文章目录
在Docker中使用MindSpore GPU版本
参考官方文档:安装指南
获取安装命令
如图所示
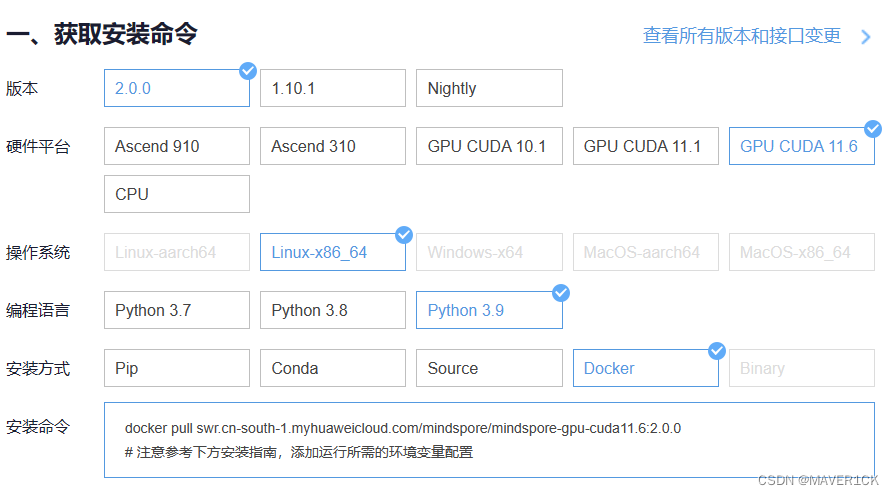
命令为
docker pull swr.cn-south-1.myhuaweicloud.com/mindspore/mindspore-gpu-cuda11.6:2.0.0
安装
这里选择已经预安装MindSpore x.y.z GPU版本的生产环境。(CUDA10.1或CUDA11.1或CUDA11.6后端)
安装nvidia-container-toolkit
依次执行:
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
获取MindSpore镜像
docker pull swr.cn-south-1.myhuaweicloud.com/mindspore/mindspore-gpu-{cuda_version}:{version}
将 {version} 替换为对应MindSpore版本,如2.0.0。
将 {cuda_version} 替换为对应MindSpore依赖的CUDA版本,包括cuda10.1,cuda11.1和cuda11.6。
例如执行前面获得的命令:
docker pull swr.cn-south-1.myhuaweicloud.com/mindspore/mindspore-gpu-cuda11.6:2.0.0
如果需要获取构建环境或者运行时环境镜像:
docker pull swr.cn-south-1.myhuaweicloud.com/mindspore/mindspore-gpu:{tag}
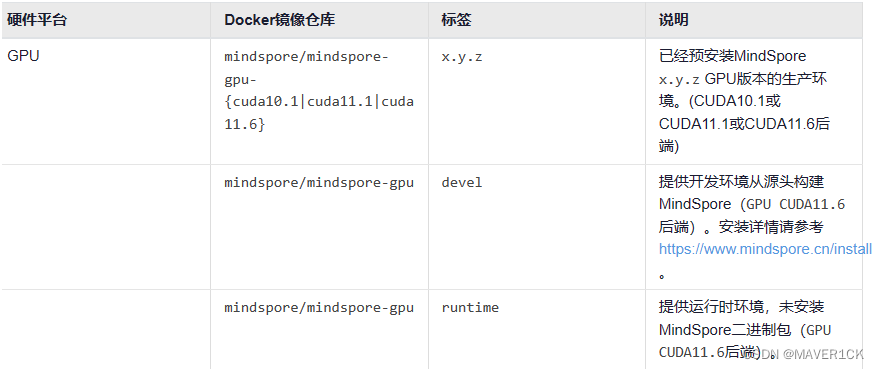
将 {tag} 替换为对应上述表格中的标签,包括devel和runtime。
测试
运行MindSpore镜像
docker run --rm -it -v /dev/shm:/dev/shm --runtime=nvidia swr.cn-south-1.myhuaweicloud.com/mindspore/mindspore-gpu-{cuda_version}:{tag} /bin/bash
其中:
- –rm 表示退出容器后删除容器(可以不加这个参数)
- -v /dev/shm:/dev/shm 将NCCL共享内存段所在目录挂载至容器内部;
- –runtime=nvidia 用于指定容器运行时为nvidia-container-runtime;
- {tag}对应上述表格中的标签。
- {cuda_version} 对应MindSpore依赖的CUDA版本,包括cuda10.1,cuda11.1和cuda11.6。
例如使用前面下载的镜像:
docker run --rm -it -v /dev/shm:/dev/shm --runtime=nvidia swr.cn-south-1.myhuaweicloud.com/mindspore/mindspore-gpu-cuda11.6:2.0.0 /bin/bash
如需使用可视化调试调优工具MindSpore Insight,需设置–network参数为host模式,例如:
docker run --rm -it -v /dev/shm:/dev/shm --network host --runtime=nvidia swr.cn-south-1.myhuaweicloud.com/mindspore/mindspore-gpu-cuda11.6:2.0.0 /bin/bash
运行代码
进入容器后,运行代码并检查输出:
python -c "import mindspore;mindspore.run_check()"
如果输出为:
MindSpore version: 2.0.0
The result of multiplication calculation is correct, MindSpore has been installed on platform [GPU] successfully!
则说明安装成功。
使用VSCode开发
见在Windows 11 中安装和使用 WSL 2:使用VSCode连接容器。
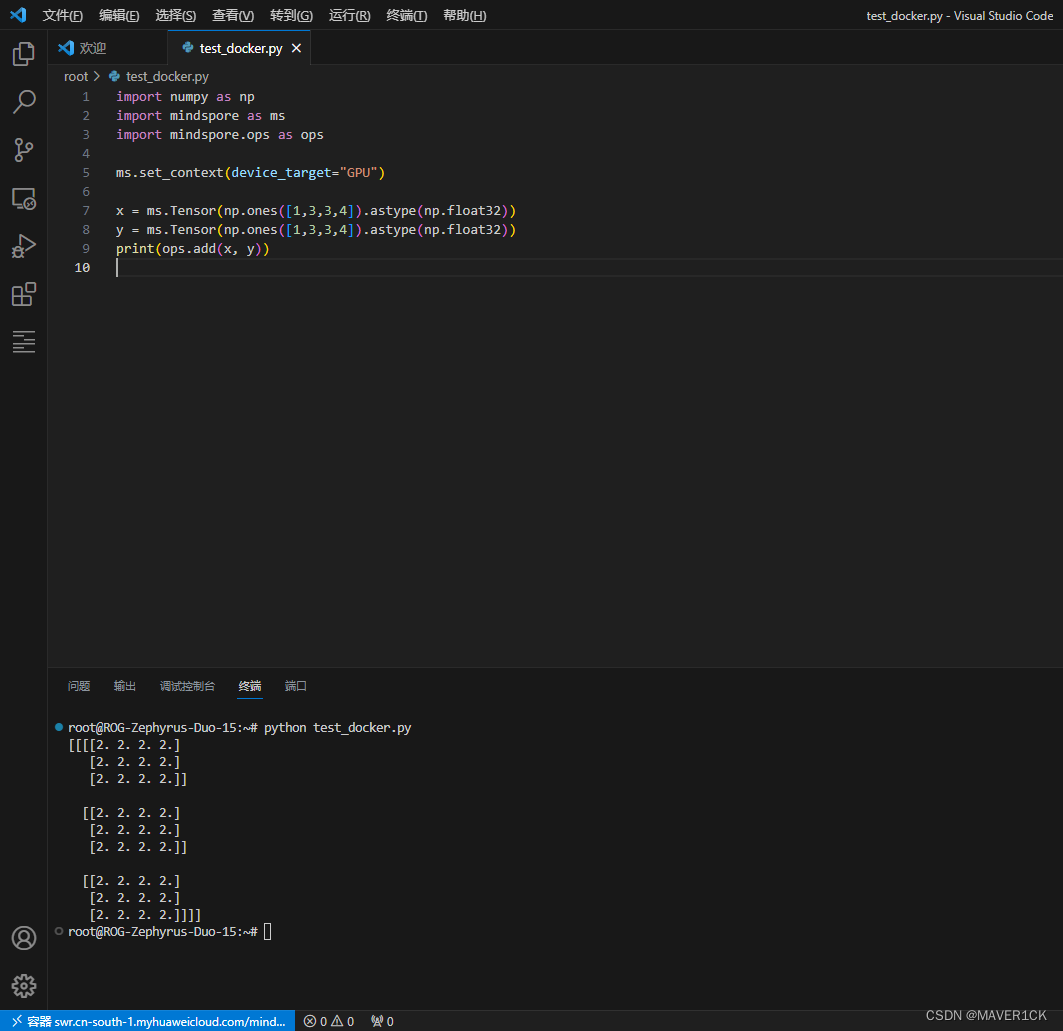
进入容器后,新建 test_docker.py ,添加以下代码:
import numpy as np
import mindspore as ms
import mindspore.ops as ops
ms.set_context(device_target="GPU")
x = ms.Tensor(np.ones([1,3,3,4]).astype(np.float32))
y = ms.Tensor(np.ones([1,3,3,4]).astype(np.float32))
print(ops.add(x, y))
然后打开终端运行:
python test_docker.py
输出结果如下说明环境配置成功:
[[[[2. 2. 2. 2.]
[2. 2. 2. 2.]
[2. 2. 2. 2.]]
[[2. 2. 2. 2.]
[2. 2. 2. 2.]
[2. 2. 2. 2.]]
[[2. 2. 2. 2.]
[2. 2. 2. 2.]
[2. 2. 2. 2.]]]]