ES简介
Elasticsearch(通常简称为ES)是一个开源的分布式搜索和分析引擎,旨在处理各种类型的数据,包括结构化、半结构化和非结构化数据。它最初是为全文搜索而设计的,但随着时间的推移,它已经演变成一个功能强大的数据分析工具,用于实时搜索、日志和事件数据分析、业务智能等各种用途。以下是关于Elasticsearch的一些关键特点和概念:
-
分布式性能:Elasticsearch是一个分布式系统,它可以轻松扩展到多个节点,实现水平扩展。这意味着它能够处理大规模的数据,并且在性能和容量方面具有弹性。
-
实时搜索:Elasticsearch提供了实时搜索功能,可以在数据变化时立即更新搜索结果。这对于需要快速获取最新数据的应用非常有用。
-
多数据类型支持:Elasticsearch可以处理各种类型的数据,包括文本、数字、地理空间数据等。它不仅支持全文搜索,还支持结构化查询和分析。
-
强大的查询语言:Elasticsearch使用自定义的查询语言(基于JSON),允许您执行各种查询,包括全文搜索、过滤、聚合和排序等。它还支持模糊查询、正则表达式和多字段搜索等功能。
-
分布式文档存储:Elasticsearch使用倒排索引来存储文档,这使得它在搜索时非常高效。文档可以以JSON格式存储,并且可以根据需要进行动态映射。
-
数据聚合:Elasticsearch具有强大的聚合功能,允许您在大数据集上执行各种分析操作,如汇总、平均、最大值、最小值等。
-
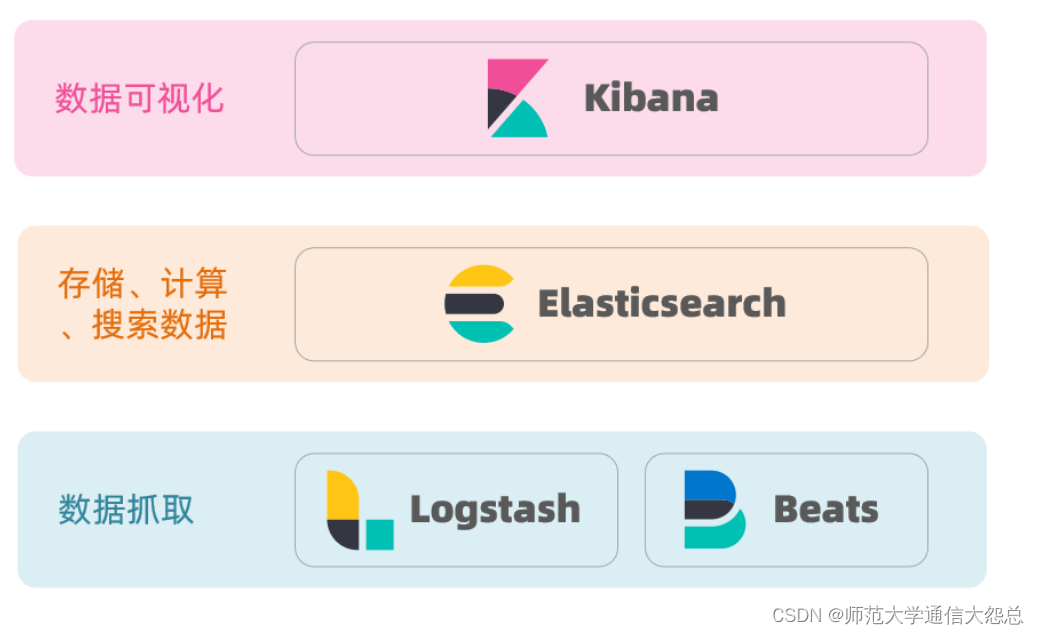
实时数据分析:Elasticsearch与Logstash和Kibana(通常一起称为ELK Stack)集成得很好,使其成为实时日志和事件数据分析的理想选择。
-
开源和社区支持:Elasticsearch是开源项目,拥有庞大的开发者社区,提供了丰富的文档和插件生态系统,以满足各种需求。
Elasticsearch的用途非常广泛,包括全文搜索引擎、日志和指标分析、业务智能、安全信息和事件管理(SIEM)、商品推荐、地理信息系统(GIS)等等。它的弹性、性能和丰富的功能使其成为许多现代应用程序架构的重要组成部分。
代码示例:
索引和文档操作:在Elasticsearch中,数据存储在索引中,索引由多个文档组成。以下是如何创建、更新和删除文档的示例:
创建一个索引以及添加文档到索引:
PUT /my_index
// 创建文档
POST /my_index/my_type/1
{
"name": "John Doe",
"age": 30,
"city": "New York"
}
// 更新文档
POST /my_index/my_type/1/_update
{
"doc": {
"age": 31
}
}
// 删除文档
DELETE /my_index/my_type/1
全文搜索:Elasticsearch以其强大的全文搜索功能而闻名。
// 执行全文搜索
GET /my_index/my_type/_search
{
"query": {
"match": {
"name": "John"
}
}
}
聚合:Elasticsearch允许执行各种聚合操作,如统计、平均值和分组等。
// 计算年龄的平均值
GET /my_index/my_type/_search
{
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
}
地理空间搜索:Elasticsearch支持地理空间数据,可以执行地理位置的搜索和聚合。
// 查找附近的地点
GET /my_geo_index/_search
{
"query": {
"geo_distance": {
"distance": "10km",
"location": {
"lat": 40.0,
"lon": -74.0
}
}
}
}
Logstash集成:Logstash是一个用于数据收集、转换和发送到Elasticsearch的工具。
input {
file {
path => "/var/log/myapp.log"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "my_logs"
}
}
Kibana可视化:Kibana是Elasticsearch的可视化工具,用于创建仪表板和图表。
JAVA示例:
当使用Elasticsearch进行编程时,通常使用Elasticsearch的客户端库,如Elasticsearch RestHighLevelClient(用于Java)或其他语言的类似库。以下是Java中使用Elasticsearch RestHighLevelClient进行一些常见操作的简化代码示例:
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.common.xcontent.XContentType;
// 创建RestHighLevelClient
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http"))
);
try {
// 索引一个文档
IndexRequest request = new IndexRequest("my_index");
String jsonString = "{\"name\":\"Alice\",\"age\":28}";
request.source(jsonString, XContentType.JSON);
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
// 获取文档
GetRequest getRequest = new GetRequest("my_index", "_doc", "1");
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
if (getResponse.isExists()) {
String sourceAsString = getResponse.getSourceAsString();
System.out.println("文档内容:" + sourceAsString);
} else {
System.out.println("文档不存在。");
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
// 关闭客户端
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
这个示例演示了如何使用Java的Elasticsearch RestHighLevelClient库来索引文档、获取文档,并在完成操作后关闭客户端。请确保将适当的依赖项添加到项目中,以便使用Elasticsearch客户端库。
对于Elasticsearch的更高级用法和配置,可以参考官方文档和相关教程。不同编程语言的Elasticsearch客户端库也会有一些语法差异,所以具体的示例代码可能会有所不同。









