 优质项目专栏:提升自身的硬实力:汇总有意义的项目设计集合,助力新人快速实战掌握技能,助力用户更好利用 CSDN 平台,自主完成项目设计升级,提升自身的硬实力。
优质项目专栏:提升自身的硬实力:汇总有意义的项目设计集合,助力新人快速实战掌握技能,助力用户更好利用 CSDN 平台,自主完成项目设计升级,提升自身的硬实力。

资料合集更优惠
-
第一期资料合集:
https://download.csdn.net/download/sinat_39620217/88114420 -
第二期资料合集:
待更新
1.项目合集第一期
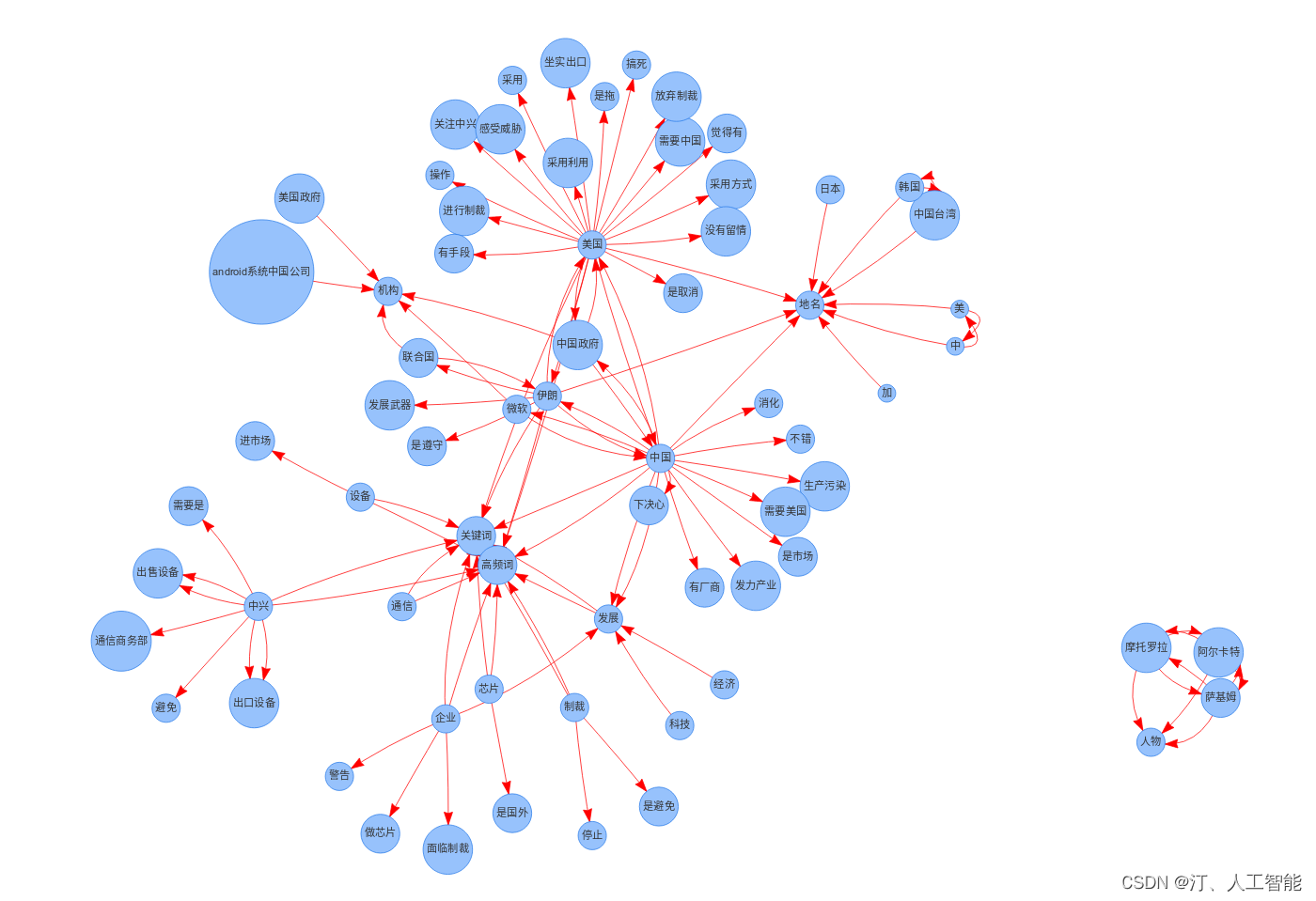
1.1. 文档关键信息提取形成知识图谱:基于NLP算法提取文本内容的关键信息生成信息图谱教程及码源(含pyltp安装使用教程)
* 项目介绍
目标:输入一篇文档,将文档进行关键信息提取,进行结构化,并最终组织成图谱组织形式,形成对文章语义信息的图谱化展示。
如何用图谱和结构化的方式,即以简洁的方式对输入的文本内容进行最佳的语义表示是个难题。 本项目将对这一问题进行尝试,采用的方法为:输入一篇文档,将文档进行关键信息提取,并进行结构化,并最终组织成图谱组织形式,形成对文章语义信息的图谱化展示。
效果展示:
1.2. OCR基于PaddleOCR的多视角集装箱箱号检测识别,实现检测识别模型串联推理。
一、项目介绍
集装箱号是指装运出口货物集装箱的箱号,填写托运单时必填此项。标准箱号构成基本概念:采用ISO6346(1995)标准
标准集装箱箱号由11位编码组成,如:CBHU 123456 7,包括三个部分:
- 第一部分由4位英文字母组成。前三位代码主要说明箱主、经营人,第四位代码说明集装箱的类型。列如CBHU 开头的标准集装箱是表明箱主和经营人为中远集运
- 第二部分由6位数字组成。是箱体注册码,用于一个集装箱箱体持有的唯一标识
- 第三部分为校验码由前4位字母和6位数字经过校验规则运算得到,用于识别在校验时是否发生错误。即第11位编号
本教程基于PaddleOCR进行集装箱箱号检测识别任务,使用少量数据分别训练检测、识别模型,最后将他们串联在一起实现集装箱箱号检测识别的任务
效果展示:


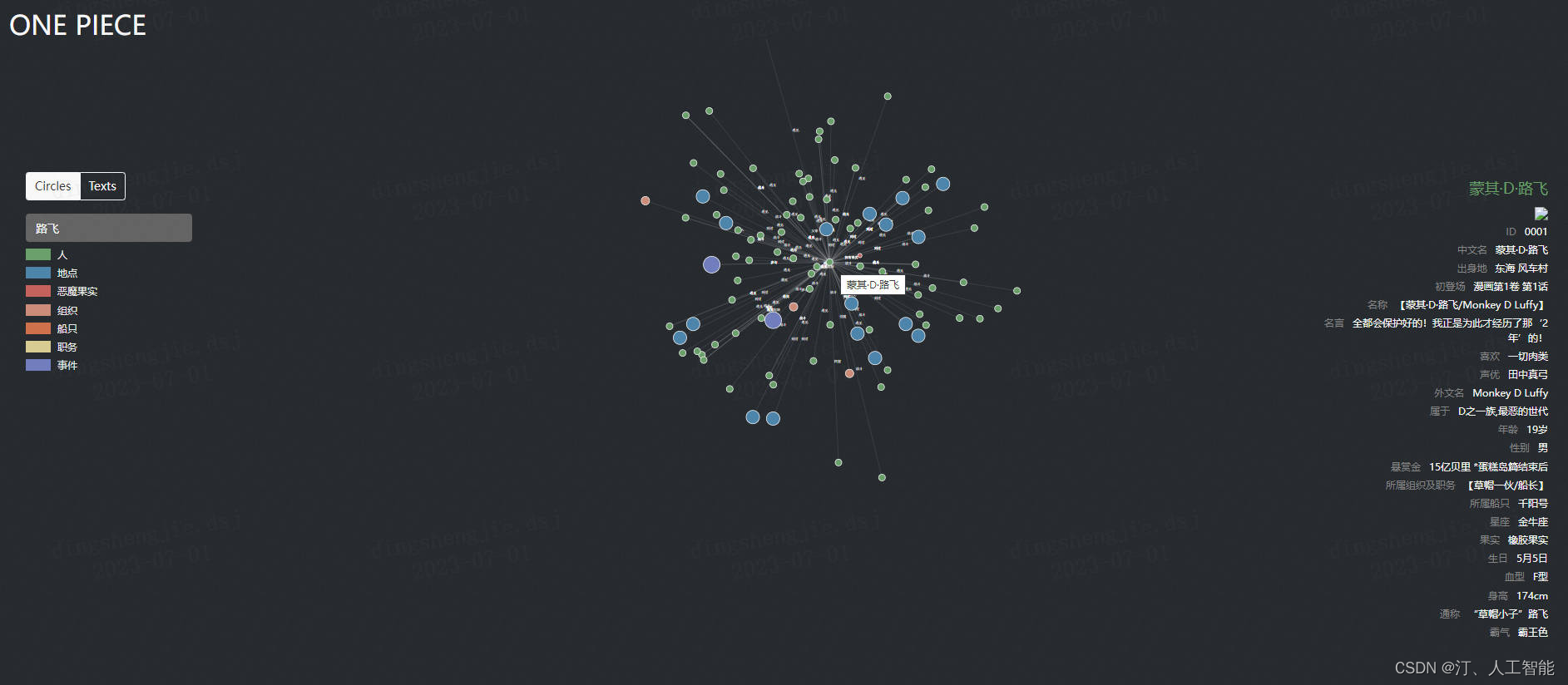
1.3. 知识图谱之《海贼王-ONEPICE》领域图谱项目实战(含码源):数据采集、知识存储、知识抽取、知识计算、知识应用、图谱可视化、问答系统(KBQA)等
- 项目背景& 项目内容
《海贼王》(英文名ONE PIECE) 是由日本漫画家尾田荣一郎创作的热血少年漫画,因为其宏大的世界观、丰富的人物设定、精彩的故事情节、草蛇灰线的伏笔,受到世界各地的读者欢迎,截止2019年11月7日,全球销量突破4亿6000万本[1],并被吉尼斯世界纪录官方认证为“世界上发行量最高的单一作者创作的系列漫画”[2]。
《海贼王》从1997年开始连载至今,以及将近22年,在900多话的漫画中大量性格鲜明的角色相继登场,故事发生的地点也在不断变化,这既给我们带来阅读的乐趣,同时也为我们梳理故事脉络带来了挑战。
本次任务试图为《海贼王》中出现的各个实体,包括人物、地点、组织等,构建一个知识图谱,帮助我们更好的理解这部作品。
本项目内容包括数据采集、知识存储、知识抽取、知识计算、知识应用五大部分
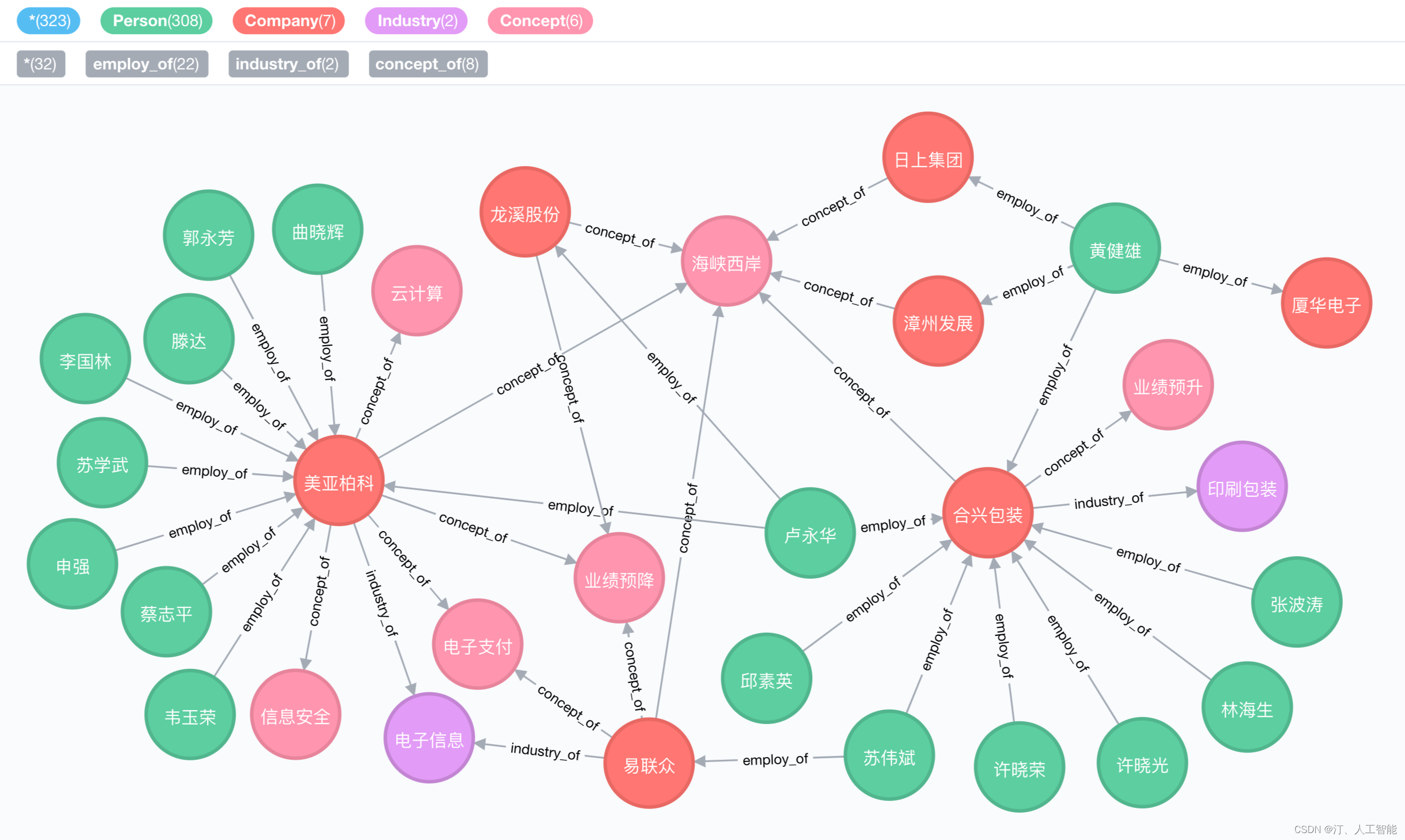
1.4. 手把手教学构建证券知识图谱/知识库(含码源):网页获取信息、设计图谱、Cypher查询、Neo4j关系可视化展示
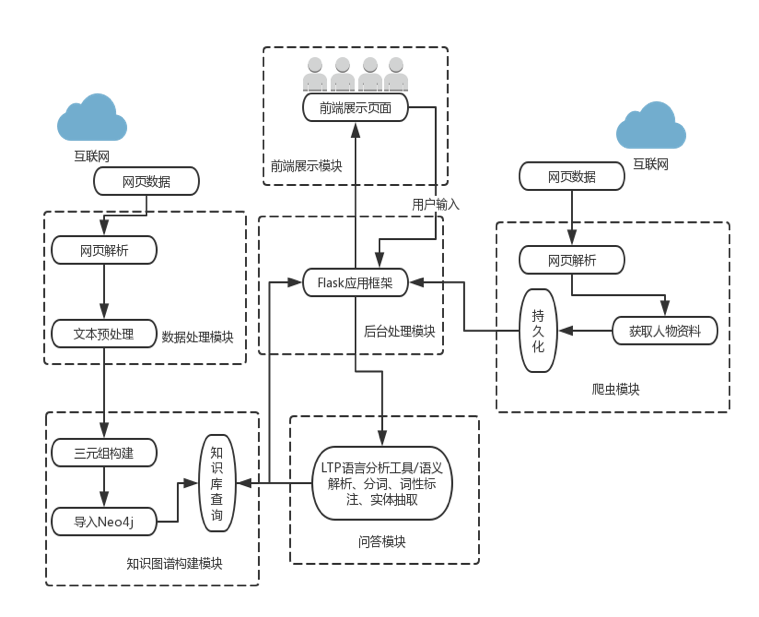
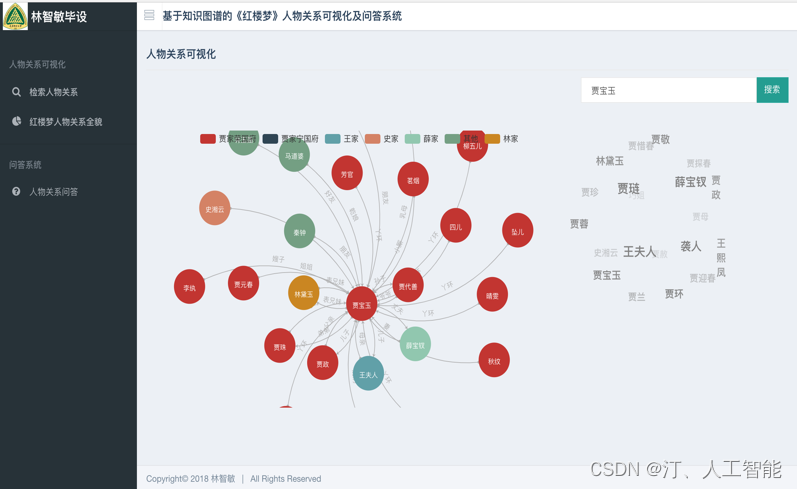
1.5. 基于知识图谱的《红楼梦》人物关系可视化及问答系统(含码源):命名实体识别、关系识别、LTP简单教学
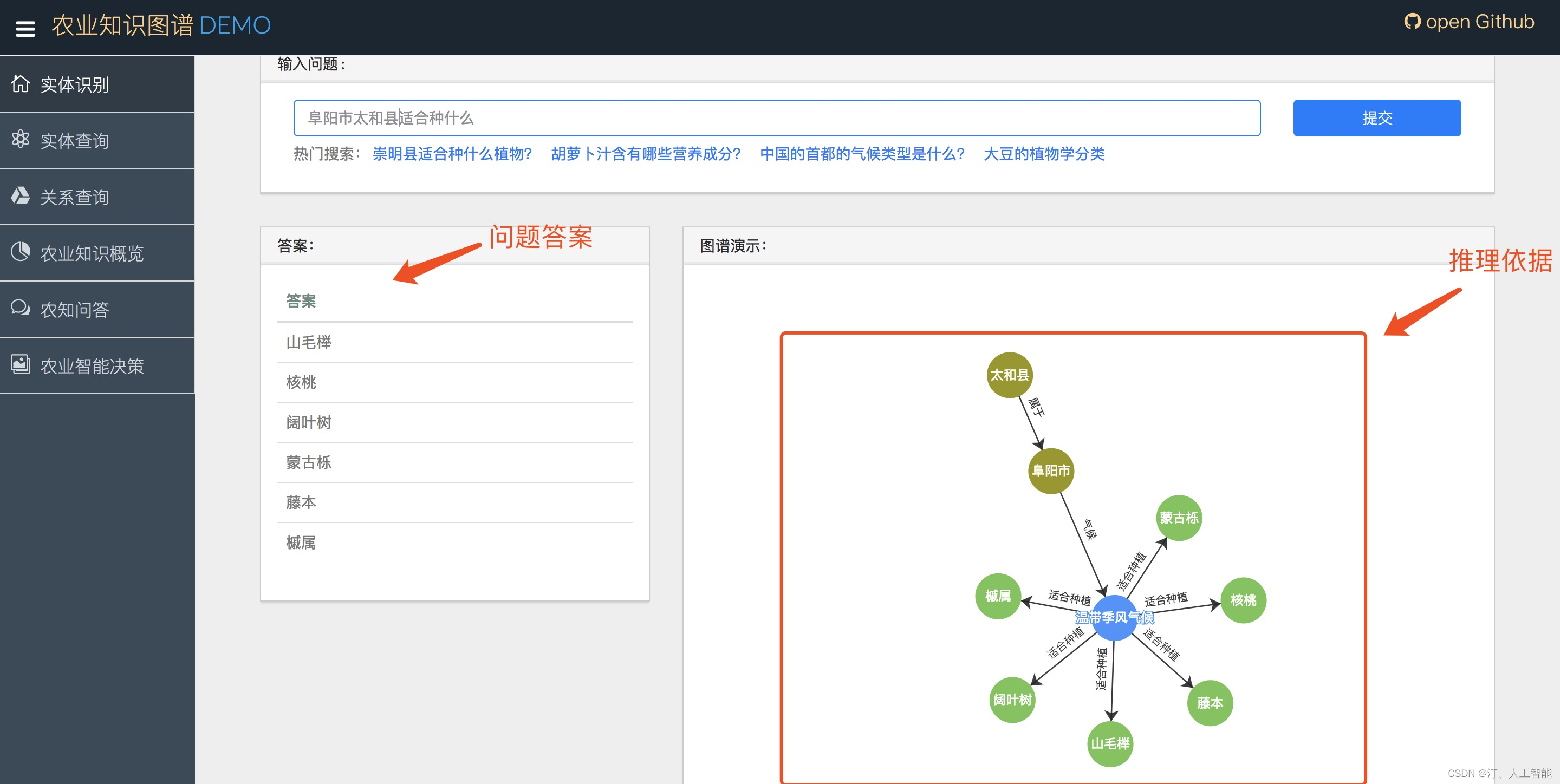
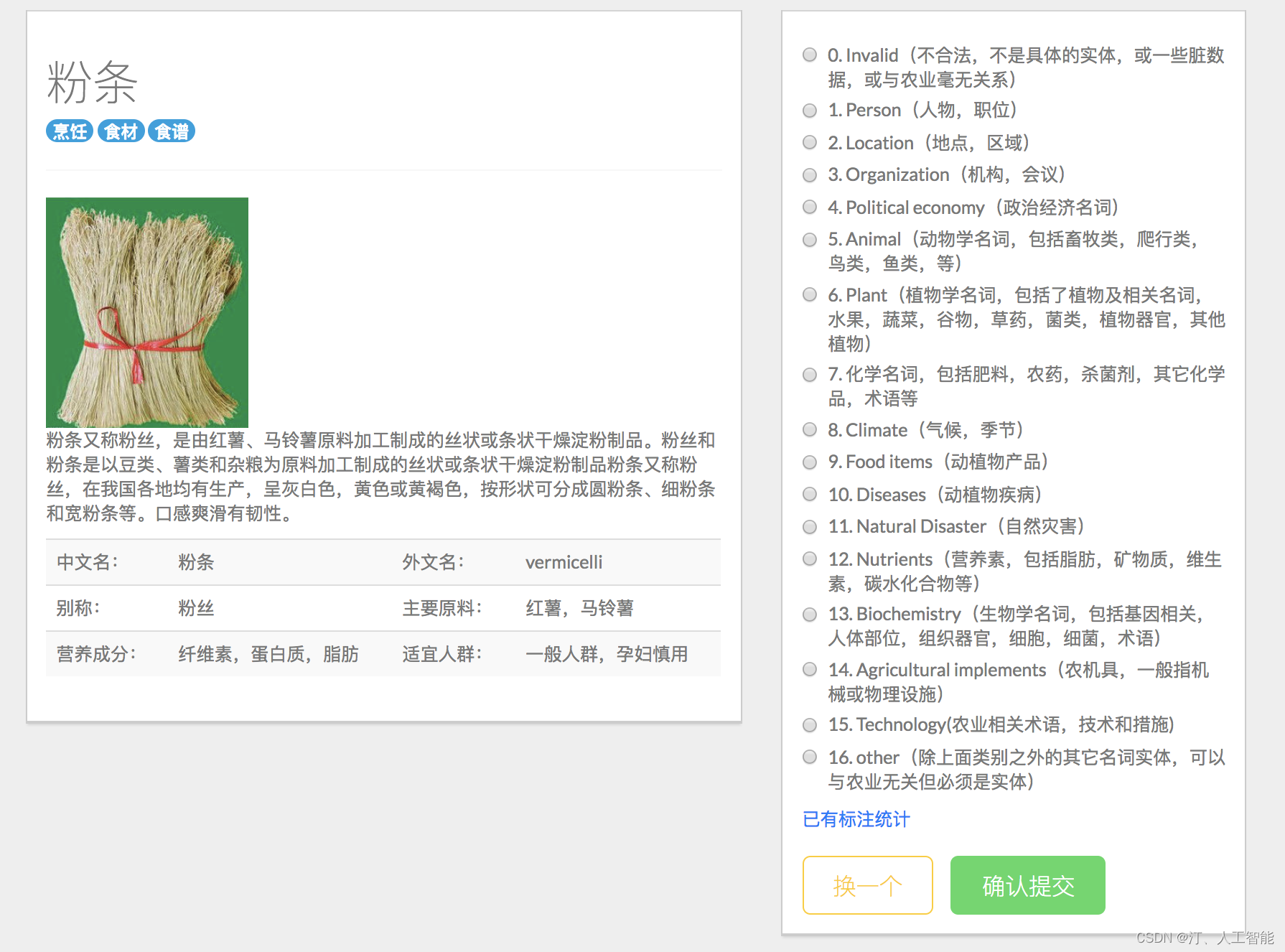
1.6. 手把手教学构建农业知识图谱:农业领域的信息检索+智能问答,命名实体识别,关系抽取,实体关系查询
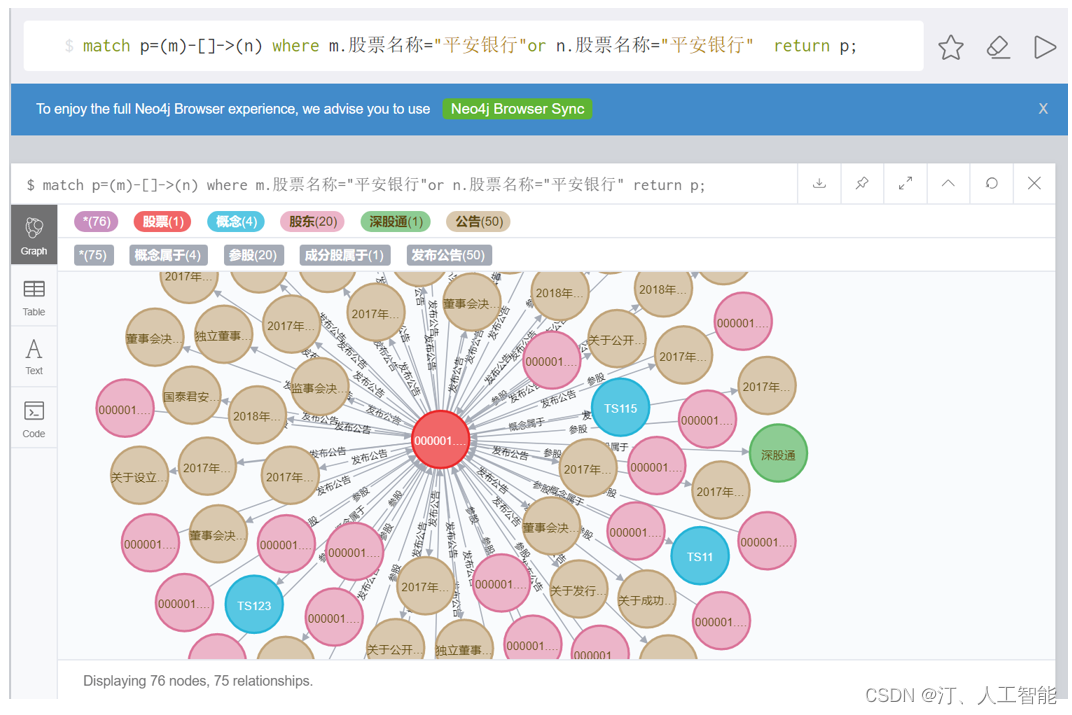
1.7 手把手教学小型金融知识图谱构建:量化分析、图数据库neo4j、图算法、关系预测、命名实体识别、Cypher Cheetsheet详细教学等
1.8 金融时间序列预测方法合集:CNN、LSTM、随机森林、ARMA预测股票价格(适用于时序问题)、相似度计算、各类评判指标绘图(数学建模科研适用)
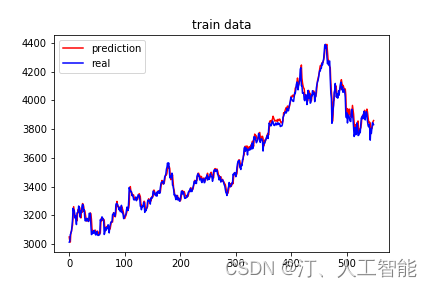
1.9 领域知识图谱-中式菜谱知识图谱:实现知识图谱可视化和知识库智能问答系统(KBQA)
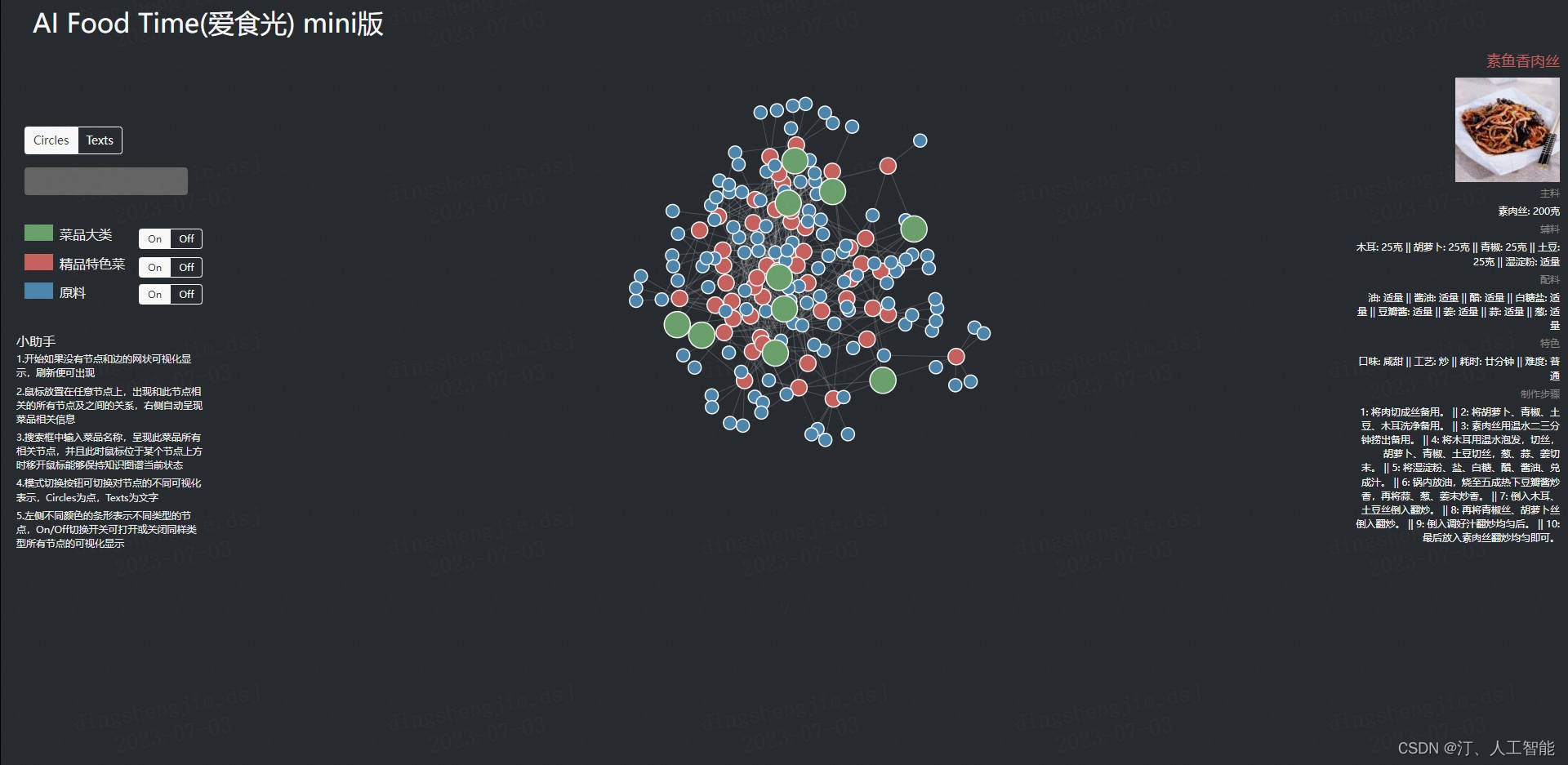
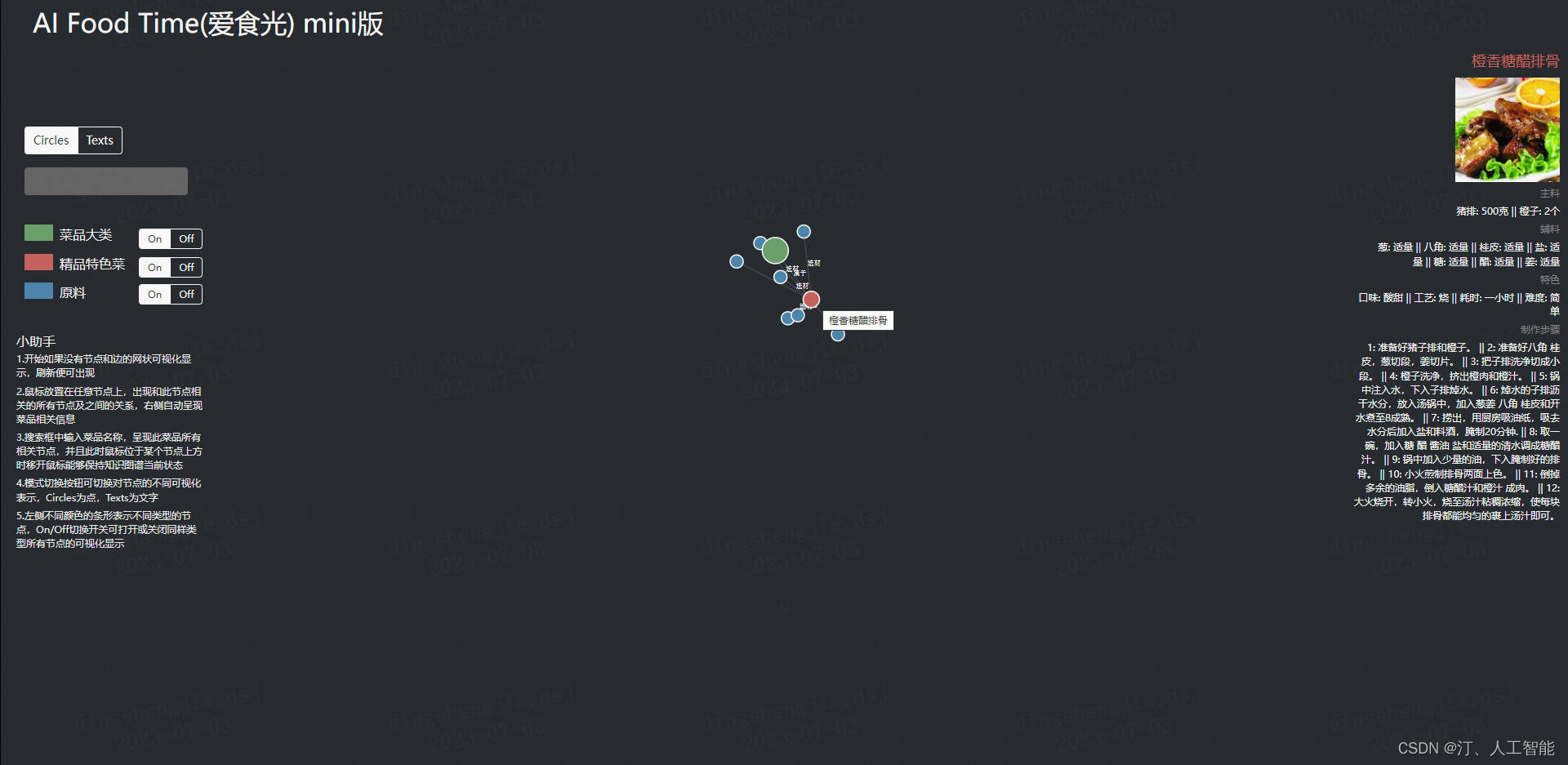
本项目开发的系统名称为AI Food Time,中文名为爱食光。如需体验可视化功能可直接访问点击可视化功能。
通过收集网上完全公开的有关中式菜谱的数据,经过数据清洗和分析,转换为知识图谱的存储结构,并提供可视化展示与搜索和智能问答等功能,为热爱美食与烹饪的人们提供方便快捷的中式菜谱服务,并以知识图谱的形式直观显示出不同菜品的关系及所用原料,在生活中具有很大的实际应用需求,包括:
一类菜品的不同具体做法,例如水煮鱼包括麻辣水煮鱼、小清新版水煮鱼和家常版水煮鱼等;
通过菜品与食材的关联关系,可以查询家中现有食材可以烹饪哪些菜品;
可以直接显示出每种菜品所需主料,辅料,配料及其具体数量和烹饪方法,与网上的一些菜谱网页相比更加简单直观;
可视化能够对各种菜品及关联关系有一个全局的认识,并能够显示每种菜品对应的图片;
智能问答系统可采用自然语言进行提问,系统反馈答案结果。
1.10 从零开始的知识图谱生活,构建一个百科知识图谱,完成基于Deepdive的知识抽取、基于ES的简单语义搜索、基于 REfO 的简单KBQA

1.11 从零开始构建一个电影知识图谱,实现KBQA智能问答[上篇]:本体建模、RDF、D2RQ、SPARQL endpoint与两种交互方式详细教学

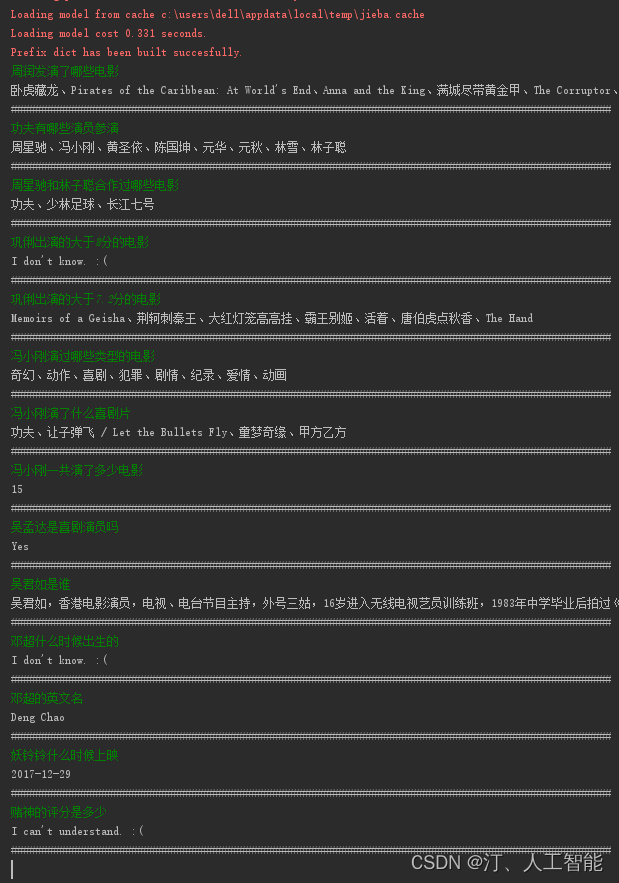
1.12 领域知识图谱的医生推荐系统:利用BERT+CRF+BiLSTM的医疗实体识别,建立医学知识图谱,建立知识问答系统
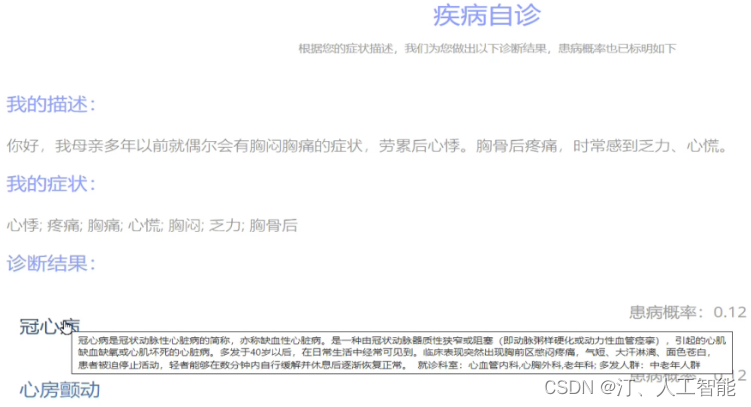

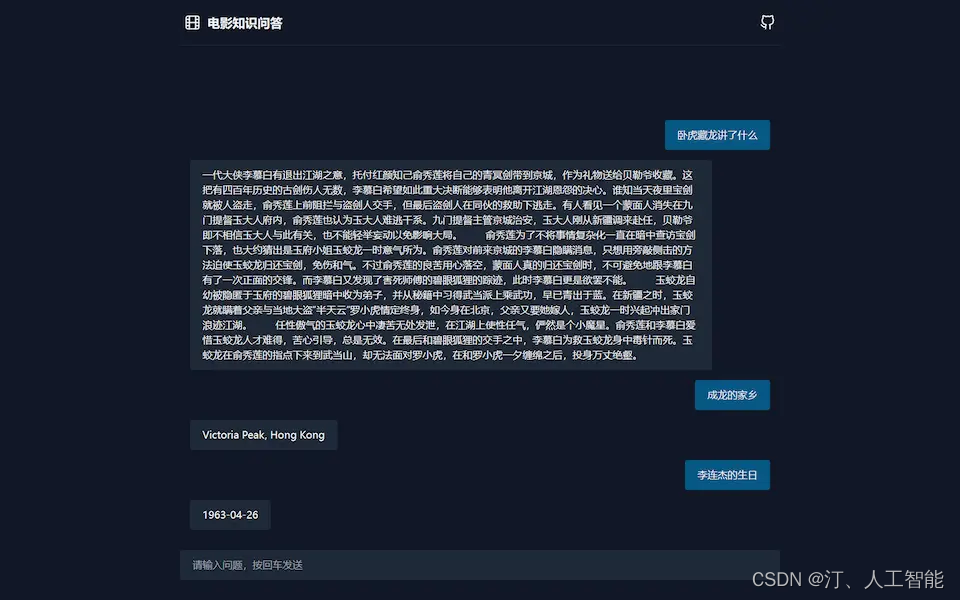
1.13 基于知识图谱的电影知识问答系统:训练TF-IDF 向量算法和朴素贝叶斯分类器、在 Neo4j 中查询
1.14 学科知识图谱学习平台项目 :技术栈Java、Neo4j、MySQL等超详细教学
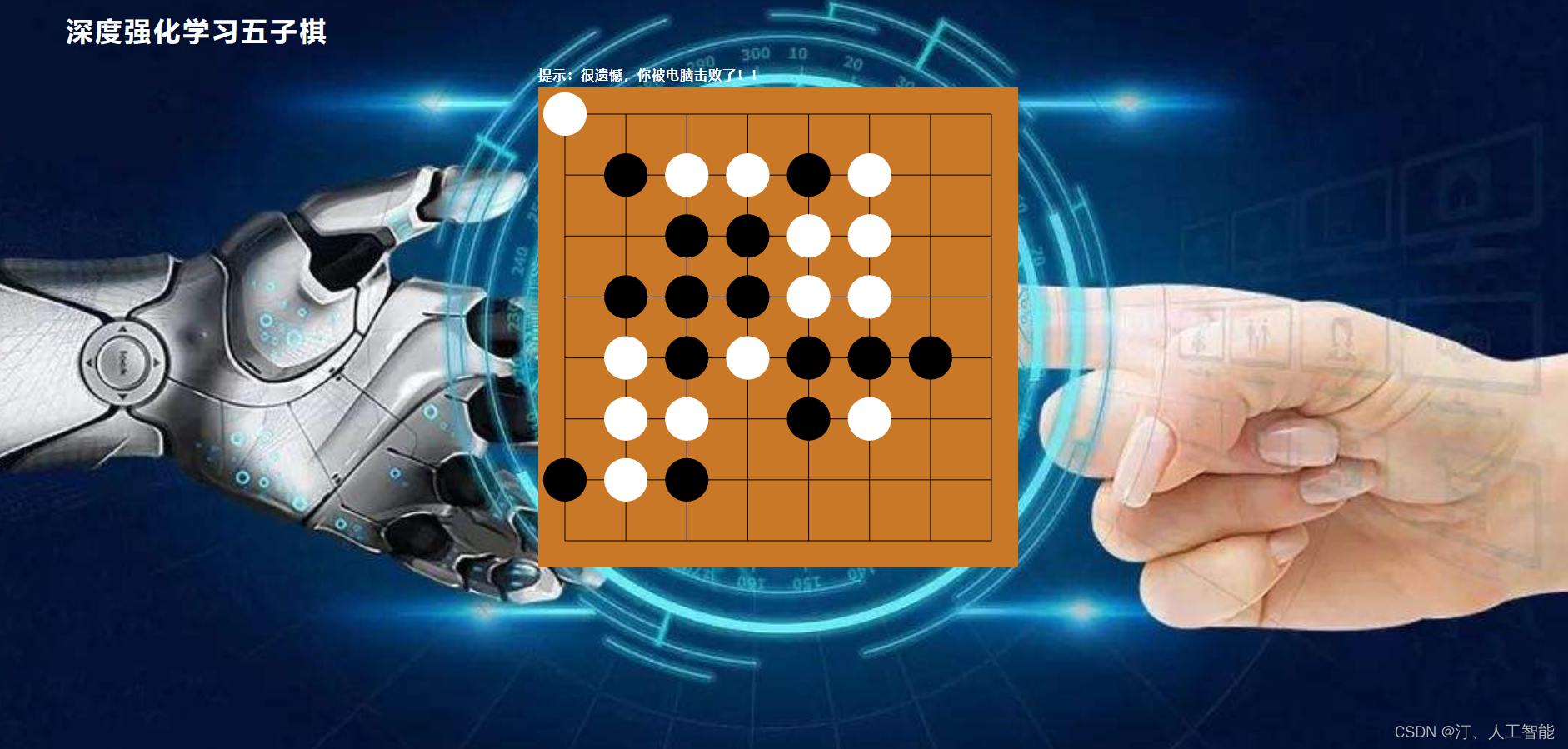
1.15 强化学习:实现了基于蒙特卡洛树和策略价值网络的深度强化学习五子棋(含码源)
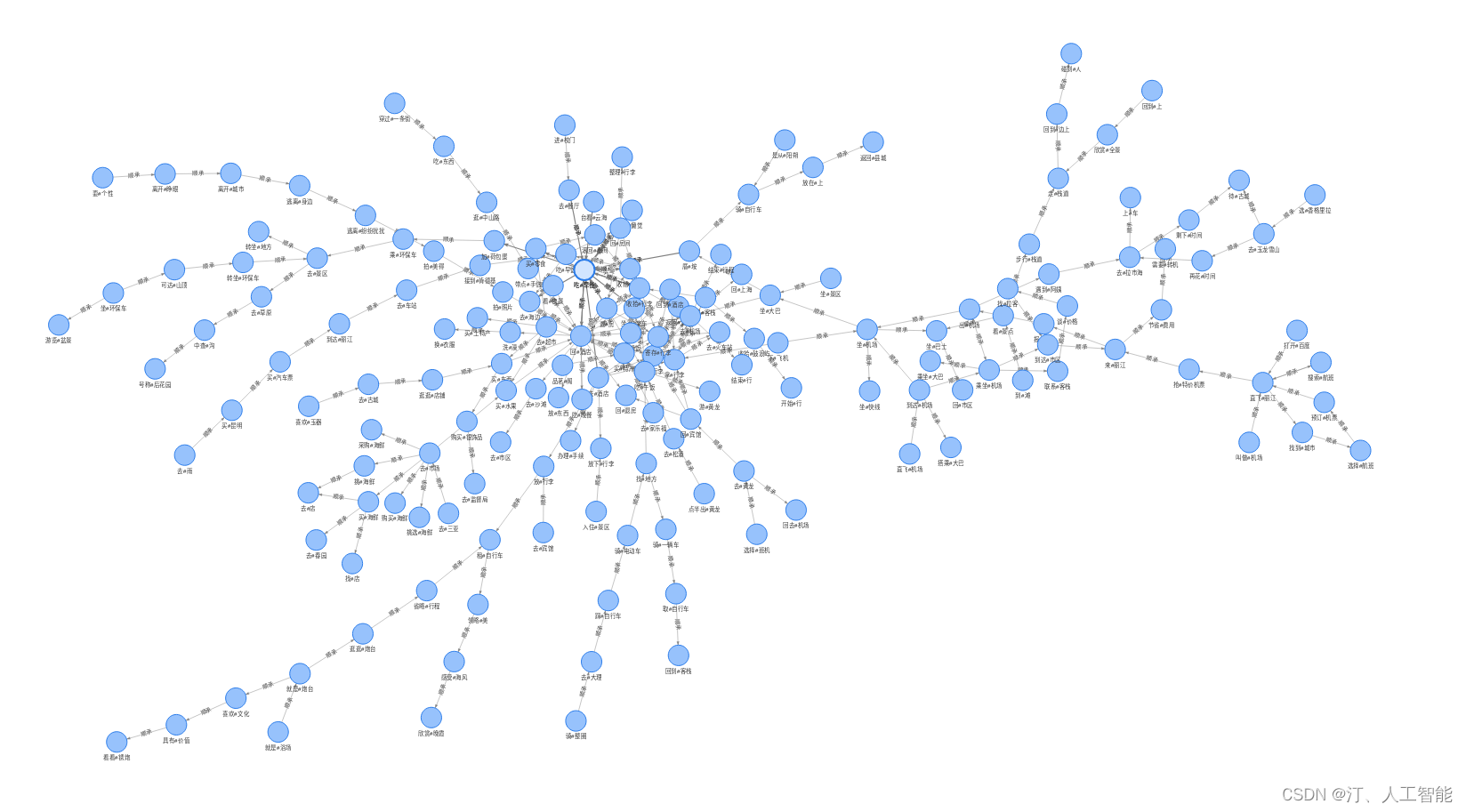
1.16 基于50W携程出行攻略构建事件图谱(含码源):交通工具子图谱、订酒店吃饭事件图谱等
1.17 从零开始搭建医药领域知识图谱实现智能问答与分析服务(含码源):含Neo4j基于垂直网站数据的医药知识图谱构建、医药知识图谱的自动问答等

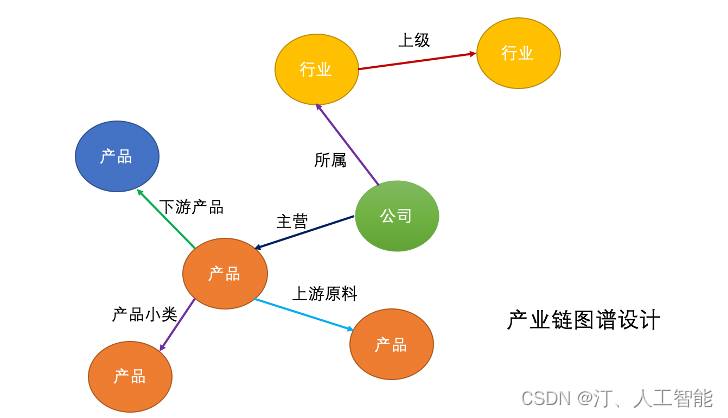
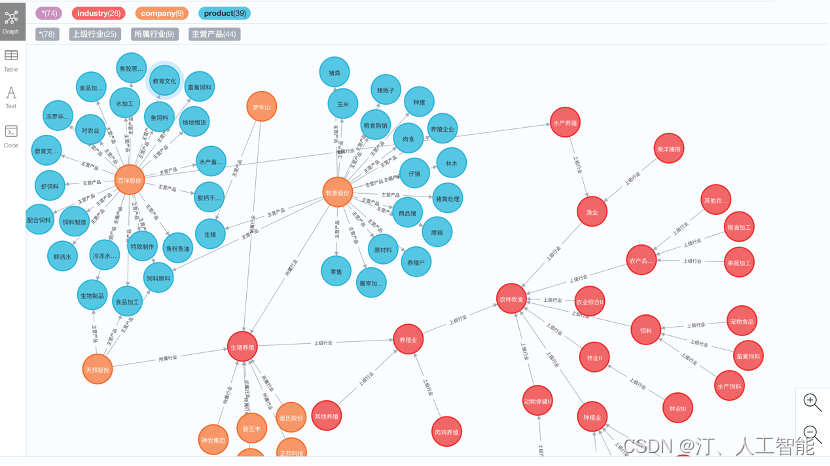
1.18 金融领域:产业链知识图谱包括上市公司、行业和产品共3类实体,构建并形成了一个节点10w+,关系边16w的十万级别产业链图谱
1.19 中文人物关系知识图谱(含码源):中文人物关系图谱构建、数据回标、基于远程监督人物关系抽取、知识问答等应用.
1.20 基于因果关系知识库的因果事件图谱构建、文本预处理、因果事件抽取、事件融合等
2.项目合集 第二期
2.1 从零构建医疗领域知识图谱的KBQA问答系统:其中7类实体,约3.7万实体,21万实体关系。
2.2 基于新浪微博海量用户行为数据、博文数据数据分析:包括综合指数、移动指数、PC指数三个指数
2.3 电子商务平台市场动向的数据分析平台:阿里商品指数,包括淘宝采购指数,淘宝供应指数,1688供应指数。
2.4 基于罪名法务智能知识图谱(含码源):基于280万罪名预测、20W法务问答与法律资讯问答功能
2.5 MedicalGPT:基于LLaMA-13B的中英医疗问答模型(LoRA)、实现包括二次预训练、有监督微调、奖励建模、强化学习训练[LLM:含Ziya-LLaMA]。
2.6 中文LLaMA模型和指令精调的Alpaca大模型:中文数据进行二次预训练,进一步提升了中文基础语义理解能力
2.7 ChatIE:通过多轮问答问题实现实命名实体识别和关系事件的零样本信息抽取,并在NYT11-HRL等数据集上超过了全监督模型
2.8 基于中文金融知识的 LLaMA 系微调模型的智能问答系统:LLaMA大模型训练微调推理等详细教学
2.9 ChatPaper全流程加速科研:论文阅读+润色+优缺点分析与改进建议+审稿回复
2.10 GPT学术优化 (GPT Academic):支持一键润色、一键中英互译、一键代码解释、chat分析报告生成、PDF论文全文翻译功能、互联网信息聚合+GPT等等
2.11 ChatGenTitle:使用百万arXiv论文信息在LLaMA模型上进行微调的论文题目生成模型
2.12 VLE基于预训练文本和图像编码器的图像-文本多模态理解模型:支持视觉问答、图文匹配、图片分类、常识推理等
2.13 TextBrewer:融合并改进了NLP和CV中的多种知识蒸馏技术、提供便捷快速的知识蒸馏框架、提升模型的推理速度,减少内存占用
未完待续不定期更新
资料合集更优惠
-
第一期资料合集:
https://download.csdn.net/download/sinat_39620217/88114420 -
第二期资料合集:








