一、redis
1、缓存-缓存穿透
缓存穿透就是查询一个数据库不存在的数据,这样就会缓存不命中导致一直查询数据库
解决方案:
1、设置空值
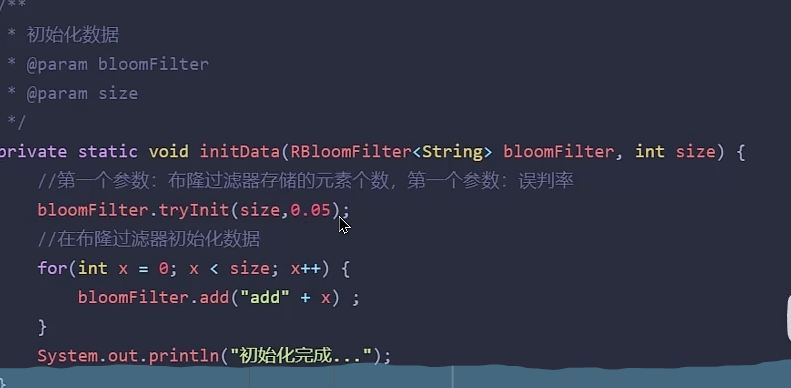
2、布隆过滤器
布隆过滤器误判解决:
1、redis分布式锁
2、给布隆过滤器设置误判率
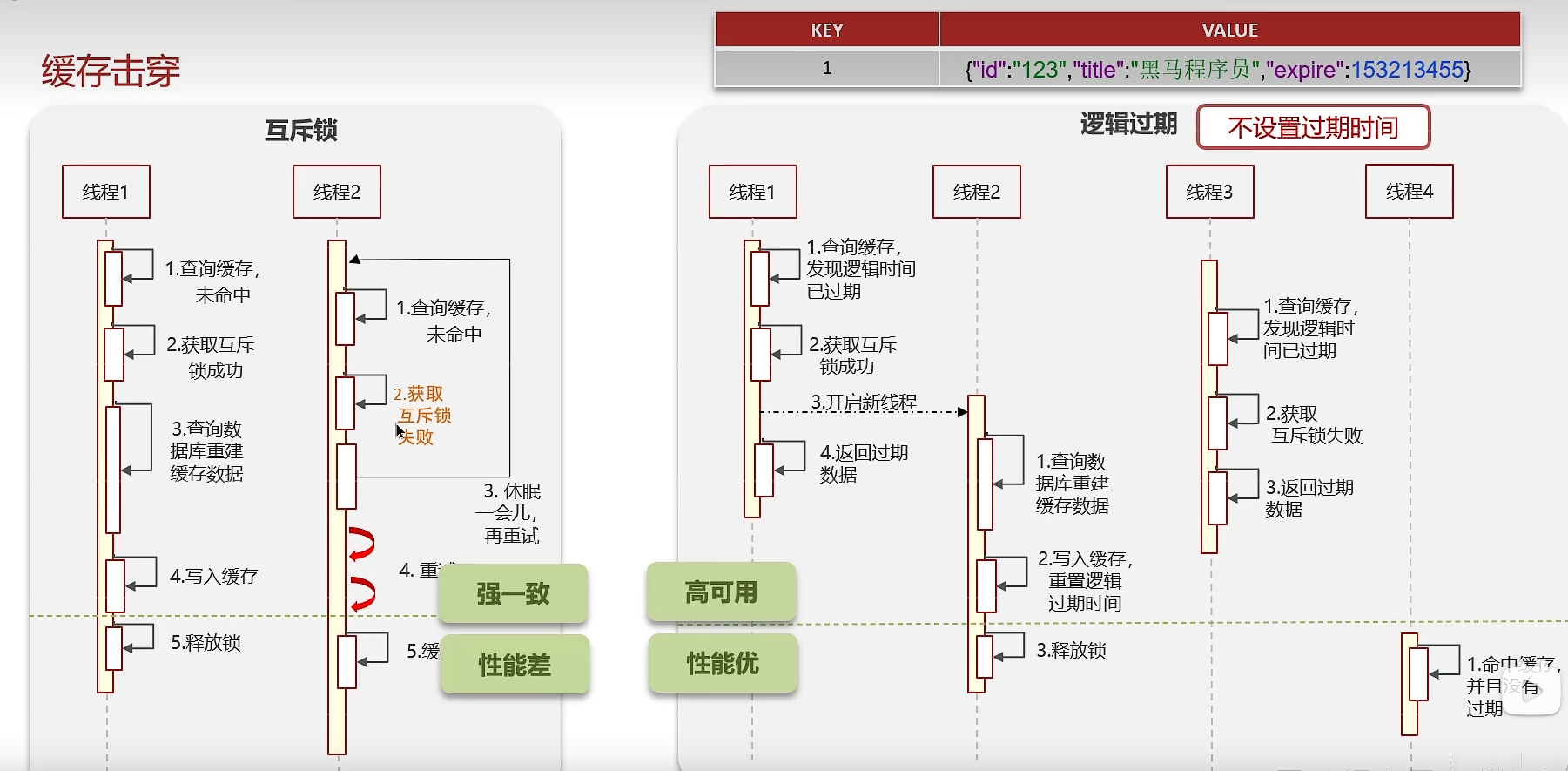
2、缓存击穿
缓存击穿的意思是对于设置了过期时间的key,缓存在某个时间点过期的时
候,恰好这时间点对这个Key有大量的并发请求过来,这些请求发现缓存过
期一般都会从后端 DB 加载数据并回设到缓存,这个时候大并发的请求可能
会瞬间把 DB 压垮。
解决方案有两种方式:
第一可以使用互斥锁:当缓存失效时,不立即去load db,先使用如 Redis 的
setnx 去设置一个互斥锁,当操作成功返回时再进行 load db的操作并回设缓
存,否则重试get缓存的方法
第二种方案可以设置当前key逻辑过期,大概是思路如下:
①:在设置key的时候,设置一个过期时间字段一块存入缓存中,不给当前
key设置过期时间
②:当查询的时候,从redis取出数据后判断时间是否过期
③:如果过期则开通另外一个线程进行数据同步,当前线程正常返回数据,
这个数据不是最新
当然两种方案各有利弊:
如果选择数据的强一致性,建议使用分布式锁的方案,性能上可能没那么
高,锁需要等,也有可能产生死锁的问题
如果选择key的逻辑删除,则优先考虑的高可用性,性能比较高,但是数据
同步这块做不到强一致
3、缓存雪崩

解决方案:
1、给不同的key设置随机过期时间
2、加互斥锁
3、redis集群
4、缓存预热
4、双写一致性
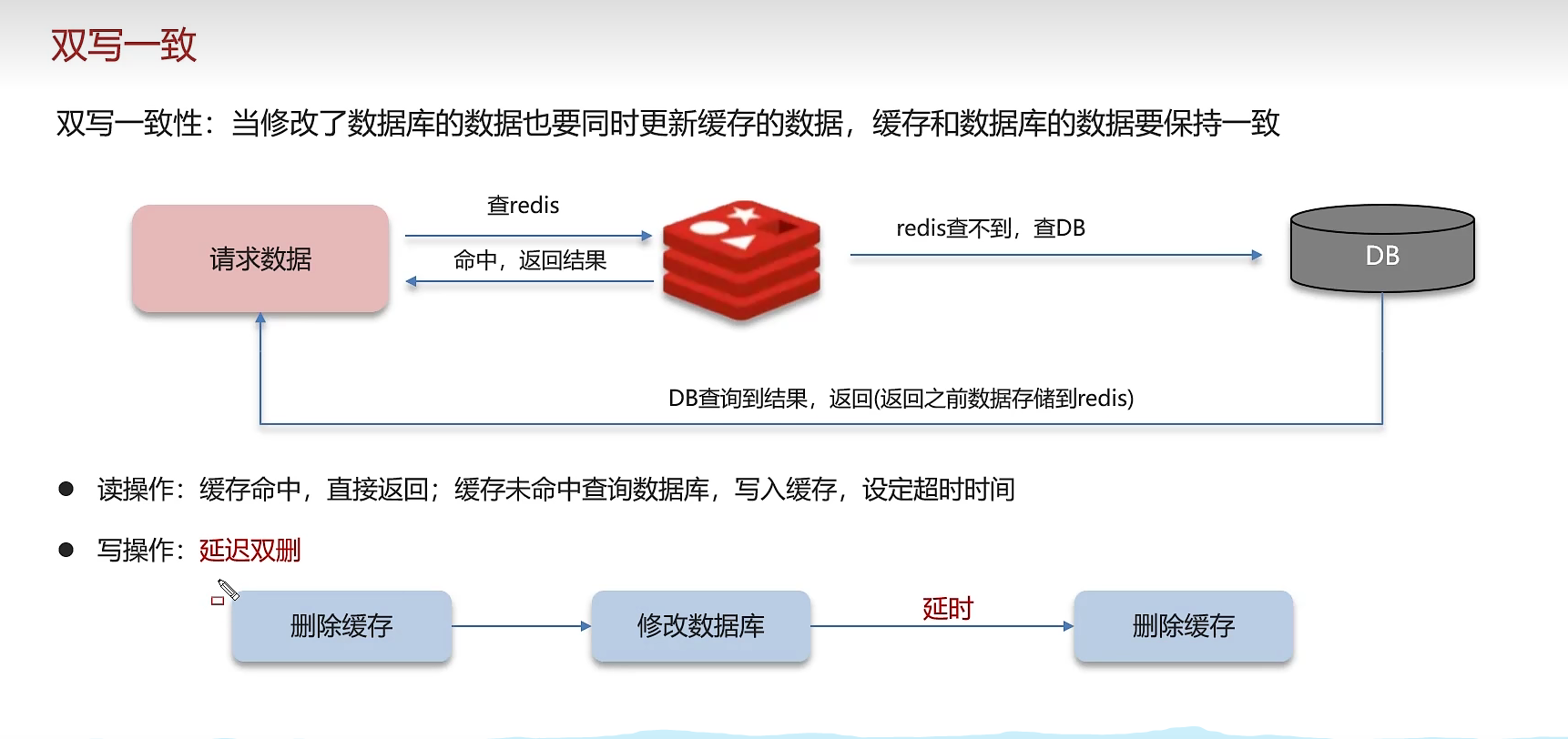
解决方案:
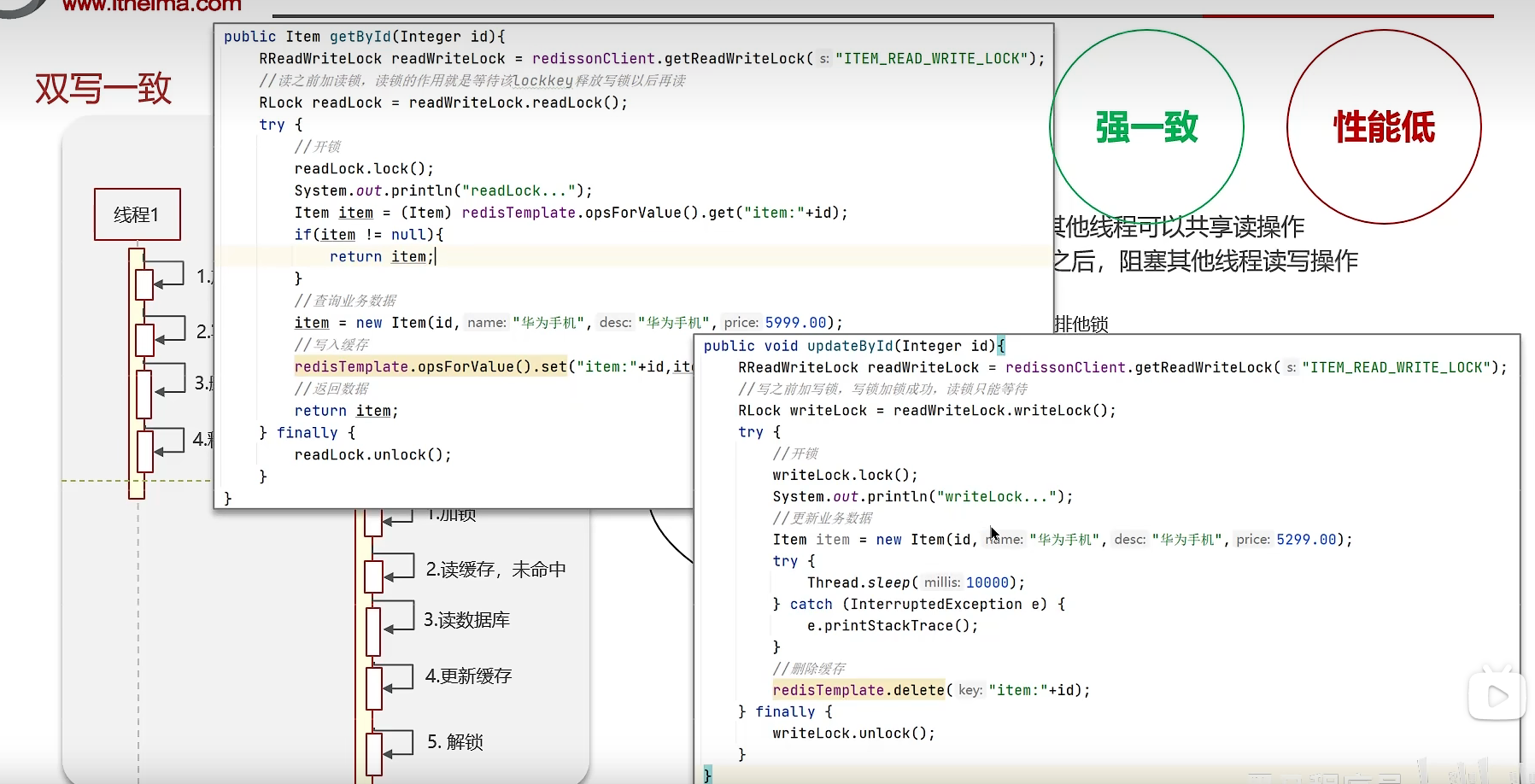
1、分布式锁
2、rabbitmq
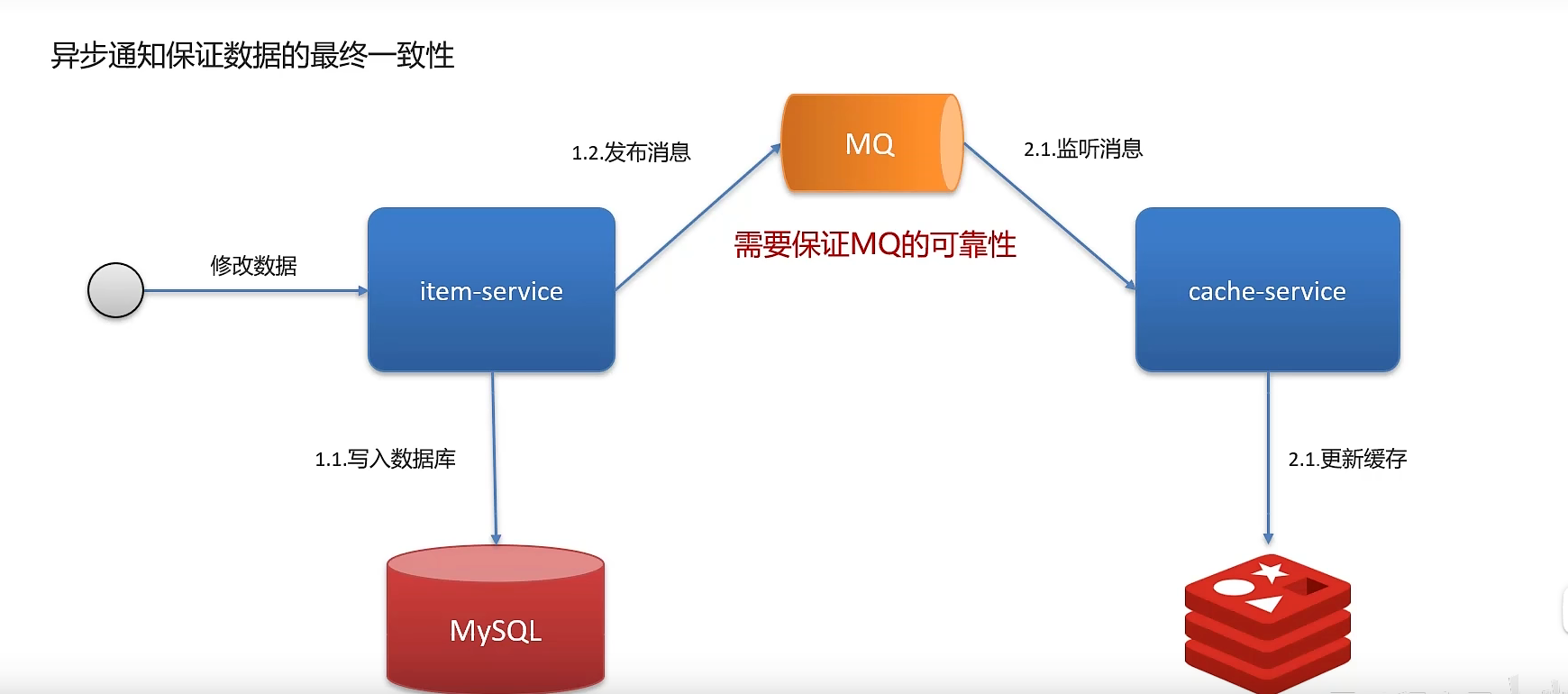
先更新数据库,成功后往消息队列发消息,消费到消息后再删除缓存,借助消息队列的重试机制来实现,达到最终一致性的效果。
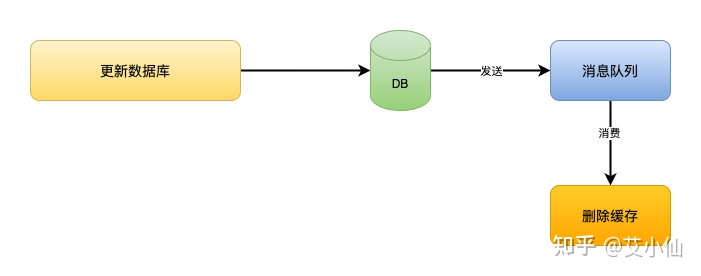
3、延迟双删
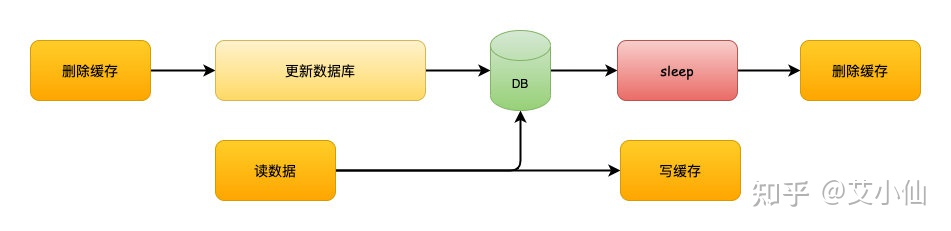
延时双删的方案的思路是,为了避免更新数据库的时候,其他线程从缓存中读取不到数据,就在更新完数据库之后,再sleep一段时间,然后再次删除缓存。
sleep的时间要对业务读写缓存的时间做出评估,sleep时间大于读写缓存的时间即可。
流程如下:
1、线程1删除缓存,然后去更新数据库
2、线程2来读缓存,发现缓存已经被删除,所以直接从数据库中读取,这时候由于线程1还没有更新完成,所以读到的是旧值,然后把旧值写入缓存
3、线程1,根据估算的时间,sleep,由于sleep的时间大于线程2读数据+写缓存的时间,所以缓存被再次删除
4、如果还有其他线程来读取缓存的话,就会再次从数据库中读取到最新值
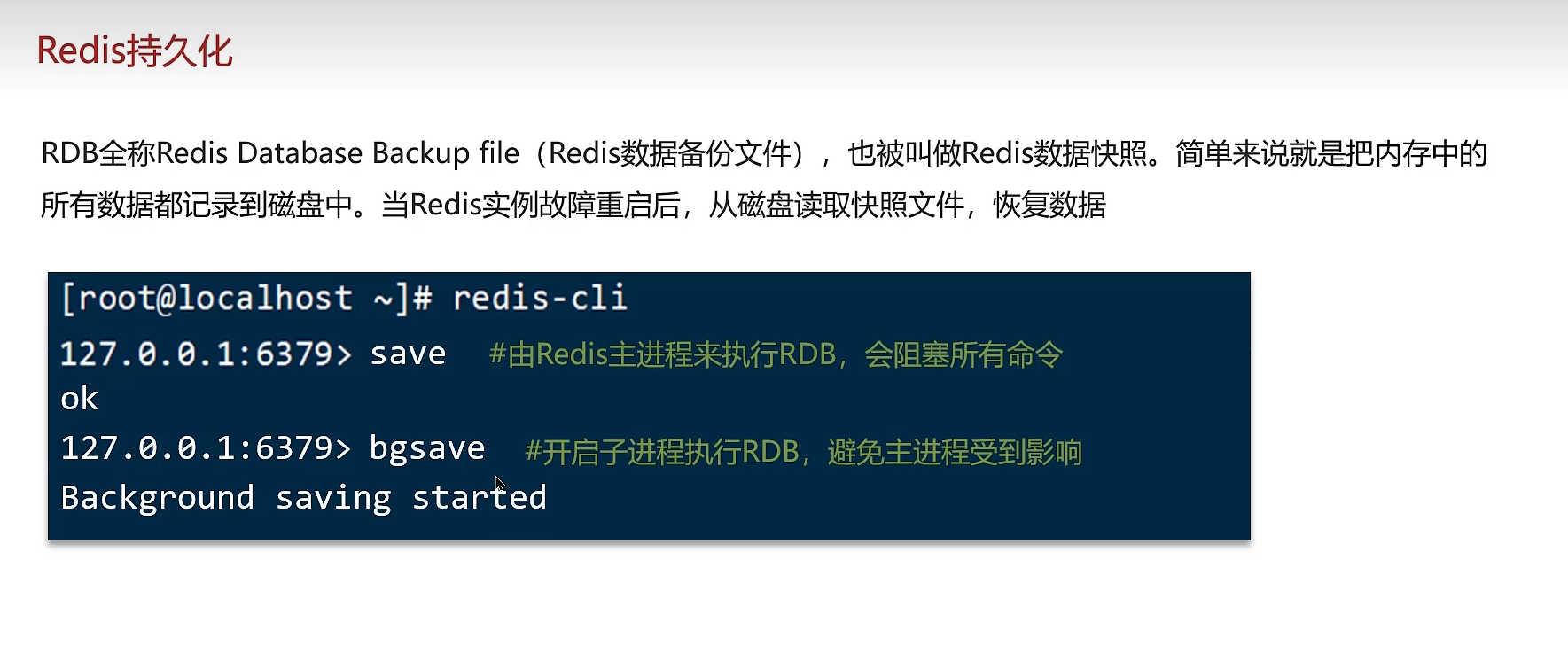
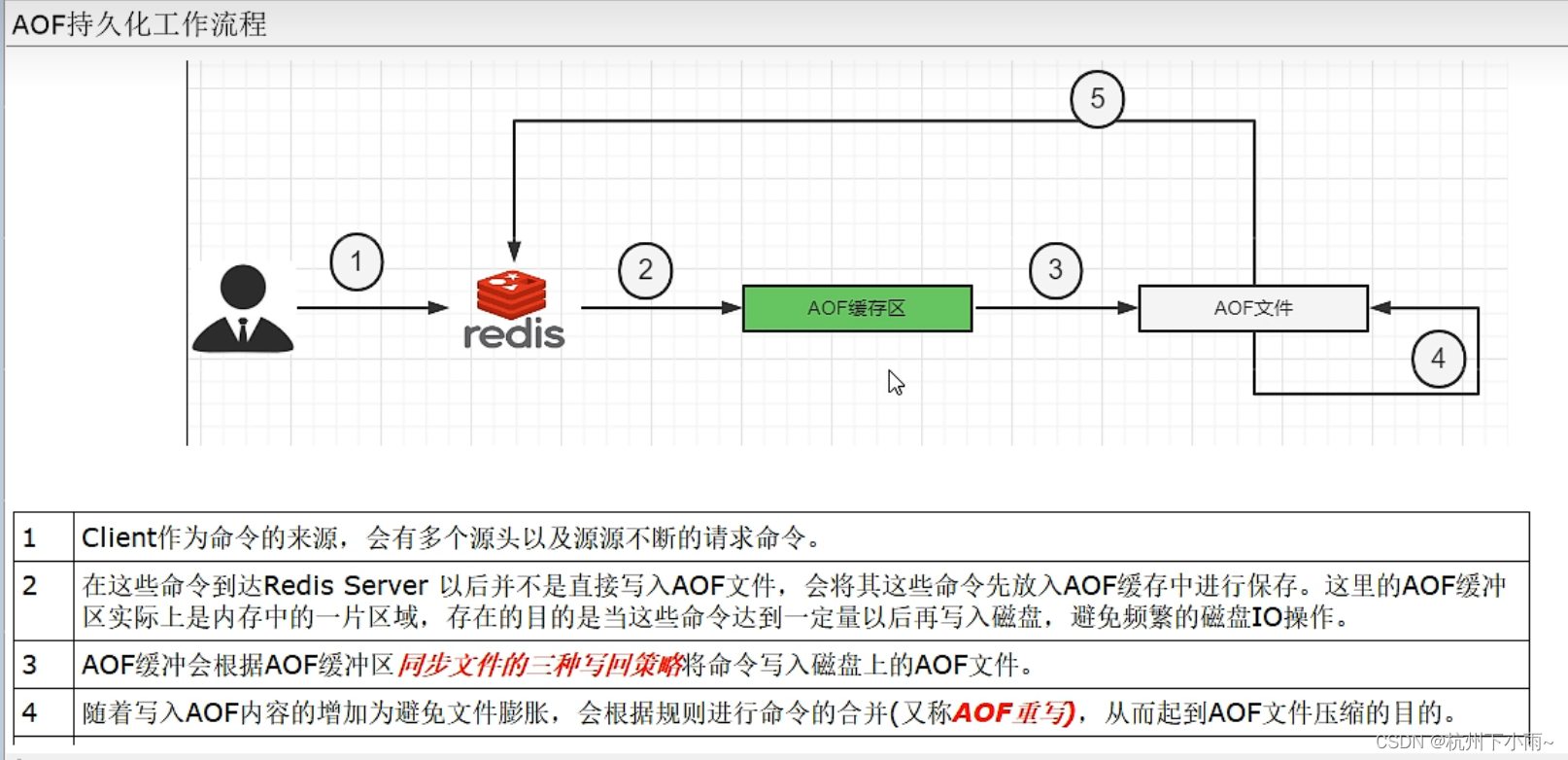
5、持久化存储
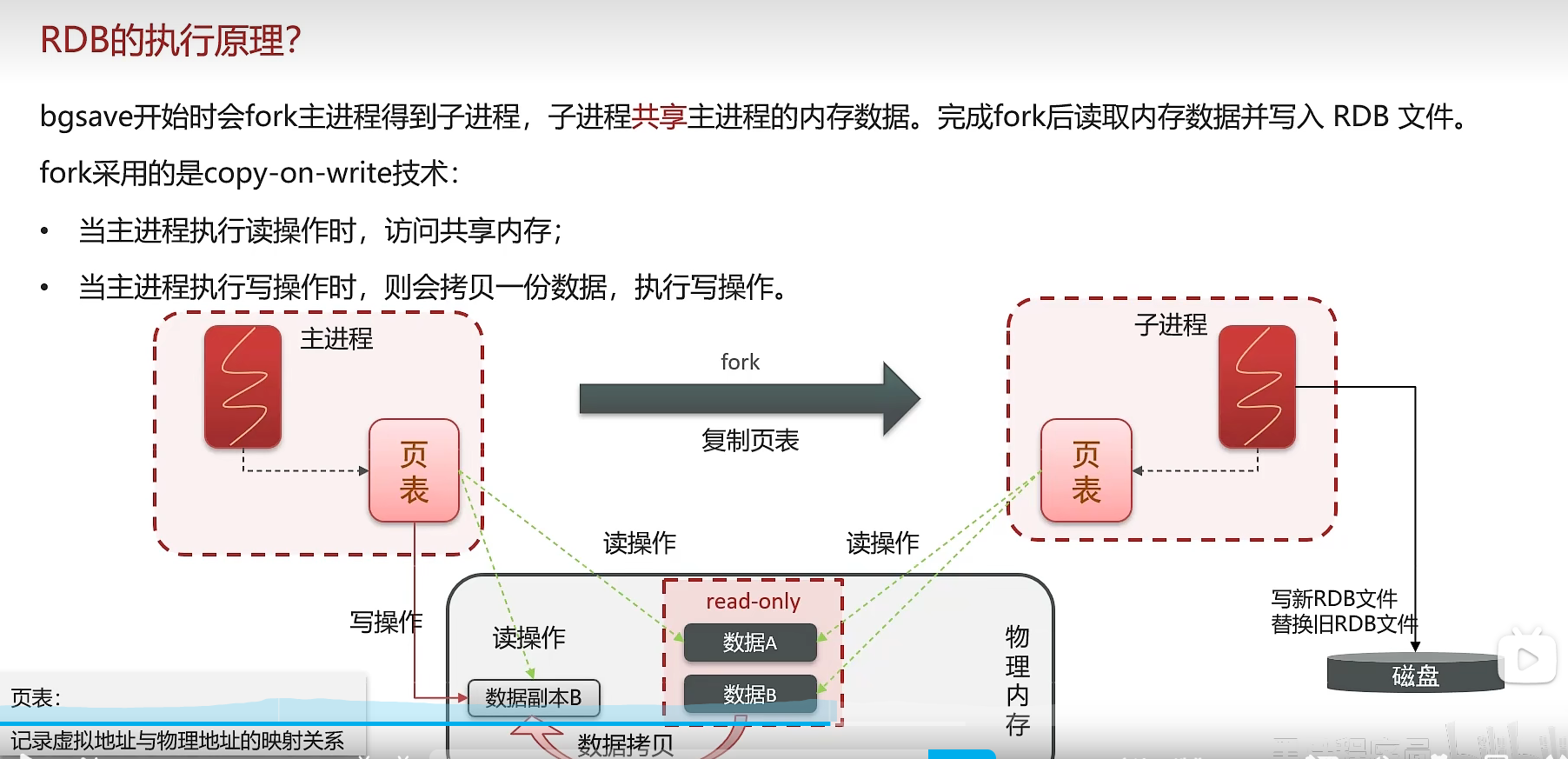
RDB

AOF
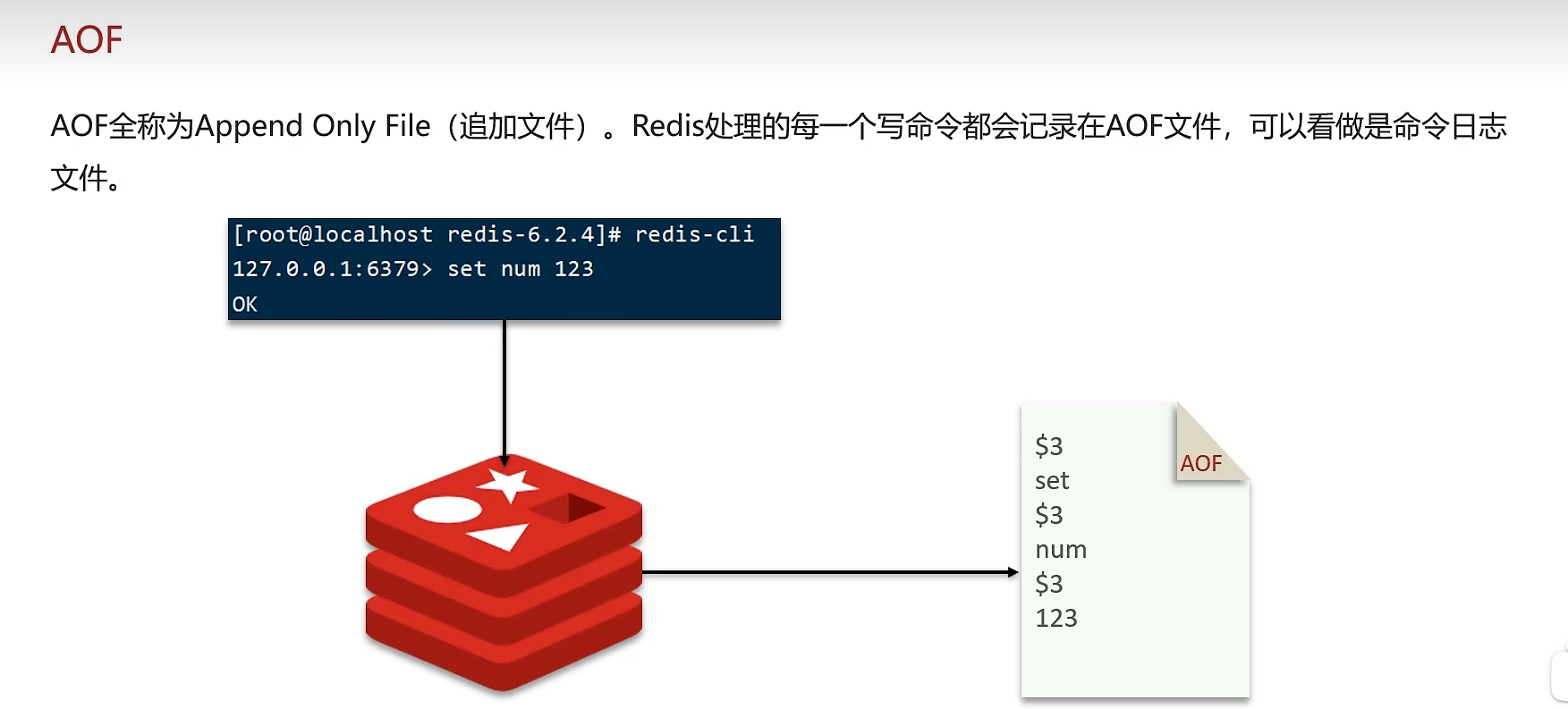



原理:
6、过期删除策略
惰性删除

定期删除

7、数据淘汰策略


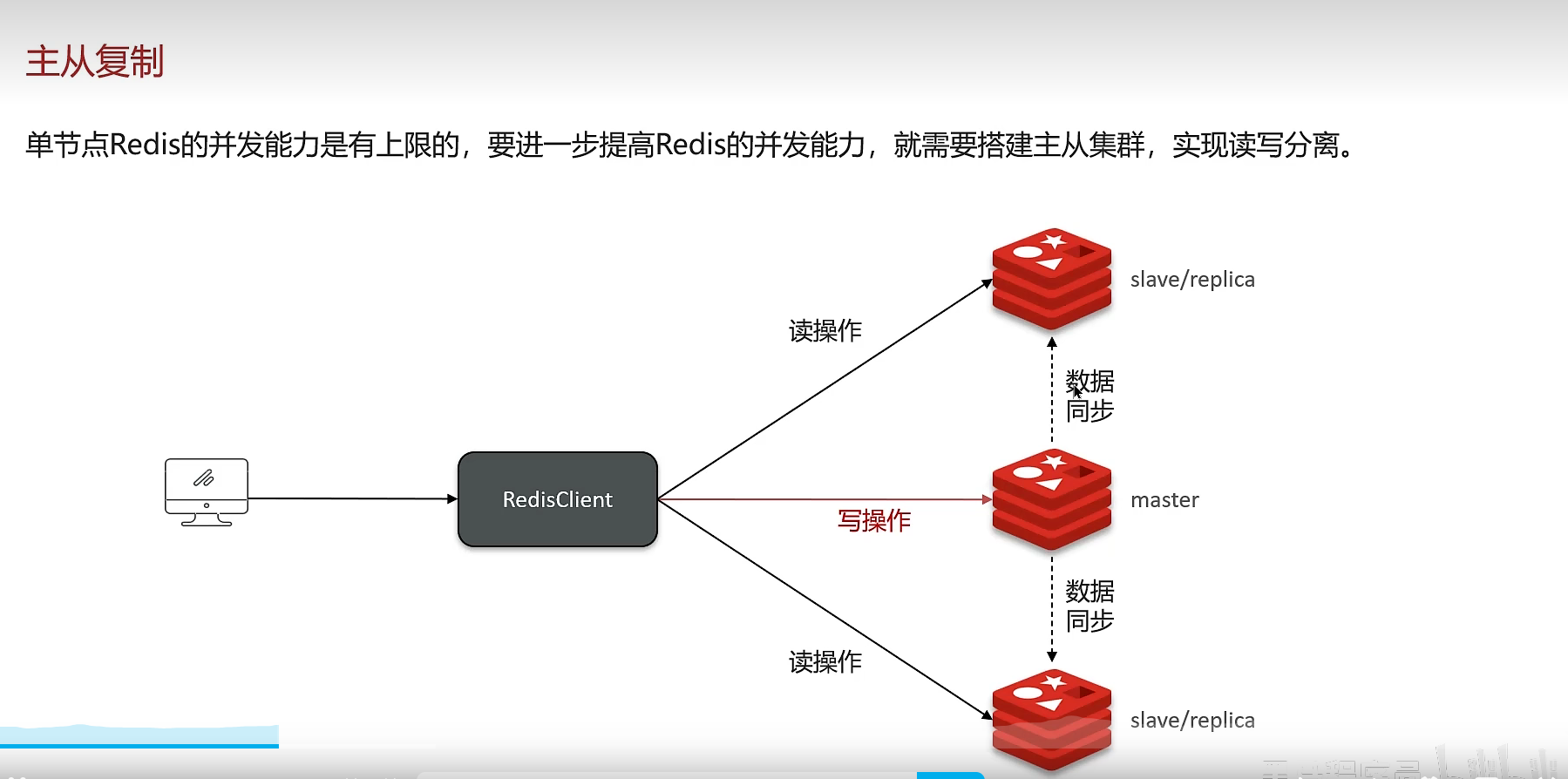
8、主从复制


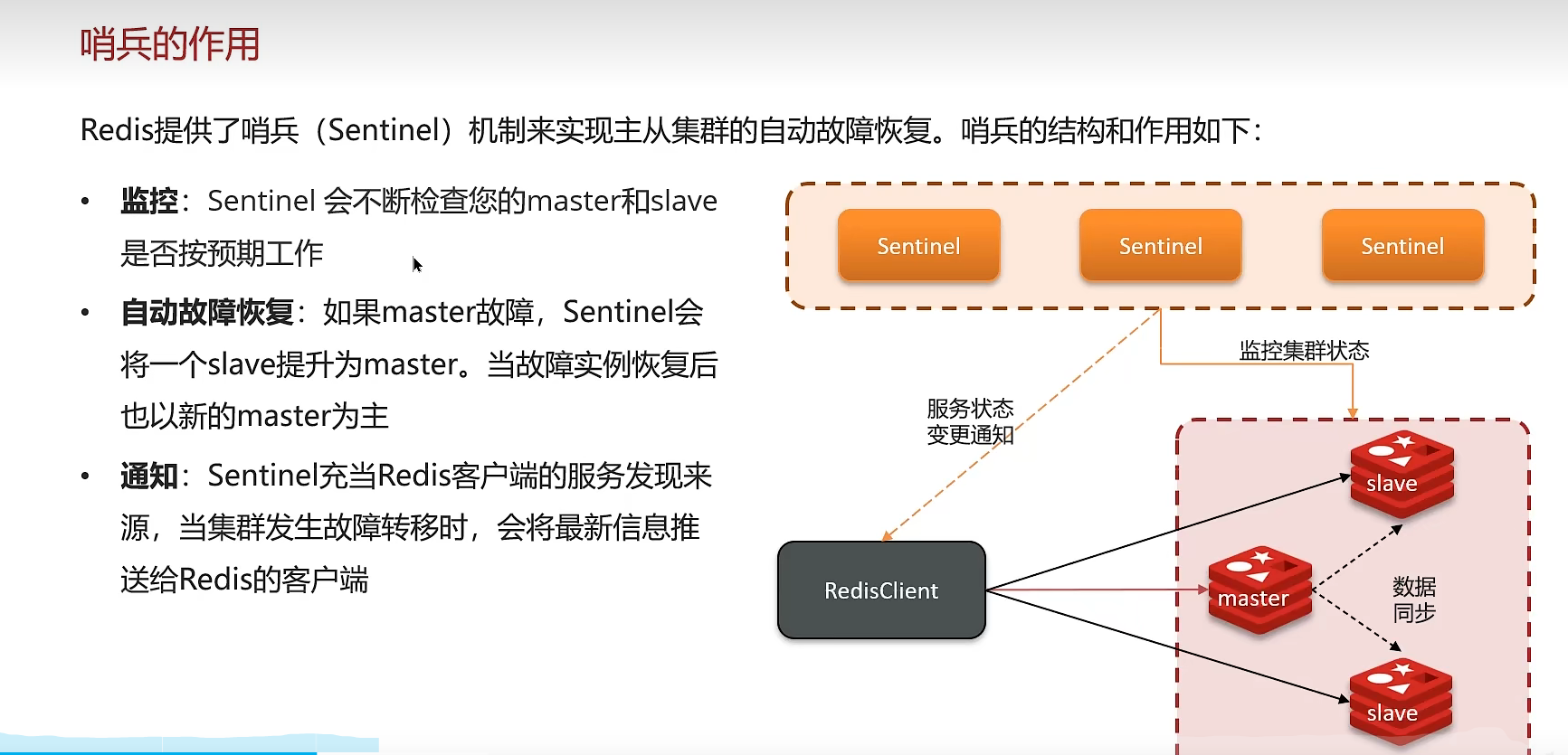
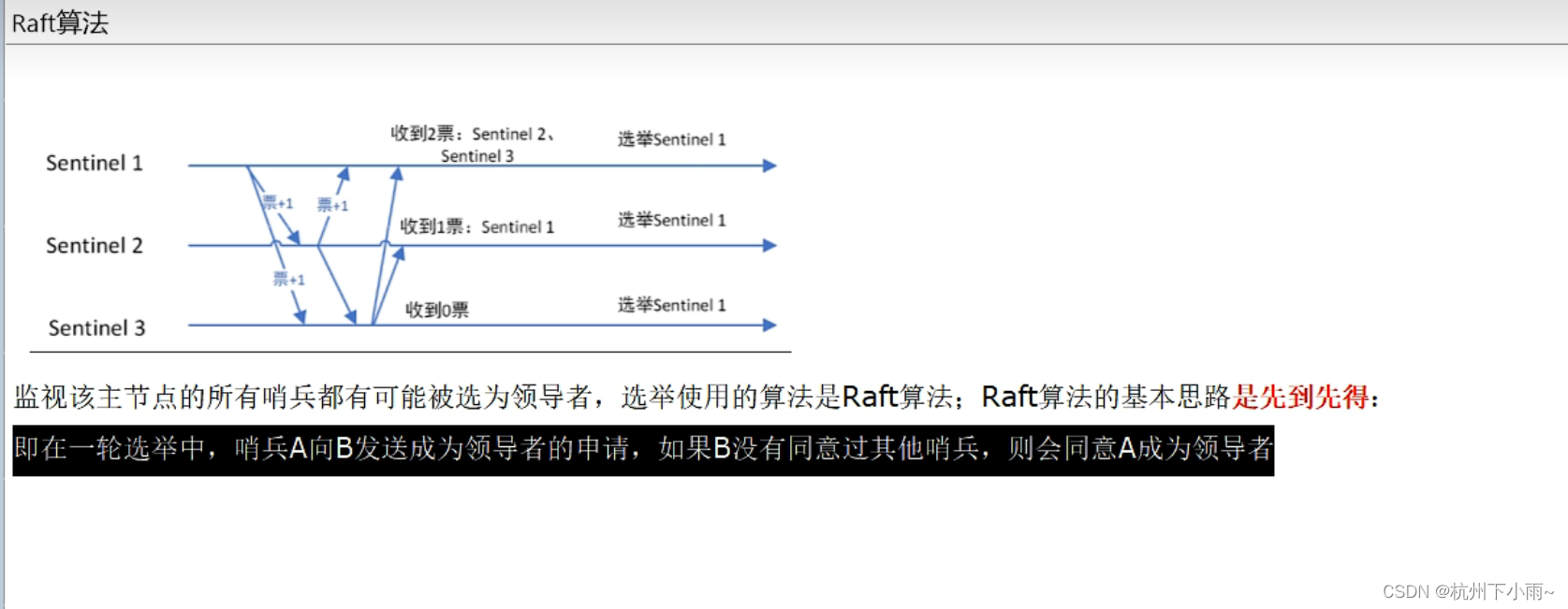
9、哨兵


10、分片集群
11、redis是单线程的为什么还这么快

二、Mysql
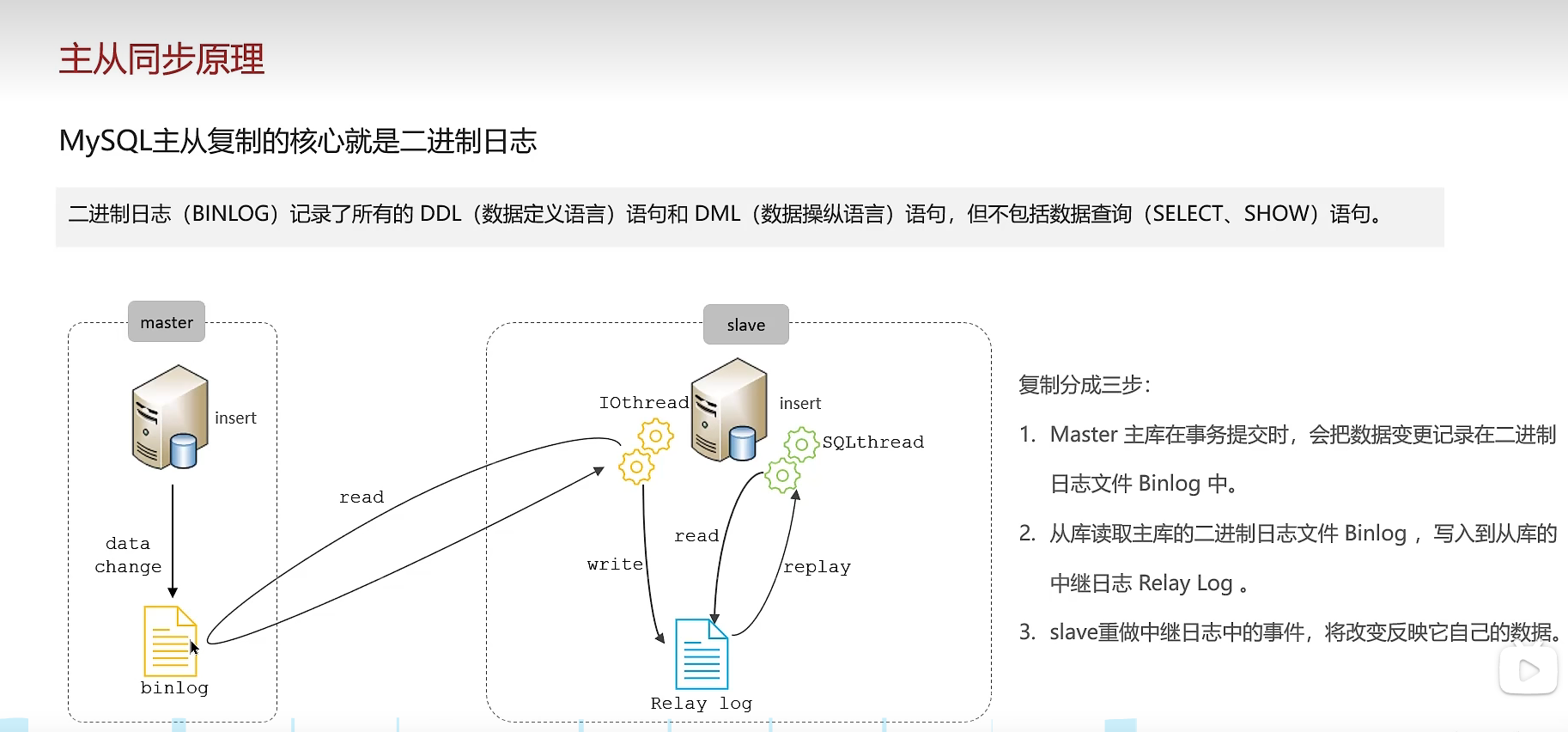
1、主从复制
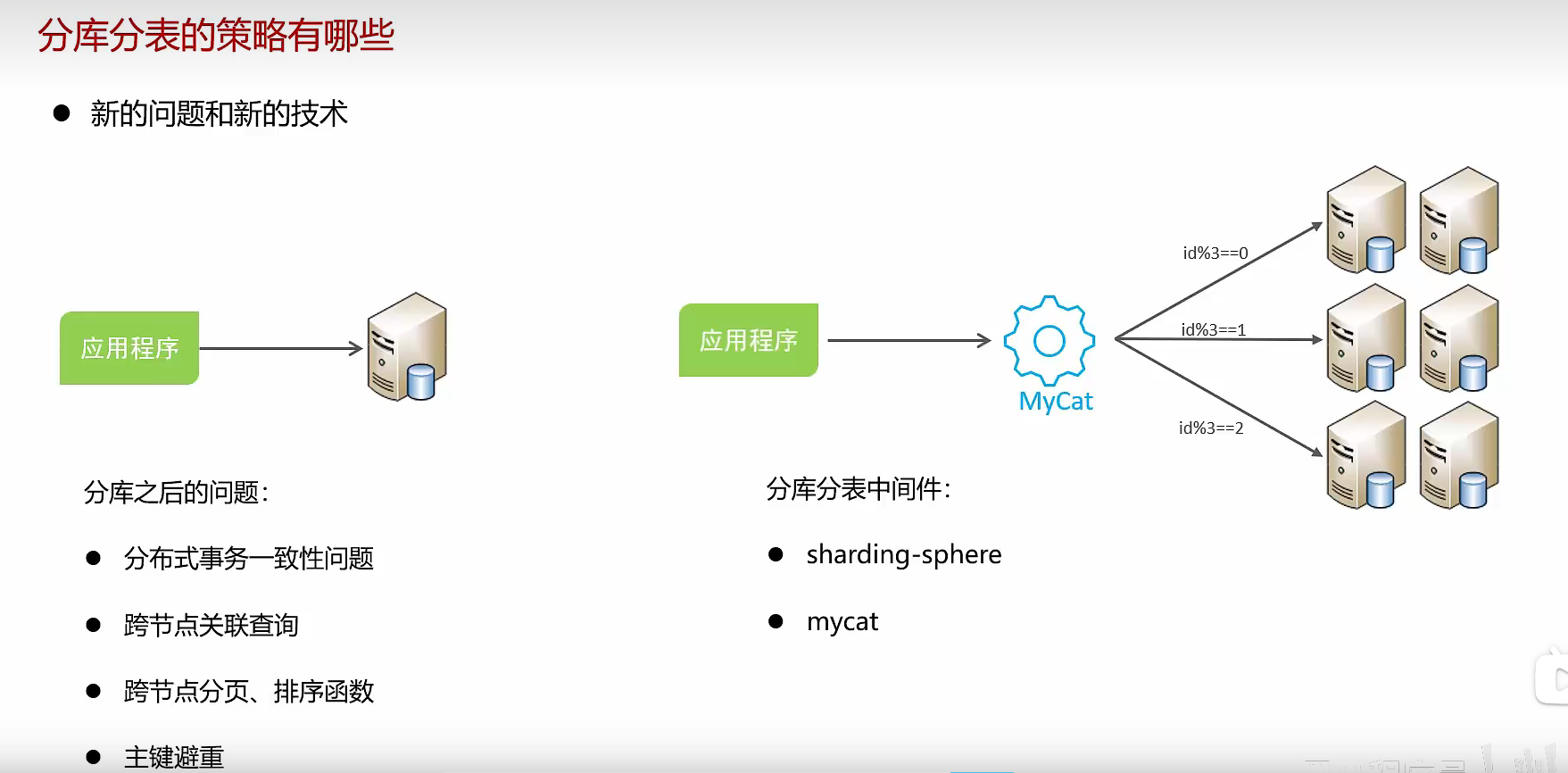
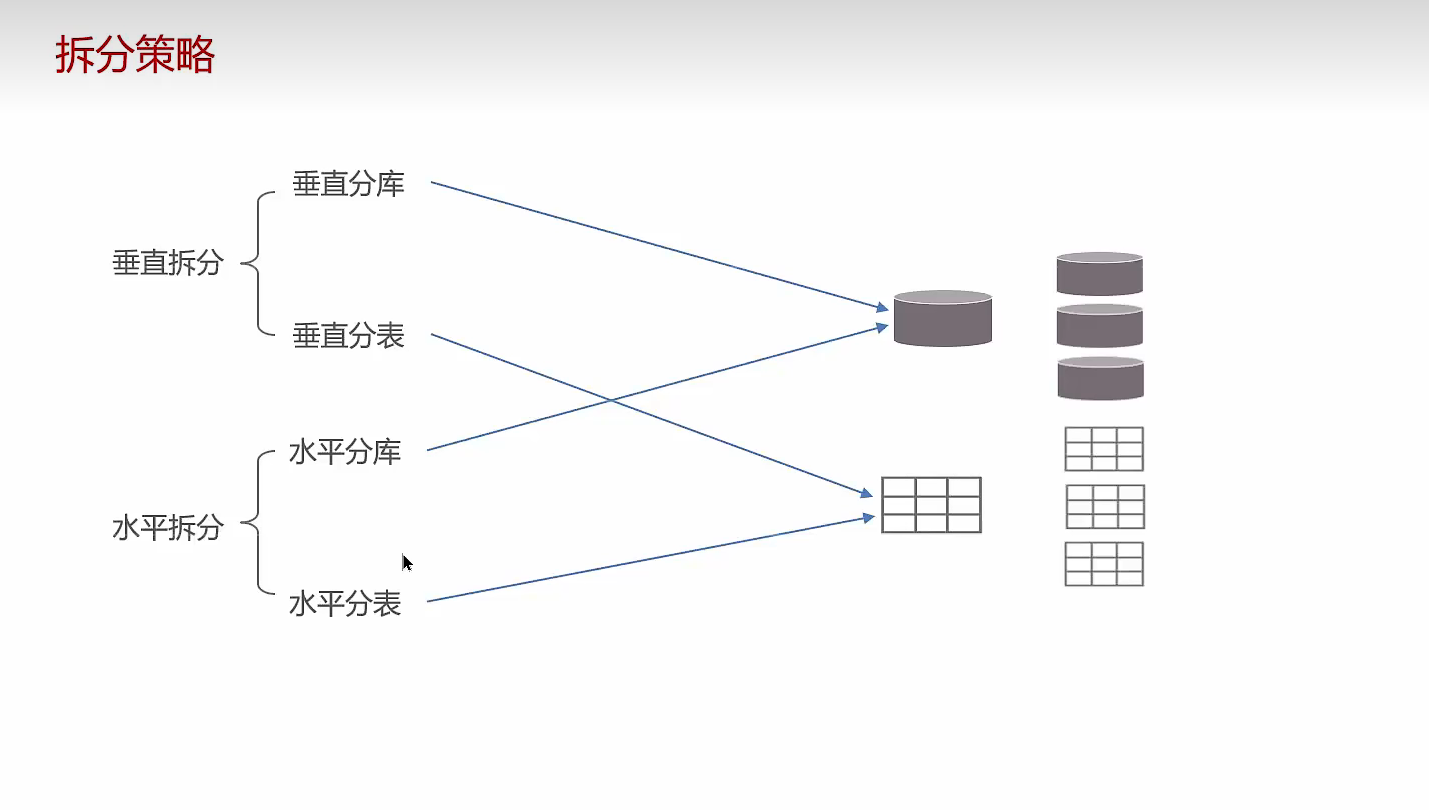
2、分库分表
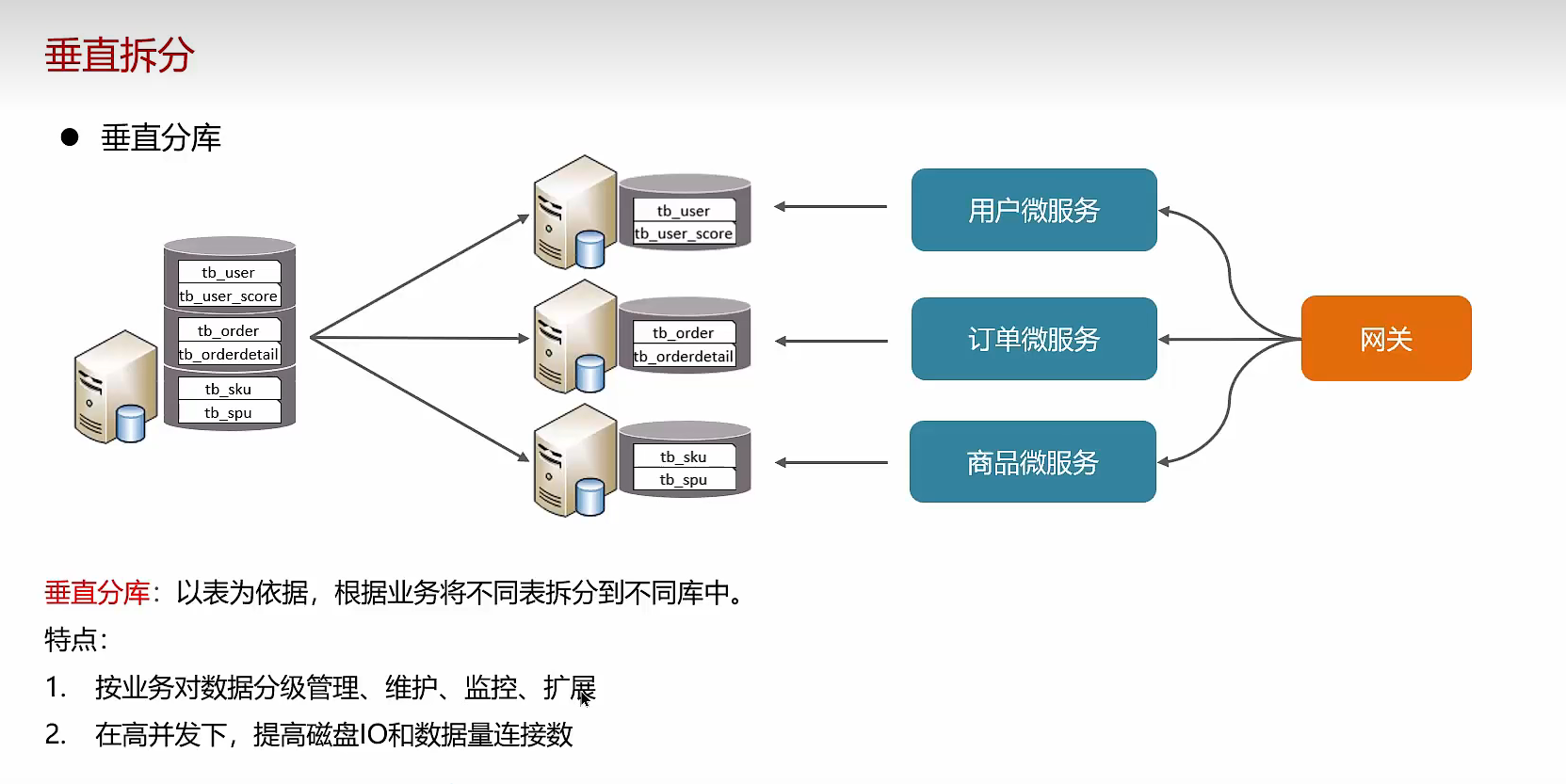
垂直分库
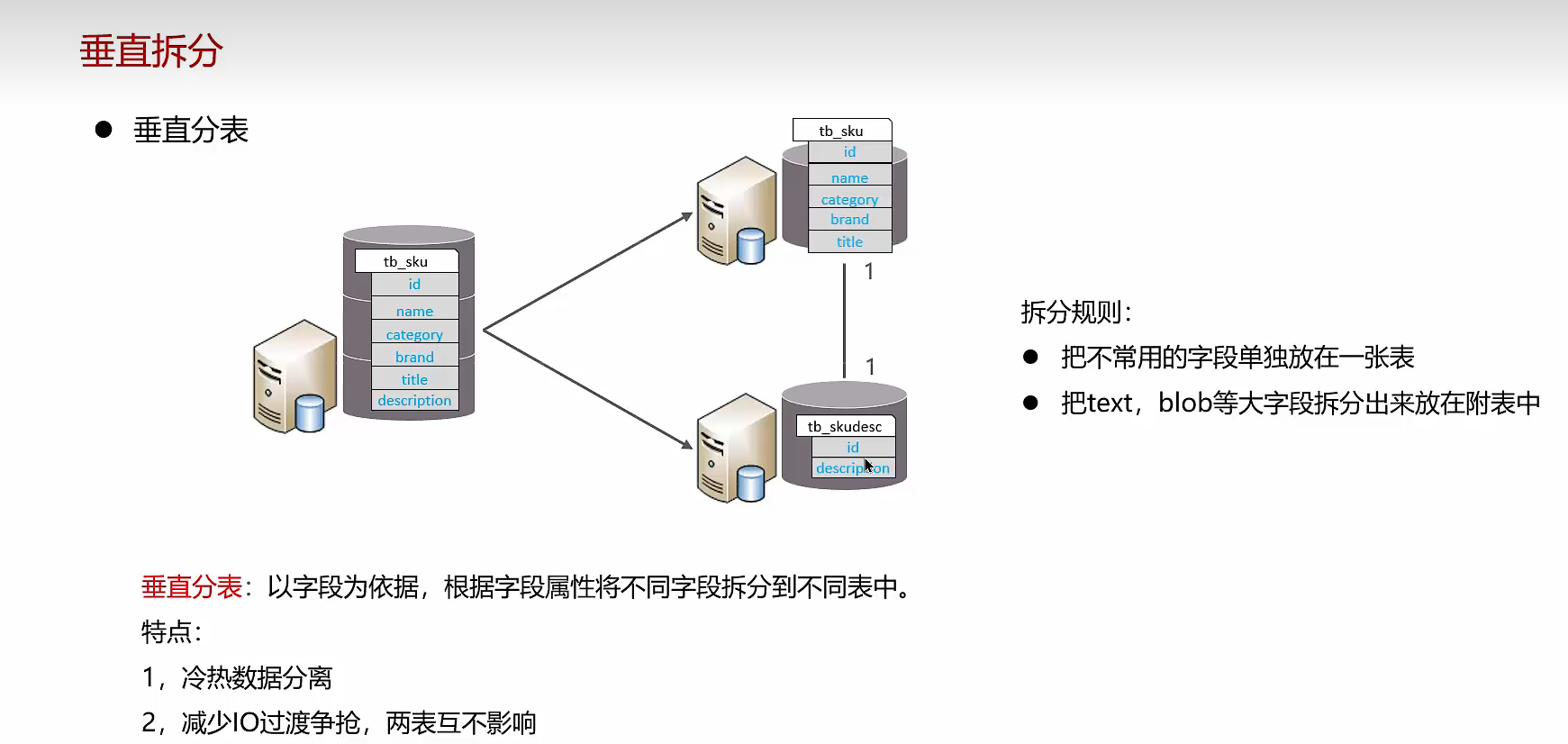
垂直分表
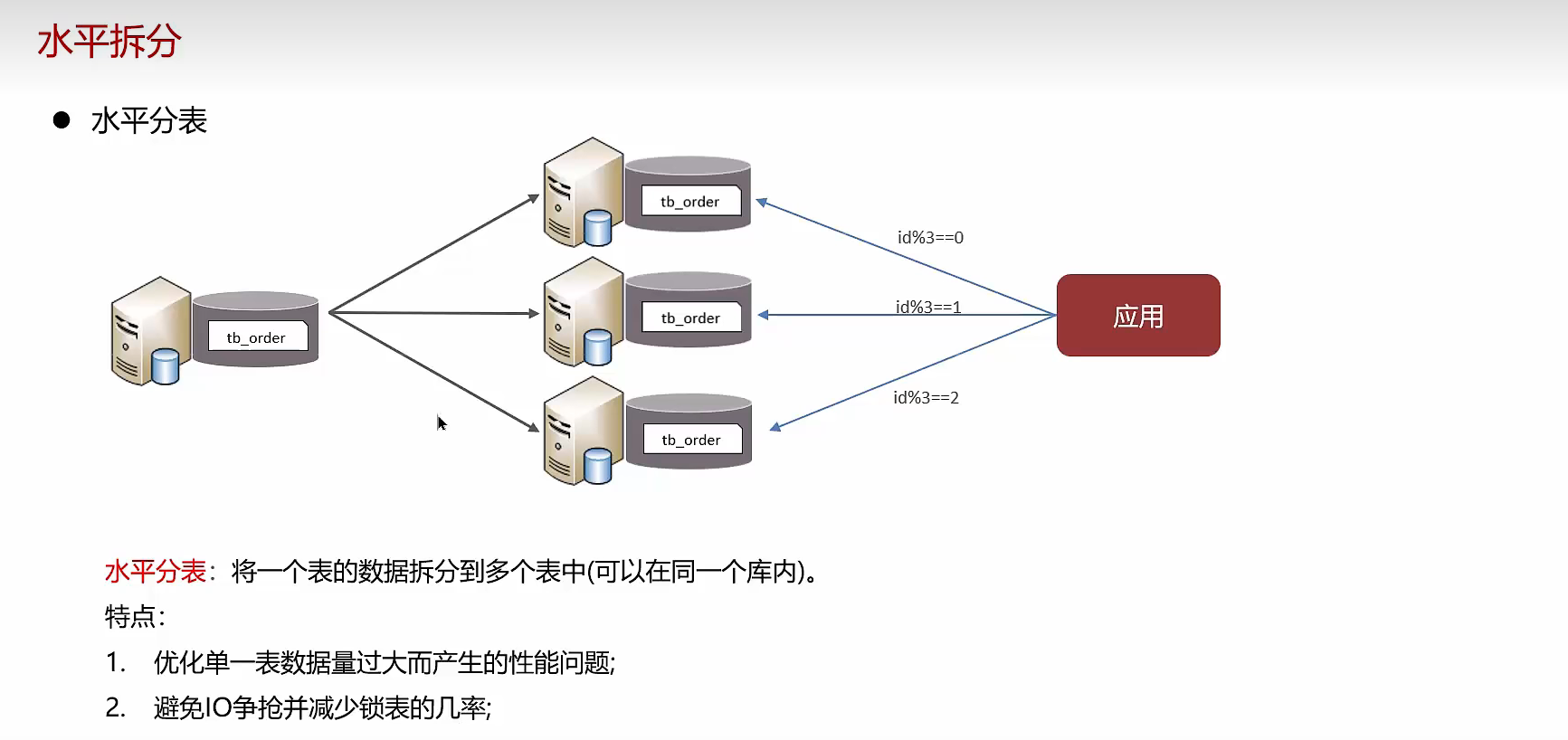
水平分库
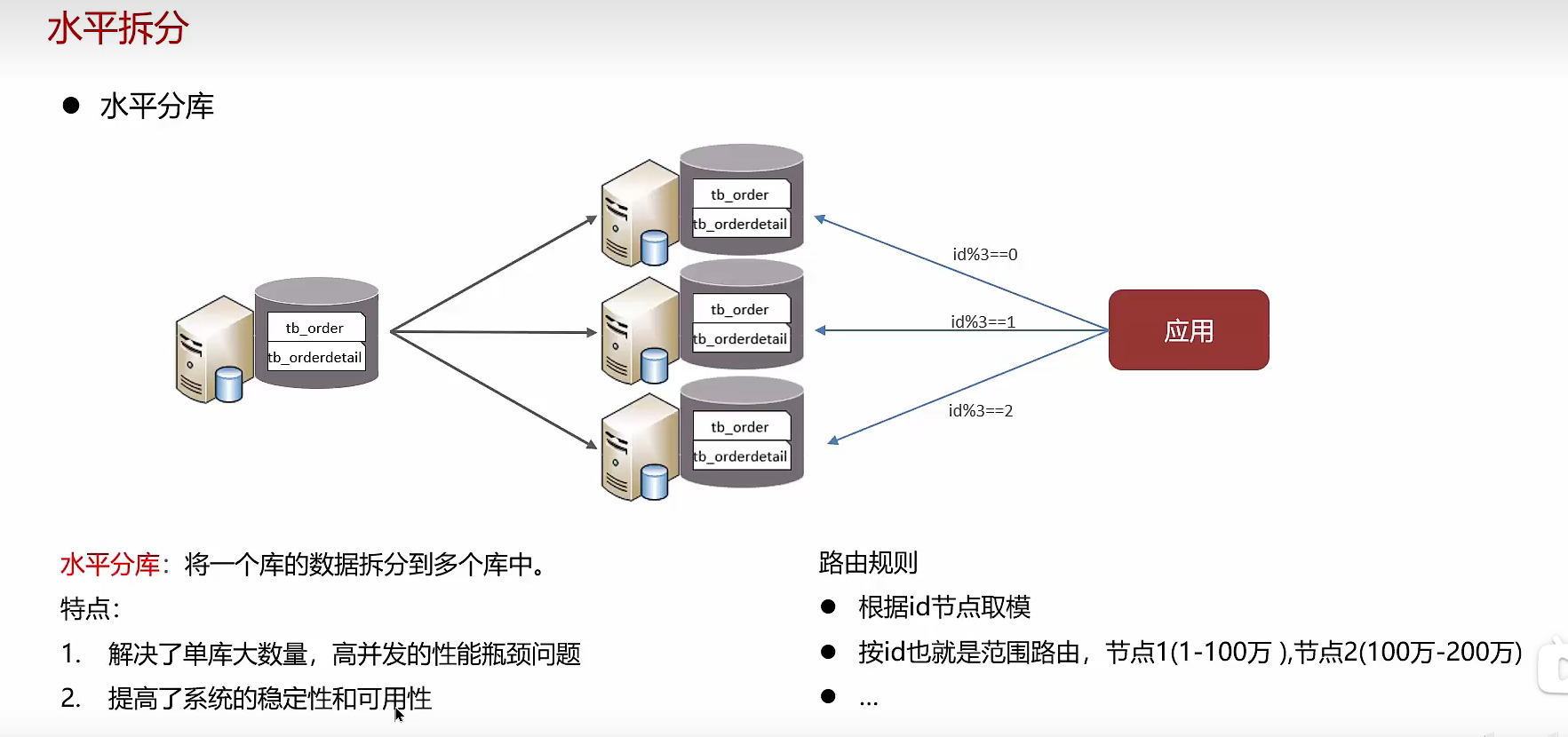
水平分表