卷友们好,我是rumor。
大模型是一个实验工程,涉及数据清洗、底层框架、算法策略等多个工序,每个环节都有很多坑,因此知道如何避坑和技术选型非常重要,可以节省很多算力和时间,说白了就是一摞摞毛爷爷。

近期百川智能发布了Baichuan2的7B和13B版本,可能不少卷友被刷屏惯了没有仔细看,他们在放出模型的同时也给了一份技术报告,里面干货满满,因此我自来水一波,带大家一起看看百川积累的KnowHow。同时也有一些我没完全懂的地方,希望抛砖引玉,可以一起在评论区讨论。
Pre-train
数据
数据多样性
从不同的来源获取数据,最好建立一个类目体系,可以提升对整体数据分布的把控,方便后续增减。
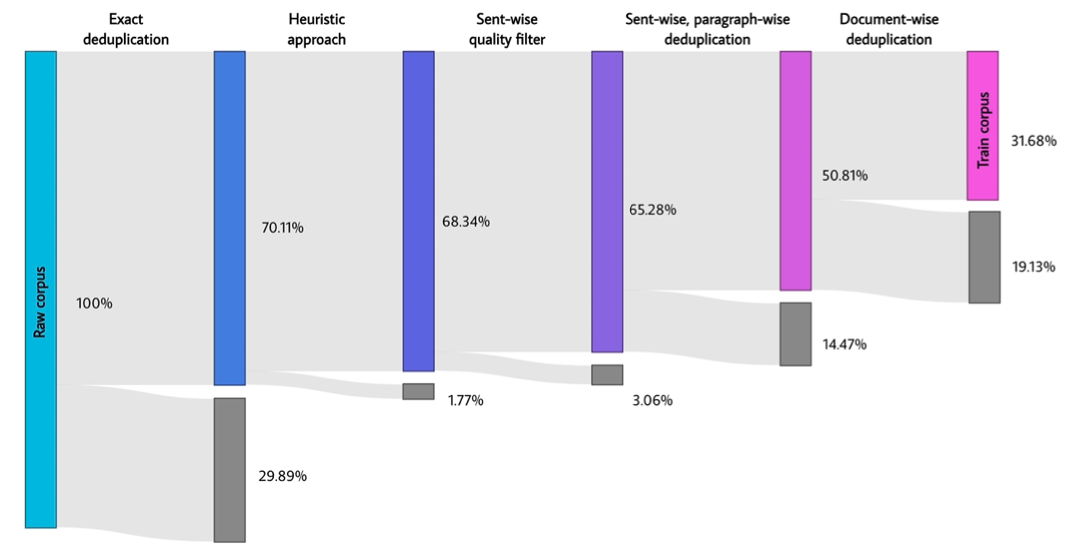
进行聚类和去重,可以通过LSH局部敏感或者稠密向量作为聚类特征,LSH更快一些,但向量可以更好地编码语义。但这里有个问题是需要卡阈值,去重过猛会影响多样性降低泛化能力。因此百川选择的做法是去除一部分,并对剩余的样本打分,作为预训练时采样的权重。
整体去重的流程如下(这里我没太懂的是为何把Document去重放在最后一步,如果放在前面的环节应该可以显著减少句子和段落的数据量):
数据质量
采用句子级别的分类器进行过滤,这个是业内常用做法了,但具体用什么数据训练,用什么标准标注没有细说。
对于内容安全,用规则和模型洗掉有害内容,还额外找了一些正向价值观的数据源,提升采样概率。
模型结构
Tokenizer
Tokenizer的难点是平衡压缩比和词表尺寸,比如频繁出现的几个中文是可以用1个token表示的,这样inference时就会很快,但合并的话这几个中文字单独的embedding训练可能就不充分,跟其他字组合时语义表示会不够好。
因此百川使用BPE,选择了比较折中的12万大小,同时披露了以下细节:
对原始数据不做任何归一化
把数字完全拆开,可以更好理解数值数据
为了代码数据,专门增加空格token
覆盖率在0.9999,只有少量fall back(一种避免OOV的方法,在碰到unknown中文时会变成utf8的byte token)
位置编码
由于有外推的需求,最近位置编码有很多新的工作,比较火的当属RoPE和ALiBi,这里百川都用了,因为他们实验发现位置编码并没有显著影响模型表现,同时进行了速度优化:
RoPE + Flash Attention
ALiBi + xFormers
激活函数
采用了表现更好的SwiGLU,由于SwiGLU有三个矩阵,引入了更多参数,因此百川缩小了FFN层的尺寸(4->8/3再处理成128的倍数)。
Normalisations
对Transformer的输入采用LayerNorm,对warm-up更鲁棒
采用了RMSNorm的实现,指计算输入特征的方差,提升计算效率
混合精度
采用BF16,因为其具有更大的范围,可以让训练更稳定,但对于位置编码、优化器等,采用全精度。
提升稳定性
NormHead:对输出的表示进行归一化。首先低频token的模会在训练中变小,进行归一化后可以提升稳定性。另外百川通过对输出表示聚类,发现cosine距离可以将相似语义的聚到一起而L2距离不行,归一化可以消除最终计算logits时点乘中L2的影响。从实验结果可以明显发现loss收敛更好更稳定。
Max-z loss:在训练过程中,百川发现模型的logits都很大,这样就会对解码时的超参数鲁棒性较低,因此增加max-z loss拉低logits的值。
注:对于预训练的优化解读跳过了Infra的部分,不是那么懂。。
Alignment
SFT
数据质量:采用抽检的方式进行质量把控,抽一批数据检查,不合格全部退回。
数据数量:100k(目前开源SFT数据还是挺多的,不知道百川出于什么考虑
Reward Model
Prompt多样性:构造了一个200+细分类目的数据体系,尽可能覆盖用户需求,同时提升每类prompt多样性,从而提升泛化能力
Response多样性:用不同尺寸和阶段的百川模型生成答案,不使用其他开源模型(经验证无法提升RM准确率)
PPO
预先对critic模型进行了warmup
为提升RL稳定性,进行梯度裁剪
安全
由于模型开源,百川在内容安全上非常细致,包括:
聘请10位专业审核人员构建了100+安全类目
用50人的标注团队构建了200K攻击指令
对于攻击指令,生产多样性很大的回答
总结
Baichuan2的效果比第一版提升了很多,在推理任务上效果翻倍,是目前开源模型中过了最多中文语料的模型 。欢迎用过的朋友在评论区反馈效果~
。欢迎用过的朋友在评论区反馈效果~

我是朋克又极客的AI算法小姐姐rumor
北航本硕,NLP算法工程师,谷歌开发者专家
欢迎关注我,带你学习带你肝
一起在人工智能时代旋转跳跃眨巴眼
「感恩开源,白嫖开心」









