
本文收录在专栏:#云计算入门与实践 - 华为云 专栏中,本系列博文还在更新中
相关华为云云耀云服务器L实例评测文章列表如下:
- 华为云云耀云服务器L实例评测 | 从零开始:云耀云服务器L实例的全面使用解析指南
- 华为云云耀云服务器L实例评测|轻量级应用服务器对决:基于 Geekbench 深度测评华为云云耀云服务器L实例的处理器性能
- 华为云云耀云服务器L实例评测|轻量级应用服务器对决:基于 STREAM 深度测评华为云云耀云服务器L实例的内存性能
华为云云耀云服务器L实例评测|轻量级应用服务器对决:基于 fio 深度测评华为云云耀云服务器L实例的磁盘性能 - [ 云计算 华为云 ] 解决办法:如何更换华为云云耀云服务器L实例的镜像
文章目录
一、评测背景
本文是继上篇:《华为云云耀云服务器L实例评测|轻量级应用服务器对决:基于 Geekbench 深度测评华为云云耀云服务器L实例》后,继续探讨华为云的创新产品【华为云云耀云服务器L实例】,为读者提供全面的评测信息,本篇文章重点是测试其【华为云云耀云服务器L实例】的内存性能。我们仍然选取了对比机器,也就是友商的轻量级应用服务器 lighthouse,经过使用 STREAM 的详细测试,我们将对华为云的最新云耀云服务器L实例的CPU处理器性能进行严格测试和分析,以帮助你更加清晰的认识华为云的最新云耀云服务器L实例,以及帮助你更好的在众多繁杂的服务器中进行选择判断。
二、评测声明
本人任何测试其云计算或者其他商品,都站在如下声明立场
尽管本文是在参与华为云云耀云服务器L实例评测活动的背景下编写的,但是本博主是站在一个中立的角度来进行评测,不存在因为是活动文上来就无脑吹,这有背征文的目的以及我的个人初衷。
三、被评测服务器参数及准备
3.1 被评测服务器基本参数
华为云云耀云服务器L实例现阶段提供2核2G、2核4G、2核8G的 3 种 CPU 和内存规格,不同 CPU 和内存规格与系统盘、峰值带宽和流量包组合共有 6 种实例规格。这里选择的友商测试机为轻量应用服务器 lighthouse,该友商的轻量型应用服务器与华为云云耀云服务器L实例类似,都提供不同的应用场景,不通过的镜像支持以及规格,可以说是相互的对标产品。
本测试使用的华为云云耀云服务器L实例与友商的轻量应用服务器 lighthouse均位于广州区域,且配置均为2核2G,配置参数表格为:
| 规格配置 | 华为云云耀云服务器L实例 | 友商的轻量应用服务器 lighthouse |
|---|---|---|
| 核心数 | 2核 | 2核 |
| 内存 | 2G | 2G |
| 操作系统 | CentOS 7.6 | CentOS 7.6 |
| 区域 | 广州 | 广州 |
3.2 测试机采购
3.2.1 华为云云耀云服务器L实例
因为本文重点是对华为云云耀云服务器L实例进行处理器层面的评测,由于篇幅有限,此处步骤略过,对于如何采购华为云云耀云服务器L实例具体步骤细节,参考我之前的博文中的第三节即可:华为云云耀云服务器L实例评测 | 从零开始:云耀云服务器L实例的全面使用解析指南
购买后服务器规格如下:
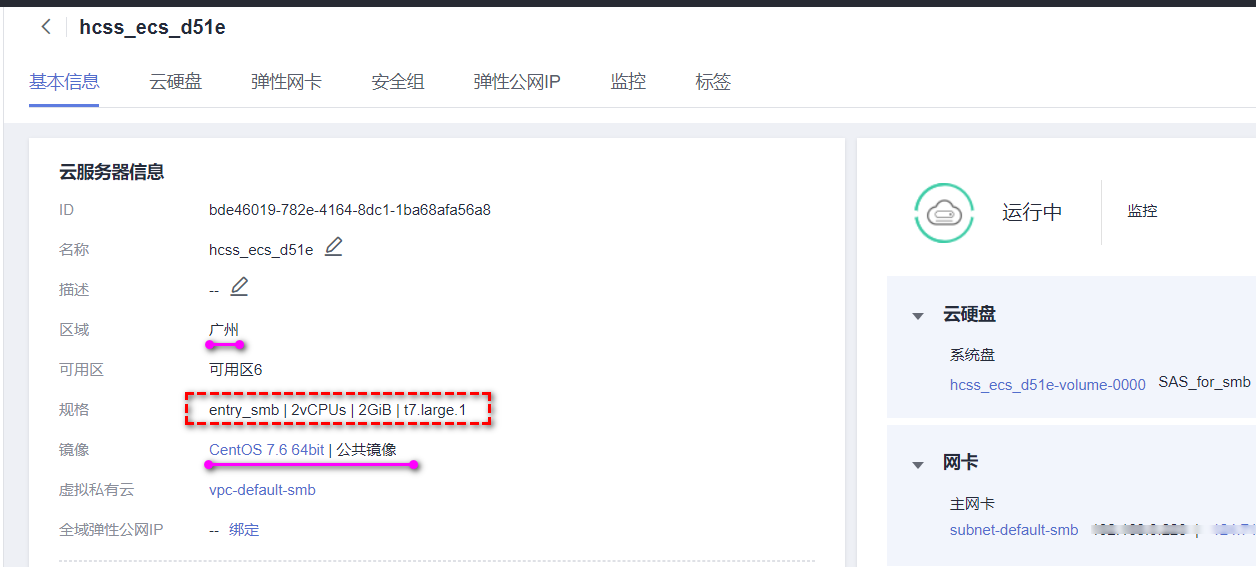
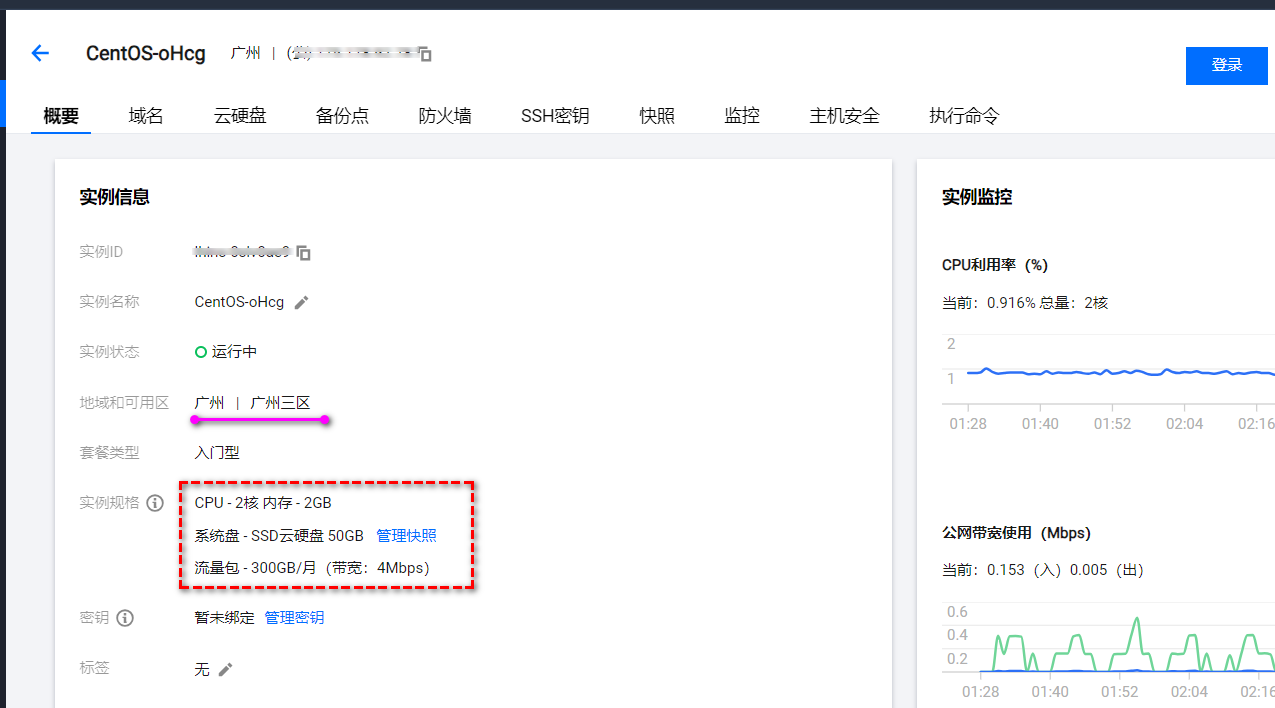
3.2.2 友商的轻量应用服务器 lighthouse
对比测试机采购步骤略过,因为不是今天的主角,直接在下面贴出购买后的截图
四、使用 Stream 测试内存性能
STREAM 软件是一款内存带宽性能测试的关键工具,也是衡量服务器内存性能的通用标杆。随着处理器核心数量的增加,内存带宽对于提升整个系统性能变得愈发关键。如果系统无法高效地将内存中的数据传送到处理器,那么多个处理核心可能会因等待数据而处于闲置状态。这种闲置时间不仅会减少系统效率,还会抵消多核心和高主频带来的性能优势。
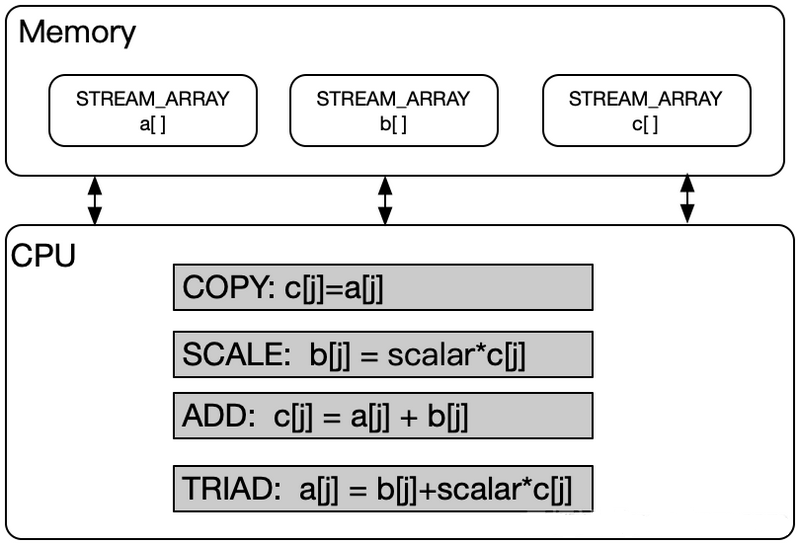
STREAM 软件在内存带宽性能测试中表现出色,具备出色的空间局部性,并且与缓冲区TLB(Translation Lookaside Buffer)以及缓存的兼容性极佳。该软件支持四种运算方式,包括复制(Copy)、尺度变换(Scale)、矢量求和(Add)以及复合矢量求和(Triad),从而全面评估内存带宽性能。这使得 STREAM 成为一个不可或缺的工具,用于深入了解系统内存性能,优化系统配置,提高整体性能表现。
下面是我们使用 STREAM 测试内存性能的过程:
为了演示如何使用 STREAM 我们这里直接使用华为云云耀云服务器L实例进行演示
4.1 Stream 安装
官方源码地址:http://www.cs.virginia.edu/stream/FTP/Code/stream.c
[root@hcss-ecs-d51e stream]# wget http://www.cs.virginia.edu/stream/FTP/Code/stream.c
[root@hcss-ecs-d51e stream]# yum install gcc -y
# stream 版本 5.10 使用
[root@hcss-ecs-d51e stream]# gcc -O3 -fopenmp -DSTREAM_ARRAY_SIZE=10000000 -DNTIMES=10 stream.c -o stream
# stream 版本 5.9 使用
[root@brinnatt ~]# gcc -O3 -fopenmp -DN=2000000 -DNTIMES=10 stream.c -o stream
[root@hcss-ecs-d51e stream]# ls
stream stream.c
[root@hcss-ecs-d51e stream]#
含义、方法及相关解释:
- -O3:指定最高编译优化级别,即 3
- -fopenmp:启用 OpenMP,适应多处理器环境,更能得到内存带宽实际最大值。开启后,程序默认运行线程为 CPU 线程数
- -DSTREAM_ARRAY_SIZE:指定测试数组
a[]、b[]、c[]的大小(Array size)。该值对测试结果影响较大(5.10 版本,参数名为-DSTREAM_ARRAY_SIZE,默认值 10000000;若 stream.c 为 5.9 版本参数名为-DN,默认值 2000000)。- 注意:必须设置测试数组大小远大于 CPU 最高级缓存(一般为 L3 Cache)的大小,否则就是测试 CPU 缓存的吞吐性能,而非内存吞吐性能。
- -DNTIMES=10:执行的次数,并从这些结果中选最优值。
- stream.c:待编译的源码文件
- stream:输出的可执行文件名
- 其他参数:
- -mtune=native -march=native:针对 CPU 指令的优化,-mtune=native会在已选指令集约束下生成本地机器优化代码;使用-march=native将启用本地机器支持的所有指令子集。更多编译器对 CPU 的优化参考(点击这里)
- -mcmodel=medium :当单个 Memory Array Size 大于 2GB 时需要设置此参数
- -DOFFSET=4096 :数组的偏移,一般可以不定义
推荐计算公式:{最高级缓存X MB}×1024×1024×4.1×CPU路数/8,结果取整数。
解释:由于 stream.c 源码推荐设置至少 4 倍最高级缓存,且 STREAM_ARRAY_SIZE 为 double 类型 = 8 Byte。所以公式为:最高级缓存(单位:Byte)×4.1倍×CPU路数/8。
例如:测试机器是双路 CPU,最高级缓存 32MB,则计算值为 32×1024×1024×4.1×2/8≈34393292。
4.2 在华为云云耀云服务器L实例运行 Stream 测试
使用命令指定运行线程为 n,即使用如下命令运行测试
export OMP_NUM_THREADS=4
./stream
在编译输出的可执行文件(stream)所在目录下运行:
[root@hcss-ecs-d51e stream]#
[root@hcss-ecs-d51e stream]#
[root@hcss-ecs-d51e stream]# export OMP_NUM_THREADS=4
[root@hcss-ecs-d51e stream]# ./stream
-------------------------------------------------------------
STREAM version $Revision: 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array size = 10000000 (elements), Offset = 0 (elements)
Memory per array = 76.3 MiB (= 0.1 GiB).
Total memory required = 228.9 MiB (= 0.2 GiB).
Each kernel will be executed 10 times.
The *best* time for each kernel (excluding the first iteration)
will be used to compute the reported bandwidth.
-------------------------------------------------------------
Number of Threads requested = 4
Number of Threads counted = 4
-------------------------------------------------------------
Your clock granularity/precision appears to be 1 microseconds.
Each test below will take on the order of 4504 microseconds.
(= 4504 clock ticks)
Increase the size of the arrays if this shows that
you are not getting at least 20 clock ticks per test.
-------------------------------------------------------------
WARNING -- The above is only a rough guideline.
For best results, please be sure you know the
precision of your system timer.
-------------------------------------------------------------
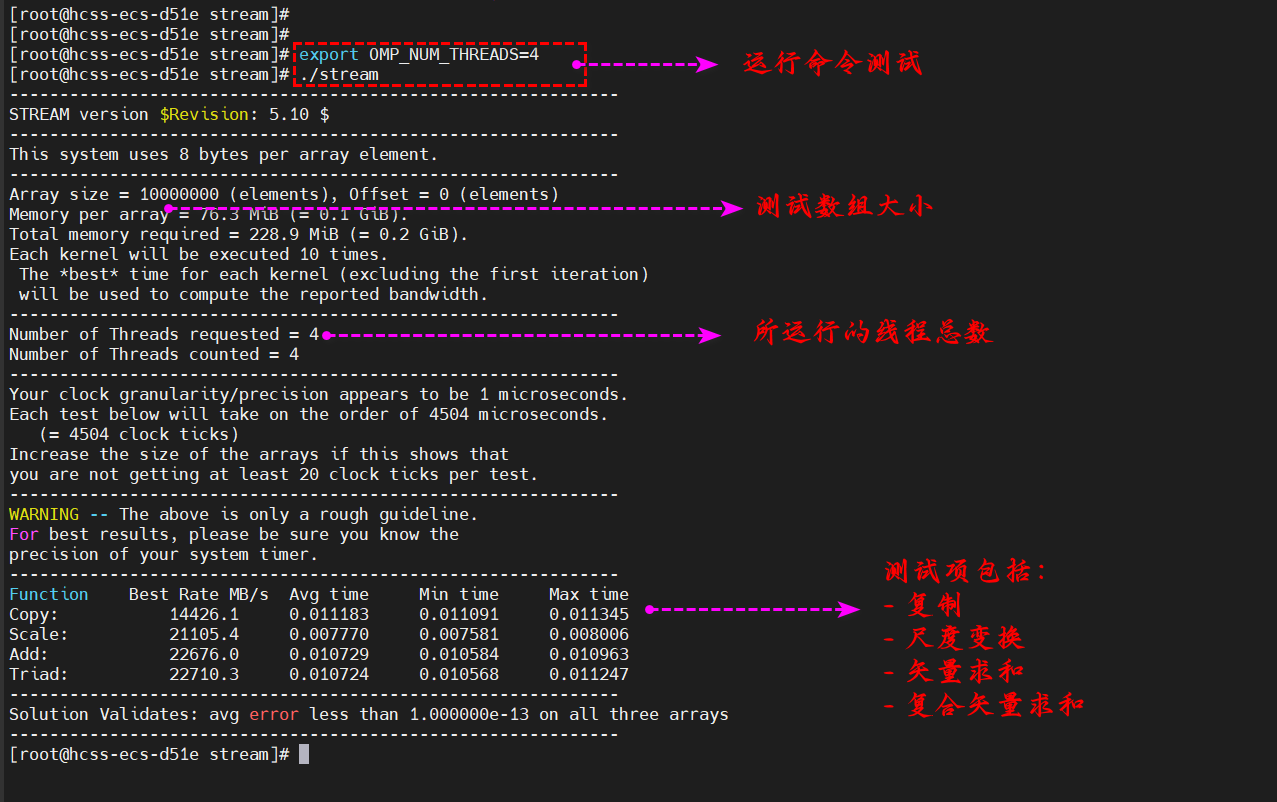
Function Best Rate MB/s Avg time Min time Max time
Copy: 14426.1 0.011183 0.011091 0.011345
Scale: 21105.4 0.007770 0.007581 0.008006
Add: 22676.0 0.010729 0.010584 0.010963
Triad: 22710.3 0.010724 0.010568 0.011247
-------------------------------------------------------------
Solution Validates: avg error less than 1.000000e-13 on all three arrays
-------------------------------------------------------------
最终测试结果图,如下:
4.3 在友商的轻量应用服务器 lighthouse 运行 Stream 测试
在上述 4.2 节中,华为云云耀云服务器L实例上运行 Stream 测试步骤里已经详细介绍如何使用 Stream 以及相关的细节介绍,这里节约篇幅省略中间过程,直接给出在友商的轻量应用服务器 lighthouse 运行 Stream 的结果:
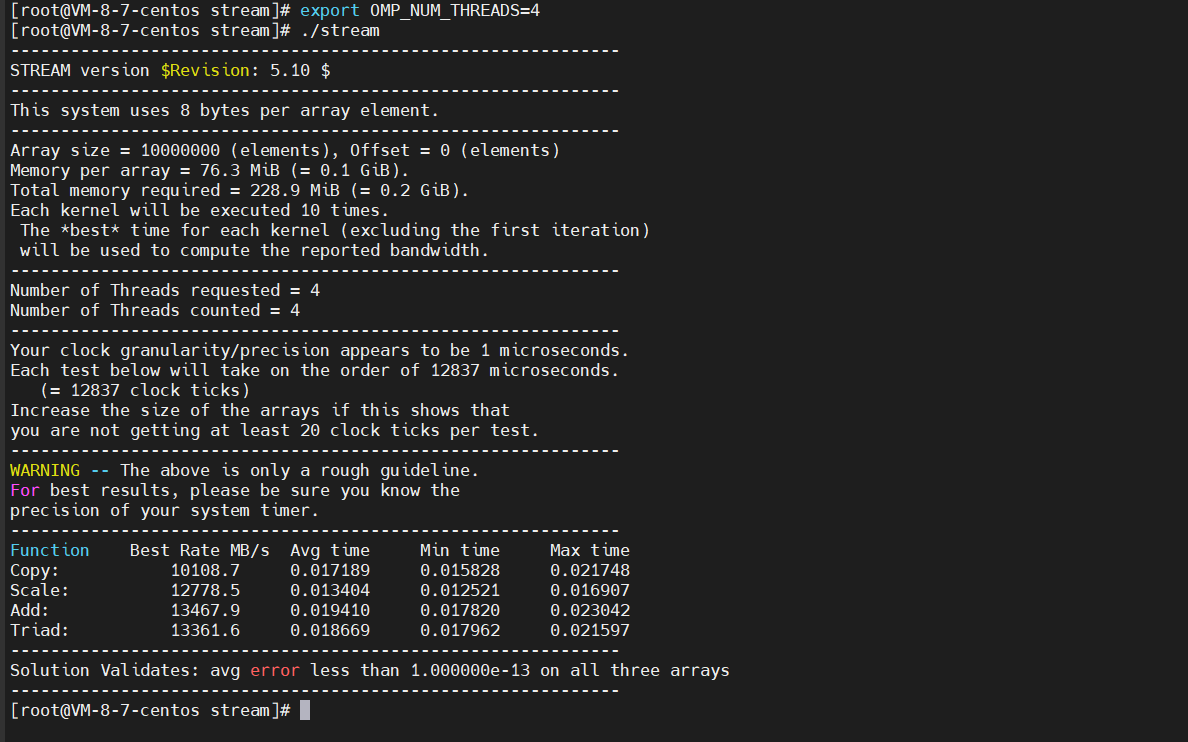
五、最终测试比对结果(本文重点)
这里和之前使用 Geekbench 跑分的时候一样,废话不多,直接上 STREAM 的最终结果:
| STREAM version $Revision: 5.10 | 数组大小 | 复制(Copy)MB/S | 尺度变换(Scale)MB/S | 矢量求和(Add)MB/S | 复合矢量求和(Triad)MB/S |
|---|---|---|---|---|---|
| 华为云云耀云服务器L实例 | 10000000 | 14426.1 | 21105.4 | 22676.0 | 22710.3 |
| 友商的轻量应用服务器 lighthouse | 10000000 | 10108.7 | 12778.5 | 13467.9 | 13361.6 |
注意:上述表格数据建议多次跑分取平均值后在进行统计
从上表中可以看出,同样是测试数组大小为 10000000 个的情况下,华为云云耀云服务器L实例的各项指标完胜友商的轻量应用服务器 lighthouse,其中复制的速率比友商的机器略高,几乎差不多,但是在尺度变换、矢量求和与复合矢量求和的速率几乎是友商机器的 2 倍左右。
在我们上篇文章:《华为云云耀云服务器L实例评测|轻量级应用服务器对决:基于 Geekbench 深度测评华为云云耀云服务器L实例》中,对华为云云耀云服务器L实例进行了处理器 CPU 的测试,当时的结果也是华为云云耀云服务器L实例的性能要优于友商的同类型竞品,而这次的内存测试上,同样的完胜,不得不说,华为的这个新产品,抛开价格以外的因素,性能上几乎是优于同类型竞品。
六、文末总结
在本文中,我们深入研究了华为云云耀云服务器L实例和友商的轻量应用服务器 lighthouse,特别关注了它们的内存性能。从评测背景开始,我们明确了本文的研究目的。接着,我们详细介绍了被评测服务器的基本参数和测试机采购过程,包括华为云云耀云服务器L实例和友商的轻量应用服务器 lighthouse。
在本文的重点部分,我们使用 STREAM 工具来测试这两款服务器的内存性能。我们介绍了 STREAM 工具的安装过程,并分别在两种服务器上运行了 STREAM 测试,以深入评估它们的内存带宽性能。
过本文的评测和比对,可以帮助读者更好地了解这两款服务器的内存性能表现,为他们做出明智的决策提供有价值的信息。无论是在企业环境还是个人应用中,优化内存性能都是提高整体系统性能的关键一步。
[ 本文作者 ] bluetata
[ 原文链接 ] https://bluetata.blog.csdn.net/article/details/132920474
[ 最后更新 ] 09/18/2023 1:50
[ 版权声明 ] 如果您在非 CSDN 网站内看到这一行,
说明网络爬虫可能在本人还没有完整发布的时候就抓走了我的文章,
可能导致内容不完整,请去上述的原文链接查看原文。






