pg软件包自带插件
前言
pg的插件是基于库的;
pg的数据字典介绍:

1、pg_stat_statements插件
Pg_stat_statements 是一个扩展,而不是核心数据库的一部分。它是一个contrib 扩展,随 postgres 源代码一起提供。pg_stat_statements 的功能位于一个名为 pg_stat_statements.so 的库中,并且必须将 postgres 配置为通过设置加载该库shared_preload_libraries。
一般我们编译安装是make & make install的方式,这种方式不会编译contrib下的内容,需要再手动编译contrib下的扩展
源码编译pg_stat_statements插件:
cd ./contrib/pg_stat_statements
make & make install
修改postgresql.conf,添加:
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.max = 10000
pg_stat_statements.track = all
重启:
pg_ctl restart
创建插件:
create extension pg_stat_statements;
查看插件是否创建成功:
SELECT * FROM pg_extension;

查询单次调用最耗 IO SQL TOP 5:
select userid::regrole, dbid, query from pg_stat_statements order by (blk_read_time+blk_write_time)/calls desc limit 5;
查询总最耗 IO SQL TOP 5:
select userid::regrole, dbid, query from pg_stat_statements order by (blk_read_time+blk_write_time) desc limit 5;
查询响应时间抖动最严重 SQL:
select userid::regrole, dbid, query from pg_stat_statements order by stddev_time desc limit 5;
查询最耗共享内存 SQL:
select userid::regrole, dbid, query from pg_stat_statements order by (shared_blks_hit+shared_blks_dirtied) desc limit 5;
查询最耗临时空间 SQL:
select userid::regrole, dbid, query from pg_stat_statements order by temp_blks_written desc limit 5;
清理历史记录:
select pg_stat_statements_reset();
2、auto_explain
我们可以通过explain/explain analyze查看sql的预执行计划/实际执行计划;但是无法查看性能问题发生时的历史执行计划,可以通过auto_explain插件来进行分析
源码编译pg_stat_statements插件:
cd ./contrib/auto_explain
make & make install
修改postgresql.conf,添加:
shared_preload_libraries = 'pg_stat_statements,auto_explain'
auto_explain.log_min_duration='100ms'
auto_explain.log_analyze=on
auto_explain.log_buffers=off
重启:
pg_ctl restart -m fast
测试:
sysbench=# \timing
Timing is on.
sysbench=# select count(*) from pgbench_accounts;
count
----------
10000000
(1 row)
Time: 6725.638 ms (00:06.726)
查看日志中的执行计划:

3、pg_prewarm
数据库重启后,数据库的缓存将被清空,若为生产系统,会在数据库重启后的一段时间内读取硬盘数据,从而可能造成性能问题。pg_prewarm插件可以将数据(表或索引)预先加载到数据库缓存/操作系统缓存
cd contrib/pg_prewarm
make & make install
要在表/索引所在的库中创建pg_prewarm的插件

返回的166549是预估的表的block数量(block_size为8k),analyse命令可以刷新此值(analyze pgbench_accounts;),buffer表示加载到数据库缓存;read表示同步加载到OS缓存;prefetch表示异步加载到OS缓存
也可以缓存索引:

pg_prewarm仅用于对热表数据预热,内存不够时被缓存的数据有可能被挤出,无法持久化到内存
pg_prewarm没出来之前有第三方工具pgfincore功能较丰富,支持表、索引加载到OS缓存,也支持刷出,同时支持查看表被缓存的情况。
4、postgres_fdw
此插件为pg外部表插件,可以访问其他pg实例的表(在本地映射),或者跨database访问(同一个sql不能同时查询两个库),类似oracle的dblink
安装插件:
cd contrib/postgres_fdw
make & make install
创建插件:
create extension postgres_fdw;
查询已安装插件:
SELECT * FROM pg_extension;

创建server:
CREATE SERVER haodb_server FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.237.23', port '5432', dbname 'haodb');
select * from information_schema.foreign_servers;
select * from pg_foreign_server;

创建mapping用户:
CREATE USER mapping FOR haodb SERVER haodb_server OPTIONS (user 'haodb', password 'haodb');
select * from information_schema.user_mappings;

创建外部表:
import foreign schema public limit to (test1) from server haodb_server into joyce_schema;
查询外部表:
select * from information_schema.foreign_tables;

select * from pg_foreign_table;
外部表不仅可以查询,也可以进行增删改的操作:
目标库:
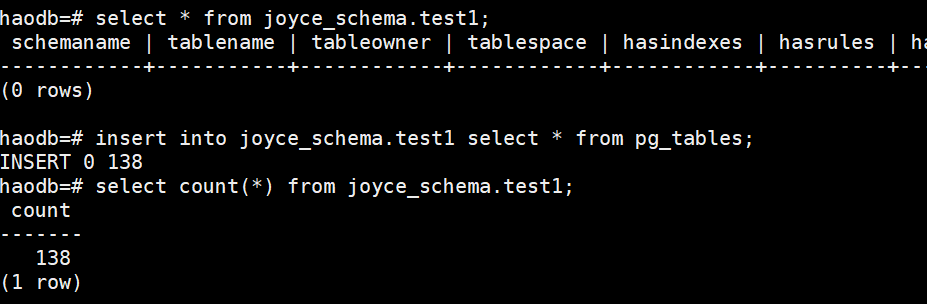
源库:
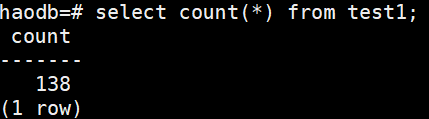
也可以进行DDL操作(可以修改表结构,不能drop table):
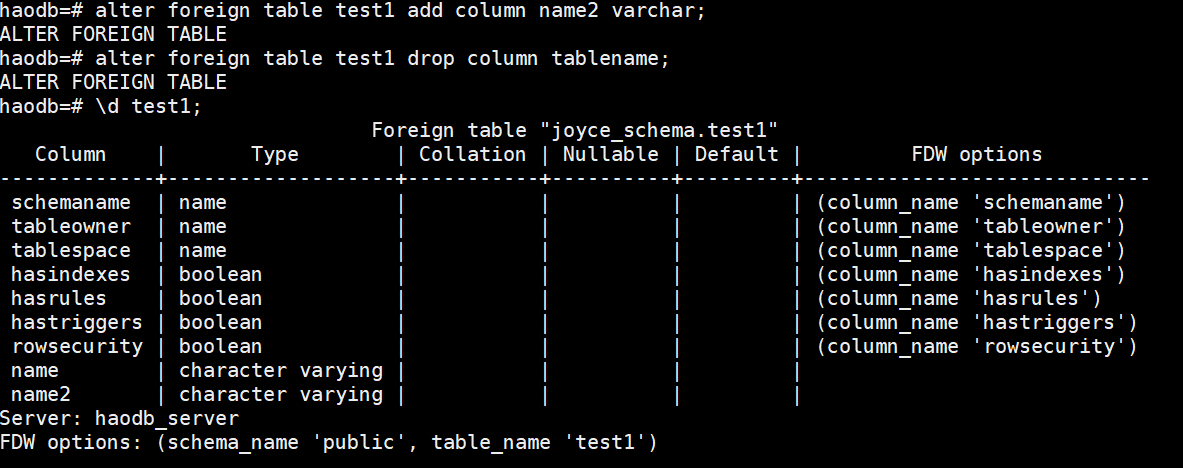
删除外部表:
drop FOREIGN table joyce_schema.test1;
如果想导入外部某个schema下的全部表,可以使用:
import foreign schema public from server haodb_server;
![]()
参考文档:
同理也有mysql_fdw、oracle_fdw来通过pg查询mysql、oracle的表,见【其他插件】
5、file_fdw
file_fdw插件为pg提供了访问外部文件的能力,目前只提供了只读能力,外部文件必须是符合COPY规则的
安装插件:
cd contrib/file_fdw
make & make install
创建插件:
create extension file_fdw;
查询已安装插件:
SELECT * FROM pg_extension;
创建外部服务:
CREATE SERVER fileserver FOREIGN DATA WRAPPER file_fdw;
有个csv外部文件,创建对应的外部表:
head /tmp/pg_foreign_table.csv
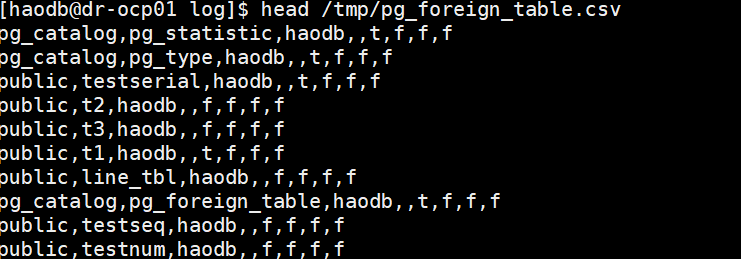
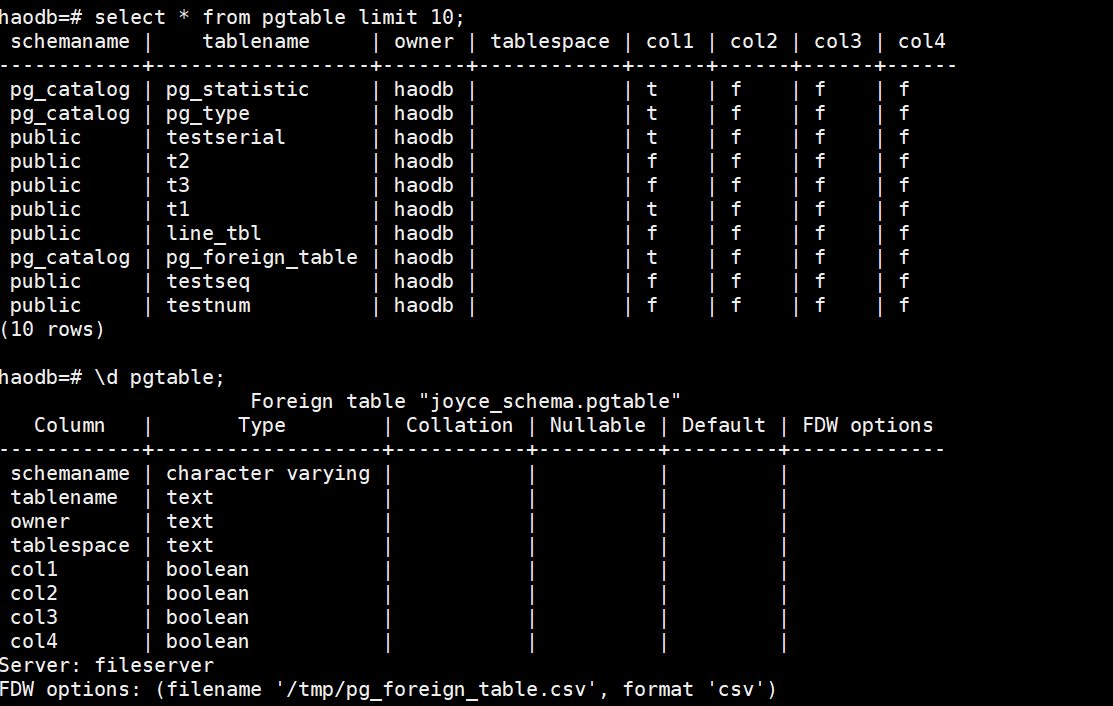
CREATE FOREIGN TABLE pgtable (
schemaname varchar,
tablename text,
owner text,
tablespace text,
col1 boolean,
col2 boolean,
col3 boolean,
col4 boolean
) SERVER fileserver
OPTIONS ( filename '/tmp/pg_foreign_table.csv', format 'csv' );
6、dblink
与postgres_fdw类似,编译安装方法也类似
cd contrib/dblink
make & make install
create extension dblink;
创建myconn dblink:
select dblink_connect('myconn','host=10.10.237.23 port=5432 dbname=haodb user=haodb password=haodb');
引用dblink:
select * from dblink ('myconn','select * from test') as dblink_test(a int);
用法有点奇奇怪怪,fdw强于dblink插件,建议使用外部表
7、pageinspect
pageinspect插件是查看表文件的一个插件,可以查询表的历史事务,对MVCC有更深入的理解
瀚高利用此特性可以实现闪回查询,原生pg不行
安装插件:
cd contrib/pageinspect
make & make install
创建插件:
create extension pageinspect;
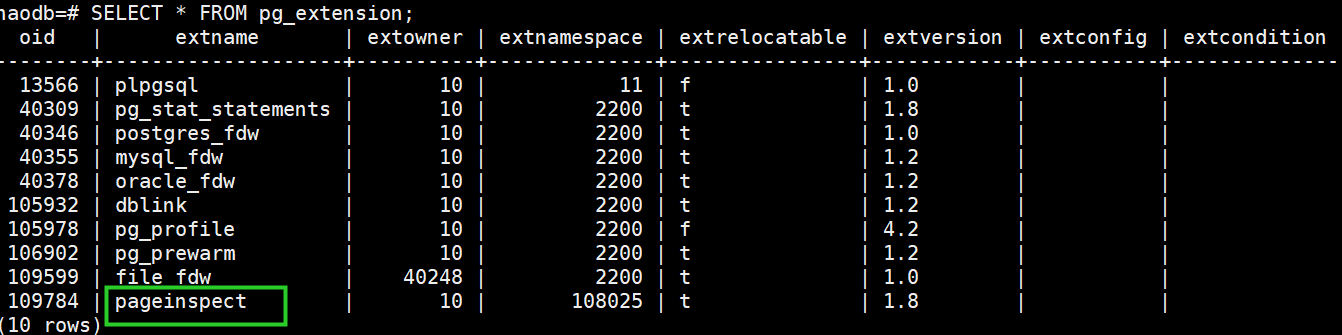
查询已安装插件:
SELECT * FROM pg_extension;
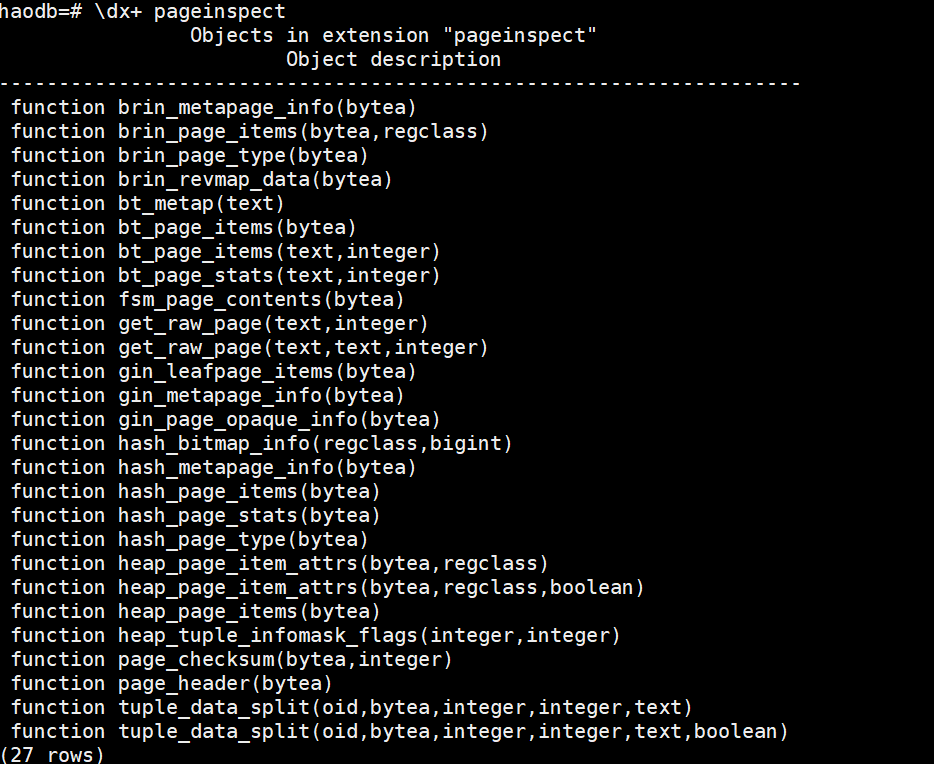
查询插件支持的function:
\dx+ pageinspect
测试
我们使用hash_page_items和get_raw_page来读取表文件的内容
create table t1(id int,name varchar(10));
insert into t1 values(1,'a'),(2,'b');
select xmin,xmax,ctid,* from t1; --查询表中的内容
select t_xmin,t_xmax,t_ctid from heap_page_items(get_raw_page('t1',0)); --查询表文件中的内容此时表和表文件的xmin一致:
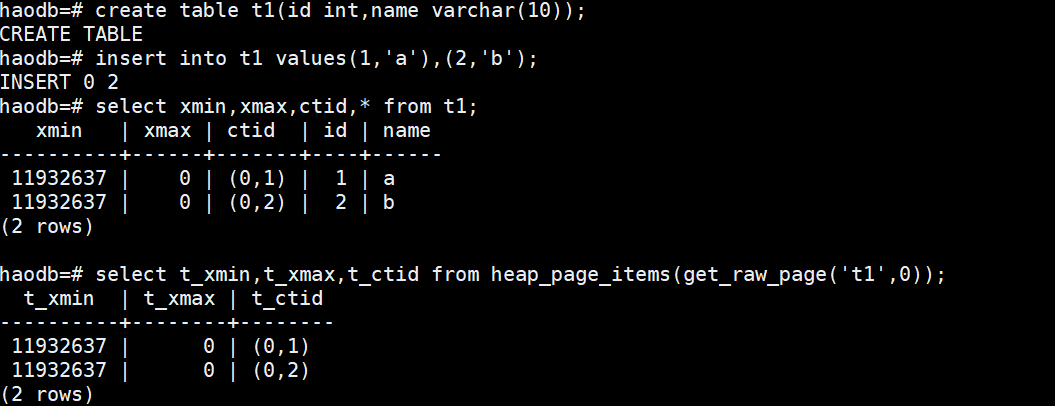
对表做update操作:
update t1 set name='c' where id=1;
select xmin,xmax,ctid,* from t1;
select t_xmin,t_xmax,t_ctid from heap_page_items(get_raw_page('t1',0));此时表文件中出现了行的多版本信息(t_xmax不为0的那行是待回收的行)
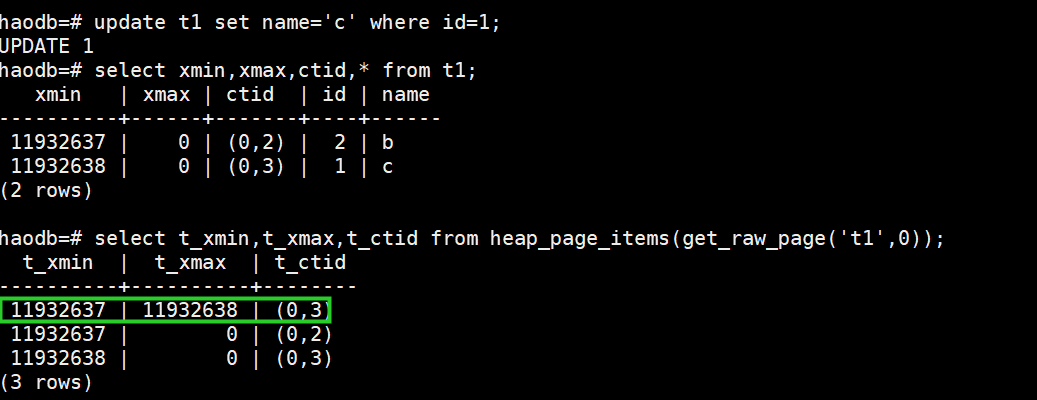
也可以看出,pg中update是delete+insert的
手动做vacuum
vacuum t1;
可以发现空间被清理,但未被回收
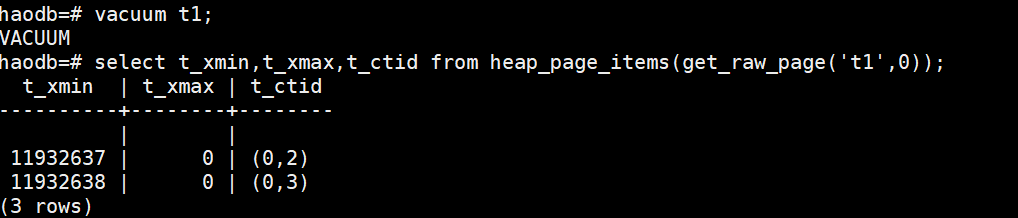
vacuum full t1;
空间被回收:
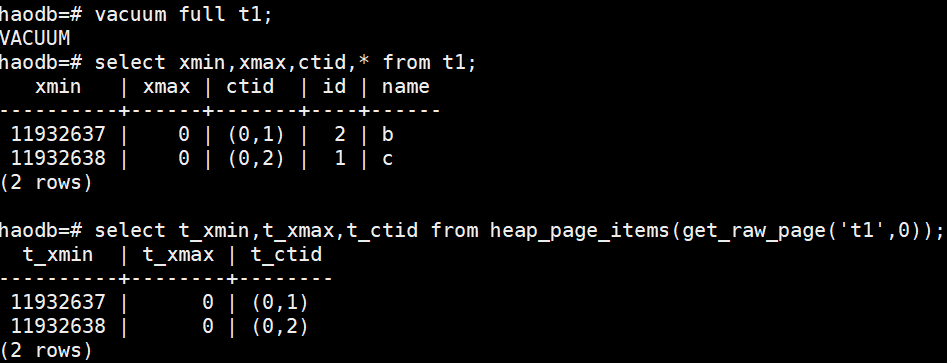
其他插件
1、mysql_fdw
下载mysql_fdw最新版本
https://github.com/EnterpriseDB/mysql_fdw/releases
编译安装
export PATH=$PATH:/usr/local/mysql/bin:/haodb/haodb/bin
export LD_LIBRARY_PATH=/usr/lib:/usr/lib64:/usr/local/mysql/lib:/haodb/haodb/lib
yum -y install mysql-devel
cd contrib (pg的contrib目录)
unzip /soft/mysql_fdw-REL-2_9_0.zip
cd mysql_fdw-REL-2_9_0/
make & make install
创建mysql_fdw插件
create extension mysql_fdw;

CREATE SERVER mysql_server FOREIGN DATA WRAPPER mysql_fdw OPTIONS (host '10.10.237.20', port '3306');
CREATE USER MAPPING FOR haodb SERVER mysql_server OPTIONS (username 'test', password 'test');
CREATE FOREIGN TABLE fdw_t1
(
TABLE_SCHEMA varchar,
TABLE_NAME varchar
)
SERVER mysql_server
OPTIONS (dbname 'test', table_name 't1');
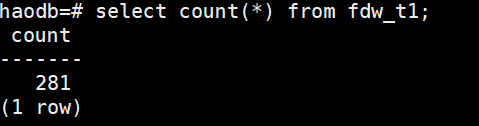
2、oracle_fdw
下载oracle_fdw
GitHub - laurenz/oracle_fdw: PostgreSQL Foreign Data Wrapper for Oracle
编译安装
添加如下变量配置到/etc/profile
export ORACLE_HOME=/oracle/product/19c
export LD_LIBRARY_PATH=$ORACLE_HOME/lib:$LD_LIBRARY_PATH
export PATH=$ORACLE_HOME/bin:$PATH
export TNS_ADMIN=$ORACLE_HOME/network/admin
source /etc/profile
cd contrib
unzip /soft/oracle_fdw-master.zip
make & make install
create extension oracle_fdw;
可能报以下错误:
(1)libclntsh.so.19.1: cannot open shared object file: No such file or directory
![]()
可以通过配置以下解决:
vi /etc/ld.so.conf.d/oracle-x86_64.conf
/oracle/product/19c/lib
haodb用户下执行 sudo ldconfig (注意先给haodb sudo权限)
(2)执行sudo ldconfig报错如下:

是由于上面两个文件都是实体文件不是软链接,可以通过将实体文件重命名,再重新软连接解决
su - oracle
mv /oracle/product/19c/lib/libexpat.so.1 /oracle/product/19c/lib/libexpat.so.1.bk
ln -s /oracle/product/19c/lib/libexpat.so.1.bk /oracle/product/19c/lib/libexpat.so.1
mv /oracle/product/19c/lib/libsrvm19.so /oracle/product/19c/lib/libsrvm19.so.bk
ln -s /oracle/product/19c/lib/libsrvm19.so.bk /oracle/product/19c/lib/libsrvm19.so
再次创建oracle_fdw插件不再报错
create extension oracle_fdw;

--注意haodb软件的用户需要能调用sqlplus连接oracle库

CREATE SERVER oradb FOREIGN DATA WRAPPER oracle_fdw OPTIONS (dbserver '10.10.237.20:1521/cc');
CREATE USER MAPPING FOR haodb SERVER oradb OPTIONS (user 'test', password 'test');
CREATE FOREIGN TABLE fdw_t2 (
owner VARCHAR(128),
TABLE_NAME VARCHAR(128)
) SERVER oradb OPTIONS (schema 'TEST', table 'T2');
CREATE FOREIGN TABLE fdw_t3 (
id int,
name varchar(10)
) SERVER oradb OPTIONS (schema 'TEST', table 'T3');
--注意因为oracle表名都是大写存储的,这里的schema和table都要大写,防止小写找不到表
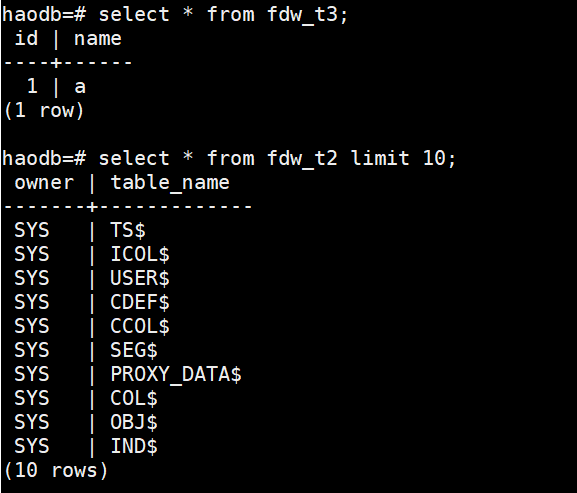
这种sql都正常执行,但是fdw_t2有2000多行记录,count(*)会导致报错,原因不明
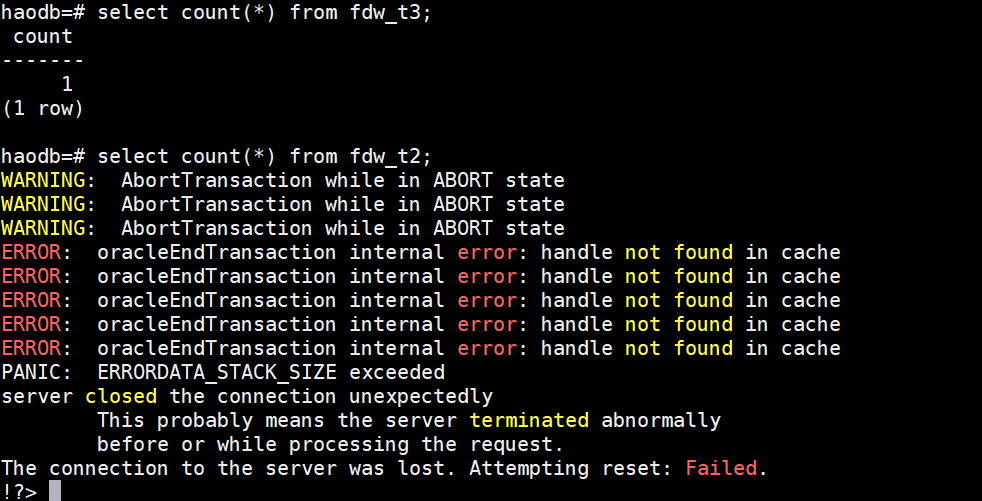
给源库的t3 insert一行记录,count(*)也会报错

似乎是个bug
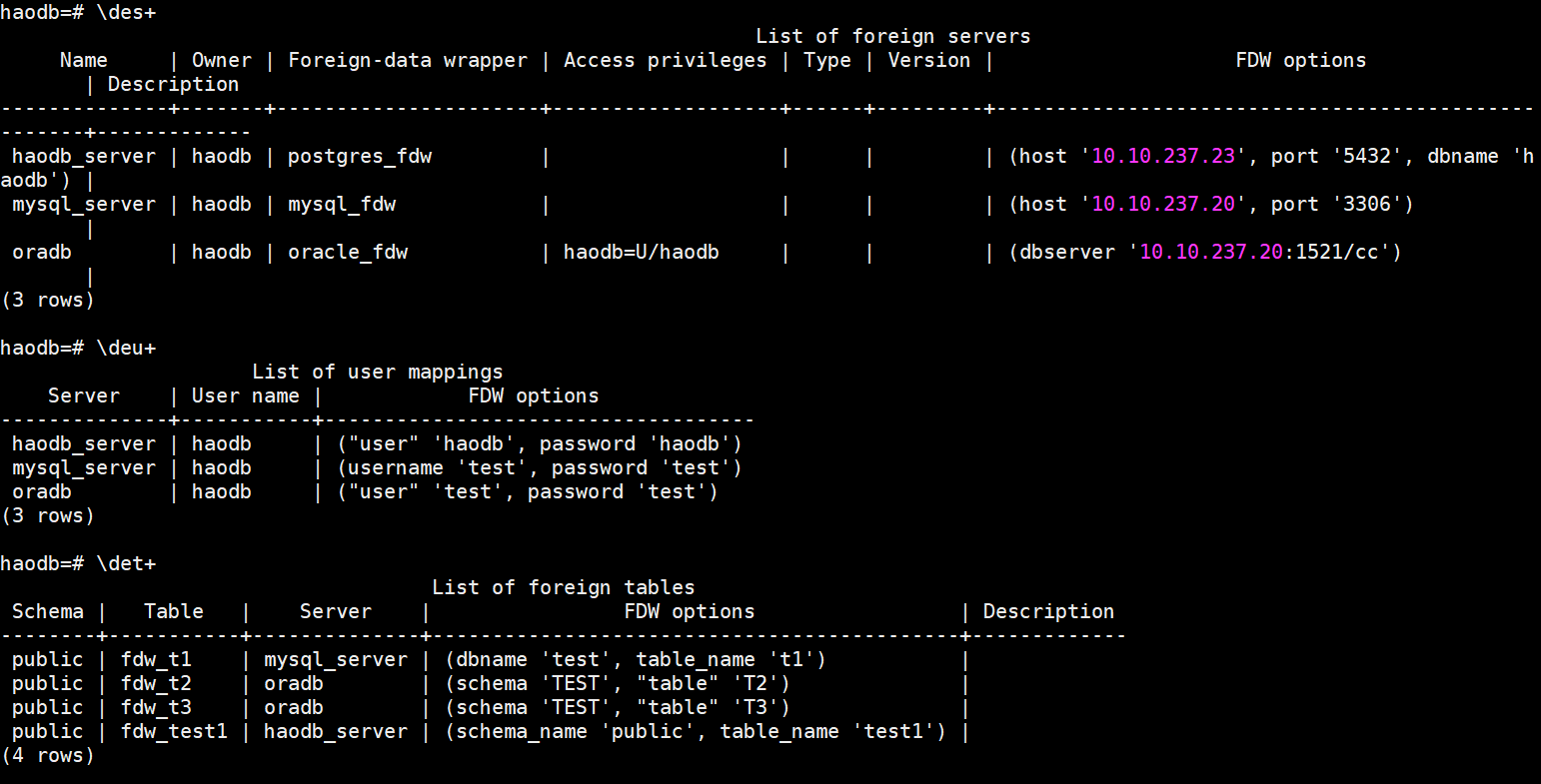
查看所有外部对象:
查看所有外部server: /des+
查看所有外部user mapping: /deu+
查看所有外部表:/det+

3、pg_profile
pg_profile扩展是基于postgres的标准统计视图,类似于Oracle AWR架构,在指定时间生成快照,并切提供html格式来解释快照之间的统计数据
使用pg_profile的前提是安装了dblink和pg_stat_statements插件,pg_profile需要如下的参数设置:
track_activities = on
track_counts = on
track_io_timing = on
#track_wal_io_timing = on # Since Postgres 14
track_functions = all
pg_ctl reload 即可生效,无需重启
下载pg_profile
https://github.com/zubkov-andrei/pg_profile
解压安装:
cd contrib
unzip /soft/pg_profile-master.zip
cd pg_profile-master
make & make install
create extension pg_profile;
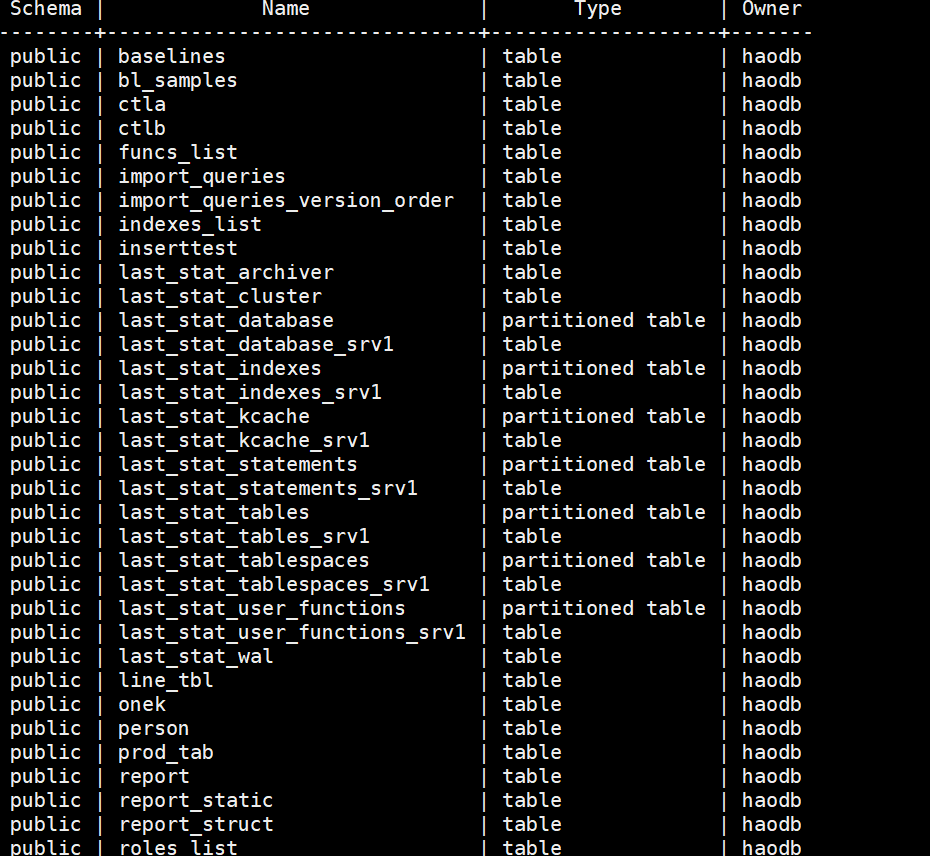
很多表被自动创建了
select show_samples(); --查看当前已存在的快照
select * from take_sample(); --手动创建快照
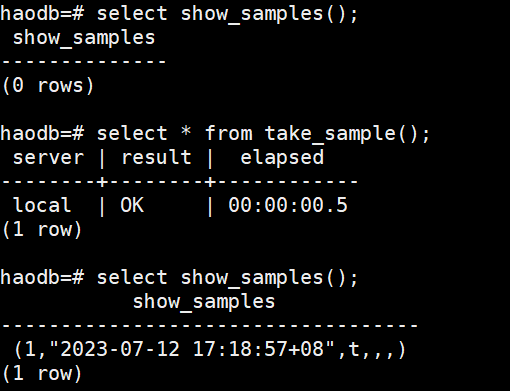
生成awr报告:
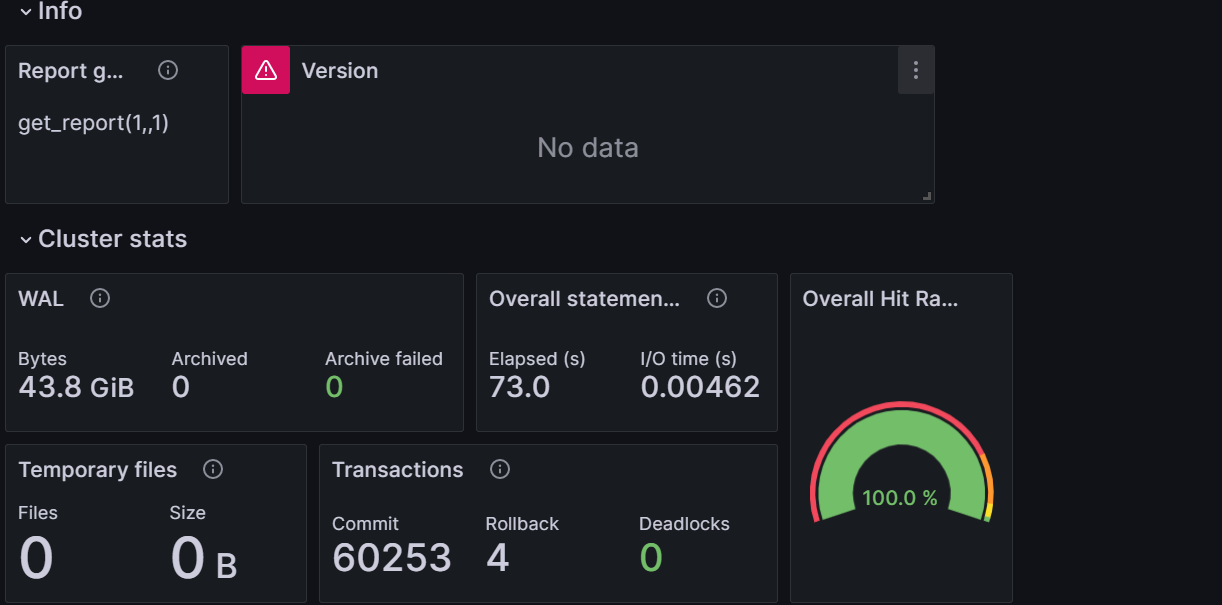
psql -Aqtc "select get_report(1,2)" --output awr_report_postgres_1_2.html
html报告的主内容如下图:

crontab中配置每半小时生成快照:
*/30 * * * * psql -c 'SELECT profile.snapshot()' > /haodb/haodb/pg_awr.log 2>&1
同时pg_profile有自带的grafana监控模板,可以在grafana新建postgres的data source
导入pg_profile_visualization.json,新建dashboard
可以看到dashboard监控(但是感觉没什么意思)
4、pgwatch2+grafana
下载pgwatch2
https://github.com/cybertec-postgresql/pgwatch2/releases
rpm -ivh pgwatch2_1.10.0_linux_64-bit.rpm
创建configdb
psql -c "create user pgwatch2 password 'pgwatch2'" -Uhaodb
psql -c "create database pgwatch2 owner pgwatch2" -Uhaodb
psql -f /etc/pgwatch2/sql/config_store/config_store.sql pgwatch2 -Uhaodb
psql -f /etc/pgwatch2/sql/config_store/metric_definitions.sql pgwatch2 -Uhaodb
创建metrics storage DB
cd contrib/btree_gin/
make & nake install
psql -c "create database pgwatch2_metrics owner pgwatch2" -Uhaodb
cd /etc/pgwatch2/sql/metric_store
psql -f roll_out_metric_time.psql pgwatch2_metrics -Uhaodb
安装python3
yum install python3 python3-pip python3-devel
su - haodb
cd /etc/pgwatch2/
pip3 install -U -r webpy/requirements_pg_metrics.txt --default-timeout=100
pip3 install -U -r webpy/requirements_influx_metrics.txt --default-timeout=100
cd webpy
若8080端口已被占用,可修改web.py为未被占用的端口
![]()
启动pgwatch2
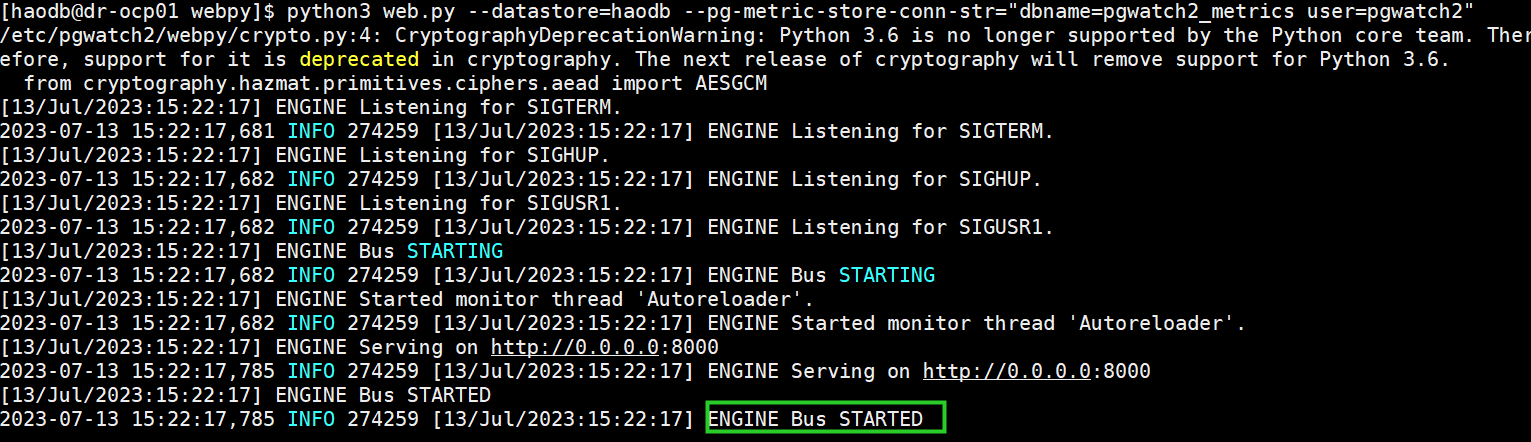
python3 web.py --datastore=haodb --pg-metric-store-conn-str="dbname=pgwatch2_metrics user=pgwatch2"
若出现以下说明WebUI启动成功
cd /usr/lib/systemd/system/
cp /etc/pgwatch2/webpy/startup-scripts/pgwatch2-webui.service .
按照实际的配置修改pgwatch2-webui.service
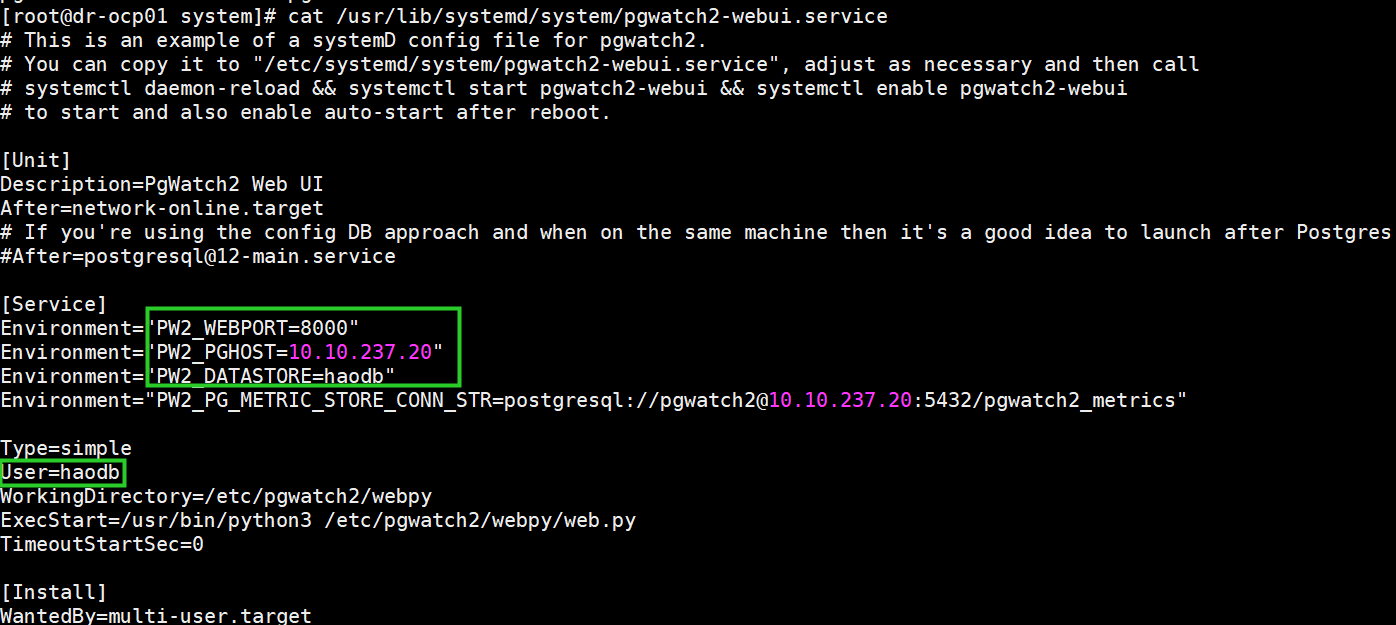
ln -s /haodb/haodb/lib/libpq.so.5.13 /usr/lib64/libpq.so.5
systemctl start pgwatch2-webui
被监控的数据库中创建监控用户:
CREATE ROLE m_pgwatch2 WITH LOGIN PASSWORD 'm_pgwatch2';
ALTER ROLE m_pgwatch2 CONNECTION LIMIT 3;
GRANT pg_monitor TO m_pgwatch2;
GRANT CONNECT ON DATABASE haodb TO m_pgwatch2;
GRANT USAGE ON SCHEMA public TO m_pgwatch2;
GRANT EXECUTE ON FUNCTION pg_stat_file(text) to m_pgwatch2;
新增监控数据库信息:

填写完成后点击New
被监控机器启动agent:
pgwatch2-daemon --host=10.10.237.20 --user=pgwatch2 --dbname=pgwatch2 --datastore=postgres --pg-metric-store-conn-str=postgresql://pgwatch2@10.10.237.20:5432/pgwatch2_metrics --verbose=info
导入dashboard.json到grafana,这里我没有把数据显示出来,与之前的pgscv有点类似,就没深入追究了
5、pgbadger
用于解析pg的log文件
要开启慢sql
log_min_duration_statement='5s'
logging_collector = on
log_directory = '/haodb/haodb/log'
log_filename = 'haodb-%Y-%m-%d_%H%M%S.log'
log_rotation_age = 1d
log_rotation_size = 10MB
log_line_prefix = '%m [%p] '
下载pgbadger
https://github.com/darold/pgbadger/releases
解压并安装
unzip pgbadger-12.1.zip
cd pgbadger-12.1
yum install cpan perl-ExtUtils-CBuilder perl-ExtUtils-MakeMaker -y
cpan ExtUtils::Install
perl Makefile.PL
make & make install
/usr/local/bin/pgbadger -V
安装httpd
yum install httpd -y
mkdir /var/www/html/pgbadger
systemctl start httpd
分析log:
pgbadger --prefix '%m [%p] ' /haodb/haodb/log/haodb-*.log -o /var/www/html/pgbadger/out.html -f stderr -s 10
查看:
还有一些插件这里没有深入介绍:如分片插件citus、oracle语法兼容插件orafce等










