🌷🍁 博主猫头虎 带您 Go to New World.✨🍁
🦄 博客首页——猫头虎的博客🎐
🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺
🌊 《IDEA开发秘籍专栏》学会IDEA常用操作,工作效率翻倍~💐
🌊 《100天精通Golang(基础入门篇)》学会Golang语言,畅玩云原生,走遍大小厂~💐
🪁🍁 希望本文能够给您带来一定的帮助🌸文章粗浅,敬请批评指正!🍁🐥
文章目录
- 深入理解 PostgreSQL 中的 MVCC(多版本并发控制)机制
- 摘要:
- 一,引言
- 二,什么是MVCC(多版本并发控制)
- 三,MVCC在PostgreSQL中的应用
- 四,MVCC的核心组件
- 五,读操作和写操作的执行过程
- 六,MVCC的性能和应用注意事项
- 1. MVCC的性能优势:
- 2. MVCC的资源消耗:
- 3. 使用MVCC的注意事项和最佳实践:
- a. 选择合适的事务隔离级别:根据应用的需求,选择合适的事务隔离级别。较低的隔离级别(如读已提交)可以提高并发性能,但可能牺牲一定的数据一致性。
- b. 避免长事务:长时间运行的事务可能导致版本链过长,增加数据库的存储开销和维护成本。尽量缩短事务的执行时间,减少版本链的长度。
- c. 定期清理过期数据:定期清理过期数据可以帮助维持数据库的性能,但需要在维护和性能之间做出权衡。
- d. 避免过度并发:虽然MVCC可以提高并发性能,但过度的并发操作可能会导致资源竞争和性能下降。合理规划并发连接数,避免资源抢占。
- e. 处理写入冲突:多个事务同时修改同一行数据可能导致写入冲突。在应用程序中要处理冲突,使用乐观并发控制或锁机制来保证数据的一致性。
- f. 监控和调优:定期监控数据库的性能和资源使用情况,根据需要进行调优,以确保MVCC的良好性能。
- 七,与其他并发控制机制的比较
- 八,案例研究
- 九,结论
- 十. 参考文献
- 原创声明

深入理解 PostgreSQL 中的 MVCC(多版本并发控制)机制
摘要:
一,引言
- 简要介绍MVCC(多版本并发控制)概念和其在数据库中的重要性。
- 提出写作目的,即深入理解PostgreSQL中的MVCC机制,并解释读者可以从本文中学到什么。
二,什么是MVCC(多版本并发控制)
MVCC,即多版本并发控制,是一种用于处理数据库中并发操作的机制。在传统的并发控制方式中,常见的做法是通过锁定资源来确保在某一时刻只有一个事务可以修改或读取数据,以防止数据不一致或冲突。然而,传统的锁定机制可能会导致性能瓶颈和并发性下降,尤其在高并发访问的情况下。
MVCC通过引入多个数据版本来解决传统锁定机制的一些局限性。在MVCC中,每个数据库事务在读取数据时会看到一个特定的版本,这使得事务之间可以同时进行读写操作,而不会相互干扰。每个事务可以操作自己的数据版本,从而实现了更高的并发性和更好的性能。
MVCC的核心思想是,对于每个修改操作,不是直接在原始数据上进行修改,而是创建一个新的数据版本,并将修改操作应用于新版本。这样,其他事务仍然可以访问旧版本的数据,而不会受到正在进行的修改的影响。只有在事务提交时,新版本的数据才会替代旧版本,从而实现数据的一致性。
MVCC在数据库中起作用的原理是通过使用版本号、时间戳或类似的标识来管理数据版本,并通过一定的规则来决定哪些版本对于每个事务是可见的。
总之,MVCC是一种强大的并发控制机制,它允许多个事务同时进行读写操作,提高了数据库的并发性和性能,并解决了传统锁定机制可能带来的性能问题和并发冲突。
三,MVCC在PostgreSQL中的应用
在PostgreSQL数据库管理系统中,MVCC被广泛应用,成为其并发控制的核心机制。PostgreSQL通过具体的实现方式来支持MVCC,以下是它在PostgreSQL中的应用及相关优势:

1. MVCC的具体实现方式
在PostgreSQL中,MVCC的实现方式涉及以下几个核心组件:
a. 事务ID(Transaction ID)
每个事务在创建时都会被分配一个唯一的事务ID。事务ID在数据库中是递增的,并且对于每个事务,它所创建的数据版本都会与其事务ID关联。
b. 版本链(Version Chain)
对于每个数据行,都会存在一个版本链,它链接了不同事务创建的数据版本。新的修改操作将创建一个新版本,并将其链接到当前数据行的版本链中。
c. 可见性规则(Visibility Rules)
PostgreSQL定义了一组可见性规则,用于决定哪些数据版本对于特定事务是可见的。一般来说,对于一个事务来说,它只能看到早于其开始时间的事务所创建的数据版本。
2. MVCC在PostgreSQL中的优势
a. 并发性提升
由于MVCC允许多个事务同时读取数据,而不会相互干扰,因此它极大地提高了数据库的并发性能。事务之间不再需要互相等待锁释放,从而减少了由于锁竞争带来的阻塞情况。
b. 无锁读取(Non-locking Read)
MVCC的实现使得读取操作可以不使用显式锁定,即可达到数据一致性。读取操作不会对正在进行的写操作产生阻塞,从而降低了数据库的负载,提高了读取性能。
c. 无干扰写入(Non-blocking Write)
不同事务的写操作可以并行进行,由于每个事务都有自己的数据版本,因此不会发生写入冲突。这样,MVCC避免了许多传统并发控制方式中需要进行锁定和回滚的情况。
3. 提高并发性和性能
在PostgreSQL中,利用MVCC可以采取一些策略来进一步提高并发性和性能:
a. 适当设置事务隔离级别
通过选择合适的事务隔离级别,可以平衡一致性和并发性能之间的关系。较低的隔离级别(如读已提交)可以提高并发性能,但可能牺牲一定的数据一致性。
b. 定期清理过期数据
版本链会随着时间的推移变得越来越长,可能导致性能下降。定期清理过期数据可以帮助维持数据库的性能。
总结而言,MVCC在PostgreSQL中为数据库的并发控制提供了强大的机制,通过适当的实现方式,PostgreSQL能够提高并发性和性能,并为读写操作提供高效的并发控制方式,使得数据库在高并发环境下表现出色。
四,MVCC的核心组件
在PostgreSQL中,MVCC(多版本并发控制)的实现涉及以下核心组件,它们共同协作来管理并发访问数据库的数据版本:
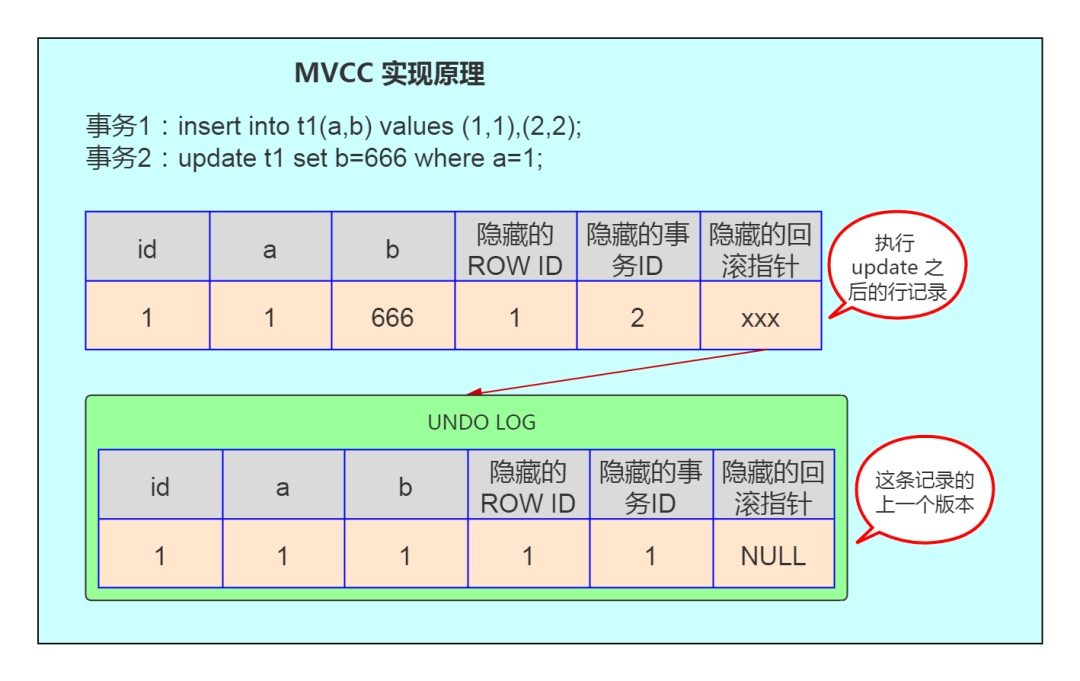
1. 事务ID(Transaction ID)
事务ID是PostgreSQL中用于标识事务的唯一标识符。每个事务在创建时都会被分配一个递增的事务ID。事务ID在数据库中是全局唯一的,并且会在每个新的事务提交时递增。通过事务ID,PostgreSQL可以跟踪每个事务对数据库的读取和修改操作。
2. 版本链(Version Chain)
版本链是一个链接在数据行上的链表,用于存储不同事务创建的数据版本。每次对数据行进行修改时,都会创建一个新的数据版本,并将其链接到版本链的头部。这样,最新的数据版本就会成为版本链的第一个节点,而旧的版本会通过链表依次连接在后面。
3. 可见性规则(Visibility Rules)
可见性规则定义了哪些数据版本对于特定事务是可见的。每个事务在启动时会记录一个开始时间戳,并在整个事务执行期间保持不变。可见性规则通常根据事务的开始时间戳来确定该事务能够看到哪些版本的数据。对于某个事务来说,它只能看到版本链中那些在它启动时间之前创建的数据版本,从而实现了每个事务的数据隔离性。
4. 快照(Snapshot)
快照是一个事务在特定时间点数据库状态的拷贝。在每个事务中,都会有一个快照,用于记录在事务启动时数据库中数据的状态。这个快照将在整个事务的执行过程中被使用,用于确定该事务能够看到哪些数据版本。通过快照,每个事务可以获取一个一致性的数据库视图,即使在并发环境中,也能避免数据的混乱或冲突。
5. 可回滚段(Undo Log)
为了支持回滚操作,PostgreSQL使用了可回滚段(Undo Log)。当一个事务需要回滚时,Undo Log中存储了在该事务执行期间对数据所做的修改,从而可以撤销这些修改,使数据库恢复到事务开始之前的状态。
总结而言,PostgreSQL通过事务ID、版本链、可见性规则和快照等核心组件来实现MVCC。这些组件协同工作,使得PostgreSQL能够在高并发的情况下提供有效的并发控制,支持多个事务同时读写数据库,并确保每个事务都能获得一致性和隔离性的数据视图。通过MVCC的实现,PostgreSQL成为了一个强大的高性能数据库管理系统。
五,读操作和写操作的执行过程
在MVCC中,读操作(SELECT)和写操作(INSERT、UPDATE、DELETE)的执行过程有所不同。以下是它们在PostgreSQL中的具体执行过程:
读操作(SELECT)的执行过程:
-
获取事务的快照(Snapshot): 在执行SELECT语句的事务开始时,会获取一个快照,用于记录当前数据库状态。
-
查询可见数据版本: 使用事务的快照,查询操作会检查每个数据行的版本链,并根据可见性规则确定哪些数据版本对于该事务是可见的。
-
读取数据: 根据查询的结果,事务只会看到在它启动时间之前已经提交的数据版本,这样可以保证事务的数据视图是一致性的。
-
处理并发修改: 如果其他事务正在对数据行进行修改,而这些修改版本对于当前查询的事务不可见,数据库会返回旧版本的数据给该事务。这样,读操作不会受到并发写操作的干扰。
写操作(INSERT、UPDATE、DELETE)的执行过程:
-
开始事务: 写操作的事务开始时,会获取一个唯一的事务ID,并且记录当前数据库状态的快照。
-
创建新版本: 对于写操作,数据库不会直接在原始数据上进行修改,而是创建一个新的数据版本。修改会被应用到新版本中,而旧版本不会受到影响。
-
版本链的变化: 新版本会被链接到数据行的版本链上,成为链表的头部。这样,最新的数据版本将成为第一个节点,而旧版本则通过链表连接在后面。
-
事务处理: 在事务执行过程中,写操作的修改只对当前事务可见,不会对其他事务产生影响。
-
事务提交: 当写操作所在的事务提交时,新版本的数据会被标记为已提交状态,成为其他事务可见的数据版本。
-
冲突处理: 如果多个事务尝试同时修改同一行数据,可能会发生冲突。在这种情况下,PostgreSQL会使用锁或乐观并发控制机制来解决冲突,确保事务的数据修改是一致的。
总结而言,MVCC在读操作中通过快照和版本链来实现数据的隔离性和一致性。读操作只会看到在事务启动时间之前的已提交数据版本,避免了并发写操作的影响。而写操作则通过创建新的数据版本,并使用版本链来跟踪数据的修改历史。冲突处理保证了并发写操作的一致性,使得数据库能够在高并发环境中提供有效的并发控制和数据保护。
六,MVCC的性能和应用注意事项
MVCC(多版本并发控制)在PostgreSQL中带来了很多性能优势,同时也需要考虑一些资源消耗和应用注意事项。以下是对MVCC的性能和应用的讨论:
1. MVCC的性能优势:
a. 并发性提升:MVCC允许多个事务同时读取数据,而不会相互干扰,从而提高了数据库的并发性能。读操作不需要显式锁定,避免了读写操作之间的阻塞。
b. 无锁读取:MVCC实现了无锁读取,读操作不会对正在进行的写操作产生阻塞,降低了数据库的负载,提高了读取性能。
c. 无干扰写入:不同事务的写操作可以并行进行,每个事务都有自己的数据版本,避免了写入冲突,提高了写入性能。
2. MVCC的资源消耗:
a. 存储开销:由于MVCC需要维护多个数据版本,可能会导致存储开销增加。版本链的维护和快照的创建会占用额外的存储空间。
b. 清理过程:随着时间的推移,版本链会越来越长,可能导致性能下降。定期清理过期数据是必要的,但也会增加数据库的维护成本。
c. 内存开销:MVCC需要维护每个事务的快照和版本链等数据结构,可能增加数据库的内存使用量。
3. 使用MVCC的注意事项和最佳实践:
a. 选择合适的事务隔离级别:根据应用的需求,选择合适的事务隔离级别。较低的隔离级别(如读已提交)可以提高并发性能,但可能牺牲一定的数据一致性。
b. 避免长事务:长时间运行的事务可能导致版本链过长,增加数据库的存储开销和维护成本。尽量缩短事务的执行时间,减少版本链的长度。
c. 定期清理过期数据:定期清理过期数据可以帮助维持数据库的性能,但需要在维护和性能之间做出权衡。
d. 避免过度并发:虽然MVCC可以提高并发性能,但过度的并发操作可能会导致资源竞争和性能下降。合理规划并发连接数,避免资源抢占。
e. 处理写入冲突:多个事务同时修改同一行数据可能导致写入冲突。在应用程序中要处理冲突,使用乐观并发控制或锁机制来保证数据的一致性。
f. 监控和调优:定期监控数据库的性能和资源使用情况,根据需要进行调优,以确保MVCC的良好性能。
总结而言,MVCC在PostgreSQL中带来了显著的并发性能提升,但也需要考虑资源消耗和应用注意事项。通过合理的设计和维护,MVCC可以使数据库在高并发环境下表现出色,提供高效的数据访问和并发控制机制。
七,与其他并发控制机制的比较
在并发控制中,MVCC与传统的锁定机制(如悲观锁和乐观锁)有着显著的区别。下面对它们进行比较,列出各自的优势和劣势:
1. MVCC(多版本并发控制):
优势:
- 更高的并发性: MVCC允许多个事务同时读取数据,而不需要互相等待锁释放,提高了数据库的并发性能。
- 无锁读取: 读操作不需要显式锁定,读操作之间不会相互阻塞,减少了资源竞争和阻塞情况,提高了读取性能。
- 无干扰写入: 不同事务的写操作可以并行进行,每个事务都有自己的数据版本,避免了写入冲突,提高了写入性能。
劣势:
- 存储开销: MVCC需要维护多个数据版本,可能导致存储开销增加,版本链的维护和快照的创建会占用额外的存储空间。
- 清理过程: 随着时间的推移,版本链会越来越长,可能导致性能下降。定期清理过期数据是必要的,但需要在维护和性能之间做出权衡。
- 内存开销: MVCC需要维护每个事务的快照和版本链等数据结构,可能增加数据库的内存使用量。
2. 传统锁定机制:
悲观锁(Pessimistic Locking):
优势:
- 数据一致性: 悲观锁通过在读写数据时锁定资源,确保数据操作的一致性,避免了并发冲突。
- 简单易懂: 实现悲观锁相对简单,易于理解和使用。
劣势:
- 并发性较差: 悲观锁在锁定资源期间会阻塞其他事务的访问,降低了并发性能,特别在高并发情况下可能引起性能瓶颈。
- 死锁风险: 当多个事务相互等待对方释放锁时,可能导致死锁的发生,需要谨慎处理。
乐观锁(Optimistic Locking):
优势:
- 较好的并发性能: 乐观锁不会立即锁定资源,而是在提交更新时检查数据是否被其他事务修改,减少了锁竞争,提高了并发性能。
- 无阻塞读取: 乐观锁允许多个事务同时读取数据,不会阻塞读取操作。
劣势:
- 冲突处理: 当多个事务同时更新同一行数据时,可能会发生冲突,需要额外的处理机制来解决冲突。
- 数据一致性: 乐观锁不会立即锁定资源,因此在更新时需要验证数据是否被修改过,可能导致数据不一致的情况。
总结:
MVCC通过版本链和可见性规则实现了高并发性能和数据一致性,适用于高并发读写操作的场景。传统锁定机制(悲观锁和乐观锁)可以提供数据一致性,但对并发性能有一定影响,需要根据具体应用场景进行选择。在选择MVCC或传统锁定机制时,需要综合考虑并发性能、数据一致性、资源消耗和应用复杂度等因素。
八,案例研究
让我们通过一个简单的案例研究来演示MVCC在实际应用中的效果。假设有一个名为"products"的数据库表,用于存储产品信息,包括产品名称(name)、价格(price)、库存数量(quantity)等字段。
我们将模拟两个并发事务同时对库存数量进行修改的场景,一个事务执行产品库存减少的操作,另一个事务执行产品库存增加的操作。在传统的锁定机制中,可能会导致并发冲突和阻塞。但是在MVCC中,由于每个事务都有自己的数据版本,它们可以并发地执行而不会互相干扰。
数据库表结构:
| name | price | quantity |
|---|---|---|
| Product A | 10.0 | 100 |
并发事务操作:
-
事务1(T1)执行产品库存减少操作:
BEGIN; -- 开启事务 UPDATE products SET quantity = quantity - 50 WHERE name = 'Product A'; -- 执行其他操作 COMMIT; -- 提交事务 -
事务2(T2)执行产品库存增加操作:
BEGIN; -- 开启事务 UPDATE products SET quantity = quantity + 30 WHERE name = 'Product A'; -- 执行其他操作 COMMIT; -- 提交事务
MVCC效果演示:
在MVCC中,T1和T2两个事务都会创建各自的数据版本,并且不会互相干扰。实际上,在T1和T2执行期间,它们都能读取到未提交的修改,并且相互之间不会阻塞。
初始状态: Product A 的库存数量为 100。
事务1(T1)执行过程: T1开始时,快照显示 Product A 的数量为 100。T1执行了库存减少操作,创建了新的数据版本,但对于其他事务(包括T2)来说,这个修改是不可见的。
事务2(T2)执行过程: T2开始时,快照显示 Product A 的数量为 100。T2执行了库存增加操作,同样也创建了新的数据版本,对其他事务(包括T1)不可见。
提交事务: 在T1和T2都完成操作后,它们分别提交事务。T1和T2所做的修改会成为其他事务可见的新数据版本。
最终结果: 在MVCC中,T1和T2的操作都会被保存,Product A 的最终库存数量取决于T1和T2提交的先后顺序。
例如,如果T1先提交,则最终库存数量为 100 - 50 + 30 = 80。如果T2先提交,则最终库存数量为 100 + 30 - 50 = 80。无论哪个事务先提交,都不会导致数据不一致的情况。
这个简单的案例研究演示了MVCC在实际应用中的效果,它允许多个事务并发执行,并通过版本链和可见性规则来保证数据的隔离性和一致性,提供了高效的并发控制机制。
九,结论
MVCC(多版本并发控制)是数据库管理系统中一种重要且高效的并发控制机制。它通过使用版本链和可见性规则来管理并发访问数据库的数据版本,为数据库提供了强大的并发性能和数据一致性。在MVCC中,多个事务可以并发地读取和写入数据,而不会相互干扰,避免了传统锁定机制可能引起的性能问题和资源竞争。
MVCC的优势包括:
-
高并发性能: MVCC允许多个事务同时读取数据,无需阻塞,从而提高了数据库的并发性能。并发写入操作可以并行进行,避免了写入冲突,提高了写入性能。
-
数据隔离性: MVCC通过可见性规则,确保每个事务只能看到早于其启动时间的数据版本,保证了数据的隔离性,避免了数据的混乱和冲突。
-
无锁读取: 读操作不需要显式锁定,读操作之间不会相互阻塞,提高了读取性能,减少了资源竞争。
-
无干扰写入: 不同事务的写操作可以并行进行,每个事务都有自己的数据版本,避免了写入冲突,提高了写入性能。
在PostgreSQL中,MVCC作为并发控制的核心机制,为数据库提供了强大的功能。PostgreSQL实现MVCC的关键特性包括事务ID、版本链、可见性规则和快照等。通过这些特性,PostgreSQL能够在高并发环境下提供高效的并发控制和数据保护,支持多个事务同时读写数据库,确保数据的一致性和隔离性。
深入学习PostgreSQL中的MVCC机制对于数据库开发人员和管理员来说是非常有价值的。了解MVCC的原理和应用可以帮助优化数据库的性能和并发控制,提高应用程序的吞吐量和响应性能。同时,MVCC也为开发人员提供了更灵活的并发控制方式,避免了传统锁定机制可能带来的性能瓶颈和复杂性。
因此,深入学习PostgreSQL中的MVCC是非常值得的,它将使您能够更好地理解数据库的并发控制机制,优化数据库性能,确保数据的一致性和完整性,为应用程序提供更高效的数据处理能力。
十. 参考文献
在撰写本文章过程中,参考了以下相关文献、网页和资源:
- PostgreSQL Documentation: Concurrency Control - https://www.postgresql.org/docs/current/mvcc.html
- PostgreSQL Wiki: MVCC - https://wiki.postgresql.org/wiki/MVCC
- PostgreSQL Tutorial: Multi-Version Concurrency Control (MVCC) - https://www.postgresqltutorial.com/postgresql-mvcc/
- Understanding MVCC and Locking in PostgreSQL - https://severalnines.com/database-blog/understanding-mvcc-and-locking-postgresql
- What is MVCC (Multi-Version Concurrency Control) in PostgreSQL? - https://www.citusdata.com/blog/2016/03/30/what-is-mvcc/
- Database Management Systems, Raghu Ramakrishnan, Johannes Gehrke, 3rd Edition, McGraw-Hill Education, 2002.
以上资源为了确保本文的准确性和全面性,对MVCC机制在PostgreSQL中的理解和应用提供了宝贵的参考和支持。
原创声明
======= ·
- 原创作者: 猫头虎
作者wx: [ libin9iOak ]
本文为原创文章,版权归作者所有。未经许可,禁止转载、复制或引用。
作者保证信息真实可靠,但不对准确性和完整性承担责任。
未经许可,禁止商业用途。
如有疑问或建议,请联系作者。
感谢您的支持与尊重。
点击
下方名片,加入IT技术核心学习团队。一起探索科技的未来,共同成长。







