1、二维卷积函数——cnv2d():
'''
in_channels (int): 输入通道数
out_channels (int): 输出通道数
kernel_size (int or tuple): 卷积核大小
stride (int or tuple, optional): 步长 Default: 1
padding (int, tuple or str, optional): 填充 Default: 0
padding_mode (str, optional): 填充模式 Default: 'zeros'
dilation (int or tuple, optional): Default: 1
groups (int, optional): Default: 1
bias (bool, optional): 偏置 Default: ``True``
'''从数据集中加载数据(batch_size=64)
dataset = torchvision.datasets.CIFAR10(root="./train_dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=64)
建立2维卷积网络模型
class Diviner(nn.Module):
def __init__(self):
super(Diviner,self).__init__()
self.conv1 = Conv2d(in_channels=3,out_channels=6, kernel_size=(3,3) , stride=(1,1),padding=0)
def forward(self,x):
x = self.conv1(x)
return x
实例化网络模型,并将卷积后得到的图片在tensorboard中展示
diviner = Diviner()
writer = SummaryWriter("conv")
step = 0
for data in dataloader:
imgs,target = data
output = diviner(imgs)
writer.add_images("input",imgs,step)
output = torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output,step)
step = step + 1
writer.close()

2、线性层函数——Linear()
'''
in_features: size of each input sample
out_features: size of each output sample
bias: If set to ``False``, the layer will not learn an additive bias. Default: ``True``
'''加载数据集(略)
建立线性网络模型
class Diviner(nn.Module):
def __init__(self):
super(Diviner, self).__init__()
self.linear1 = Linear(196608,10)
def forward(self,input):
output = self.linear1(input)
return output
3、最大池化函数——maxpooling()
加载数据集(略)
建立最大池化层网络模型
class Diviner(nn.Module):
def __init__(self):
super(Diviner, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
def forward(self,input):
output = self.maxpool1(input)
return output
实例化网络模型,并将池化后得到的图片在tensorboard中展示
writer = SummaryWriter("maxpooling")
step = 0
for data in dataloader:
imgs,targets = data
output = diviner(imgs)
writer.add_images("input", imgs, step)
writer.add_images("output",output,step)
step = step + 1
writer.close() 

4、激活函数——sigmoid()、relu()
加载数据集(略)
建立激活函数网络模型
class Diviner(nn.Module):
def __init__(self):
super(Diviner, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output实例化网络模型,并将激活后得到的图片在tensorboard中展示
diviner = Diviner()
step = 0
writer = SummaryWriter("relu")
for data in dataloader:
imgs,targets = data
output = diviner(imgs)
writer.add_images("relu",output,step)
step = step + 1
writer.close()
5、损失函数——loss()
加载数据集(略)
建立一个网络模型
class Diviner(nn.Module):
def __init__(self):
super(Diviner, self).__init__()
self.modle1 = Sequential(
Conv2d(3, 32, (5, 5), padding=2),
MaxPool2d(2),
Conv2d(32, 32, (5, 5), padding=2),
MaxPool2d(2),
Conv2d(32, 64, (5, 5), padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x = self.modle1(x)
return x
实例化网络模型,定义损失函数和优化器(反向传播)
diviner = Diviner()
loss = nn.CrossEntropyLoss()
optim = torch.optim.SGD(diviner.parameters(),lr=0.05)
我们进行迭代,并记录损失值
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs,targets = data
outputs =diviner(imgs)
result_loss = loss(outputs,targets)
optim.zero_grad()
result_loss.backward()
optim.step()
running_loss += result_loss
print(running_loss)6、使用GPU进行完整模型训练
import torch
import torchvision
#准备数据集
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
train_data = torchvision.datasets.CIFAR10(root="./train_dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10(root="./train_dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据库的长度{}".format(train_data_size))
print("测试数据库的长度{}".format(test_data_size))
#利用dataloader来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
#创建网络模型
class Diviner(nn.Module):
def __init__(self):
super(Diviner, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, (5, 5), (1, 1), 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, (5, 5), (1, 1), 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, (5, 5), (1, 1), 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, input):
x = self.model(input)
return x
diviner = Diviner()
diviner = diviner.cuda() #模型
#损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda() #损失函数
#优化器
learn_rate = 0.01
optimizer = torch.optim.SGD(diviner.parameters(),lr=learn_rate)
#设置训练网络的一些参数
#记录训练的次数
total_train_step = 0
#记录测试的次数
total_test_step = 0
#训练的轮次
epoch = 10
writer = SummaryWriter("train")
for i in range(epoch):
print("-------第{}轮训练开始了-------".format(i+1))
#训练步骤开始:
diviner.train() #非必要,在特定层
for data in train_dataloader:
imgs,targets = data
#数据
imgs = imgs.cuda()
targets = targets.cuda()
outputs = diviner(imgs)
loss = loss_fn(outputs,targets)
#优化器模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if(total_train_step%100 == 0):
print("训练次数:{},loss:{}".format(total_train_step,loss))
writer.add_scalar("train_loss",loss.item(),total_train_step)
#测试步骤开始:
diviner.eval() #非必要 在特定层
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs,targets = data
imgs = imgs.cuda()
targets = targets.cuda()
outputs = diviner(imgs)
loss = loss_fn(outputs,targets)
total_test_loss += loss
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy += accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss",total_test_loss,total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step += 1
#保存模型
torch.save(diviner,"diviner_{}".format(i))
writer.close()

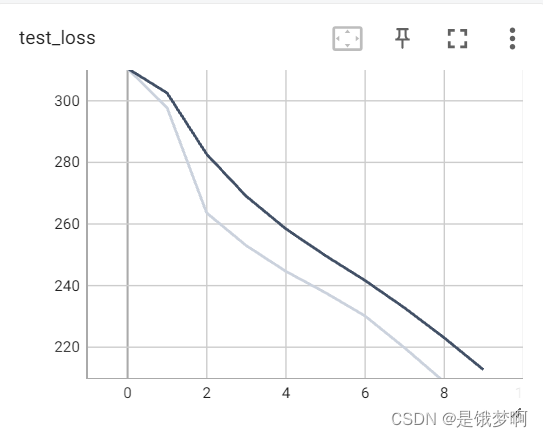
最后一轮数据:
-------第10轮训练开始了-------
训练次数:7100,loss:1.2293018102645874
训练次数:7200,loss:0.9501622319221497
训练次数:7300,loss:1.0970317125320435
训练次数:7400,loss:0.8500756025314331
训练次数:7500,loss:1.195753812789917
训练次数:7600,loss:1.2974092960357666
训练次数:7700,loss:0.8670048117637634
训练次数:7800,loss:1.2882726192474365
整体测试集上的loss:197.17103576660156
整体测试集上的正确率:0.5577999949455261







