02_elasticsearch 核心概念
1、lucene和elasticsearch的前世今生
1、lucene和elasticsearch的前世今生
lucene:最先进、功能最强大的搜索库。但是直接基于lucene开发,非常复杂,api复杂(实现一些简单的功能,写大量的java代码),需要深入理解原理(各种索引结构)
elasticsearch:基于lucene,隐藏lucene复杂性,提供简单易用的restful api接口、java api接口(还有其他语言的api接口)
(1)分布式的文档存储引擎
(2)分布式的搜索引擎和分析引擎
(3)分布式,支持PB级数据
开箱即用,优秀的默认参数,不需要任何额外设置,完全开源
关于elasticsearch的一个传说,有一个程序员失业了,陪着自己老婆去英国伦敦学习厨师课程。程序员在失业期间想给老婆写一个菜谱搜索引擎,觉得lucene实在太复杂了,就开发了一个封装了lucene的开源项目,compass。后来程序员找到了工作,是做分布式的高性能项目的,觉得compass不够,就写了elasticsearch,让lucene变成分布式的系统。
2、elasticsearch的核心概念
(1)Near Realtime(NRT)
近实时。有两个意思。从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级。常规上讲的实时说的是写入到查询数据是在毫秒级。
(2)Cluster
集群。包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
(3)Node
节点。集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
(4)Document&field:
文档。es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。如下实例:
product document
{
"product_id": "1",
"product_name": "高露洁牙膏",
"product_desc": "高效美白",
"category_id": "2",
"category_name": "日化用品"
}
(5)Index:
索引。包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
ps: index -》 table
docment-〉》一条记录
(6)Type:
类型。每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field。比如商品index,里面存放了所有的商品数据,商品document。但是商品分很多种类,每个种类的document的field可能不太一样,比如说电器商品,可能还包含一些诸如售后时间范围这样的特殊field;生鲜商品,还包含一些诸如生鲜保质期之类的特殊field,这时就需要多个type:日化商品type、电器商品type、生鲜商品type
ps: 高本已经去掉 type的概念
日化商品type:product_id,product_name,product_desc,category_id,category_name
电器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鲜商品type:product_id,product_name,product_desc,category_id,category_name,eat_period
每一个type里面,都会包含一堆document
{
"product_id": "2",
"product_name": "长虹电视机",
"product_desc": "4k高清",
"category_id": "3",
"category_name": "电器",
"service_period": "1年"
}
{
"product_id": "3",
"product_name": "基围虾",
"product_desc": "纯天然,冰岛产",
"category_id": "4",
"category_name": "生鲜",
"eat_period": "7天"
}
需要注意的是:Elasticsearch 版本中5.x以前的multiple types还可以正常工作,但是6.x里面新创建的index只允许一个type了,从7.0开始将强制只有一个type
单index,多type结构弊端
人们经常会谈到index类似传统sql数据库的“database”,而type类似于"table"。现在想想,这是一个非常糟糕的比喻,而这个比喻会造成很多错误的假设。
在传统的sql数据库中,各个"table"之间是互相独立的,在一个表中的列都与另一个表相同名称的列无关。
①、而在我们elasticsearch中同一 Index 下,同名 Field 类型必须相同,即使不同的 Type;
②、同一 Index 下,TypeA 的 Field 会占用 TypeB 的资源(互相消耗资源),会形成一种稀疏存储的情况。尤其是 doc value ,为什么这么说呢?doc value为了性能考虑会保留一部分的磁盘空间,这意味着 TypeB 可能不需要这个字段的 doc_value 而 TypeA 需要,那么 TypeB 就被白白占用了一部分没有半点用处的资源;
③、Score 评分机制是 index-wide 的,不同的type之间评分也会造成干扰。
④、索引元数据本身是放在主节点中维护的,CP 设计。意味着涉及到大量字段变更及元数据变更的操作,都会导致该 Index 被堵塞或假死。我们应该对这样的 Index 做隔离,避免影响到其他 Index 正常的增删改查。甚至当涉及到字段变更十分频繁且无法预定义 schema 的场景时,是否要使用 ES 都应该慎思熟虑了!
(7)shard
分片。单台机器无法存储大量数据,es可以将一个索引(index)中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
(8)replica
副本。任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(简称shard。建立索引时一次设置,不能修改,默认5个),replica shard(简称repica。随时修改数量,默认1个),默认每个索引10个shard(5个primary shard,5个replica shard),最小的高可用配置,是2台服务器。
ps: 分片: 对比数据 库就是分表,一个表存储太大了,分开存储
副本: 对比数据库就是从库, 主库宕机了,从库顶,就是备选作用
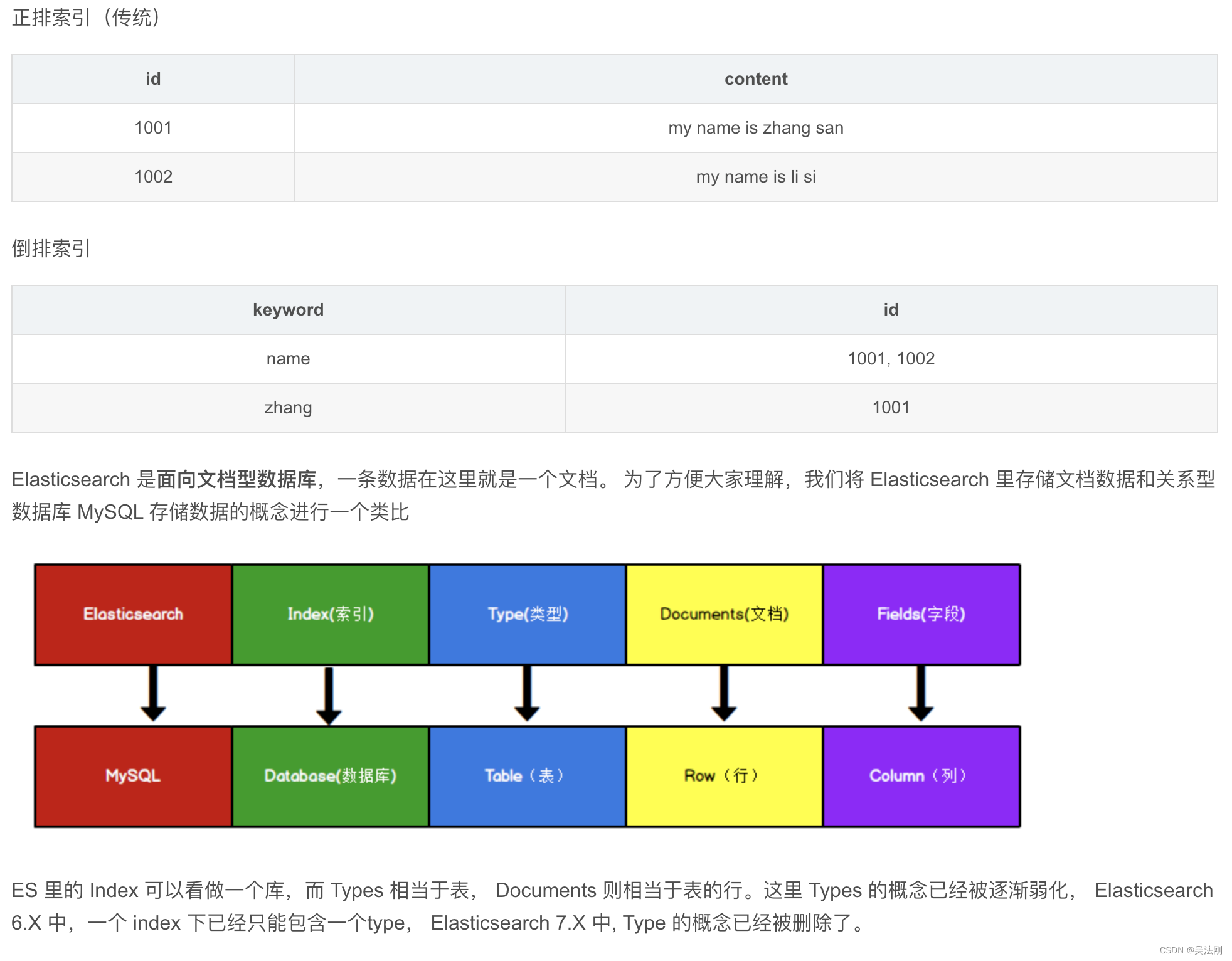
上图的 理解 我是吧: Index 安装 table 理解的,这样理解也更准确 个人感觉









