删除空行
#del all None value
data_all.dropna(axis=1, how='all', inplace=True)删除空列
#del all None value
data_all.dropna(axis=0, how='all', inplace=True)缺失值处理
观测缺失值
观测数据缺失值有一个比较好用的工具包——missingno,直接传入DataFrame,会将所有的列缺失比例可视化,是一个比较方便的工具。
将观测的缺失值数据统计成为一个数据表,并将数据表可视化,
# 统计缺失值数量
missing=data_all.isnull().sum().reset_index().rename(columns={0:'missNum'})
# 计算缺失比例
missing['missRate']=missing['missNum']/data_all.shape[0]
# 按照缺失率排序显示
miss_analy=missing[missing.missRate>0].sort_values(by='missRate',ascending=False)
# miss_analy 存储的是每个变量缺失情况的数据框然后将缺失值数据miss_analy可视化
import matplotlib.pyplot as plt
import pylab as pl
fig = plt.figure(figsize=(18,6))
plt.bar(np.arange(miss_analy.shape[0]), list(miss_analy.missRate.values), align = 'center',color=['red','green','yellow','steelblue'])
plt.title('Histogram of missing value of variables')
plt.xlabel('variables names')
plt.ylabel('missing rate')# 添加x轴标签,并旋转90度
plt.xticks(np.arange(miss_analy.shape[0]),list(miss_analy['index']))
plt.xticks(rotation=90)
# 添加数值显示
for x,y in enumerate(list(miss_analy.missRate.values)):
plt.text(x,y+0.12,'{:.2%}'.format(y),ha='center',rotation=90)
plt.ylim([0,1.2])
plt.show()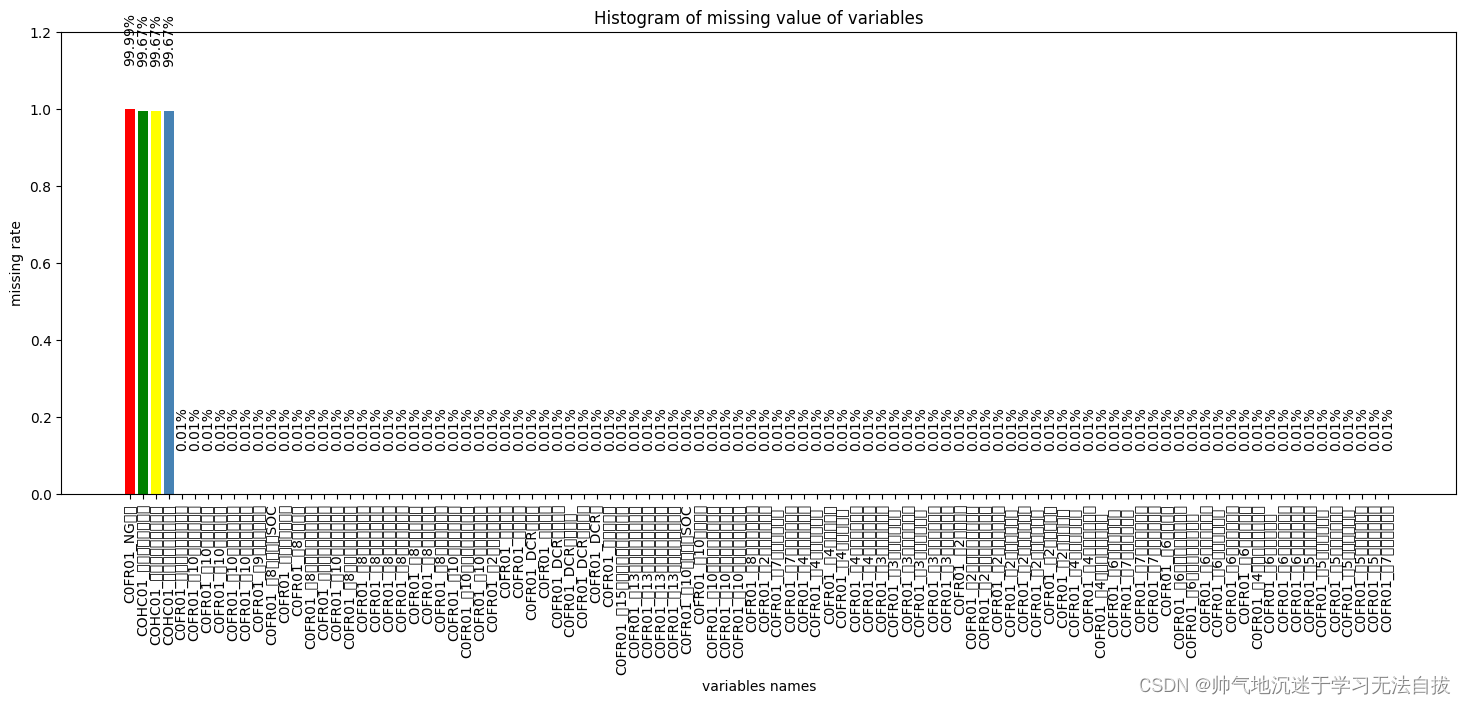
当然有些画图的技巧,需要每个人根据各自的需求去探索,笔者画图功底也比较差,可以参考Sklearn里面的sample,也可以查阅Seaborn中的技术文档。以上数据可视化后可以看到每一列的缺失值比例,然后可以自己设定缺失值阈值α,如果缺失值比例大于α则删除该列,或者其他却缺失值处理策略。当然笔者任务是建立高精度的预测模型,而且,数据量还可以。所以就没有用填充策略。
删除缺失严重特征
alpha = 0.2
need_delete_cols = []
for index,row in miss_analy.iterrows():
if row['missRate'] > alpha:
need_delete_cols.append(row['index'])
#delete most empty col
data_all = data_all.drop(columns=need_delete_cols, axis=0, inplace=True)有的人可能觉得这种方法比较麻烦,又要可视化又要单独删除,如果不需要可视化或者探索缺失值的具体情况,我这里也提供一个非常简单粗暴的缺失值删除办法
data_all=data_all.dropna(thresh=len(data_all)*alpha, axis=1)以上一行代码完成了,前述的所有删除工作。
删除单值特征
单值特征是指某一列只有一个值,不存在变化的情况,这种特征是没有任何意义的,需要直接删除
desc = data_all.astype('str').describe()
mask = desc.loc['unique',:] == 1
data_all.drop(labels=desc.columns[mask],axis=1,inplace=True)异常数据处理
这里我说的异常数据一般是指每个特征中的离群数据,因为我的任务是建立一个通用的,泛化能力较强的模型,所以这里对每个特征的离群数据进行删除操作,避免后续模型为了拟合离群点,导致过拟合的现象。那如何判断某个数据点是否离群或者异常呢?这里提供两种方法,每个方法都有优劣势,后续我再细说。
3σ方式
用传统意义上的统计方法实现,3σ我就不细说了,正态分布3σ之外的数据为异常
def del_outlier(dataset):
temp = dataset.copy()
for each in temp.columns:
std = np.std(temp[each])
mean = np.mean(temp[each])
sigma = 4 * std
limit_up = mean + sigma
limit_bottom = mean - sigma
temp = temp.query('({} > {}) and ({} <{})'.format(each,limit_bottom,each,limit_up))
print(limit_up,limit_bottom)
print(each,temp.shape)
return temp这个方式比较通用,最适合看起来服从正太分布的特征。
分位数方式
首先我放个连接(https://www.itl.nist.gov/div898/handbook/prc/section1/prc16.htm),里面描述了什么是离群点。
def del_outlier(dataset):
temp = dataset.copy()
for each in temp.columns:
first_quartile = temp[each].describe()['25%']
third_quartile = temp[each].describe()['75%']
iqr = third_quartile - first_quartile
limit_up = third_quartile + 3 * iqr
limit_bottom = first_quartile - 3 * iqr
temp = temp.query('({} > {}) and ({}<{})'.format(each,limit_bottom,each,limit_up))
print(limit_up,limit_bottom)
print(each,temp.shape)
return temp分位数方式存在一个问题,如果离群点非常少,导致3/4和1/4分位数相等,就无法执行下去。
个人还是比较推荐σ的方法。
特征信息量
特诊信息量是描述的某一特征的数据是否有足够的信息熵去辅助建模,如果一个特诊的信息熵很低,那说明该特诊基本上不存在什么波动,蕴含的信息量极少(当然可能要做完归一化后观测起来会比较明显),那该特诊就可以直接删除。
以下为计算信息熵的Python代码:
from scipy.stats import entropy
from math import log, e
import pandas as pd
##""" Usage: pandas_entropy(df['column1']) """
def pandas_entropy(column, base=None):
vc = pd.Series(column).value_counts(normalize=True, sort=False)
base = e if base is None else base
return -(vc * np.log(vc)/np.log(base)).sum()执行删除信息熵小的特诊:
for each in feature_list:
# print(each,pandas_entropy(data_all[each]))
if pandas_entropy(data_all[each]) < 1:
print(each,pandas_entropy(data_all[each]))
data_all.drop(columns=[each],axis=1,inplace=True)处理不同数据类型特诊(时间特征为例)
DataFrame数据类型通常包含Object,int64,float64,,对于后两者我们没必要可以去改变,但是对于Object类型的数据,不同含义的Object数据做不同处理。笔者这里举例时间格式的Object数据处理。
数据类型查看与统计
data_all.dtypes.values_counts()将时间的Object数据进行转换。
data_all[key] = pd.to_datetime(data_all[key])
如果存在类似开始时间-结束时间的时间对数据,可以将两者相减,得到时间片段数据,例如:
data_all[time_gap] = pd.to_datetime(data_all['end']) - pd.to_datetime(data_all['start'])然后将时间段数据转为小时,或者分钟,或者秒:
data_all[key] = data_all[key].apply(lambda x: x.total_seconds() / 60 / 60)以上为个人通常来讲的数据预处理过程,建议在每执行一步后数据重新命名,并保存一份备份。
以上。
如有什么建议或者错误,大家随时拍砖。









