全文链接:http://tecdat.cn/?p=30605
应用关联规则、聚类方法等数据挖掘技术分析治疗的中药专利复方组方配伍规律(点击文末“阅读原文”获取完整代码数据)。
方法检索治疗中药专利复方,排除外用中药及中西药物合用的复方。最近我们被要求撰写关于用药规律的研究报告,包括一些图形和统计输出。对入选的中药专利复方进行术语规范化等处理,抽取信息、建立表,应用数据分析软件R对数据进行关联规则分析,应用网络分析软件进行聚类分析。
相关视频
查看数据
转换成二值矩阵数据
colnames(data) <- paste0("X",1:ncol(data))
database <- NULL
for(i in 1:nrow(data)) {
tmp <- integer(length(total_types))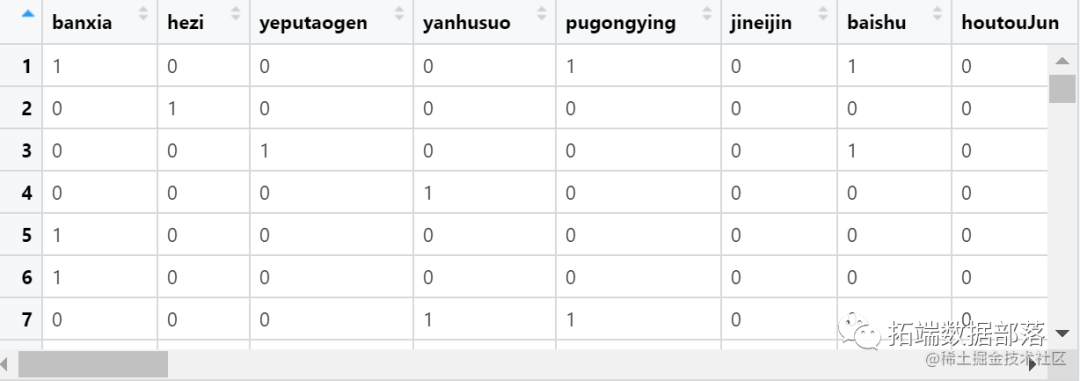
建立apriori
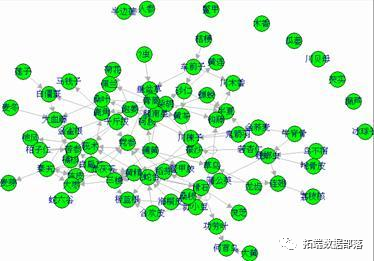
plot(all_rules, method = "graph")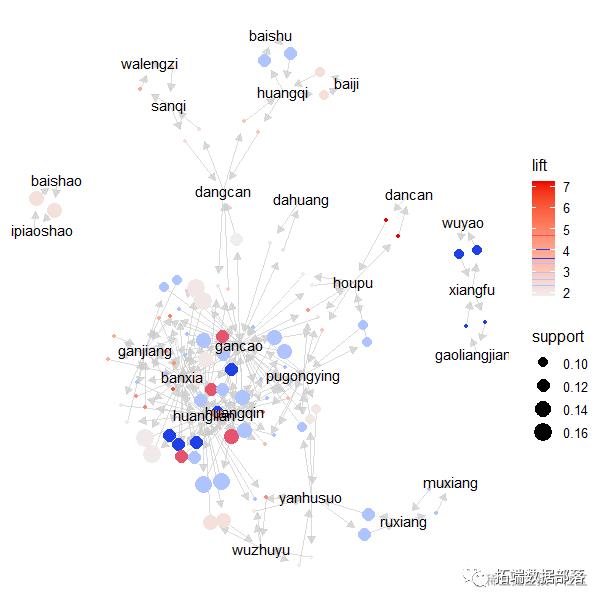
点击标题查阅往期内容


左右滑动查看更多
01
02
03
04

中药专利复方中药对的关联规则分析
药对是方剂配伍的基本形式,它反映了中药之间相辅相成、相反相成、同类相从等配伍关系。药对中的中药在组方配伍时具有在处方中同时出现的特点,因此在关联规则分析中,分析置信度较大且双向关联的规则即可得到药对。 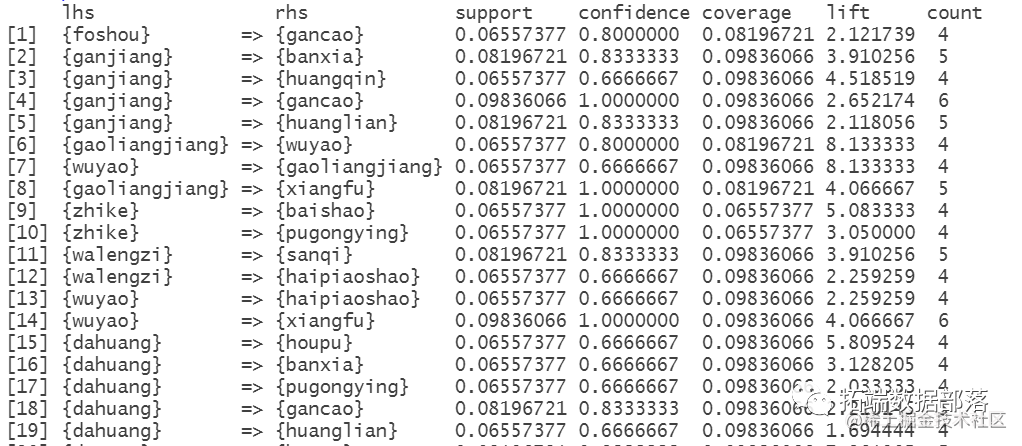
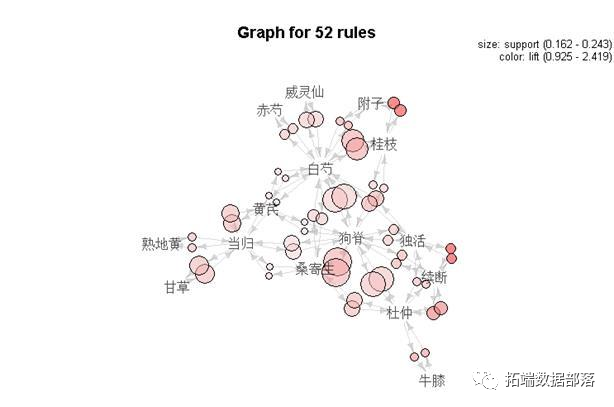
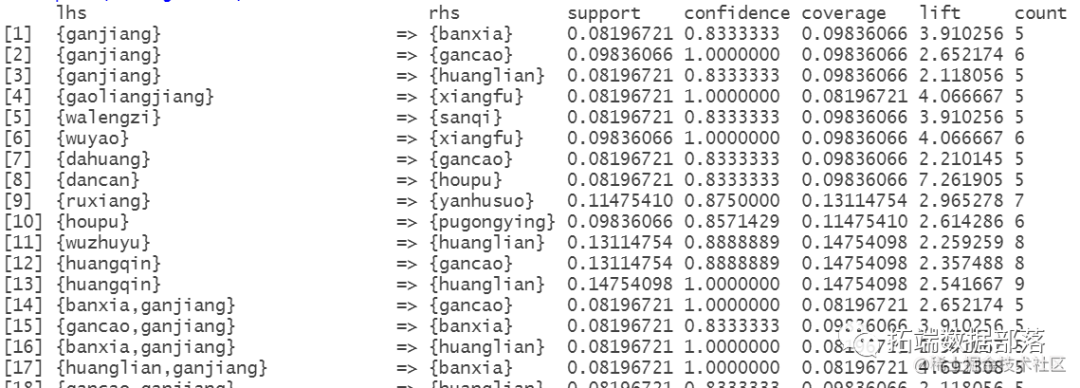
根据置信度和支持度筛选强关联规则
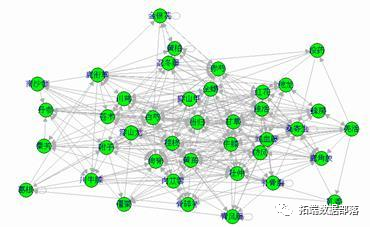
K-means均值网络聚类分析
抑郁症中药专利复方中药物之间形成了一个复杂的配伍关系网络,关联规则分析可以用来发现其中的药对及强关联规则,但随着支持度和置信度阈值参数的降低,关联规则大量涌现,使得其中的配伍规律变得难以分析,应用网络聚类方法可以有效地发现其中的配伍规律。
#聚类类别号
kmod$cluster
查看每个类别中的强关联规则

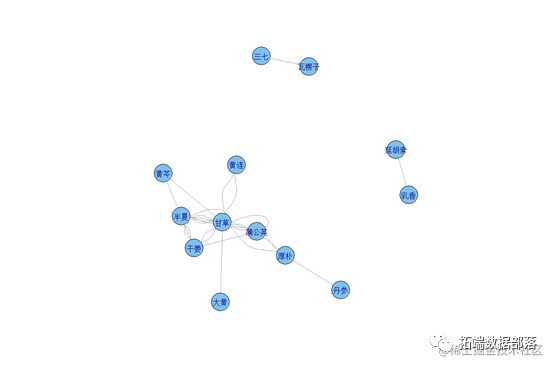
聚类1
聚类2
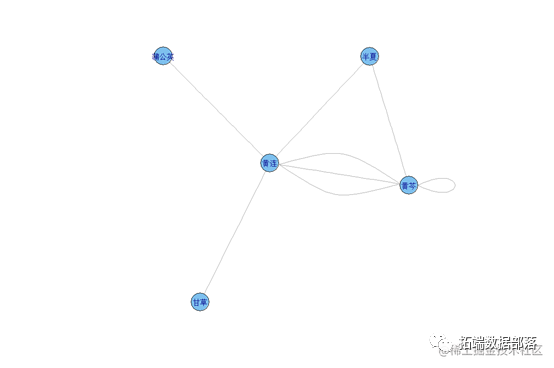
配伍关系网络的聚类分析结果显示了抑郁症治疗中常用的中药“社团”,反映了复方中一些配伍关系相对密切、固定的中药联合,临床运用可以提高疗效。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言APRIORI关联规则、K-MEANS均值聚类数据挖掘中药专利复方治疗用药规律网络可视化》。


点击标题查阅往期内容
Python面板时间序列数据预测:格兰杰因果关系检验Granger causality test药品销售实例与可视化
用SPSS Modeler的Web复杂网络对所有腧穴进行关联规则分析
PYTHON在线零售数据关联规则挖掘APRIORI算法数据可视化
R语言关联规则模型(Apriori算法)挖掘杂货店的交易数据与交互可视化
python关联规则学习:FP-Growth算法对药品进行“菜篮子”分析
基于R的FP树fp growth 关联数据挖掘技术在煤矿隐患管理
python关联规则学习:FP-Growth算法对药品进行“菜篮子”分析
K-means和层次聚类分析癌细胞系微阵列数据和树状图可视化比较
KMEANS均值聚类和层次聚类:亚洲国家地区生活幸福质量异同可视化分析和选择最佳聚类数
有限混合模型聚类FMM、广义线性回归模型GLM混合应用分析威士忌市场和研究专利申请数据
R语言多维数据层次聚类散点图矩阵、配对图、平行坐标图、树状图可视化城市宏观经济指标数据
r语言有限正态混合模型EM算法的分层聚类、分类和密度估计及可视化
Python Monte Carlo K-Means聚类实战研究
R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归
R语言实现k-means聚类优化的分层抽样(Stratified Sampling)分析各市镇的人口
R语言聚类有效性:确定最优聚类数分析IRIS鸢尾花数据和可视化
R语言k-means聚类、层次聚类、主成分(PCA)降维及可视化分析鸢尾花iris数据集
R语言有限混合模型(FMM,finite mixture model)EM算法聚类分析间歇泉喷发时间
R语言用温度对城市层次聚类、kmean聚类、主成分分析和Voronoi图可视化
R语言对用电负荷时间序列数据进行K-medoids聚类建模和GAM回归

![]()









