🚀 作者 :“大数据小禅”
🚀 文章简介 :【Flink实战】玩转Flink里面核心的Source Operator实战
🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬
什么是Flink的并行度
-
Flink的并行度是指在Flink应用程序中并行执行任务的级别或程度。它决定了任务在Flink集群中的并发执行程度,即任务被划分成多少个并行的子任务。
-
在Flink中,可以通过设置并行度来控制任务的并行执行。并行度是根据数据或计算的特性来确定的,可以根据任务的特点和所需的处理能力进行调优。
-
将一个任务的并行度设置为N意味着将该任务分成N个并行的子任务,这些子任务可以在Flink集群的不同节点上同时执行。Flink会根据配置的并行度自动对任务进行数据切分和任务调度,以实现高效的并行处理。
-
选择合适的并行度需要在平衡性、吞吐量和可伸缩性之间权衡。较高的并行度可以提高任务的处理能力和吞吐量,但也会增加系统的资源需求和管理成本。较低的并行度可能导致资源浪费和性能瓶颈。
-
在设计Flink应用程序时,可以根据任务之间的依赖关系、数据流量、数据分布以及可用的资源来选择合适的并行度。可以通过调整并行度来优化任务的性能,平衡任务的负载,提高整体的处理能力。-
Flink自定义的Source 数据源案例-并行度调整结合WebUI
- 开启webui
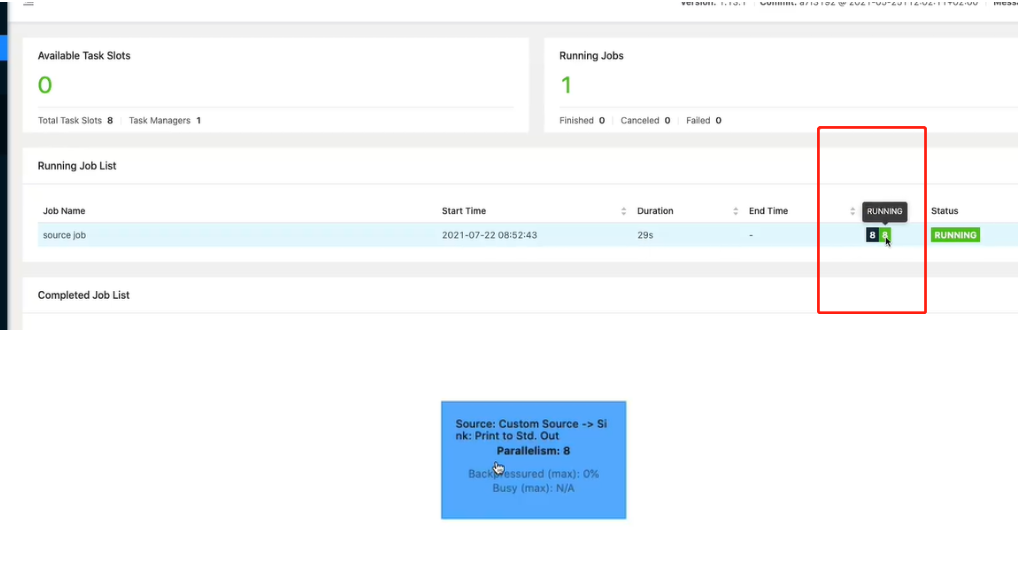
取消掉默认并行度为1,因为默认的并行度是8,也就是8个线程 默认的并行度就是系统的核数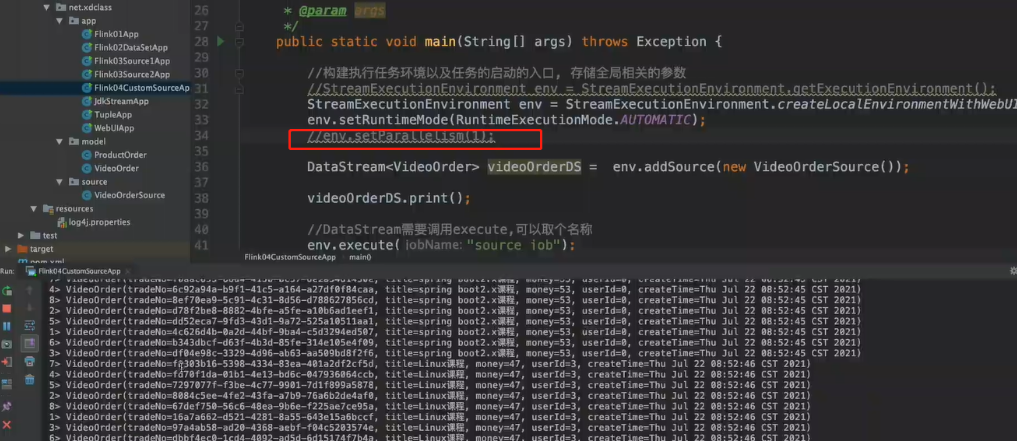
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
- 设置不同的并行度
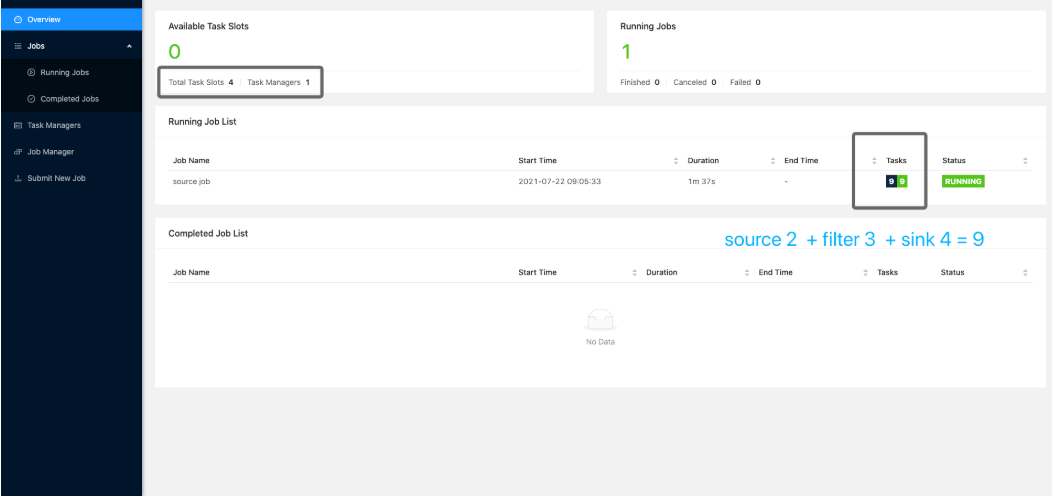
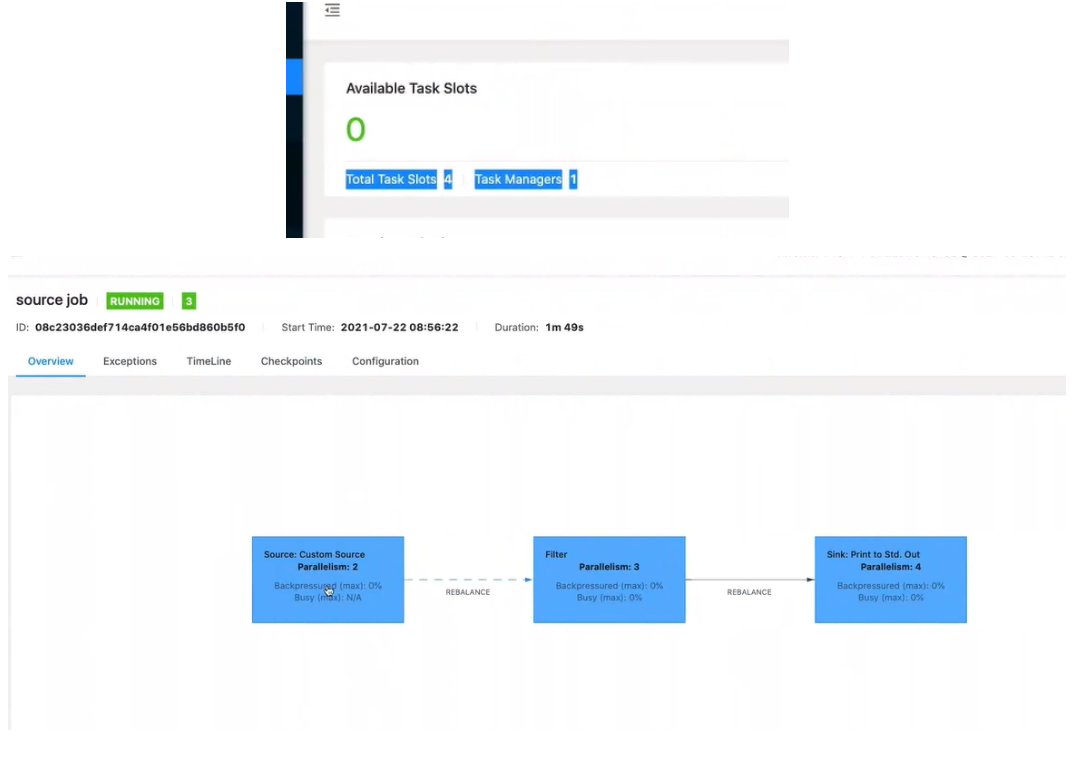
Solt的数量就是设置的最大并行度的数量
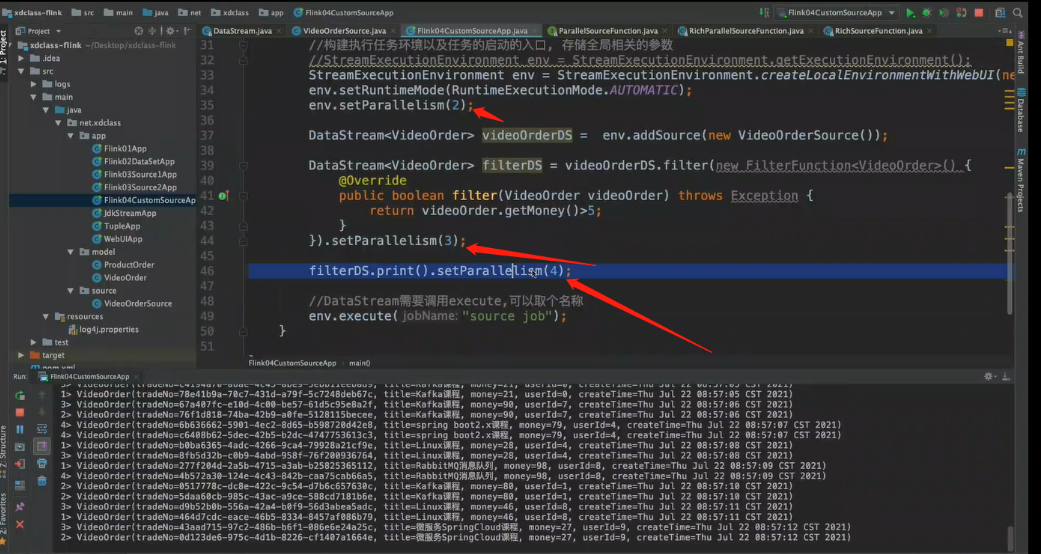
public static void main(String[] args) throws Exception {
//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数
//StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
env.setParallelism(2);
DataStream<VideoOrder> videoOrderDS = env.addSource(new VideoOrderSource());
DataStream<VideoOrder> filterDS = videoOrderDS.filter(new FilterFunction<VideoOrder>() {
@Override
public boolean filter(VideoOrder videoOrder) throws Exception {
return videoOrder.getMoney()>5;
}
}).setParallelism(3);
filterDS.print().setParallelism(4);
//DataStream需要调用execute,可以取个名称
env.execute("source job");
}
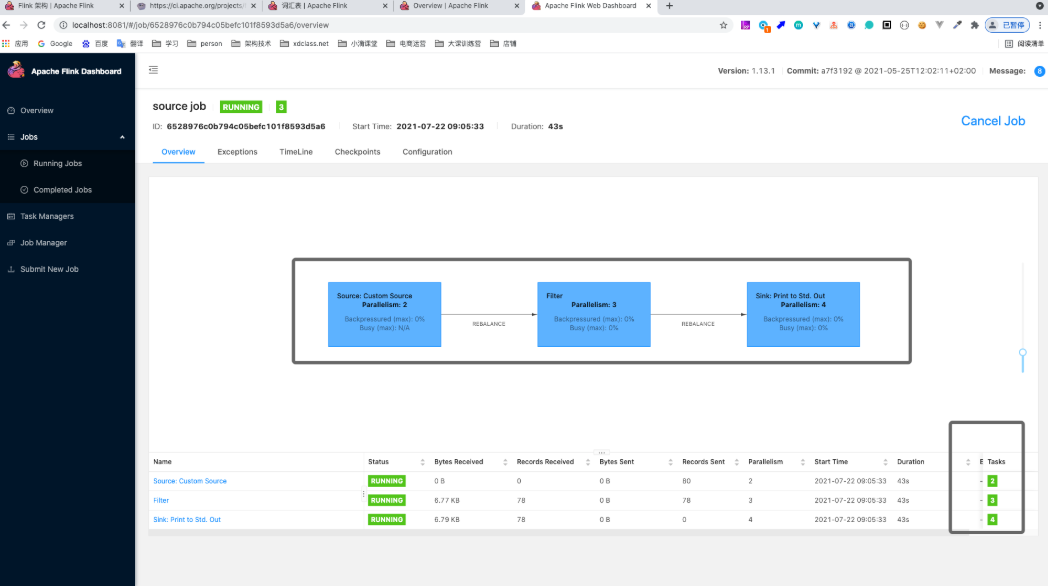
数据流中最大的并行度,就是算子链中最大算子的数量,比如source 2个并行度,filter 4个,sink 4个,最大就是4