文章目录
一、LLM模型
chatglm2模型
ChatGLM2-6B 训练参数解释
ChatGLM-6B 的部署与微调以及过程中涉及知识总结(7.26更新)
ChatGLM P-Tuning v2 避坑指南
小样本(100条)微调,建议 num_train_epochs(最大迭代轮数) =20 才能稳定拟合任务要求
百度文心千帆推荐:100条数据时, Epoch为15,1000条数据时, Epoch为10,10000条数据时, Epoch为2。
Vicuna模型
Vicuna开源代码地址:https://github.com/lm-sys/FastChat
Vicuna在线demo地址:https://chat.lmsys.org/
LLaMA2模型
LLaMA2的开源地址:https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md
LLaMA2的下载地址:https://ai.meta.com/resources/models-and-libraries/llama-downloads/
LLaMA2的官方博客地址:https://ai.meta.com/resources/models-and-libraries/llama/
- Llama-2-Chat:三个版本,7B,13B,70B
- input:text only
- ouput:text only
- 同样是基于transformer架构的自回归模型,使用SFT(supervised fine-tuning)和RLHF(human feedback)
- 70B版本推理:Grouped-Query Attention (GQA) 来优化
- 训练数据:截止到2022年9月的数据,一些微调数据是2023年7月前的
1. 训练细节
- transformer architecture (Vaswani et al., 2017),
- 使用RMSNorm(Root Mean Square Layer Normalization)方法对transformer每层的输入进行归约(norm)操作,代替了transformer之前对输出进行归约(norm):apply pre-normalization using RMSNorm (Zhang and Sennrich, 2019),
- SwiGLU激活函数:use the SwiGLU activation function (Shazeer, 2020),
- 旋转位置编码:rotary positional embeddings(RoPE, Su et al. 2022).
- 上下文长度和分组查询注意力(GQA):The primary architectural differences from Llama 1 include increased context length and grouped-query attention (GQA).
训练65B参数的模型,使用了2048块80G显存大小的A100卡,处理对应380 tokens/sec/GPU,1.4T个token训练了有21天。训练loss如下:

参数设置:
- 使用AdamW优化器,对应超参beta1=0.9, beta2=0.95; 使用cosine学习率调度,最终学习率是最大学习率的10%;weight decay为0.1, gradient clipping为0.1。
- 训练使用前2000个step进行warmup
2. Evaluation Results
Llama 1 and Llama 2评测结果:
| Model | Size | Code | Commonsense Reasoning | World Knowledge | Reading Comprehension | Math | MMLU | BBH | AGI Eval |
|---|---|---|---|---|---|---|---|---|---|
| Llama 1 | 7B | 14.1 | 60.8 | 46.2 | 58.5 | 6.95 | 35.1 | 30.3 | 23.9 |
| Llama 1 | 13B | 18.9 | 66.1 | 52.6 | 62.3 | 10.9 | 46.9 | 37.0 | 33.9 |
| Llama 1 | 33B | 26.0 | 70.0 | 58.4 | 67.6 | 21.4 | 57.8 | 39.8 | 41.7 |
| Llama 1 | 65B | 30.7 | 70.7 | 60.5 | 68.6 | 30.8 | 63.4 | 43.5 | 47.6 |
| Llama 2 | 7B | 16.8 | 63.9 | 48.9 | 61.3 | 14.6 | 45.3 | 32.6 | 29.3 |
| Llama 2 | 13B | 24.5 | 66.9 | 55.4 | 65.8 | 28.7 | 54.8 | 39.4 | 39.1 |
| Llama 2 | 70B | 37.5 | 71.9 | 63.6 | 69.4 | 35.2 | 68.9 | 51.2 | 54.2 |
3. 更多参考
[1] Llama 2 官方公告:https://ai.meta.com/llama/
[2] Llama 2 官方论文:https://huggingface.co/papers/2307.09288
[3] “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints” by Google Research:https://arxiv.org/pdf/2305.13245.pdf
[4] “Llama 2: an incredible open LLM” by Nathan Lambert: https://www.interconnects.ai/p/llama-2-from-meta
[5] Llama 2 models: https://huggingface.co/meta-llama
[6] Text generation web UI github: https://github.com/oobabooga/text-generation-webu
alpaca模型
百川大模型
- Baichuan 2:百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练,包含有 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化
- 链接:https://github.com/baichuan-inc/Baichuan2
注意:从0写个gpt简易版可以参考——极简PicoGPT
https://github.com/jaymody/picoGPT/tree/29e78cc52b58ed2c1c483ffea2eb46ff6bdec785
介绍:60行代码就能构建GPT!网友:比之前的教程都要清晰|附代码
其他大模型和peft高效参数微调
参考之前的:【LLM大模型】指令微调、peft高效参数微调
二、行业垂直领域大模型
度小满的轩辕2.0模型微调
1. 模型介绍
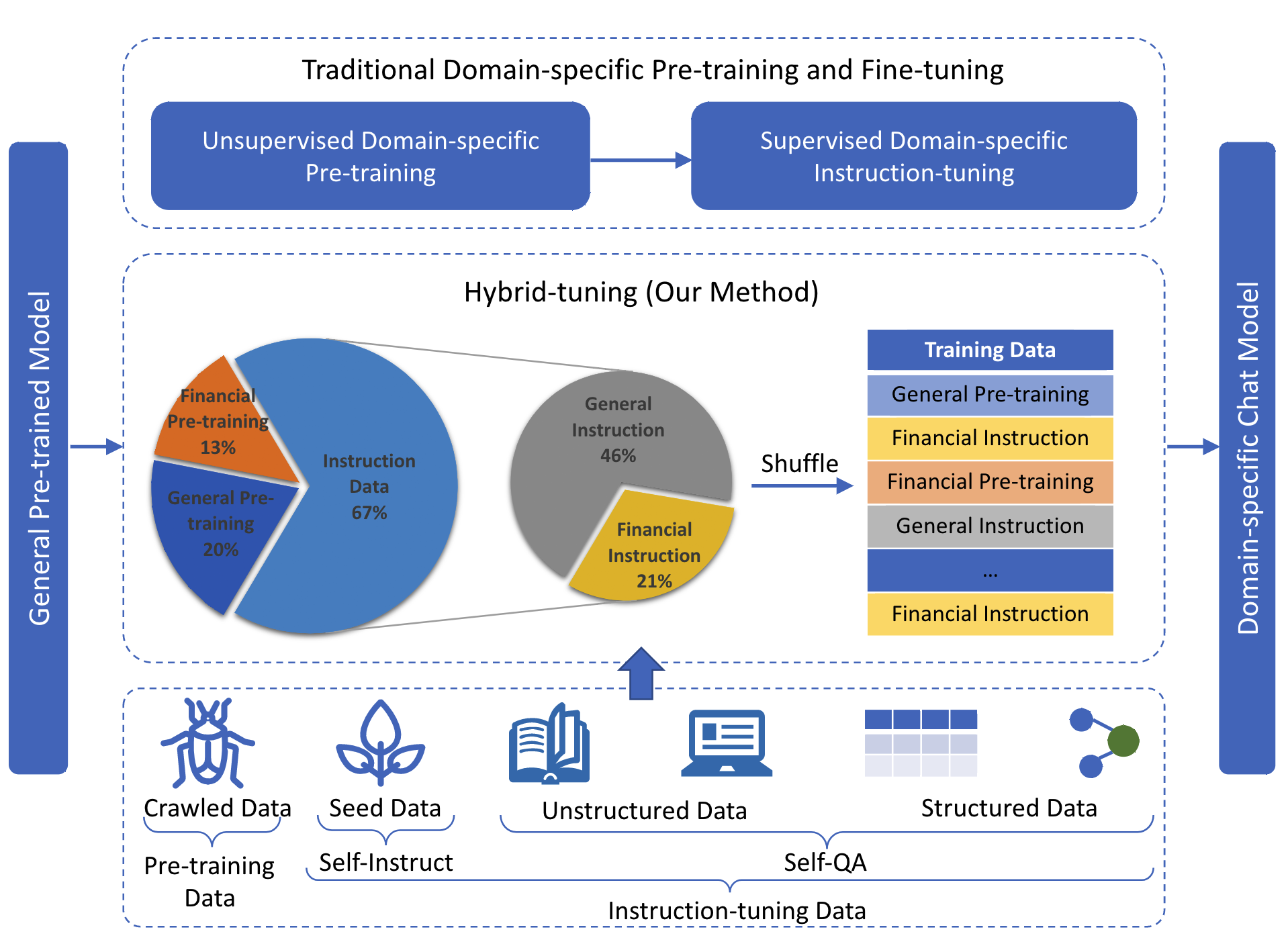
- 基于bloom-176B架构,训练了一个中文金融大模型,提出【混合微调】缓解catastrophic forgetting问题。模型使用使用的是ALiBi的位置编码,以及embedding LayerNorm,基于传统的transformer decoder架构
- 训练数据用于/包括:
- 一般领域的预训练;
- 金融指令(微调);
- 金融领域预训练;
- 一般领域指令;
- 。。。
- 金融指令(微调)。。。
- 就是反复搞个随机的任务序列,让大模型不敢或忘历史
2. 混合微调
MedicalGPT:医疗大模型
MedicalGPT项目:https://github.com/shibing624/MedicalGPT/tree/main
基于ChatGPT Training Pipeline,本项目实现了领域模型–医疗模型的四阶段训练:
- 第一阶段:PT(Continue PreTraining)增量预训练,在海量领域文档数据上二次预训练GPT模型,以注入领域知识
- 第二阶段:SFT(Supervised Fine-tuning)有监督微调,构造指令微调数据集,在预训练模型基础上做指令精调,以对齐指令意图
- 第三阶段:RM(Reward Model)奖励模型建模,构造人类偏好排序数据集,训练奖励模型,用来对齐人类偏好,主要是"HHH"原则,具体是"helpful, honest, harmless"
- 第四阶段:RL(Reinforcement Learning)基于人类反馈的强化学习(RLHF),用奖励模型来训练SFT模型,生成模型使用奖励或惩罚来更新其策略,以便生成更高质量、更符合人类偏好的文本
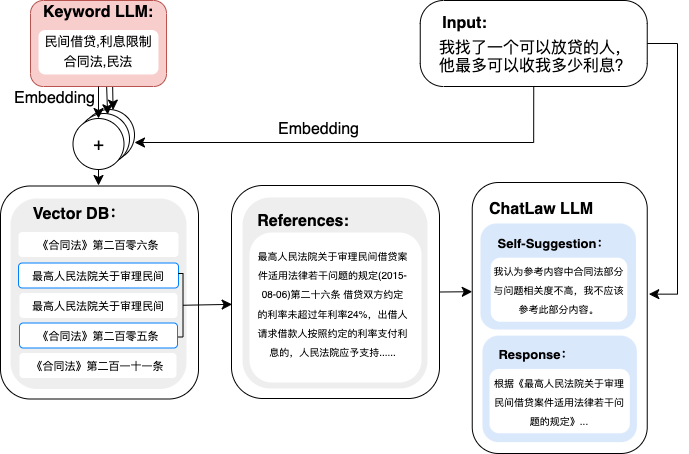
ChatLaw:法律大模型
项目:https://github.com/PKU-YuanGroup/ChatLaw
- 将query提取为keyword,然后将keyword和query分别embedding后,两者拼接的结果去向量数据库中求topk找上下文。
- base model:姜子牙-13B、Anima-33B,使用大量领域文本构建对话数据、也使用大量考题作为sft数据。
TransGPT:交通大模型
https://github.com/DUOMO/TransGPT
pt训练代码:采用了MedicalGPT提供的pretraining.py代码。
sft训练代码:采用了MedicalGPT提供的supervised_finetuning.py代码。
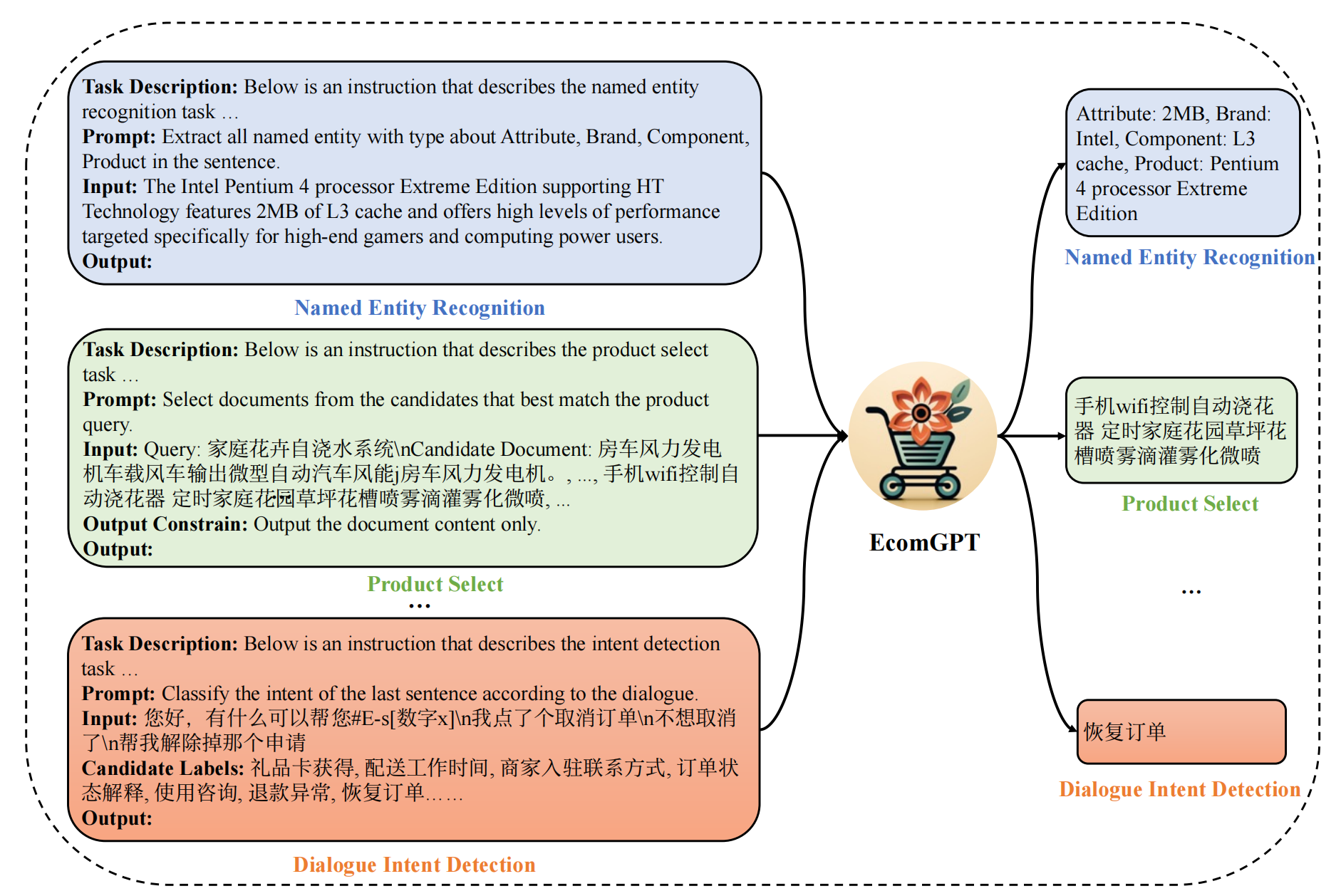
EcomGPT:电商领域大模型
解决问题:解决电商场景任务(如品牌识别,评价解析,广告文案生成等)
论文链接:https://arxiv.org/abs/2308.06966
GitHub链接:https://github.com/Alibaba-NLP/EcomGPT
1. sft数据
- 从学术论文或竞赛平台等开放数据源收集了共65个各种电商任务数据集,包括命名实体识别、评论问答、商品类目预测、多轮对话等传统的自然语言处理任务。这些开源数据集的任务都是由领域专家设计,然后由受过培训的人工标注,数据质量很高。
- 电商领域的商品item虽然变化很快,但是电商数据类型相对稳定,包括产品信息、用户对话、用户评论和搜索查询等,所以EcomGPT对基础数据构建大量原子任务(如实体片段识别、实体分类等),即任务链任务(Chain of tasks)。原子任务的标注答案尽可能从公开任务原始的标注构造,以保证准确性。实在无法构造的,借助ChatGPT帮助生成。

2. 模型微调
- 多任务的指令微调
- 将特定数据集的任务指令与数据样本结合起来,构造了大规模的指令调优数据,然后基于这个指令数据集采用标准的因果语言模型(Causal Language Model)的训练范式训练。指令包含三个部分:任务描述、任务指令、输入句子。任务描述给出任务名称,任务指令描述具体的任务需求,输入句子则是具体需要分析的句子。
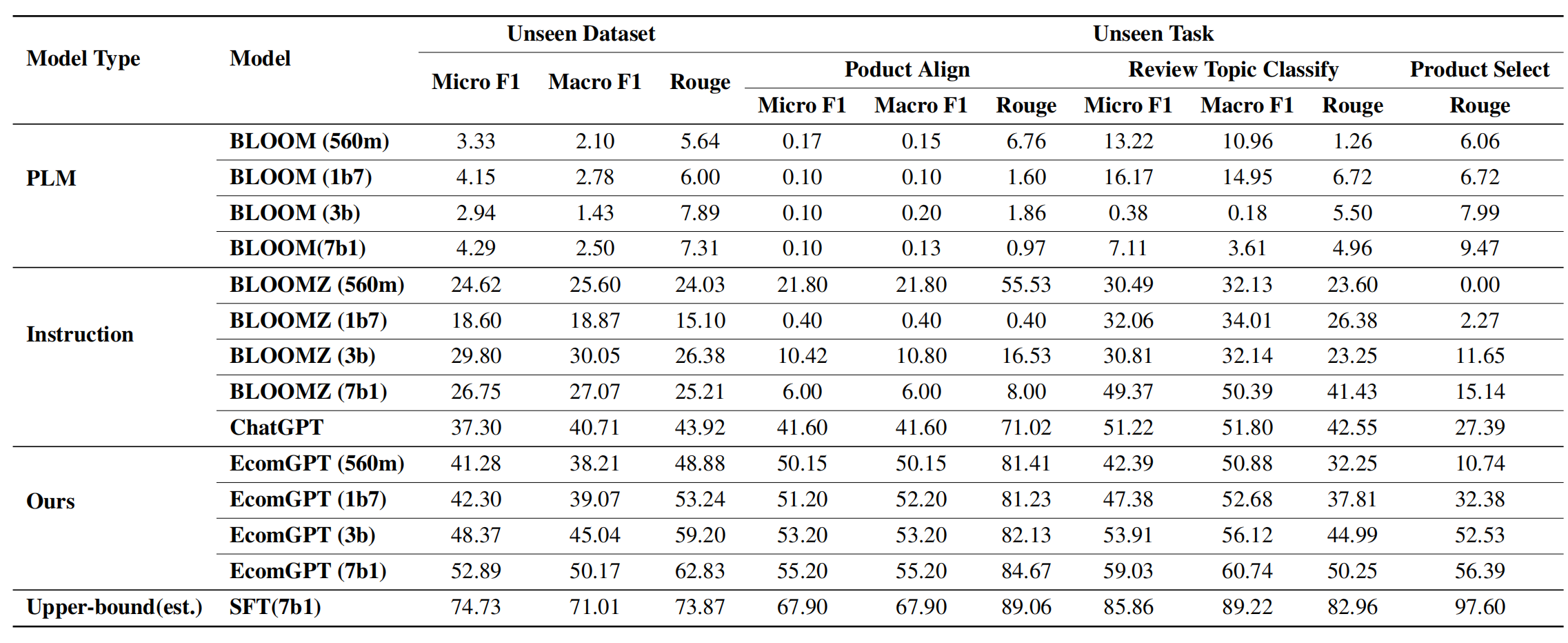
3. 评测数据集和评测结果
- 在12个训练时没见过的数据集中进行测试,使用Rouge指标,对于分类、实体识别等任务也使用F1指标。

- 分析:微调后的模型能够理解电商任务
- 从下图中看到,数据越多样化(每个任务的训练数据越多),模型效果越好(ROUGE-L指标越高)。

llama变体
中文BiLLa: A Bilingual LLaMA with Enhanced Reasoning Ability,参考
- 第一阶段:扩充中文词表,使用中文预训练语料Wudao、英文预训练语料PILE、翻译语料WMT的中英数据进行二次预训练。
- 第二阶段:训练数据在第一阶段基础上增加任务型数据,训练过程中两部分数据保持1:1的比例混合。任务型数据均为NLP各任务的主流开源数据,包含有数学解题、阅读理解、开放域问答、摘要、代码生成等,利用ChatGPT API为数据标签生成解析,用于训练提升模型对任务求解逻辑的理解。
- 第三阶段:保留第二阶段任务型数据,并转化为对话格式,增加其他指令数据(如Dolly 2.0、Alpaca GPT4、COIG等),进行对齐阶段的微调。
三、LLM模型微调
1. fine-tuning的必要性
参考reference7的某乎中北邮老师的回答:
- 从头训练新模型不一定优于微调旧模型。考虑到计算资源消耗、训练数据清洗和策划、训练过程的细节控制等因素,微调旧模型到特定领域可能是更经济高效的选择。
- 新旧模型组合可能最佳,既微调旧模型获取特定领域知识,又保留新模型的通用建模能力,组合使用可以获得更好的效果。结合优化的专家混合路由策略,新旧模型组合可能达到 1+1>2 的效果。
首先要考虑的问题,是究竟该不该做fine-tune,可以从这几个角度理解:
1、大量fine-tuning的案例证实,由于LLM本身已经学到了大量知识,轻易fine-tuning反而可能破坏其原有知识结构,导致效果下降。
2、fine-tuning后模型很容易过拟合特定任务,丧失原有的快速拟合新任务的能力。
3、fine-tuning还可能导致隐私泄露,由于fine-tuning依赖特定领域的数据集,可能暴露数据集中包含的敏感信息。
4、fine-tuning也要消耗大量时间和算力资源,而结果并不一定明显优于原模型。
5、fine-tuning难以迁移复用,每次fine-tuned仅适用于一个特定任务,无法像原模型那样泛化应用。
6、充分利用原有模型的基础上,引入先验知识,可能是更有效的方案。与fine-tuning相比,在prompt中显式融入先验知识,可以更简单直观而有效地引导模型。
7、fine-tuning后的模型输出,也会受到特定领域数据的潜在影响产生漂移,失去原有的一致性。
2. 大模型fine-tune如何避免过拟合
如果确实要做fine-tuning,为避免过拟合需要注意以下几个方面:
1、加大训练数据规模,反而可能导致过拟合。因为LLM本身已经拟合了大量文本数据分布,给它更多相似数据,可能不会提供很多有用的新信息,反而可能导致对训练数据的记忆效应。
2、简化模型结构,反而可能降低过拟合。一般认为复杂的模型容易过拟合,但对LLM而言,简化结构反而会降低其对任务的建模能力,从而减少过拟合风险。
3、提前停止训练(早停)可能会适得其反。LLM仍在不断学习新知识,过早停止反而阻碍了对新任务的适应,适当延长训练有助于增强泛化能力。
4、使用更小的学习率或许有助于防止过拟合,由于LLM已经预训练了大量的知识,所以在fine-tune时使用更小的学习率可能更为合适,还可以避免模型在fine-tune过程中忘记其原始的知识。
5、在实际应用中,应该prompt设计优化(提示工程)和模型优化配合使用,而不是单纯调参。LLM过拟合主要是对surface特征的模仿,而非真正理解语义。优化prompt可以让模型学习更抽象的表示。
6、多任务训练不一定有利于预防过拟合。不同任务间存在潜空间的迁移,单任务效果的提升可能依然过拟合特定数据集,需要更抽象的任务设计。
7、评估过程也可能过拟合,所以需要更多样化的测试用例,避免只针对某些特定情况进行有偏的评估。
8、可以尝试微调Transformer的部分head,而非整个multi-head,来局部微调模型。
9、可以考虑集成学习或专家混合,训练多份微调模型然后结果层叠或优化路由,也能有效降低最终模型总体过拟合风险。
3. 如何防止知识灾难性遗忘
- DeepMind的贝叶斯方法:Functional Regularisation for Continual Learning with Gaussian Processes
- 论文链接:https://arxiv.org/abs/1901.11356
- 局部网络共享的增量方法:Incremental Learning in Deep Convolutional Neural Networks Using Partial Network Sharing
- 论文链接: https://arxiv.org/abs/1712.02719
- 纤维丛理论:Realizing Continual Learning through Modeling a Learning System as a Fiber Bundle
- 论文链接:https://arxiv.org/abs/1903.03511
4. fine-tune的目的和场景
- 垂直领域(如英文类微调到中文):可以用无监督的继续预训练,构造带标注的指令微调数据(多场景、不同任务的数据,指令的描述形式也应该多样化,同时为了防止知识遗忘,需要引入通用领域预料)
- BloomBerg尽量让通用语料与金融语料达到1:1的混合比例
- 度小满将数据按照是否通用、是否带标注的指令数据等特性切分成块,包括通用无监督语料、金融无监督语料、通用标注指令语料、金融标注指令语料。然后将这些语料块打散随机组成训练的batch。
- 下游任务场景:
- faq对话类任务:知识库的具体内容问答,在6b、7b模型很难微调,如果模型较小,更适合结合langchain、autogpt等方式,将本地知识库的访问工具化,让模型不直接回答,而是做用户意图理解、知识检索与整合等
- 文本分类、抽取、摘要等传统nlp任务: 一般来说不需要太多数据,甚至不需要微调,直接在prompt加入一些样例,用few-shot激发大模型的in-context learning能力。但由于大模型的输入context长度通常有限制,而样例涉及的上下文通常也比较长,所以很多时候还是要做微调(微调方法借鉴第二大点)
5. LLM微调的相关参数
以firefly模型全参微调为例:
进行全量参数微调:
deepspeed --num_gpus={num_gpus} train.py --train_args_file train_args/sft.json
train_args/sft.json中的主要参数说明如下,以下参数可以根据需求进行修改,其他参数建议不做修改:
- output_dir:训练输出目录,存储checkpoint、tokenizer、tensorboard等
- model_name_or_path:预训练模型的本地目录,或者在huggingface上的模型名称。
- train_file:训练数据集路径。可以使用data/dummy_data.jsonl进行debug。
- num_train_epochs:训练的轮次。如果数据量足够大,一般建议只训一个epoch。
- per_device_train_batch_size:每张显卡的batch size。
- gradient_accumulation_steps:梯度累计步数。global batch=num_gpus * per_device_train_batch_size * gradient_accumulation_steps。
- gradient_checkpointing:如果显存捉襟见肘,可以开启。以时间换空间,模型不缓存激活状态,会进行两次forward计算,以节省显存。
- learning_rate:学习率。全量参数微调的时候,建议小一些,1e-5或5e-6。
- max_seq_length:训练时的最大长度。按照自己的设备进行设置,越长需要占用越多显存。
- logging_steps:每隔多少步统计一次train loss。
- save_steps:每隔多少步保存一个模型。
- save_total_limit:output_dir目录中最多保存多少个checkpoint,超出则会将最旧的删除。
- lr_scheduler_type:学习率变化策略。
- warmup_steps:warm up步数。学习率经过多少步,增长到指定的数值。
- optim:优化器。如果是全量参数微调,建议使用adamw_hf。
- seed:随机种子,用于复现实验结果。
- fp16:使用使用fp16混合精度。V100建议开启。
- bf16:使用使用fp16混合精度。A100建议开启。
Reference
[1] 论文:Instruction Tuning for Large Language Models: A Survey
[2] 地址:https://arxiv.org/pdf/2308.10792.pdf
[3] 论文链接:https://arxiv.org/abs/2308.06966
[4] GitHub链接:https://github.com/Alibaba-NLP/EcomGPT
[5] Llama 2:最强开源大模型简单体验及原理分析
[6] 人大综述:https://github.com/RUCAIBox/LLMSurvey
[7] 在大模型下,对于垂直领域 有必要从头训练一个大模型吗,微调方式可以替代训练大模型方式吗?
[8] LLM大模型的fine-tune如何避免过拟合?
[9] https://github.com/RonaldJEN/FinanceChatGLM/










