1、什么是buffer/cache ?
buffer/cache 其实是作为服务器系统的文件数据缓存使用的,尤其是针对进程对文件存在 read/write 操作的时候,所以当你的服务进程在对文件进行读写的时候,Linux内核为了提高服务的读写速度,则将会把文件放在此处的 buffer/cache 中进行缓存使用,由于 Linux服务的特点便是任何事物都会以文件的形式进行存在,所以你会发现不管你是否对文件做了大规模的读写,机器的 buffer/cache 是一直都存在的,并且持续的增高不下,这是因为服务器所产生的网络连接也好,用户协议的(UDP)套接字也好,这部分的数据系统都会为应用程序创建对应的文件描述符,而这些文件描述符的使用,则又都会重新进入 buffer/cache 中做读写使用,所以这也是你的机器始终都会存在较高 buffer/cache 的原因,(因为所有的文件读写都会用到 buffer/cache,在内存合理的情况下)
2、buffer/cache 需要注意的一些特点
在服务内存够用的情况下,Linux内核为了加快对文件的读写效率会将文件放入之buffer/cache 中 以保证读写效率,但其实,尽管当你的应用程序对文件的读写运行结束后,buffer/cache 也不会自动释放该部分内存,而是作为缓冲进行保留,等到你的服务进程在下一次进行相同文件的读写时就可以直接使用,省去了各种重新进行内存初始化的操作;所以这将会导致,当你的应用进程频繁对不同的文件进行读写时,你会发现服务所可以直接使用的free内存将会越来越少的一个重要原因;难道 buffer/cache 在这样无休止的缓存当中就不会自动释放?当然不是,当服务器在内存压力较大的情况下时,则将会自动进行内存的回收,作为free空间分给其它进程使用,这其中主要回收的一个内存则是 buffer/cache 的缓冲区内存块;
3、如何进行手动 buffer/cache 回收?
除了在系统进程内存使用较大压力的情况下进行内存的回收外,我们也可以进行手动的buffer/cache回收,但由于buffer/cache主要是用于文件的读写使用,所以进行文件回收时,一般常伴随系统的IO彪高,因为系统内核也对比cache中的数据与硬盘中的数据是否一致,如果不一致需要写会,然后才能进行内存的回收
将内存中数据强制先刷新到磁盘中
sync;
清理Buffer缓存区域
echo 3 > /proc/sys/vm/drop_caches 表示清除pagecache和slab分配器中的缓存对象
echo 1 > /proc/sys/vm/drop_caches:表示清除pagecache。
echo 2 > /proc/sys/vm/drop_caches:表示清除回收slab分配器中的对象(包括目录项缓存和inode缓存)。slab分配器是内核中管理内存的一种机制,其中很多缓存数据实现都是用的pagecache。1、hcache的下载地址
hcache的github地址:https://github.com/silenceshell/hcache
2、 hcache的使用方式
当前下载完对应的hcache后,则直接是一个对应的 bin文件,此时直接将对应的bin文件进行 chmod 授权后即可使用
将该bin文件设置为可执行文件
chmod 755 hcache将该hcache移动到usr的bin目录中,使其可以被全局调用该命令
mv hcache /usr/local/bin/3、hcache常用命令
全局显示10个最大的被缓存文件
hcache --top 10 查看指定进程ID所使用的buffer/cache 的使用情况
查看指定进程ID所使用的buffer/cache 的使用情况
hcache -pid 3090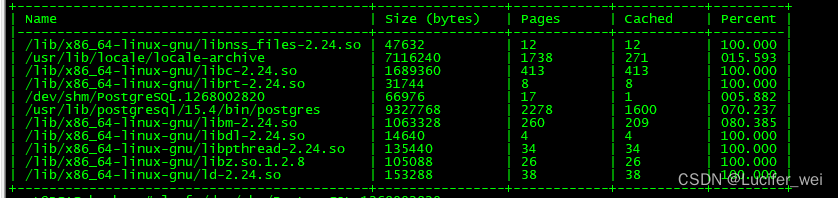
通过上述所获取到的被缓存最大的文件名称后,可以直接通过 lsof file_name 得到当前所开启该文件的所有进程信息;
显示使用/dev/shm/PostgreSQL.1268002820的进程信息
lsof /dev/shm/PostgreSQL.1268002820
获取当前进程号所打开的所有文件信息
lsof -p 3090










