前言:
C++的发展其实并不是一蹴而就的,他经历了很多阶段,本章开始,我们将进入C++11的学习。我们大致来看一下C++的发展历程:

当然在这些之中还发行了其他的版本,C++还在不断的向后发展。但是:现在公司主流使用还是 C++98和C++11 。
- 相比于C++98/03,C++11则带来了数量可观的变化,其中包含了约140个新特性,以及对C++03标准中约600个缺陷的修正,这使得C++11更像是从C++98/03中孕育出的一种新语言。
- 相比较而言,C++11能更好地用于系统开发和库开发、语法更加泛华和简单化、更加稳定和安全,不仅功能更强大,而且能提升程序员的开发效率,公司实际项目开发中也用得比较多,所以我们要作为一个重点去学习。
C++11官方网站--->C++官网
目录
(一)统一的列表初始化
(1){ }初始化
在我们之前学的C++98中,我们初始化一个变量或者是一个数组或一个对象可以是:
struct Point
{
Point(int x = 1, int y = 2)
: _x(x)
, _y(y)
{}
int _x;
int _y;
};
int main()
{
int x1 = 1;
int x2 = int();
int* p1 = new int(1);
int* p2 = new int[3]{ int(1),int(3),int(4) };
int* p3 = new int[3]{ 1,3,4 };
Point p(1, 2);
Point();
return 0;
}
现在在C++11中我们可以按照如下的方式初始化:
可以省去赋值符号。
int main()
{
int x1 = { 2 };
int x2{ 3 };
int array1[]{ 1, 2, 3, 4, 5 };
int array2[5]{ 0 };
Point p{ 1, 2 };
return 0;
}
上面支持,本质就更好支持new[]的初始化问题:
C++98只能new单个对象,new多个对象没办法很好的初始化了,定义一个对象数组是很不方便的,至少应该如下定义:
int main()
{
Point p1, p2, p3, p4;
Point* pp1 = new Point[]{ p1, p2, p3, p4 };
Point* pp2 = new Point[]{ Point(1, 1), Point(2, 2), Point(3, 3), Point(4, 4) };
return 0;
}
而在C++11中我们直接可以:
int main()
{
Point p1[] = { {1, 1}, {2, 2}, {3, 3}, {4, 4} };
Point p2[]{ {1, 1}, {2, 2}, {3, 3}, {4, 4} };
Point* p3 = new Point[]{ {1, 1}, {2, 2}, {3, 3}, {4, 4} };
return 0;
}
类比C++98的隐式类型转换:
C++98中我们知道,单参数的构造函数可以直接给个值直接构造,C++11可以说是对C++98这一特性进行了延伸:
class Date
{
public:
//explicit Date(int year, int month, int day)
Date(int year, int month, int day)
:_year(year)
, _month(month)
, _day(day)
{
cout << "Date(int year, int month, int day)" << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1{ 2023, 3, 7 };
Date d2 = { 2023, 3, 7 };
return 0;
}
- 可以理解成C++98是单参数隐式类型转换,C++11是多参数隐式类型转换(同时支持了把=去掉)
- 同样的类似于C++98,如果不想发生隐式类型转化,加上explicit

(2)std::initializer_list
大家思考一个问题:
class Date
{
public:
//explicit Date(int year, int month, int day)
Date(int year, int month, int day)
:_year(year)
, _month(month)
, _day(day)
{
cout << "Date(int year, int month, int day)" << endl;
}
private:
int _year;
int _month;
int _day;
};
//以vector,和map为例,C++11之后就我们之前学的容器可以直接通过{ } 列表初始化了:
int main()
{
vector<Date> v1 = { { 2023, 3, 7 }, { 2023, 3, 7 }, { 2023, 3, 7 } };
vector<Date> v2{ { 2023, 3, 7 }, { 2023, 3, 7 }, { 2023, 3, 7 } };
map<string, string> dict1 = { { "string", "字符串" }, { "sort", "排序" } };
map<string, string> dict2{ { "string", "字符串" }, { "sort", "排序" } };
return 0;
}我们为什么可以用 { } 初始化了?他的底层是什么呢?
有的人会说是构造函数初始化,有的人会说是迭代器初始化...
其实都不是,我们以vector为例,我们看库中的介绍
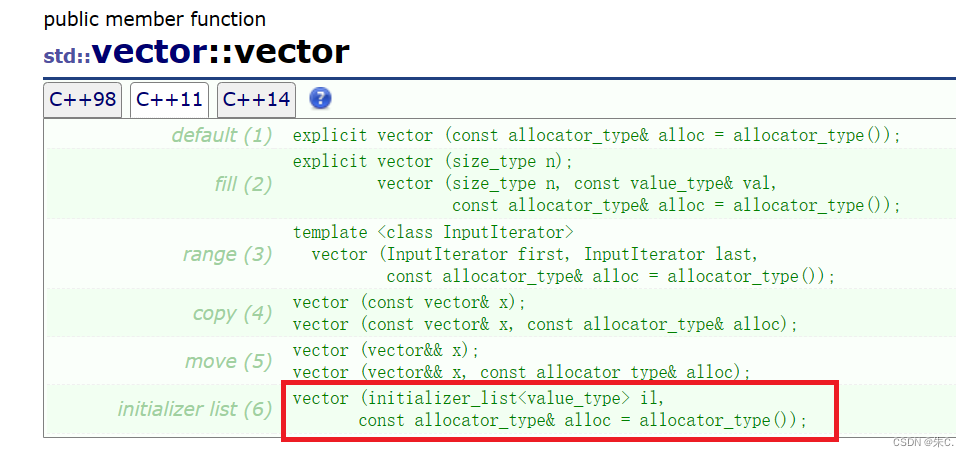
既然不是迭代器等初始化,那么应该是这个C++11新出来的容器进行的初始化,这就是我们接下来将要学习的initializer_list容器。
如果上述只是在猜测层面,我们可以 用代码验证一下: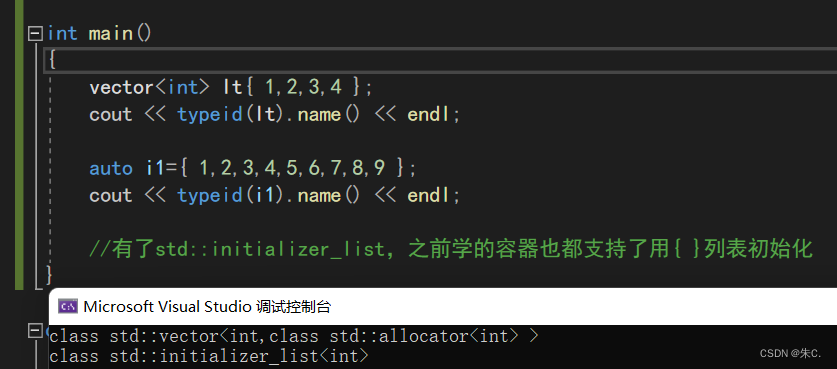
所以经过检验,我们支持{ }初始化是因为C++11提供了initializer_list容器并在其他容器中支持用initializer_list初始化的构造函数。
底层大概的样子:
- 是只能读不能写的
- 可以认为在某个区域开了一块空间,将花括号中的东西存起来
- 可以认为是常量的数组把它支持起来了
- 这里可以看到,std::initializer_list支持迭代器
注意:
std::initializer_list内容是不能被改的
综上:
- std::initializer_list是C++11新提出来的
- 有了std::initializer_list,之前学的容器也都支持了用{ }列表初始化
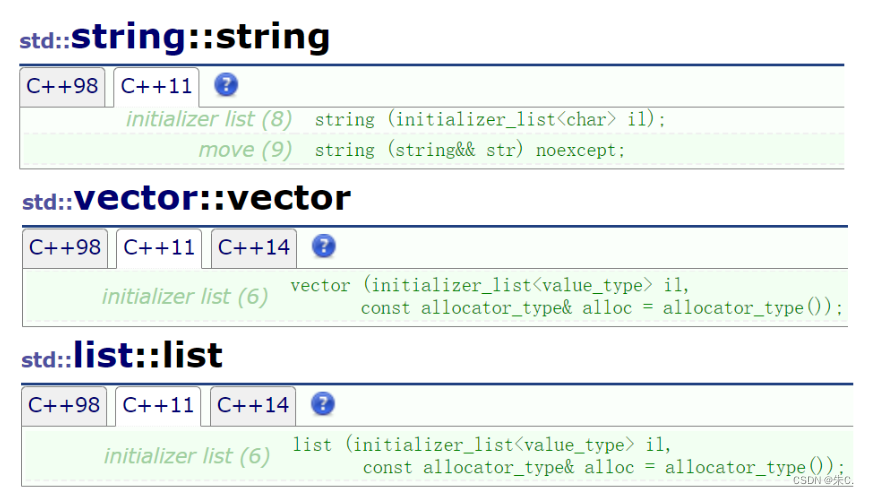
以vector,和map为例,C++11之后就我们之前学的容器可以直接通过{ } 列表初始化了:
int main()
{
vector<Date> v1 = { { 2023, 3, 7 }, { 2023, 3, 7 }, { 2023, 3, 7 } };
vector<Date> v2{ { 2023, 3, 7 }, { 2023, 3, 7 }, { 2023, 3, 7 } };
map<string, string> dict1 = { { "string", "字符串" }, { "sort", "排序" } };
map<string, string> dict2{ { "string", "字符串" }, { "sort", "排序" } };
return 0;
}
先构造一个initializer_list,再用initializer_list构造一个vector,具体过程:

也可以和之前隐式类型转换联系起来,也是中间产生了一个临时对象(initializer_list),再用临时对象去拷贝构造。
(二)右值引用
(1)什么是左、右值
传统的C++语法中就有引用的语法,而C++11中新增了的右值引用语法特性,所以从现在开始我们之前学习的引用就叫做左值引用。无论左值引用还是右值引用,都是给对象取别名。
什么是左值,什么是左值引用:
- 左值是一个表示数据的表达式,如:变量名或解引用的指针
- 我们可以获取它的地址 + 可以对它赋值
- 左值可以出现赋值符号的左边,右值不能出现在赋值符号左边
- 定义时const修饰符后的左值,不能给他赋值,但是可以取它的地址
- 左值引用就是给左值的引用,给左值取别名
什么是右值,什么是右值引用:
- 右值也是一个表示数据的表达式,如:字面常量、表达式返回值,函数返回值(这个不能是左值引用返回)等等
- 右值可以出现在赋值符号的右边,但是不能出现出现在赋值符号的左边,右值不能取地址
- 一个左值经过move之后就可以变成一个右值
- 右值引用就是对右值的引用,给右值取别名
总结:
不能说出现在赋值符号左边的就叫左值,在赋值符号右边的也有可能是左值(int a = 1; int b = a) a 可以赋值和取地址,右值却不能出现在赋值符号的左边,const修饰的对象也叫左值(特例),左值一定可以取地址,但不一定能赋值,右值不能出现在赋值符号左边,右值不能取地址。
int main()
{
//左值
int a = 1;
int& b = a;
//右值
double x = 1.1, y = 2.2;
//以下几个都是常见的右值
10;
x + y;
fmin(x, y);
//以下几个都是对右值的右值引用
int&& rr1 = 10;
double&& rr2 = x + y;
double&& rr3 = fmin(x, y);
//这里编译会报错:error C2106: “=”: 左操作数必须为左值
10 = 1;
x + y = 1;
fmin(x, y) = 1;
return 0;
}
注意:
- 需要注意的是右值是不能取地址的,但是给右值取别名后,会导致右值被存储到特定位置,且可以取到该位置的地址
- 也就是说例如:不能取字面量10的地址,但是rr1引用后,可以对rr1取地址,也可以修改rr1
- 如果不想rr1被修改,可以用const int&& rr1 去引用,是不是感觉很神奇
- 这个了解一下实际中右值引用的使用场景并不在于此,这个特性也不重要。
(2)右值的分类
上述我们讲到右值不能放在 = 符号的左边,即不能赋值,我们可以理解成其是一个临时对象,具有const属性的一个临时对象,我们对其进行详细的分类,分成两类:
- 纯右值:
- 10、a + b…
- 将亡值:
- 匿名对象string(“222”)、to_string(1234)、自定义的对象、move(s1)…
(3)左值引用和右值引用的比较
左值引用:
- 左值引用只能引用左值,不能引用右值
- 但是const左值引用既可引用左值,也可引用右值
右值引用:
- 右值引用只能右值,不能引用左值
- 但是右值引用可以引用move以后的左值
注意:
- 我们可以理解成右值是临时对象,具有const属性不能被修改的值
- 所以我们可以用const类型的引用来接收一个右值
- 我们之前用const类型的引用来接收一个左值是因为权限是可以缩小的,但是权限不能放大
//
//左值引用总结:
//1. 左值引用只能引用左值,不能引用右值。
//2. 但是const左值引用既可引用左值,也可引用右值
//int main()
//{
// int a = 1;
// int& aa1 = a;
// //int& aa2 = 1;//编译不通过
// int&& aa2 = 1;//右值引用
//
// const int& aa3 = 1;//见上
//
//
//}
//
//右值引用总结:
//1. 右值引用只能右值,不能引用左值。
//2. 但是右值引用可以move以后的左值。
//int main()
//{
// int a1 = 1;
// int a2 = 2;
// int&& aa1 = move(a1);
// int&& aa2 = 2;
// int&& aa3 = a1 + a2;
//
//}
(4)右值的使用场景
在我们之前的C++学习中,我们学的都是左值引用,左值引用可以提高程序的效率,特别是函数传引用返回的时候。
但是对于一些场景,左值引用就会失去作用:
左值引用的短板:
- 虽然左值引用在函数中返回一个引用可以提高效率,但是当函数返回对象是一个局部变量,出了函数作用域就不存在了,就不能使用左值引用返回
- 此时就只能传值返回,例如:string中的 to_string(int value)函数中可以看到,这里只能使用传值回,传值返回会导致至少1次拷贝构造,编译器会优化(如果是一些旧一点的编译器可能是两次拷贝构造)
比如我们在模拟实现string的时候,有实现to_string函数: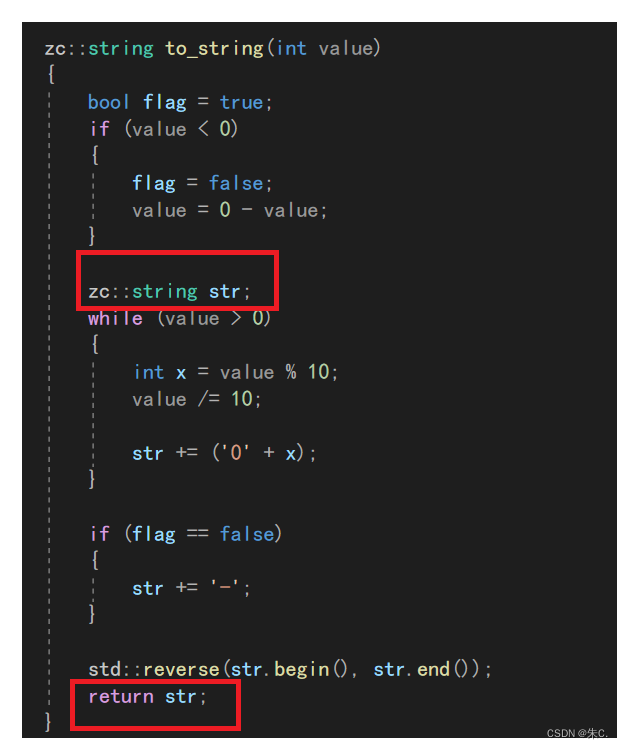
这里的str就是局部变量,我们没法传引用返回,这样就会导致效率的变低。
当然了,有的编译器会进行优化处理:

很显然即使是编译器优化了之后,也是至少有一次拷贝。
我们下面引用一个形象化的例子:
众所周知把大象放到冰箱里一共有三步:
- 第一步:打开冰箱门
- 第二步:把大象放进去
- 第三步:关上冰箱门
那么将大象从一号冰箱放到二号冰箱一共有几步:
- 传统方法: 在二号冰箱里复制一份一模一样的大象,再将一号冰箱里的大象干掉
- C++98拷贝方法:函数的传值返回就是按照这种方法,这还是编译器优化之后的样子,优化之前中间还有个临时变量,并且是深拷贝返回,效率更低下!
- 聪明办法:直接把冰箱的一号和二号的编号调换一下,这样就实现了大象在二号冰箱里了
- C++11右值引用方法:当函数传一个将亡值(右值)返回的时候,C++11提供了一个移动构造,直接用另一个新的对象的指针来接管了原来的对象。
右值引用句应用了类似上述聪明的方法一样:
右值引用和移动语义解决上述问题:
- 在string中增加移动构造,移动构造本质是将参数右值的资源窃取过来
- 占位已有,那么就不用做深拷贝了,所以它叫做移动构造,就是窃取别人的资源来构造自己

C++11中编译器会直接将传值返回识别成一个右值,然后调用移动构造:

在我们之前没有移动构造的时候,我们调用的是拷贝构造,之前我们提到过const类型既可以接收右值,也可以接收左值,所以之前我们是能匹配的上的,但是现在现在有了移动构造,编译器会匹配最匹配的那一个构造函数。
将一个左值move之后就成了右值,右值的资源有可能会被转移:
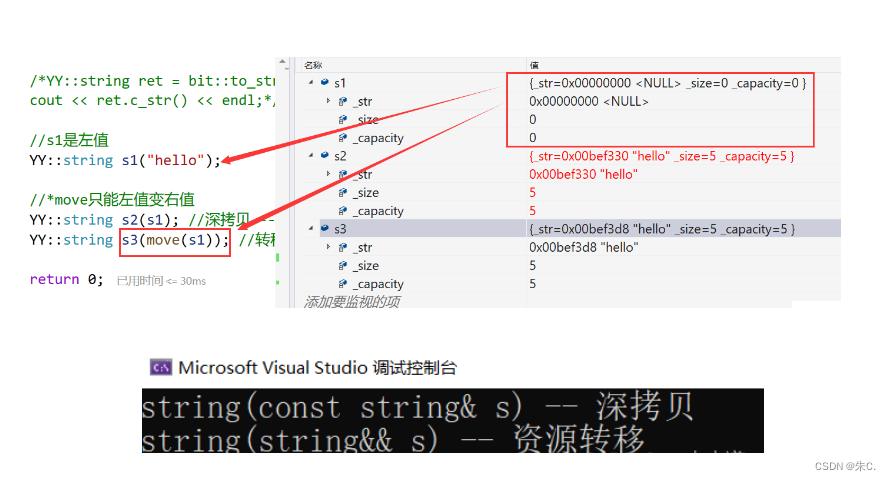
(三)新的类功能
(1)移动构造和移动赋值
默认成员函数:
- 原来C++类中,有6个默认成员函数:
-
- 构造函数
-
- 析构函数
-
- 拷贝构造函数
-
- 拷贝赋值重载
-
- 取地址重载
-
- const 取地址重载
C++11 新增了两个默认成员函数:
- 移动构造函数和移动赋值运算符重载
- 移动构造和移动赋值是有条件的,并且默认生成的达到不了我们想要的效果
- 所以一般我们自己实现
要求:
- 如果你没有自己实现移动构造函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自动生成一个默认移动构造。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动构造,如果实现了就调用移动构造,没有实现就调用拷贝构造。
- 如果你没有自己实现移动赋值重载函数,且没有实现析构函数 、拷贝构造、拷贝赋值重载中的任意一个,那么编译器会自动生成一个默认移动赋值。默认生成的移动构造函数,对于内置类型成员会执行逐成员按字节拷贝,自定义类型成员,则需要看这个成员是否实现移动赋值,如果实现了就调用移动赋值,没有实现就调用拷贝赋值。(默认移动赋值跟上面移动构造完全类似)
- 如果你提供了移动构造或者移动赋值,编译器不会自动提供拷贝构造和拷贝赋值。
STL的容器,C++11以后,都提供移动构造和移动赋值,右值引用 + 移动构造补齐了C+ +传参和传返回值的最后一块短板。
STL容器中的各种插入也用到了右值引用:==
当这些容器的元素是某个对象的时候,插入的话要new一个新的元素,也会产生深拷贝的问题,所以这里用到右值引用将会非常方便:

注意:
- 不要随意的将左值move成右值,不然会造成资源的丢失!!
- 比如你初始化下面s2后,然后将它move成右值了,再想找它就找不到了!

(2)强制生成默认函数的关键字default
C++11可以让你更好的控制要使用的默认函数。假设你要使用某个默认的函数,但是因为一些原因这个函数没有默认生成。比如:我们提供了拷贝构造,就不会生成移动构造了,那么我们可以使default关键字显示指定移动构造生成。
class Person
{
public:
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
{}
//不仅不让调用还不让生成 -- 对于内置类型完成值拷贝
//对于自定义类型有移动构造调用移动构造,没移动构造调用拷贝构造
//Person(const Person& p) = delete;
//强制生成移动构造
Person(Person&& pp) = default;
//我们显示写完拷贝构造,默认生成的移动赋值也不见了
//所以要强制生成移动赋值
Person& operator=(Person&& pp) = default;
Person(const Person& p)
:_name(p._name)
, _age(p._age)
{}
/*Person& operator=(const Person& p)
{
if(this != &p)
{
_name = p._name;
_age = p._age;
}
return *this;
}*/
/*~Person()
{}*/
private:
YY::string _name;
int _age;
};
int main()
{
Person s1;
Person s2 = s1; //拷贝构造
Person s3 = std::move(s1); //移动构造
Person s4;
s4 = std::move(s2);
return 0;
}

当出现拷贝构造的时候,那么就不会生成默认的移动构造,都去走拷贝构造了,这时候我们可以强制生成(默认的)移动构造,这时内置类型值拷贝,自定义类型调用其移动构造,没有移动构造就调用其拷贝构造。
同样的,移动赋值也是同样的道理,也可以有default。
(3)禁止生成默认函数的关键字delete
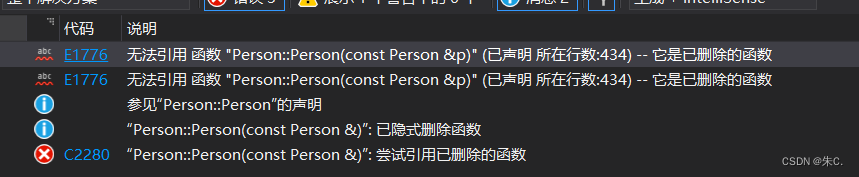
如果能想要限制某些默认函数的生成,在C++98中,是该函数设置成private,并且只声明补丁而已,这样只要其他人想要调用就会报错。在C++11中更简单,只需在该函数声明加上=delete即可,该语法指示编译器不生成对应函数的默认版本,称=delete修饰的函数为删除函数。
我们不想用到默认生成的成员函数的时候就可以直接delete掉,强制其不生成。
class Person
{
public:
Person(const char* name = "", int age = 0)
:_name(name)
, _age(age)
{}
Person(const Person& p) = delete;
private:
zc::string _name;
int _age;
};
int main()
{
Person s1;
Person s2 = s1;
Person s3 = std::move(s1);
return 0;
}
感谢您的阅读!







