本篇主要总结的是stack和queue的模拟实现以及deque的原理
stack的模拟实现
和前面的模拟实现相同,首先要看官方实现的功能


这里引入了Container的概念,从字面意思来看,也就是说,在实例化模板的时候实际上是需要实例化两个参数的,一个是栈内元素的数据类型,一个是容器的类型,这里通过缺省参数给定了一个deque,因此平时使用的时候不需要实例化第二个参数,关于deque的概念后面再进行讲解
从中可以看出,stack的实现是以一个容器为模板,在这个模板的基础上引申出了栈的概念,因此在模拟实现的过程中相对容易一些
#include <iostream>
#include <vector>
#include <list>
#include <deque>
namespace mystack
{
template <class T,class Container>
class stack
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back();
}
bool empty()
{
return _con.empty();
}
int size()
{
return _con.size();
}
const T& top()
{
return _con.back();
}
private:
Container _con;
};
}
但是在实际的栈的实现中,是使用带有缺省参数的模板参数,在容器的实现中是使用的是deque,因此在使用STL中的模板实例化只需要实例化第一个参数即可,默认是使用的是deque,也可以实例化为vector和list
#include "stack.h"
#include <stack>
// 采用vector来当容器生成栈
int main()
{
std::stack<int, std::vector<int>> s;
// 入栈
s.push(1);
s.push(2);
s.push(3);
s.push(4);
// 出栈
while (!s.empty())
{
std::cout << s.top() << " ";
s.pop();
}
return 0;
}
#include "stack.h"
#include <stack>
// 采用list来当容器生成栈
int main()
{
std::stack<int, std::list<int>> s;
// 入栈
s.push(1);
s.push(2);
s.push(3);
s.push(4);
// 出栈
while (!s.empty())
{
std::cout << s.top() << " ";
s.pop();
}
return 0;
}
deque
那么下面引入deque的概念,什么是deque,它的用法又是什么?
还是从cplusplus中查阅它的概念
deque的概念
deque也被叫做双端队列,从名字可以看出通俗来说它就是在两端都可以进出的队列,因此可以随意的头插头删尾插尾删
deque的底层实现方式
从上面的内容可以知道,deque可以实现在容器两端进行插入删除的操作,那其内部是如何进行工作的?

上面是两个容器的不同点,其实可以看出vector的优点其实就对应的是list的缺点,而list的优点就对应了vector的缺点,因此才需要根据不同的实验需求选择对应的容器来使用
deque的原理
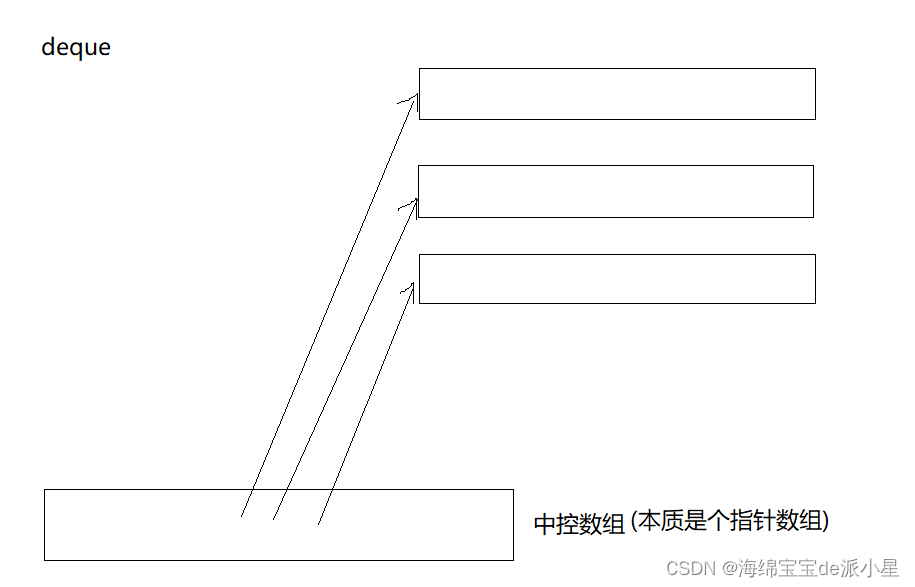
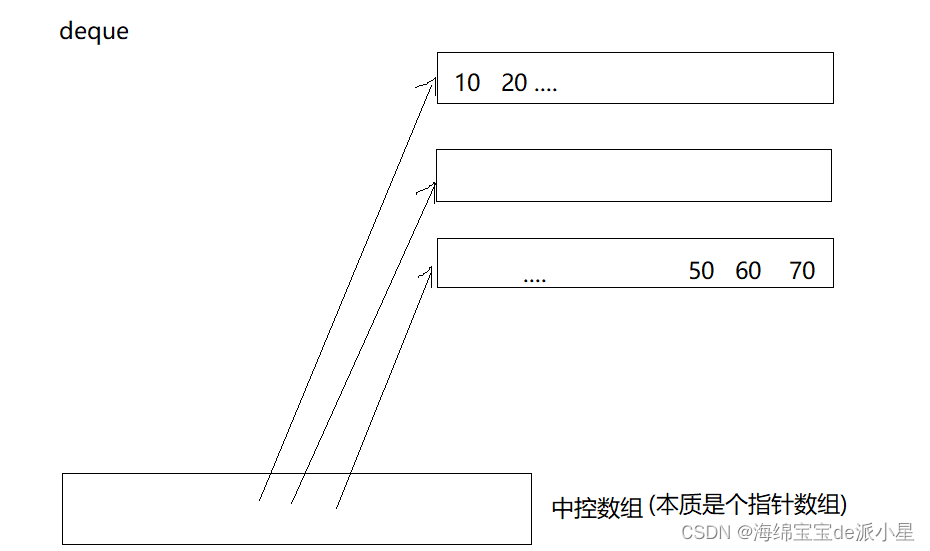
deque的原理就是采用了一个中控数组用来管理每一个小数组,所以中控数组是一个指针数组,其中存储的是每一个小数组的指针,当需要插入元素的时候,就在这个中控数组的中间部分的指针指向的元素中进行插入,这样的模式就导致它具备了向前面插入数据,也具备了向后面插入数据的能力
向头部和尾部插入数据:
如果头部有数据继续头插,那么就会开辟额外的小数组用来存储
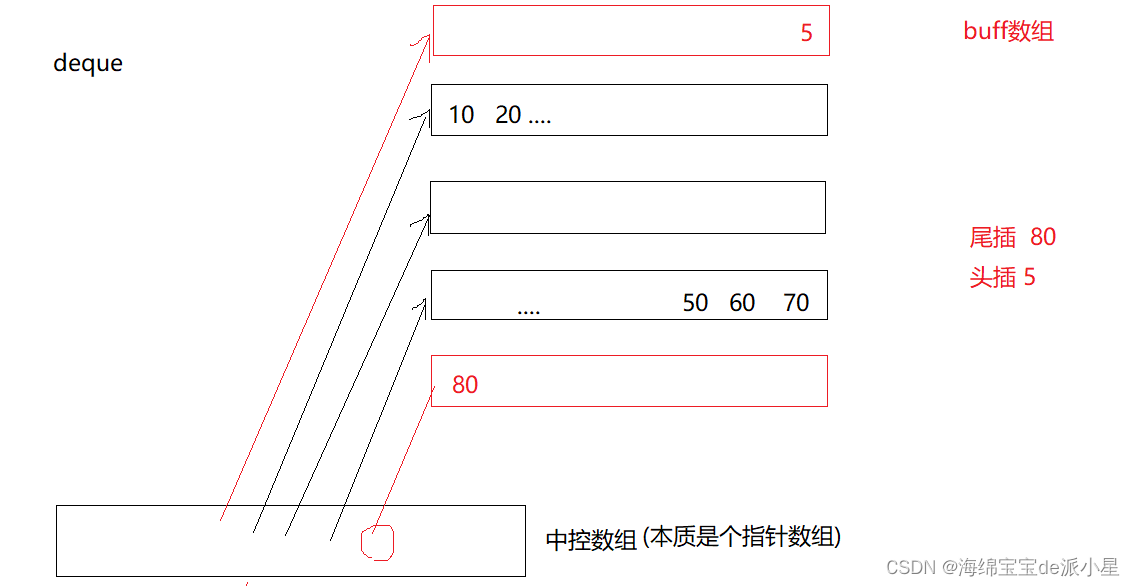
但是这样就产生了一个问题,如果中控数组控制的小数组已经排满了数据,但是我还要实施插入的操作应该如何实现?
- 可以整体挪动数据,把所有数组向后挪动一位
- 可以对单个小数组进行扩容,使得每一个小数组的长度不一样
这是两种扩容的思路,如果采用第一种思路,那么在挪动数据的时候效率会很低,但是优势是进行下标的随机访问的时候拥有更高效的功能
如果采用的是第二种思路,那么在插入数据的时候成本很低,但是在访问的时候就有较高的计算成本
因此两种扩容思路都有其好的一点和坏的一点,具体如何实施看对于容器的需求如何
在实际的使用场景中,对于deque其实是不常用的,因为它兼容了vector和list的部分优势,但是在随机访问的情况下不如vector,在插入删除数据的方面不如list,只是出于一个较为兼容的容器,在实际开发中应用场景并不多

那为什么会选择deque作为底层容器的实现?
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以; queue是先进先出的特殊线性数据结构,只要具有push_back()和pop_front()操作的线性结构,都可以作为queue的底层容器,比如list
但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作- 在
stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高,结合了deque的优点,而完美的避开了其缺陷
queue的模拟实现
#include <iostream>
#include <vector>
#include <list>
#include <deque>
namespace myqueue
{
template <class T,class Container=std::deque<T>>
class queue
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_front();
}
bool empty()
{
return _con.empty();
}
int size()
{
return _con.size();
}
const T& front()
{
return _con.front();
}
const T& back()
{
return _con.back();
}
private:
Container _con;
};
}
#include "queue.h"
int main()
{
myqueue::queue<int> q;
// 插入数据
q.push(1);
q.push(2);
q.push(3);
q.push(4);
q.push(5);
// 打印数据
while (!q.empty())
{
std::cout << q.front() << " ";
q.pop();
}
return 0;
}
这里直接使用了deque作为缺省参数,因此实例化只需要使用一个参数即可









