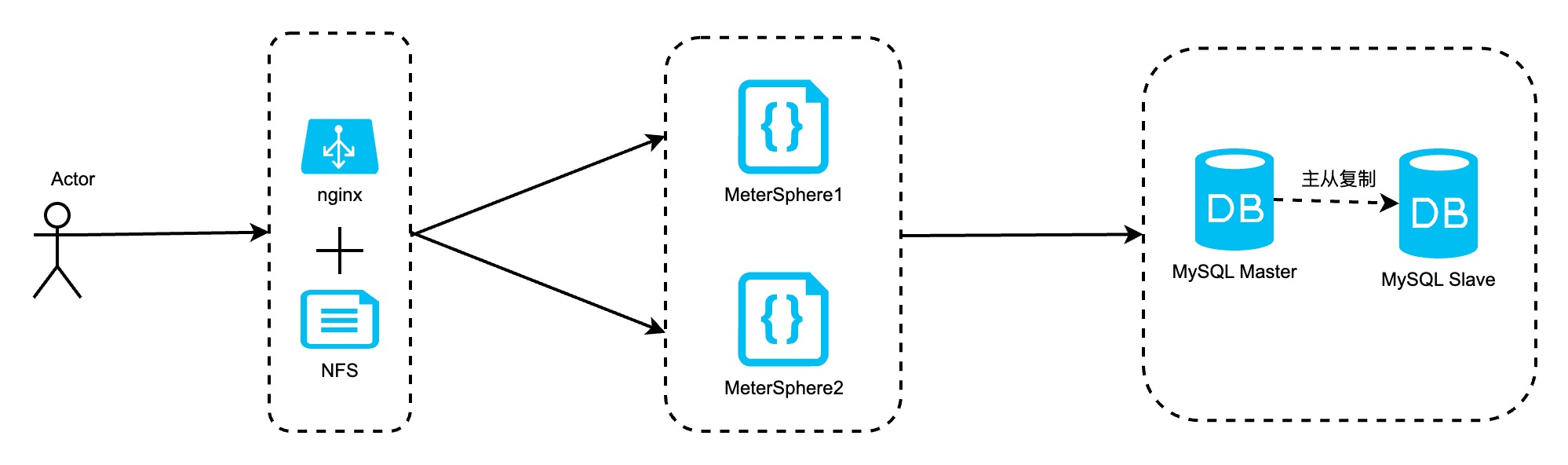
一、MeterSphere高可用部署架构及服务器配置
1.1 服务器信息
| 序号 | 应用名称 | 操作系统要求 | 配置要求 | 描述 |
|---|---|---|---|---|
| 1 | 负载均衡器 | CentOS 7.X /RedHat 7.X | 2C,4G,200GB | 部署Nginx,实现负载路由。 部署NFS服务器。 |
| 2 | MeterSphere应用节点1 | CentOS 7.X /RedHat 7.X | 8C,16GB,200GB | 部署MeterSphere应用 |
| 3 | MeterSphere应用节点2 | CentOS 7.X /RedHat 7.X | 8C,16GB,200GB | 部署MeterSphere应用 |
| 4 | MySQL Master节点 | CentOS 7.X /RedHat 7.X | 8C,16GB,200GB | 部署MySQL Master |
| 5 | MySQL Slave节点 | CentOS 7.X /RedHat 7.X | 8C,16GB,200GB | 部署MySQL Slave |
1.2 部署架构图
二、Mysql8数据库主从搭建
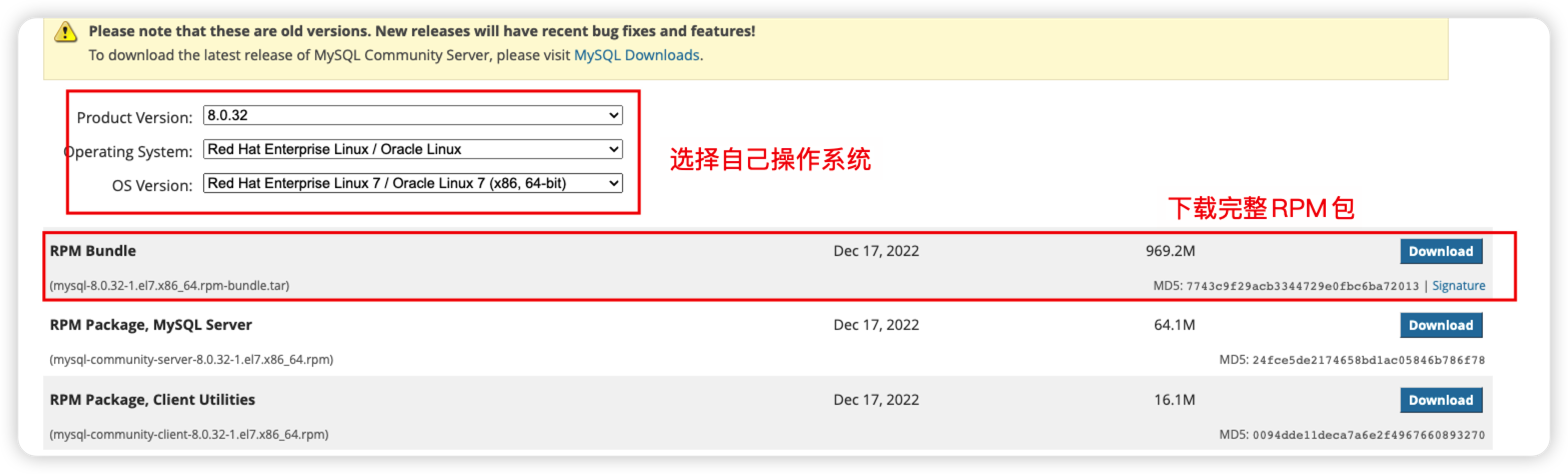
2.1 下载安装包
下载地址:https://downloads.mysql.com/archives/community/
2.2 解压安装
- 下载好之后,上传服务器进行解压。
tar xvf mysql-8.0.32-1.el7.x86_64.rpm-bundle.tar
- 顺序安装rpm
rpm -ivh mysql-community-common-8.0.32-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-plugins-8.0.32-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-8.0.32-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-8.0.32-1.el7.x86_64.rpm
rpm -ivh mysql-community-icu-data-files-8.0.32-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-8.0.32-1.el7.x86_64.rpm
注意:如果在安装 mysql-community-libs-8.0.32-1.el7.x86_64.rpm 的时候出现下面错误,说明已经安装了mariadb相关依赖,需要卸载。可以执行:yum remove mysql-libs ,清除之前的依赖即可。然后重新执行 rpm -ivh mysql-community-libs-8.0.32-1.el7.x86_64.rpm 即可。

- 初始化my.cnf
特别注意: 先配置my.cnf,再启动。 如果已经启动了,没办法初始化大小写的问题了,这个时候可以删除重新初始化,操作如下:(正常配置可以忽略)
如果你不在意数据的话直接删除数据
停止MySQL
systemctl stop mysqld
删除 MySQL的数据(恢复到初始化之前)
rm -rf /var/lib/mysql
[mysqld]
datadir=/var/lib/mysql
default-storage-engine=INNODB
character_set_server=utf8mb4
lower_case_table_names=1 # 不区分大小写
performance_schema=off
table_open_cache=128
transaction_isolation=READ-COMMITTED
max_connections=1000
max_connect_errors=6000
max_allowed_packet=64M
innodb_file_per_table=1
innodb_buffer_pool_size=512M
innodb_flush_method=O_DIRECT
innodb_lock_wait_timeout=1800
character-set-client-handshake = FALSE
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
init_connect='SET default_collation_for_utf8mb4=utf8mb4_general_ci'
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
skip-name-resolve
[mysql]
default-character-set=utf8mb4
[mysql.server]
default-character-set=utf8mb
- 启动
# 启动
systemctl start mysqld
# 停止
systemctl stop mysqld
# 状态
systemctl status mysqld
# 重启
systemctl restart msyqld
- 修改密码
# 查看密码
sudo grep 'temporary password' /var/log/mysqld.log
# 如果上面查不到密码,可以执行下面的查看
sudo grep 'temporary password' /var/log/messages
# 登录
mysql -uroot -p 密码
# 修改密码
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'Password123@mysql';
# 修改root作用域
update mysql.user set host = '%' where user = 'root';
# 刷新
flush privileges;
# 重启mysql
systemctl restart mysqld
2.3 主从配置
2.3.1 主库配置
- 修改 /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
default-storage-engine=INNODB
character_set_server=utf8mb4
lower_case_table_names=1 # 不区分大小写
performance_schema=off
table_open_cache=128
transaction_isolation=READ-COMMITTED
max_connections=1000
max_connect_errors=6000
max_allowed_packet=64M
innodb_file_per_table=1
innodb_buffer_pool_size=512M
innodb_flush_method=O_DIRECT
innodb_lock_wait_timeout=1800
character-set-client-handshake = FALSE
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
init_connect='SET default_collation_for_utf8mb4=utf8mb4_general_ci'
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
skip-name-resolve
# 主从复制-主机配置
# 主服务器唯一ID
server-id=1
# 启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=sys
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
binlog-ignore-db=performance_schema
# 设置需要复制的数据库(可设置多个)
binlog-do-db=metersphere
# 为每个session分配的内存,在事务过程中用来存储二进制日志的缓存
binlog_cache_size=1M
# 主从复制的格式(mixed,statement,row,默认格式是statement。建议是设置为row,主从复制时数据更加能够统一)
binlog_format=row
# 配置二进制日志自动删除/过期时间,单位秒,默认值为2592000,即30天;8.0.3版本之前使用expire_logs_days,单位天数,默认值为0,表示不自动
删除。
binlog_expire_logs_seconds=2592000
[mysql]
default-character-set=utf8mb4
[mysql.server]
default-character-set=utf8mb
- 重启MySQL
# 启动
systemctl start mysqld
# 停止
systemctl stop mysqld
# 状态
systemctl status mysqld
# 重启
systemctl restart msyqld
- 创建主从复制用户
#创建主从复制用户
CREATE USER 'clusteruser'@'%' IDENTIFIED WITH mysql_native_password BY 'Calong@2015';
# 授权
GRANT REPLICATION SLAVE ON *.* TO 'clusteruser'@'%';
# 刷新
FLUSH PRIVILEGES;
2.3.2 从库配置
- 配置my.cnf
[mysqld]
datadir=/var/lib/mysql
default-storage-engine=INNODB
character_set_server=utf8mb4
lower_case_table_names=1
performance_schema=off
table_open_cache=128
transaction_isolation=READ-COMMITTED
max_connections=1000
max_connect_errors=6000
max_allowed_packet=64M
innodb_file_per_table=1
innodb_buffer_pool_size=512M
innodb_flush_method=O_DIRECT
innodb_lock_wait_timeout=1800
character-set-client-handshake = FALSE
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
init_connect='SET default_collation_for_utf8mb4=utf8mb4_general_ci'
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION
skip-name-resolve
# 主从复制-主机配置
# 从服务器唯一ID
server-id=2
# 需要主从复制的数据库 ,如多个则重复配置
replicate-do-db=metersphere
# 复制过滤:也就是指定哪个数据库不用同步(mysql库一般不同步) ,如多个则重复配置
binlog-ignore-db=mysql
# 为每个session分配的内存,在事务过程中用来存储二进制日志的缓存
binlog_cache_size=1M
# 主从复制的格式(mixed,statement,row,默认格式是statement。建议是设置为row,主从复制时数据更加能够统一)
binlog_format=row
# relay_log配置中继日志,默认采用 主机名-relay-bin 的方式保存日志文件
relay_log=replicas-mysql-relay-bin
# log_replica_updates表示slave是否将复制事件写进自己的二进制日志,默认值ON开启;8.0.26版本之前使用log_slave_updates
log_replica_updates=ON
# 防止改变数据(只读操作,除了特殊的线程)
read_only=ON
[mysql]
default-character-set=utf8mb4
[mysql.server]
default-character-set=utf8mb
- 执行命令
CHANGE REPLICATION SOURCE TO SOURCE_HOST='10.1.12.13',SOURCE_PORT=3306,SOURCE_USER='clusteruser',SOURCE_PASSWORD='Calong@2015',SOURCE_LOG_FILE='mysql-bin.000003',SOURCE_LOG_POS=863;
MASTER_HOST/SOURCE_HOST:主数据库的主机ip
MASTER_PORT/SOURCE_PORT:主数据库的端口,不设置则默认是3306
MASTER_USER/SOURCE_USER:主数据库被授予同步复制权限的用户名
MASTER_PASSWORD/SOURCE_PASSWORD:对应的用户密码
MASTER_LOG_FILE/SOURCE_LOG_FILE:在主数据库执行命令show master status 查询到的二进制日志文件名称
MASTER_LOG_POS/SOURCE_LOG_POS:在主数据库执行命令show master status 查询到的位置 Position的值
- 开启从节点
# 查看从节点状态
show slave status \G;
# 启动
start slvae;
# 停止
stop slave;
# 重置
reset slave;
- 查看状态
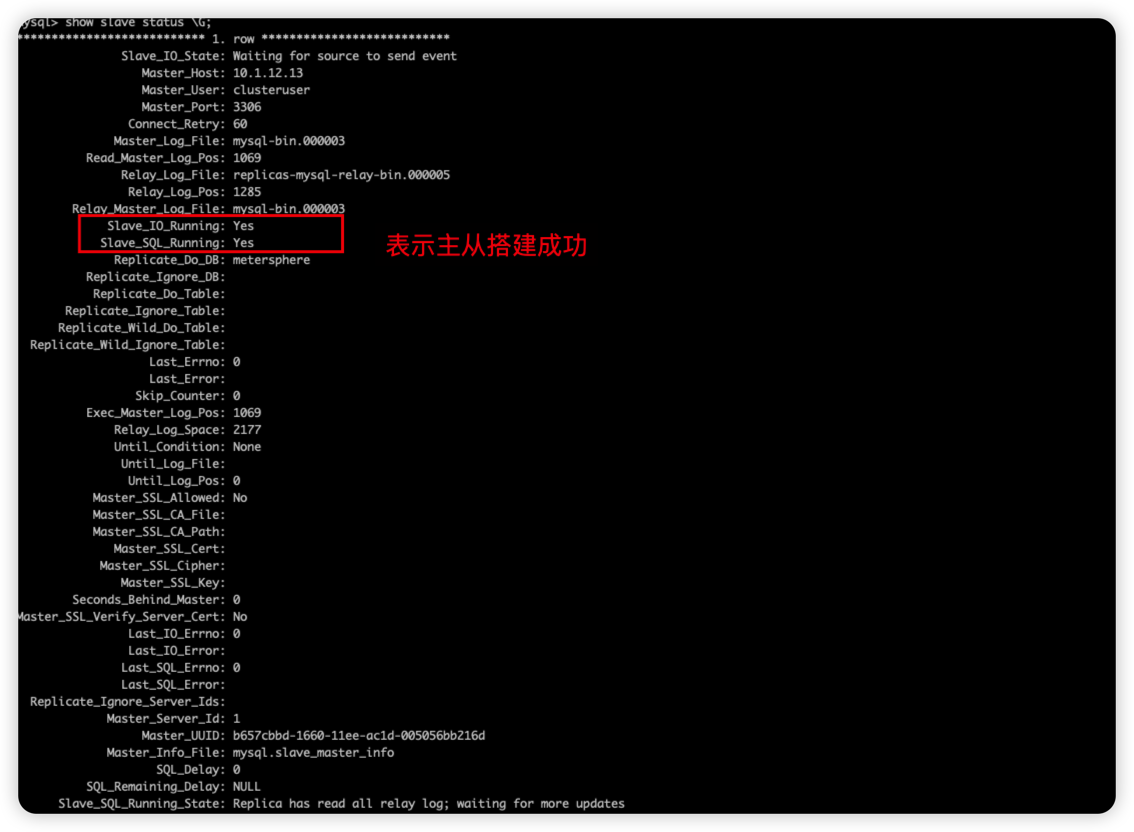
2.4 验证
- 主库添加一条数据,查看从库中是否同步,如果有,说明成功,否则失败。
- 主库执行sql语句
# 主从库执行前查看数量
select count(*) from workspace;
# 主库执行
INSERT INTO workspace ( `id`, `name`, `description`, `create_time`, `update_time`, `create_user` ) values ( "1", "test", "test", unix_timestamp(now())*1000, unix_timestamp(now())*1000, NULL );
# 主从库查看
select id,name from workspace where id='1';
主库/从库执行前:

主库执行后:


以上验证成功,即为搭建没问题。
三、Nginx 搭建
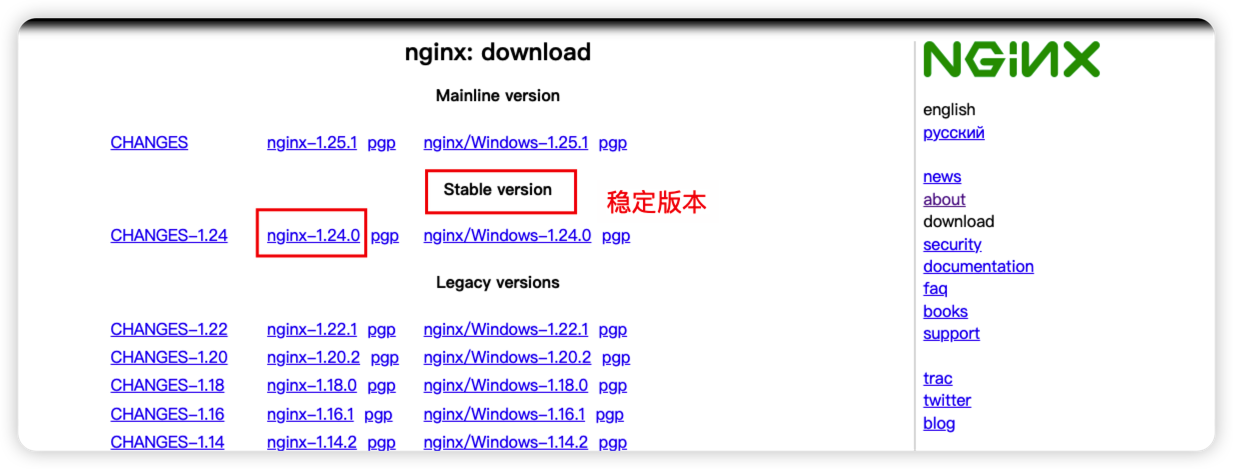
3.1 下载nginx安装包
下载地址:https://nginx.org/en/download.html
3.2 解压Nginx并安装
- 安装nginx
1. 解压nginx安装包
tar -zxvf nginx-1.24.0.tar.gz
2. 创建文件夹
mkdir /usr/local/nginx
3. 安装依赖
yum install -y gcc-c++ pcre pcre-devel zlib zlib-devel openssl openssl-devel
4.解压
cd nginx-1.24.0/
./configure --prefix=/usr/local/nginx
5. 安装
make && make install
6. 启动
cd /usr/local/nginx/sbin
./nginx
7.检查语法错误
./nginx -t
8.重启
./nginx -s reload
9.停止
./nginx -s stop
10. 验证,默认是80端口,直接访问ip,出现nginx的html页面,说明部署成功
- 修改配置信息
1. 修改配置信息,可以直接覆盖原来的。目录:/usr/local/nginx/conf/nginx.conf
#user nobody;
worker_processes 1;
#error_log logs/error.log;
#error_log logs/error.log notice;
#error_log logs/error.log info;
#pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#log_format main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
#access_log logs/access.log main;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
include /usr/local/nginx/conf/conf.d/*.conf;
#gzip on;
}
2. 创建配置目录
mkdir /usr/local/nginx/conf/conf.d
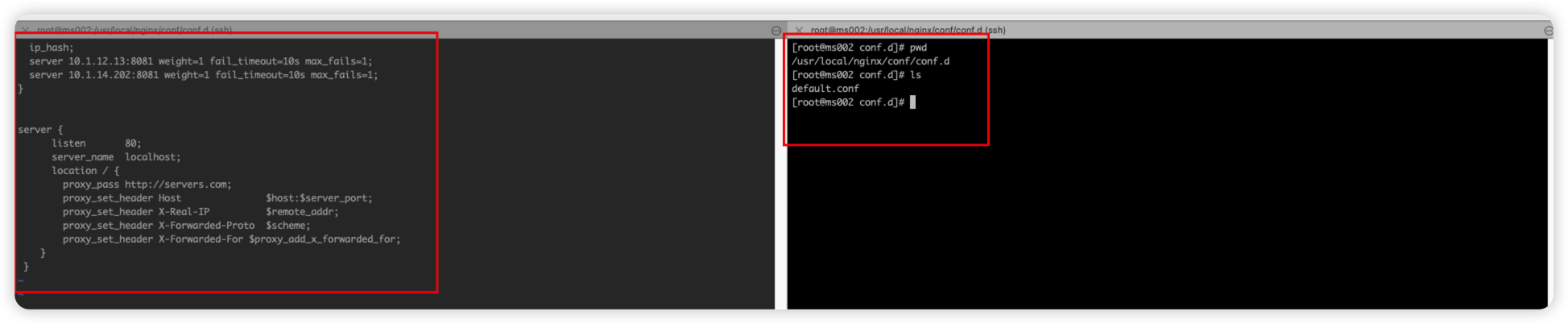
3. 创建default.conf并编辑以下内容
>>
upstream servers.com {
ip_hash;
server 10.1.12.13:8081 weight=1 fail_timeout=10s max_fails=1; # 主节点1
server 10.1.14.202:8081 weight=1 fail_timeout=10s max_fails=1; # 主节点2
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://servers.com;
proxy_set_header Host $host:$server_port;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
<<
- 效果
四、安装MeterSphere服务
官网地址:https://metersphere.io/docs/v2.x/installation/offline_installation/
- 安装包地址:https://community.fit2cloud.com/#/products/metersphere/downloads
- 解压安装, 默认安装/opt 目录
tar -zxvf metersphere-offline-installer-v2.10.2-lts.tar.gz
- 修改配置信息
cd metersphere-offline-installer-v2.10.2-lts
vi install.conf
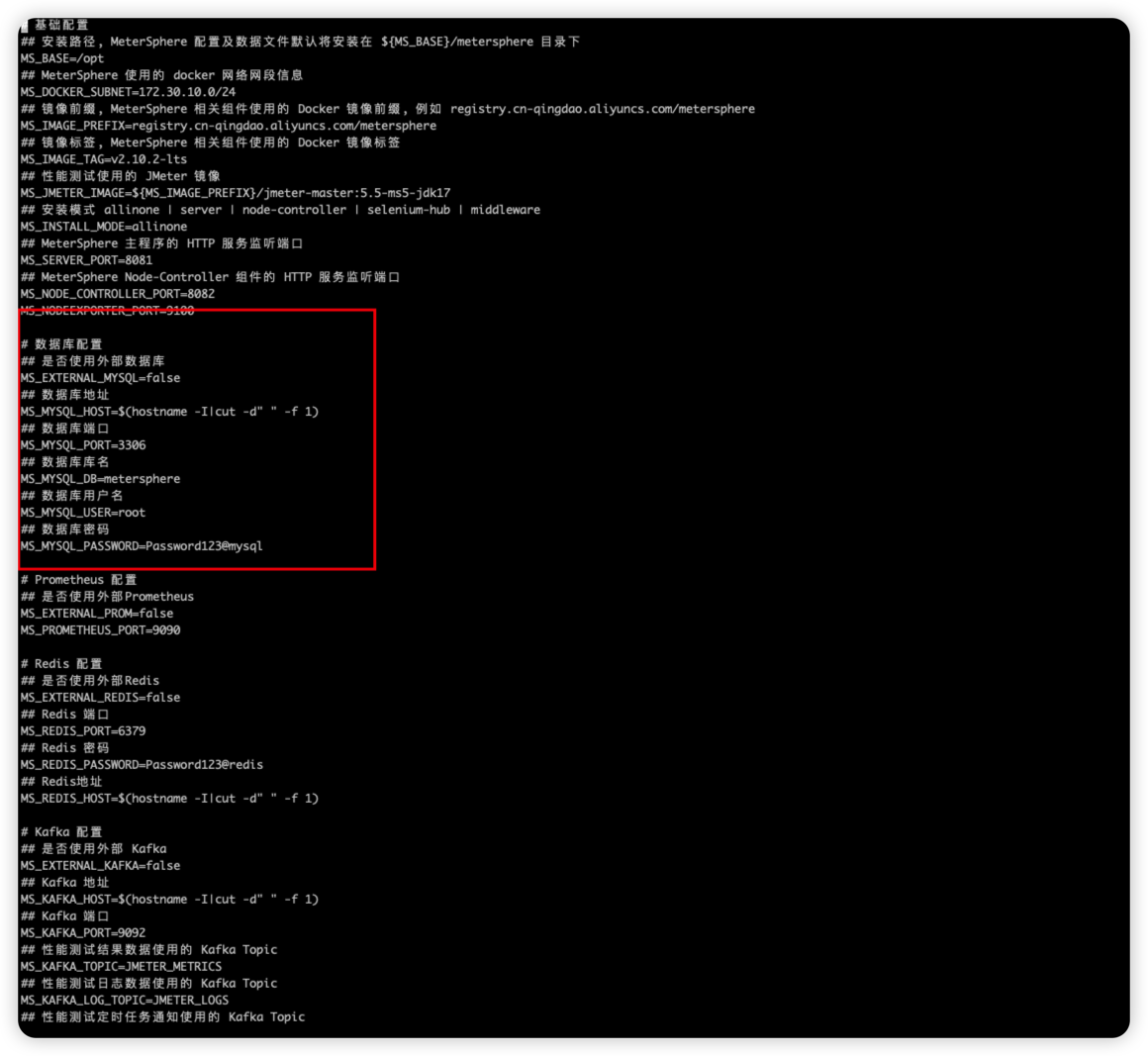
- 配置好之前搭建好MySQL的主节点信息,然后执行脚本安装
bash install.sh
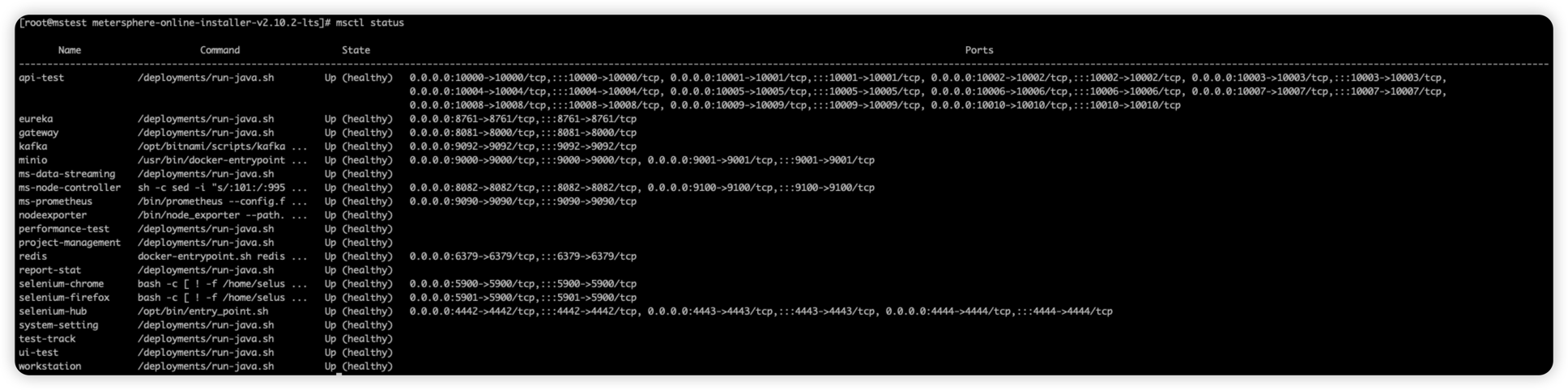
- 查看服务状态
msctl status
- 另外一个节点同样的操作,参考上面安装即可。
五、NFS 搭建
搭建NFS是为了文件共享,使两个MeterSphere节点,文件同步。
5.1 服务端搭建
1. 在nginx节点安装NFS服务器
yum -y install nfs-utils
2. 安装nfs+rpc
yum -y install nfs-utils rpcbind
3. 验证nfs安装
rpm -qa nfs-utils

4. 服务端创建共享文件目录(目录可以自定义)
mkdir -p /data/
chmod 666 /data/
因为我们要共享的是/opt/metersphere/data目录,所以需要把其文件夹给复制过来。
1. 直接去到部署metersphere的服务器,把/opt/meterspere/data 给打包
tar -czvf data.tar.gz /opt/metersphere/data
2.然后传到部署nfs服务端/data目录下
最终效果如下:
[root@ms002 data]# pwd
/data
[root@ms002 data]# ls
api-folder body jar jmeter kafka minio mysql node prometheus redis
[root@ms002 data]#
5.修改nfs的配置 /etc/exports
/data/ xx.xx.xx.xx(rw,sync,insecure,no_subtree_check,no_root_squash) xx.xx.xx.xx(rw,sync,insecure,no_subtree_check,no_root_squash)
# xx.xx.xx.xx 为客户端ip
#
#权限说明:
#rw read-write,可读写;
#sync:文件同时写入硬盘和内存;
#async:文件暂存于内存,而不是直接写入内存;
#no_root_squash:NFS客户端连接服务端时如果使用的是root的话,那么对服务端分享的目录来说,也拥有root权限。显然开启这项是不安全的。
#root_squash:NFS客户端连接服务端时如果使用的是root的话,那么对服务端分享的目录来说,拥有匿名用户权限,通常他将使用nobody或nfsnobody身份;
#all_squash:不论NFS客户端连接服务端时使用什么用户,对服务端分享的目录来说都是拥有匿名用户权限;
#anonuid:匿名用户的UID值,通常是nobody或nfsnobody,可以在此处自行设定;
#anongid:匿名用户的GID值。
#insecure:当mount监听端口大于1024时需要使用此参数

6. 重载配置数据
exportfs -rv
7. 启动rpc
systemctl start rpcbind
8.设置rpc开机启动
systemctl enable rpcbind
9.检查RPC
rpcinfo -p localhost

10.启动 NFS 服务
systemctl start nfs
systemctl enable nfs
5.2 客户端搭建(也就是安装MeterSphere节点的服务器)
1. 下载客户端
yum -y install nfs-utils
2. 校验服务端共享目录(判断网络是否通)
showmount -e xx.xx.xx.xx # xx.xx.xx.xx为服务端IP,有返回信息说明成功
3. 挂载共享目录
mount xx.xx.xx.xx:/data /opt/metersphere/data #xx.xx.xx.xx 服务端ip.
4. 至此直接在客户端或者服务端创建文件,看是否有同步即可。
注意:两个部署MeterSphere的节点都需要搭建。
六、验证
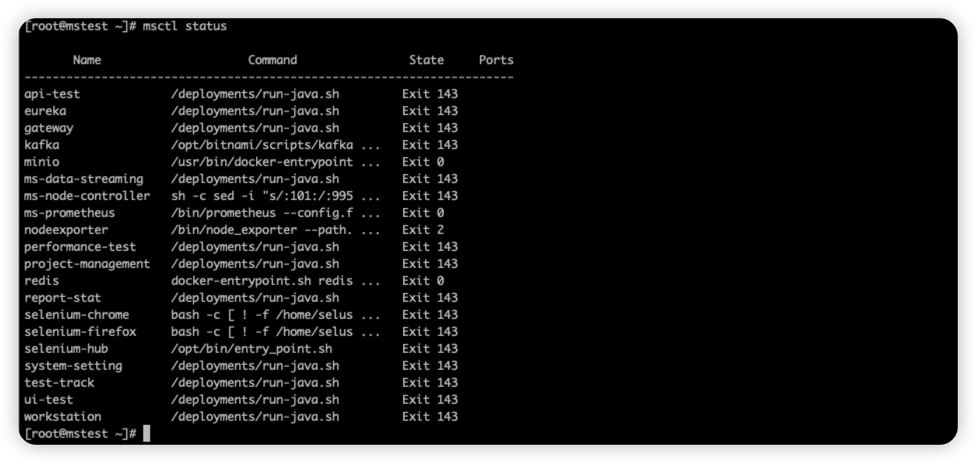
- 访问nginx节点,可以正常显示

- 因为使用nginx负载均衡,所以停掉一个服务,再进行访问。
七、注意事项
- 在安装MySQL的时候,有特别注意的地方需要仔细看下。
- 搭建双节点的MeterSphere应用所连接的中间件(kafka,redis,minio等)都需要连接同一个。
- v1和v2.3以前的版本需要NFS,v2.3开始使用MinIO对象存储,已经不再需要NFS了,但从v2.3以前版本升级上来的因为历史数据的原因还需要NFS。
- 如果需要保证相关中间件的可用性,可以自行独立部署。
- 以上就是完整的MeterSphere双活架构的部署流程,如有问题,欢迎留言。








