
进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:IT贫道_大数据OLAP体系技术栈,Apache Doris,Kerberos安全认证-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
博主个人B栈地址:豹哥教你大数据的个人空间-豹哥教你大数据个人主页-哔哩哔哩视频
目录
在clickhouse中熔断机制是限制资源被过度使用的一种保护机制,当使用的资源数量达到阈值时,正在进行的操作会被自动中断,按照使用资源统计方式不同,熔断机制分为两类。
1. 根据时间周期的累计用量熔断
这种方式下,系统资源的用量是按照时间周期累计统计,当累计量达到阈值,则直到下个计算周期开始之前,该用户将无法继续进行操作。可以通过users.xml中<quotas>标签来定义资源配额,可配配置项如下:
<quotas>
<default><!-- 自定义名称 -->
<interval>
<duration>3600</duration><!-- 时间周期,单位:秒 -->
<queries>0</queries>
<erros>0</erros>
<result_rows>0</result_rows>
<read_rows>0</read_rows>
<execution_time>0</execution_time>
</interval>
</default>
</quotas>以上配置中各项解释如下:
- default:表示自定义名称,全局唯一。
- duration:表示累积的时间周期,单位是秒。
- queries:表示在周期内允许执行的查询次数,0表示不限制。
- errors:表示在周期内允许发生异常的次数,0表示不限制。
- result_row:表示在周期内允许查询返回的结果行数,0表示不限制。
- read_rows:表示在周期内在分布式查询中,允许远端节点读取的数据行数,0表示不限制。
- execution_time:表示周期内允许执行的查询时间,单位是秒,0表示不限制。
现在测试资源配额,我们在users.xml中<quotas>标签下新建一组<limit_1>资源配额,配置如下:
<limit_1><!-- 自定义名称 -->
<interval>
<duration>3600</duration><!-- 时间周期,单位:秒 -->
<queries>5</queries>
<errors>5</errors>
<result_rows>0</result_rows>
<read_rows>0</read_rows>
<execution_time>3600</execution_time>
</interval>
</limit_1>以上配置在1小时的周期内只允许5次查询。同时将此组资源配置分配给用户zhangsan:
<zhangsan>
... ...
<quota>limit_1</quota>
</zhangsan>配置完成后,使用zhangsan登录clickhoue,执行如下查询测试:
node1 :) select * from person_info;
注意:以上查询连续执行5次,会报错:
DB::Exception: Quota for user `zhangsan` for 3600s has been exceeded: queries = 6/5. Interval will end at 2021-10-28 17:00:00. Name of quota template: `limit_1`. (QUOTA_EXPIRED)经过测试熔断机制已经生效。
至此,用户users.xml中的配置附件:https://download.csdn.net/download/qq_32020645/88360215
2. 根据单次查询的用量熔断
这种情况下,系统资源的用量是按照单词查询统计的,而具体的熔断规则是由许多不同配置项组成,这些配置项需要配置在用户对应的profile角色中,如果某次查询使用的资源用量达到了阈值,则会被中断。例如:
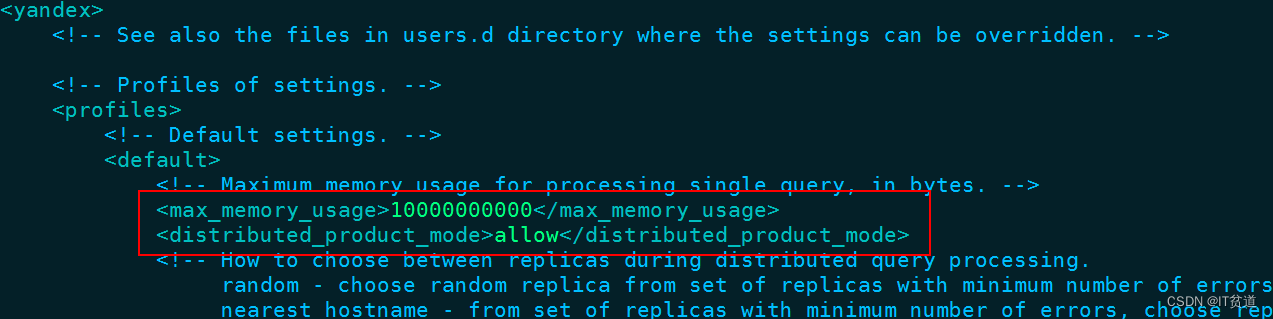
以上例子中配置项“max_memory_usage”限定了单词查询可以使用的内存量,默认情况下规定不能超过10GB,如果一次查询的内存用量超过10G则会报错。需要注意的是,在单词查询的内存用量统计中,clickhouse是以分区为最小单元进行统计,不是以总的数据总量统计,这意味着单次查询的实际内存用量是有可能超过阈值的。
下面例举一些配置的角色中常用的配置项:
1) max_memory_usage
在单个clickhouse服务进程中,运行一次查询限制使用的最大内存量,默认值为10GB。
2) max_memory_usage_for_user
在单个clickhouse服务进程中,以用户为单位进行统计,单个用户在运行查询时限制使用的最大内存量,默认值为0,即不做限制。
3) max_memory_usage_for_all_queries
在单个clickhouse服务进程中,所有运行的查询累计加在一起所限制使用的最大内存量,默认为0,即不做限制。
4) max_partitions_per_insert_block
在单次Insert写入的时候,限制创建的最大分区个数,默认值为100个,如果超出阈值,会出现异常。
5) max_rows_to_group_by
在执行Group By聚合查询时,限制去重后聚合Key的最大个数,默认值为0,即不做限制。当超过阈值时,其处理方式由group_by_overflow_mode参数决定。
6) group_by_overflow_mode
当max_rows_to_group_by熔断规则触发时,group_by_overflow_mode将会提供三种护理方式。
- throw:抛出异常,默认值。
- break:立即停止查询,并返回当前数据。
- any:仅根据当前已存在的聚合key继续完成聚合查询。
7) max_bytes_before_external_group_by
在执行group by聚合查询的时候,限制使用的最大内存量,默认值为0,不做限制,当超过阈值时,聚合查询将会使用本地磁盘。
8) join_use_nulls
当两张表进行join操作时,如果左表中的记录在右表中不存在,那么右表相应字段会返回NULL,如果配置join_use_nulls为1,那么对应字段会返回该字段相应数据类型的默认值,此值默认为0,即在右表找不到对应数据时返回NULL。










