源。每一个任务(Task)都需要分配到一个slot上执行。
这里注意要把Flink内置的ResourceManager和其他资源管理平台(比如YARN)的ResourceManager区分开。
(3)分发器(Dispatcher)
Dispatcher主要负责提供一个REST接口,用来提交应用,并且负责为每一个新提交的作业启动一个新的JobMaster 组件。Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。Dispatcher在架构中并不是必需的,在不同的部署模式下可能会被忽略掉。
2)任务管理器(TaskManager)
TaskManager是Flink中的工作进程,数据流的具体计算就是它来做的。Flink集群中必须至少有一个TaskManager;每一个TaskManager都包含了一定数量的任务槽(task slots)。Slot是资源调度的最小单位,slot的数量限制了TaskManager能够并行处理的任务数量。
启动之后,TaskManager会向资源管理器注册它的slots;收到资源管理器的指令后,TaskManager就会将一个或者多个槽位提供给JobMaster调用,JobMaster就可以分配任务来执行了。
在执行过程中,TaskManager可以缓冲数据,还可以跟其他运行同一应用的TaskManager交换数据。
4.2 核心概念
4.2.1 并行度(Parallelism)
1)并行子任务和并行度
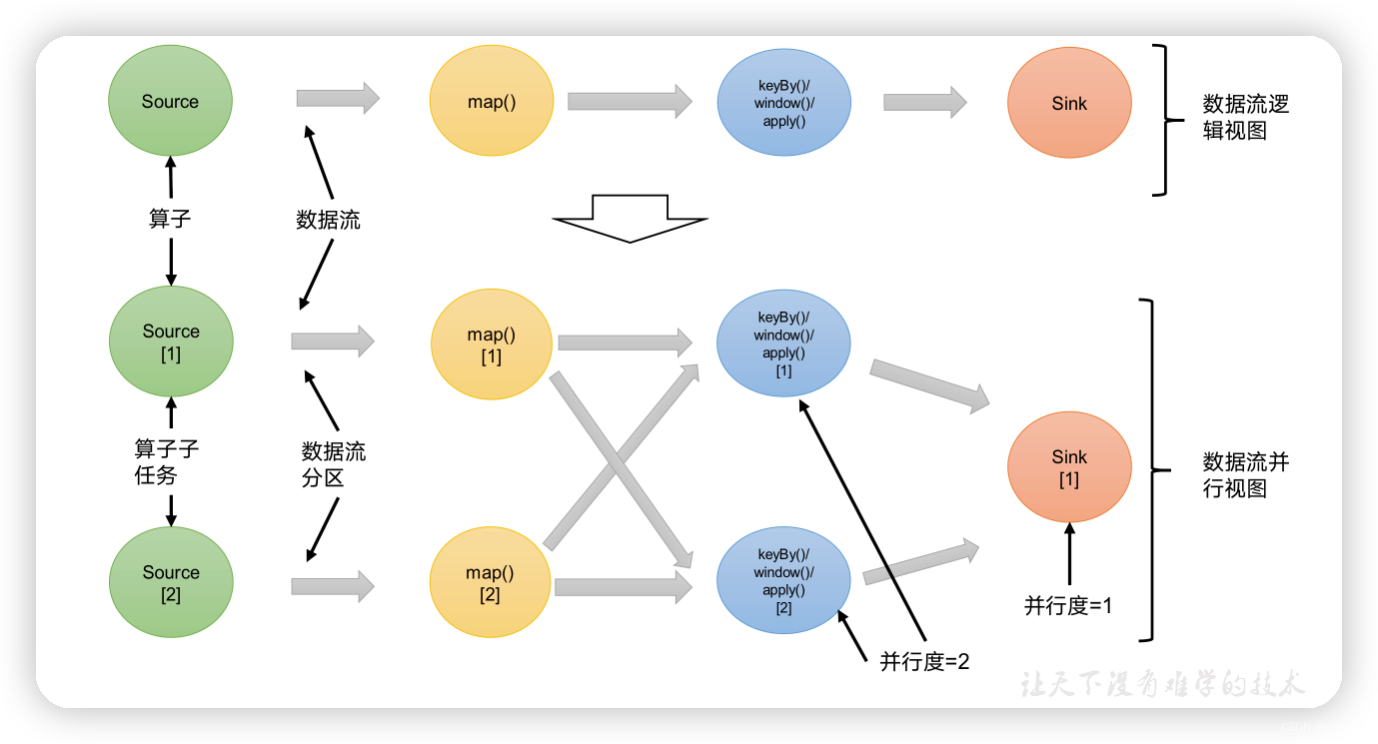
当要处理的数据量非常大时,我们可以把一个算子操作,“复制”多份到多个节点,数据来了之后就可以到其中任意一个执行。这样一来,一个算子任务就被拆分成了多个并行的“子任务”(subtasks),再将它们分发到不同节点,就真正实现了并行计算。
在Flink执行过程中,每一个算子(operator)可以包含一个或多个子任务(operator subtask),这些子任务在不同的线程、不同的物理机或不同的容器中完全独立地执行。
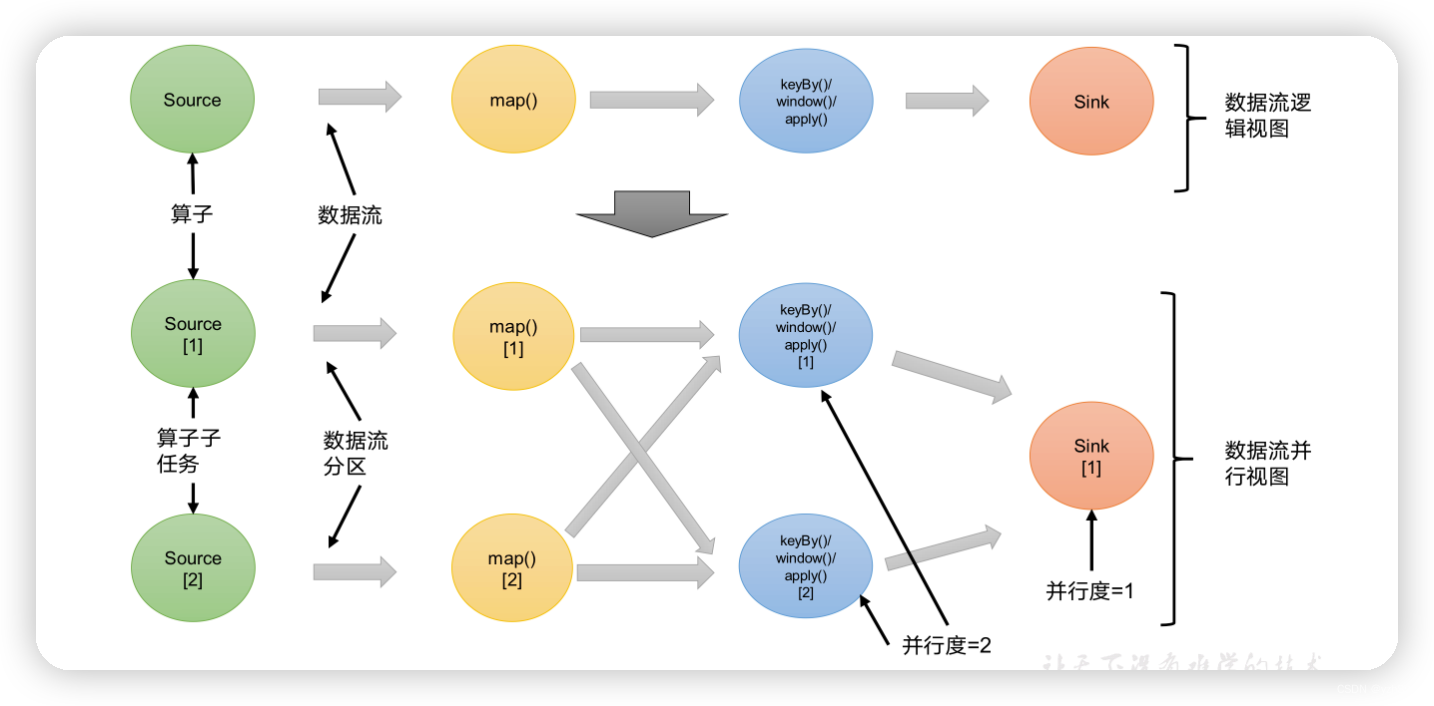
一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
例如:如上图所示,当前数据流中有source、map、window、sink四个算子,其中sink算子的并行度为1,其他算子的并行度都为2。所以这段流处理程序的并行度就是2。
2)并行度的设置
在Flink中,可以用不同的方法来设置并行度,它们的有效范围和优先级别也是不同的。
(1)代码中设置
我们在代码中,可以很简单地在算子后跟着调用setParallelism()方法,来设置当前算子的并行度:
stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2);
这种方式设置的并行度,只针对当前算子有效。
另外,我们也可以直接调用执行环境的setParallelism()方法,全局设定并行度:
env.setParallelism(2);
这样代码中所有算子,默认的并行度就都为2了。我们一般不会在程序中设置全局并行度,因为如果在程序中对全局并行度进行硬编码,会导致无法动态扩容。
这里要注意的是,由于keyBy不是算子,所以无法对keyBy设置并行度。
package com.atguigu.wc;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* TODO DataStream实现Wordcount:读socket(无界流)
*
* @author cjp
* @version 1.0
*/
public class WordCountStreamUnboundedDemo {
public static void main(String[] args) throws Exception {
// TODO 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// IDEA运行时,也可以看到webui,一般用于本地测试
// 需要引入一个依赖 flink-runtime-web
// 在idea运行,不指定并行度,默认就是 电脑的 线程数
// StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setParallelism(3);
// TODO 2. 读取数据: socket
DataStreamSource<String> socketDS = env.socketTextStream("hadoop102", 7777);
// TODO 3. 处理数据: 切换、转换、分组、聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socketDS
.flatMap(
(String value, Collector<Tuple2<String, Integer>> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}
)
.setParallelism(2)
.returns(Types.TUPLE(Types.STRING,Types.INT))
// .returns(new TypeHint<Tuple2<String, Integer>>() {})
.keyBy(value -> value.f0)
.sum(1);
// TODO 4. 输出
sum.print();
// TODO 5. 执行
env.execute();
}
}
/**
并行度的优先级:
代码:算子 > 代码:env > 提交时指定 > 配置文件
*/<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>web ui 访问 地址 ip+8081
(2)提交应用时设置
在使用flink run命令提交应用时,可以增加-p参数来指定当前应用程序执行的并行度,它的作用类似于执行环境的全局设置:
bin/flink run –p 2 –c com.atguigu.wc.SocketStreamWordCount
./FlinkTutorial-1.0-SNAPSHOT.jar
如果我们直接在Web UI上提交作业,也可以在对应输入框中直接添加并行度。
(3)配置文件中设置
我们还可以直接在集群的配置文件flink-conf.yaml中直接更改默认并行度:
parallelism.default: 2
这个设置对于整个集群上提交的所有作业有效,初始值为1。无论在代码中设置、还是提交时的-p参数,都不是必须的;所以在没有指定并行度的时候,就会采用配置文件中的集群默认并行度。在开发环境中,没有配置文件,默认并行度就是当前机器的CPU核心数。
4.2.2 算子链(Operator Chain)
1)算子间的数据传输
一个数据流在算子之间传输数据的形式可以是一对一(one-to-one)的直通(forwarding)模式,也可以是打乱的重分区(redistributing)模式,具体是哪一种形式,取决于算子的种类。
(1)一对一(One-to-one,forwarding)
这种模式下,数据流维护着分区以及元素的顺序。比如图中的source和map算子,source算子读取数据之后,可以直接发送给map算子做处理,它们之间不需要重新分区,也不需要调整数据的顺序。这就意味着map 算子的子任务,看到的元素个数和顺序跟source 算子的子任务产生的完全一样,保证着“一对一”的关系。map、filter、flatMap等算子都是这种one-to-one的对应关系。这种关系类似于Spark中的窄依赖。
(2)重分区(Redistributing)
在这种模式下,数据流的分区会发生改变。比如图中的map和后面的keyBy/window算子之间,以及keyBy/window算子和Sink算子之间,都是这样的关系。
每一个算子的子任务,会根据数据传输的策略,把数据发送到不同的下游目标任务。这些传输方式都会引起重分区的过程,这一过程类似于Spark中的shuffle。
2)合并算子链
在Flink中,并行度相同的一对一(one to one)算子操作,可以直接链接在一起形成一个“大”的任务(task),这样原来的算子就成为了真正任务里的一部分,如下图所示。每个task会被一个线程执行。这样的技术被称为“算子链”(Operator Chain)。
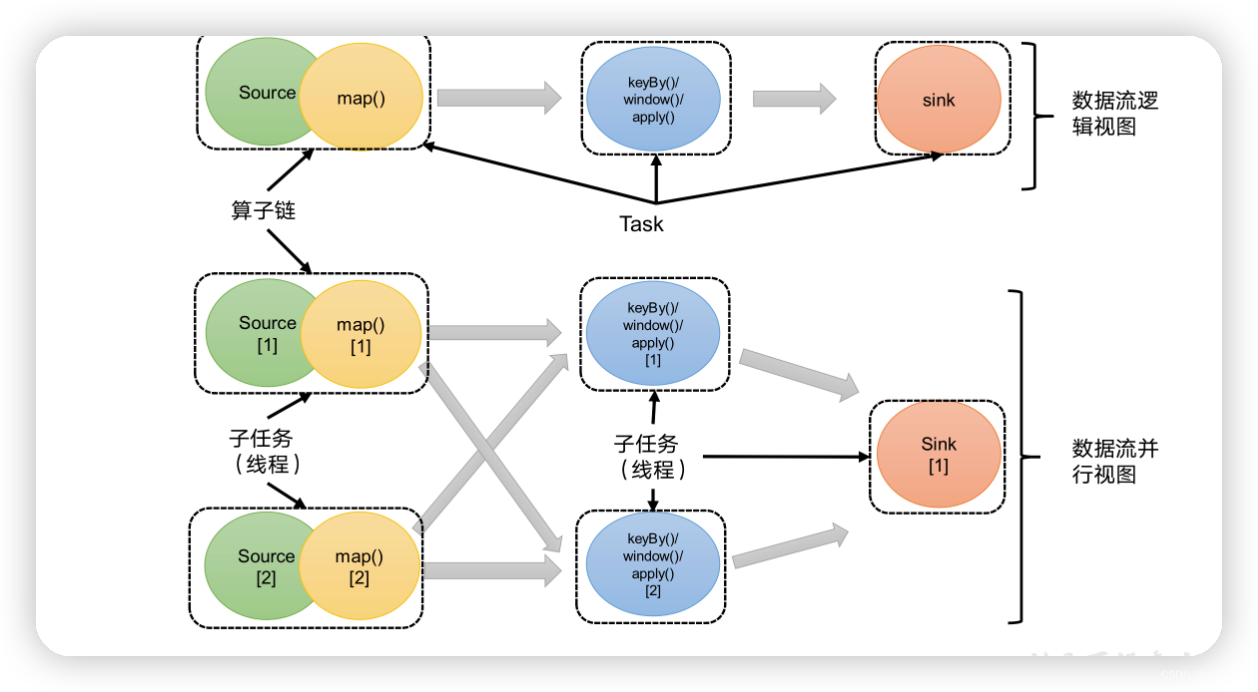
上图中Source和map之间满足了算子链的要求,所以可以直接合并在一起,形成了一个任务;因为并行度为2,所以合并后的任务也有两个并行子任务。这样,这个数据流图所表示的作业最终会有5个任务,由5个线程并行执行。
将算子链接成task是非常有效的优化:可以减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
Flink默认会按照算子链的原则进行链接合并,如果我们想要禁止合并或者自行定义,也可以在代码中对算子做一些特定的设置:
// 禁用算子链
.map(word -> Tuple2.of(word, 1L)).disableChaining();
// 从当前算子开始新链
.map(word -> Tuple2.of(word, 1L)).startNewChain()
4.2.3 任务槽(Task Slots)
1)任务槽(Task Slots)
Flink中每一个TaskManager都是一个JVM进程,它可以启动多个独立的线程,来并行执行多个子任务(subtask)。
很显然,TaskManager的计算资源是有限的,并行的任务越多,每个线程的资源就会越少。那一个TaskManager到底能并行处理多少个任务呢?为了控制并发量,我们需要在TaskManager上对每个任务运行所占用的资源做出明确的划分,这就是所谓的任务槽(task slots)。
每个任务槽(task slot)其实表示了TaskManager拥有计算资源的一个固定大小的子集。这些资源就是用来独立执行一个子任务的。
2)任务槽数量的设置
在Flink的/opt/module/flink-1.17.0/conf/flink-conf.yaml配置文件中,可以设置TaskManager的slot数量,默认是1个slot。
taskmanager.numberOfTaskSlots: 8
需要注意的是,slot目前仅仅用来隔离内存,不会涉及CPU的隔离。在具体应用时,可以将slot数量配置为机器的CPU核心数,尽量避免不同任务之间对CPU的竞争。这也是开发环境默认并行度设为机器CPU数量的原因。
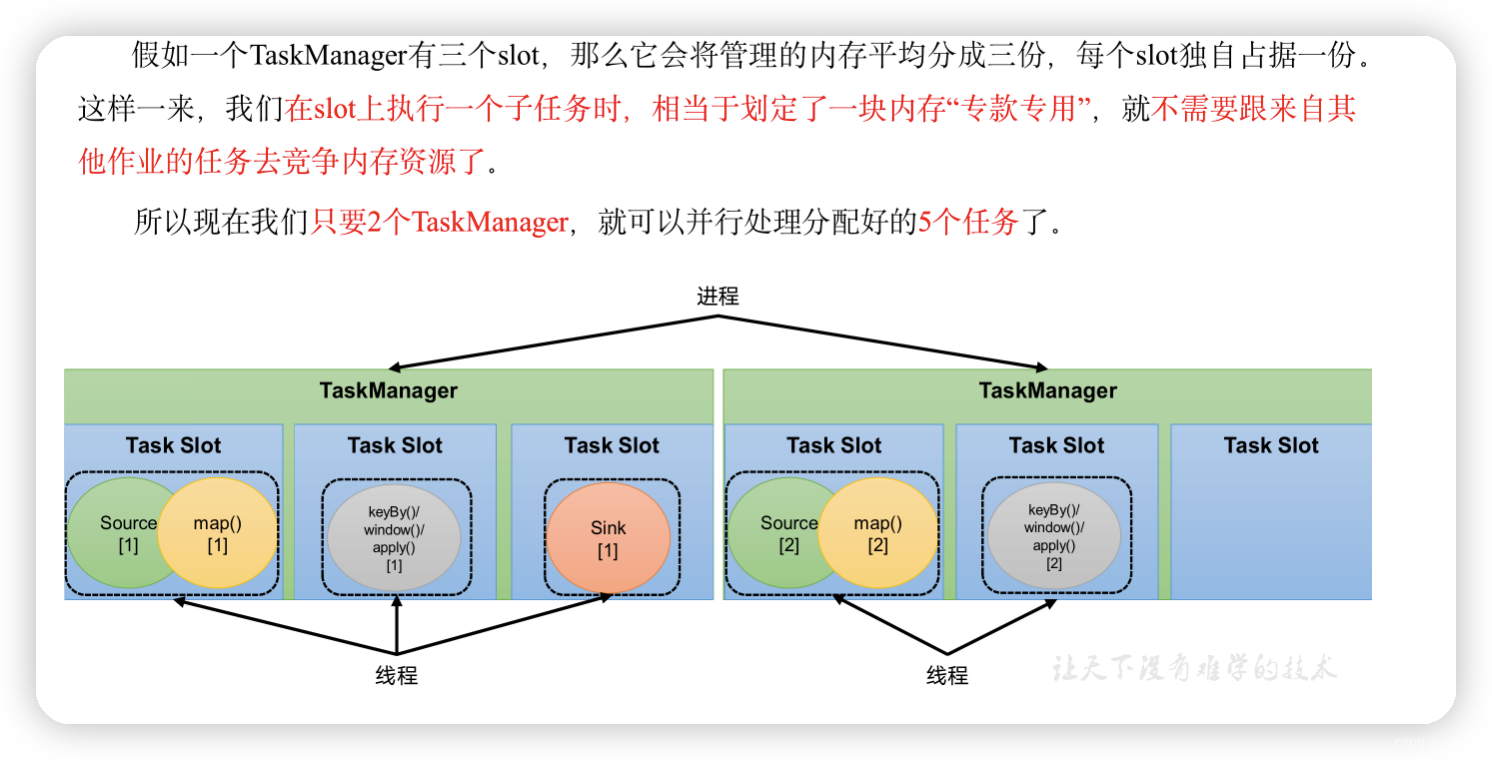
3)任务对任务槽的共享
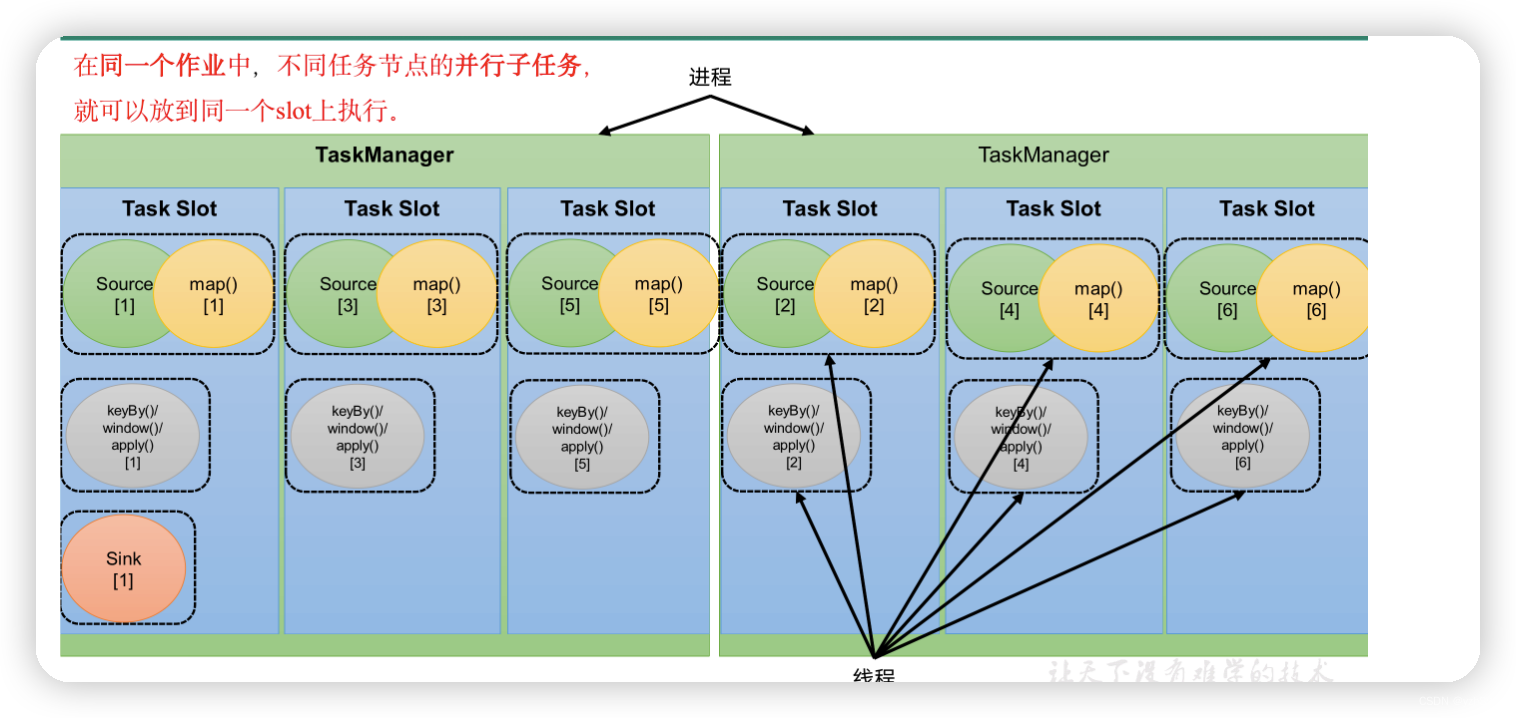
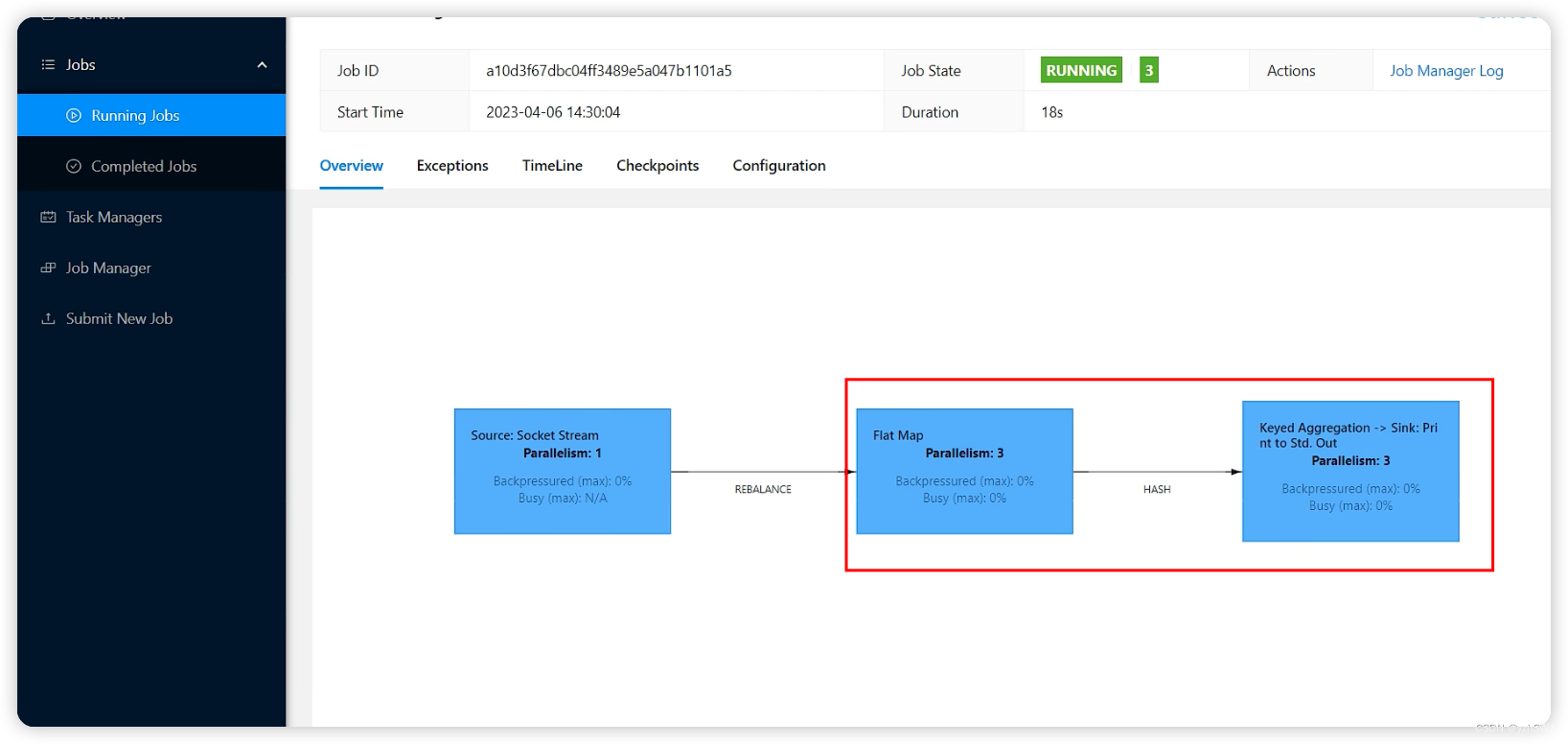
默认情况下,Flink是允许子任务共享slot的。如果我们保持sink任务并行度为1不变,而作业提交时设置全局并行度为6,那么前两个任务节点就会各自有6个并行子任务,整个流处理程序则有13个子任务。如上图所示,只要属于同一个作业,那么对于不同任务节点(算子)的并行子任务,就可以放到同一个slot上执行。所以对于第一个任务节点source→map,它的6个并行子任务必须分到不同的slot上,而第二个任务节点keyBy/window/apply的并行子任务却可以和第一个任务节点共享slot。
当我们将资源密集型和非密集型的任务同时放到一个slot中,它们就可以自行分配对资源占用的比例,从而保证最重的活平均分配给所有的TaskManager。
slot共享另一个好处就是允许我们保存完整的作业管道。这样一来,即使某个TaskManager出现故障宕机,其他节点也可以完全不受影响,作业的任务可以继续执行。
当然,Flink默认是允许slot共享的,如果希望某个算子对应的任务完全独占一个slot,或者只有某一部分算子共享slot,我们也可以通过设置“slot共享组”手动指定:
.map(word -> Tuple2.of(word, 1L)).slotSharingGroup("1");
这样,只有属于同一个slot共享组的子任务,才会开启slot共享;不同组之间的任务是完全隔离的,必须分配到不同的slot上。在这种场景下,总共需要的slot数量,就是各个slot共享组最大并行度的总和。
4.2.4 任务槽和并行度的关系
任务槽和并行度都跟程序的并行执行有关,但两者是完全不同的概念。简单来说任务槽是静态的概念,是指TaskManager具有的并发执行能力,可以通过参数taskmanager.numberOfTaskSlots进行配置;而并行度是动态概念,也就是TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置。
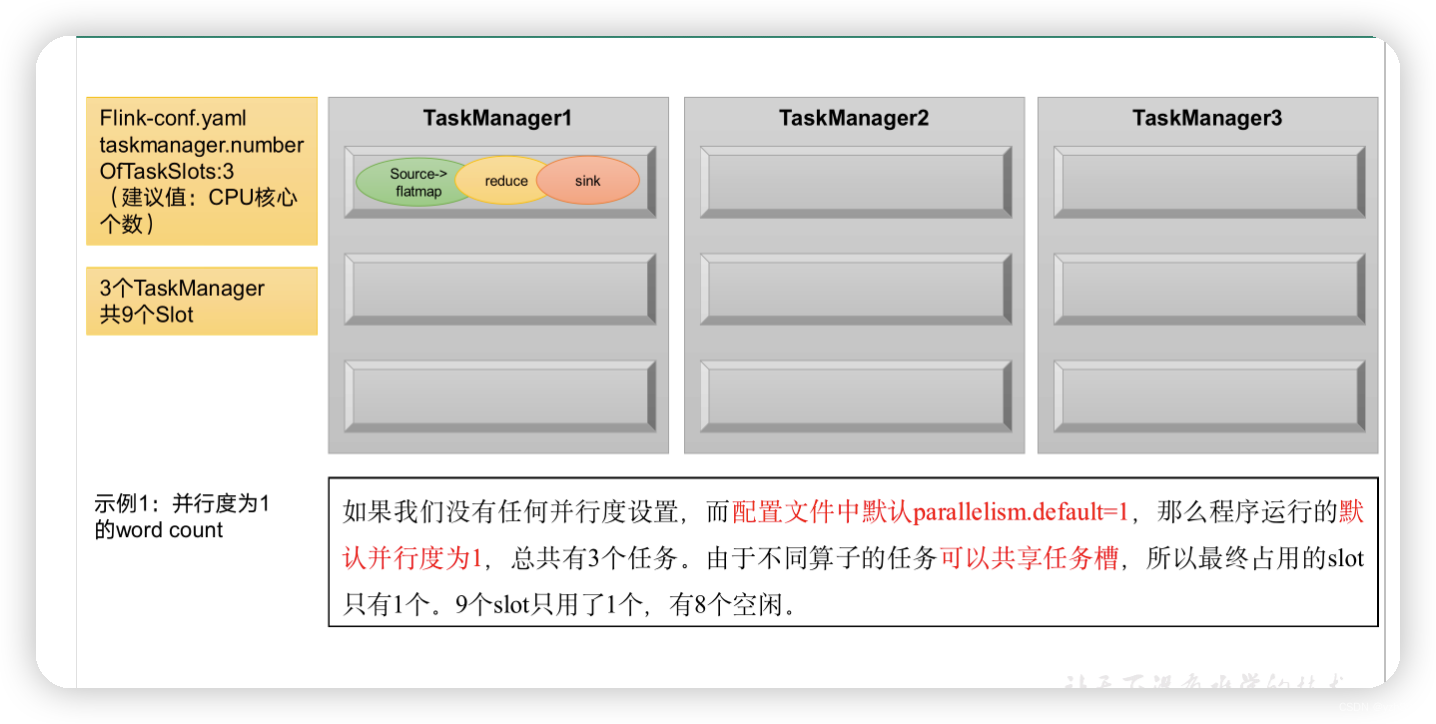
举例说明:假设一共有3个TaskManager,每一个TaskManager中的slot数量设置为3个,那么一共有9个task slot,表示集群最多能并行执行9个同一算子的子任务。
而我们定义word count程序的处理操作是四个转换算子:
source→ flatmap→ reduce→ sink
当所有算子并行度相同时,容易看出source和flatmap可以合并算子链,于是最终有三个任务节点。

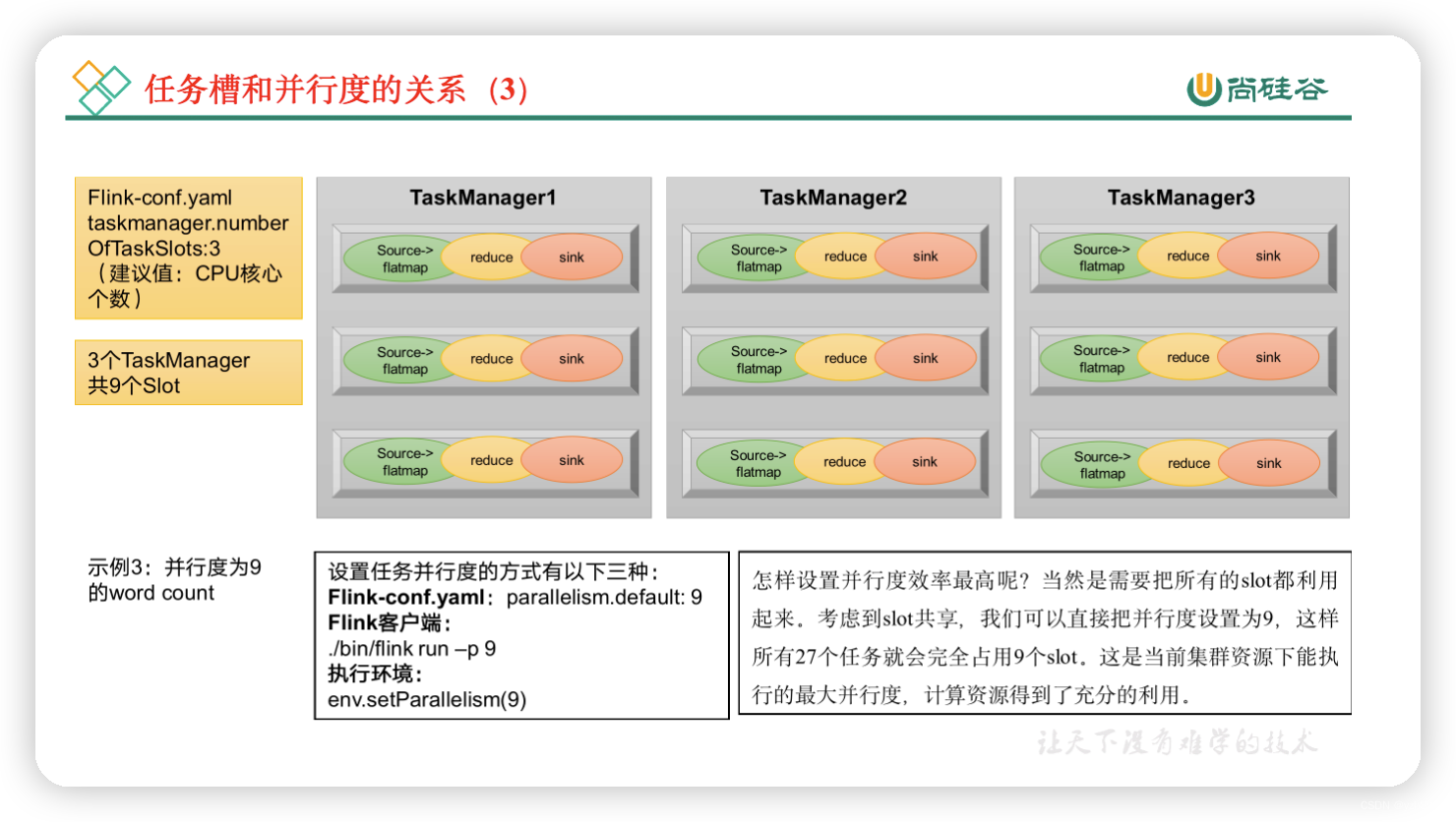
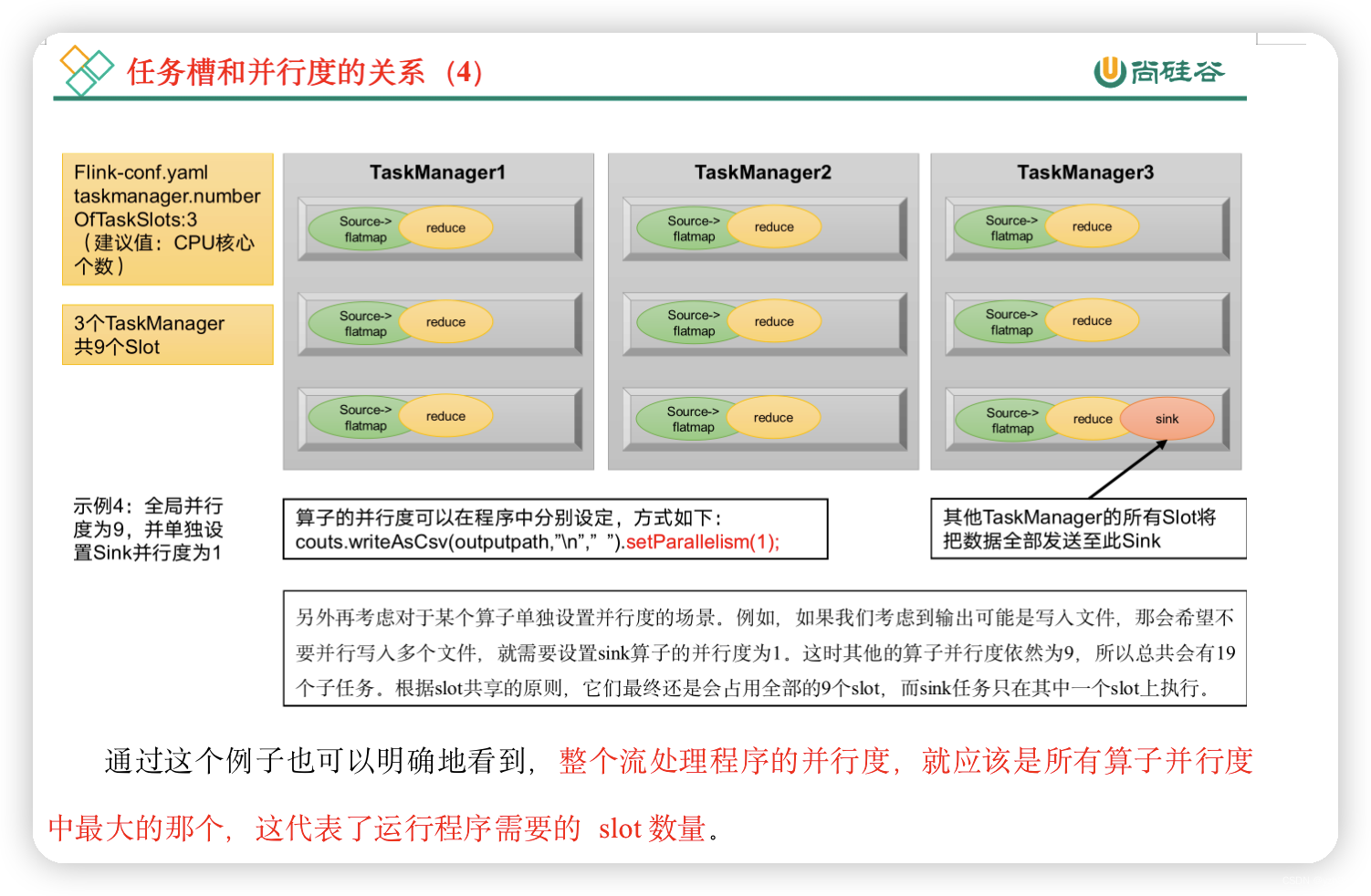
通过这个例子也可以明确地看到,整个流处理程序的并行度,就应该是所有算子并行度中最大的那个,这代表了运行程序需要的slot数量。









