source download
Intellij IDEA 有时候不下载不了 code,使用如下命令,在“terminal”下运行
mvn dependency:resolve -Dclassifier=sources
io.netty
java.lang.NoSuchMethodError: io.netty.buffer.PooledByteBufAllocator.<init>
此类问题报错,主要是io.netty 多个jar 冲突导致。、
使用以下命令查看同一个jar 有哪些版本
mvn dependency:tree
对一些不愿意引入的依赖加上 exclusion
<exclusions>
<exclusion>
<groupId>io.netty</groupId>
<artifactId>netty-common</artifactId>
</exclusion>
<exclusion>
<groupId>io.netty</groupId>
<artifactId>netty-buffer</artifactId>
</exclusion>
</exclusions>
需要注意的是 netty-all 不能顶替所有其他的netty的依赖,比如 netty-common
<exclusions>
<exclusion>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
</exclusion>
</exclusions>
classnotfound 问题
Caused by: java.lang.ClassNotFoundException: com.fasterxml.jackson.databind.util.LookupCache
需要引入如下的依赖
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.13.4.1</version>
<scope>compile</scope>
</dependency>
类加载问题
maven。scope元素主要用来控制依赖的使用范围,指定当前包的依赖范围和依赖的传递性,也就是哪些依赖在哪些classpath中可用。常见的可选值有:compile, provided, runtime, test, system等。
compile:默认值。compile表示对应依赖会参与当前项目的编译、测试、运行等,是一个比较强的依赖。打包时通常会包含该依赖,部署时会打包到lib目录下。比如:spring-core这些核心的jar包。
provided:provided适合在编译和测试的环境,和compile功能相似,但provide仅在编译和测试阶段生效,provide不会被打包,也不具有传递性。比如:上面讲到的spring-boot-devtools、servlet-api等,前者是因为不需要在生产中热部署,后者是因为容器已经提供,不需要重复引入。
runtime:仅仅适用于运行和测试环节,在编译环境下不会被使用。比如编译时只需要JDBC API的jar,而只有运行时才需要JDBC驱动实现。
test:scope为test表示依赖项目仅参与测试环节,在编译、运行、打包时不会使用。最常见的使用就是单元测试类了。
system:system范围依赖与provided类似,不过依赖项不会从maven仓库获取,而需要从本地文件系统提供。使用时,一定要配合systemPath属性。不推荐使用,尽量从Maven库中引用依赖。
import: import scope只能用在dependencyManagement里面。表示从其它的pom中导入dependency的配置。
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/sql/SparkSession$
at org.apache.spark.sql.execution.datasources.v2.odps.SparkHiveExample$.main(SparkHiveExample.scala:42)
at org.apache.spark.sql.execution.datasources.v2.odps.SparkHiveExample.main(SparkHiveExample.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.SparkSession$
at java.net.URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
... 2 more
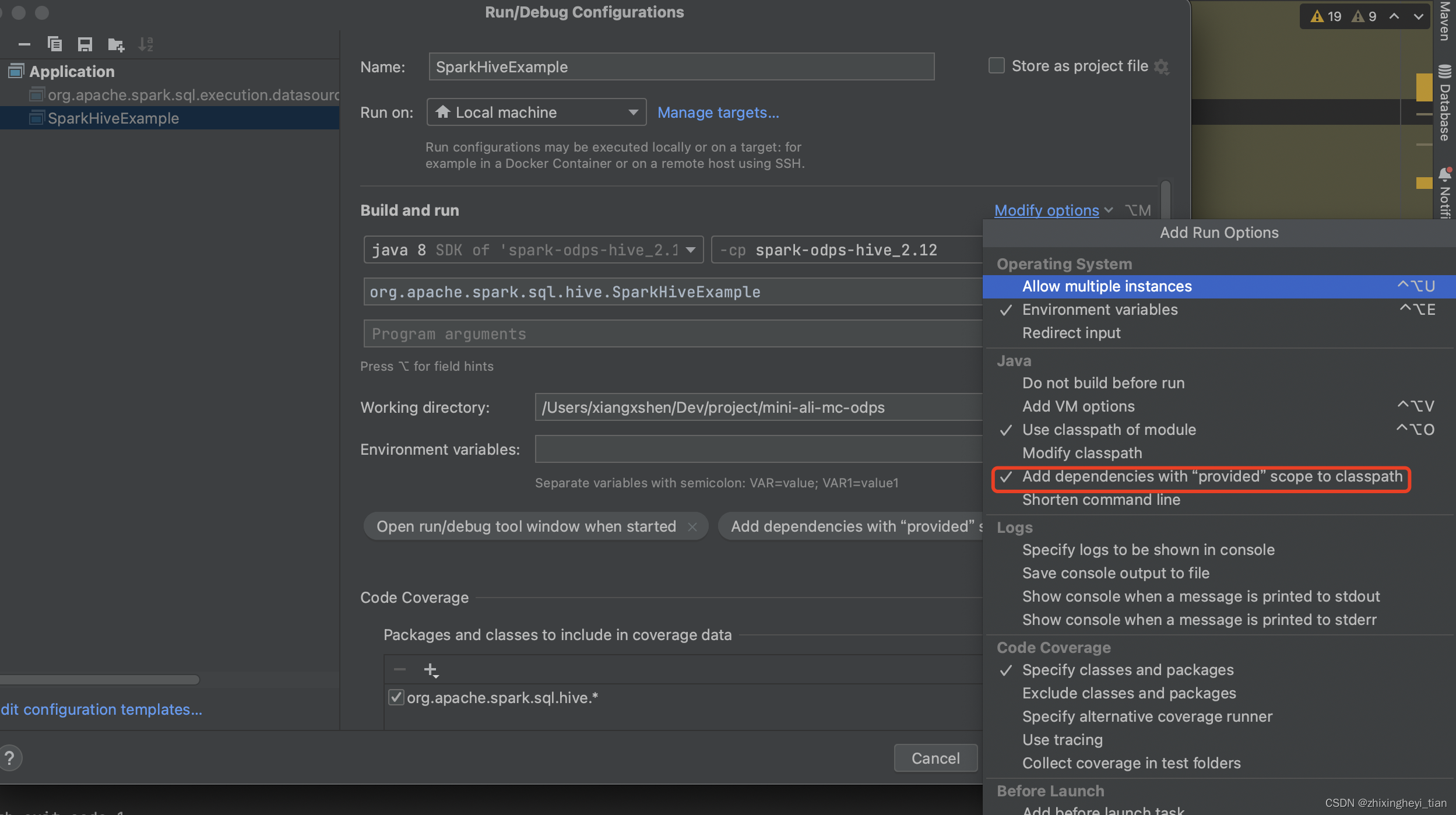
如果以上不生效,
那就去掉依赖中的
<scope>provided</scope>
scala 相关类找不到
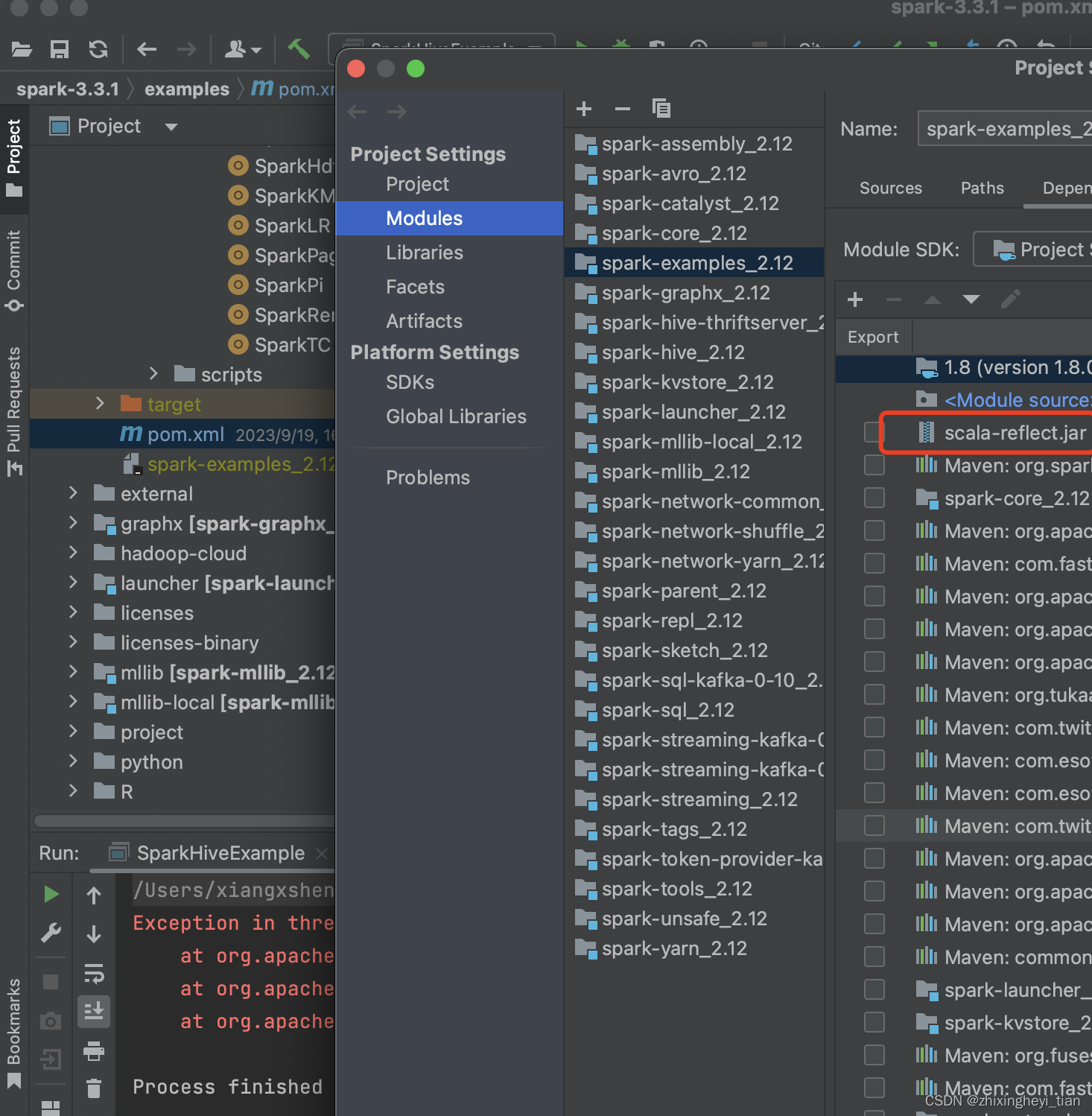
java.lang.ClassNotFoundException: scala.reflect.api.TypeCreator
如下图,
可以手动添加 reflect jar