前言
本节内容是关于kafka集群节点的服役与退役,从而实现kafka集群的缩容与扩容。在开始本节内容之前,我们要预先安装好kafka集群,并准备一台空余的服务器用来完成我们扩容与缩容的案例。关于kafka集群的安装内容这里不在赘述,相关内容请查看作者往期博客内容。
正文
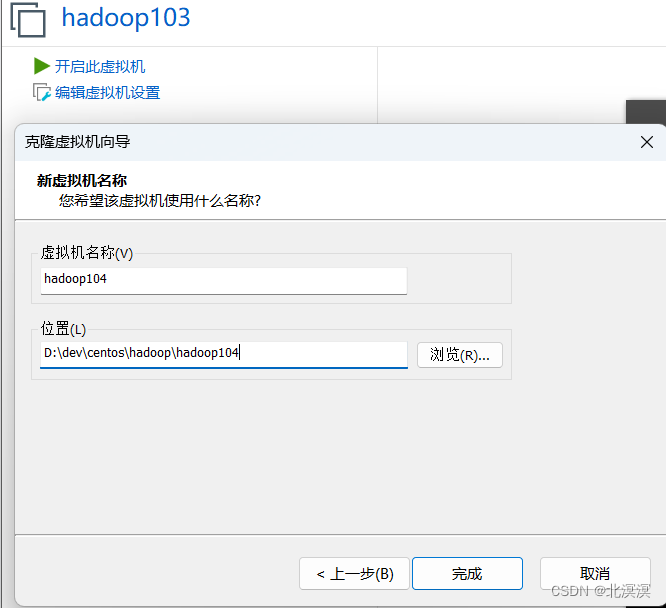
- 从hadoop103克隆一台空闲服务器hadoop104
- 克隆服务器hadoop104
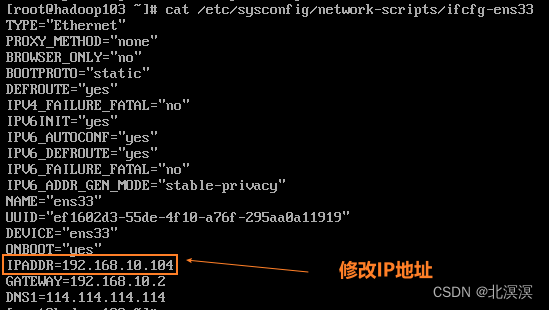
- 修改服务器IP地址
- 修改服务器主机名称
- 重启hadoop104服务器

- 在hadoop101启动zookeeper集群和kafka集群
- 启动zookeeper集群
- 启动kafka集群


- 修改hadoop104中kafka配置文件server.properties中的broker.id=3

- 删除hadoop104中kafka安装目录中的data和logs目录

- kafka集群服役新节点
- 启动hadoop104服务器上的kafka服务
bin/kafka-server-start.sh -daemon ./config/server.properties
- 查看主题是否有hadoop104服务节点使用,结果是没有
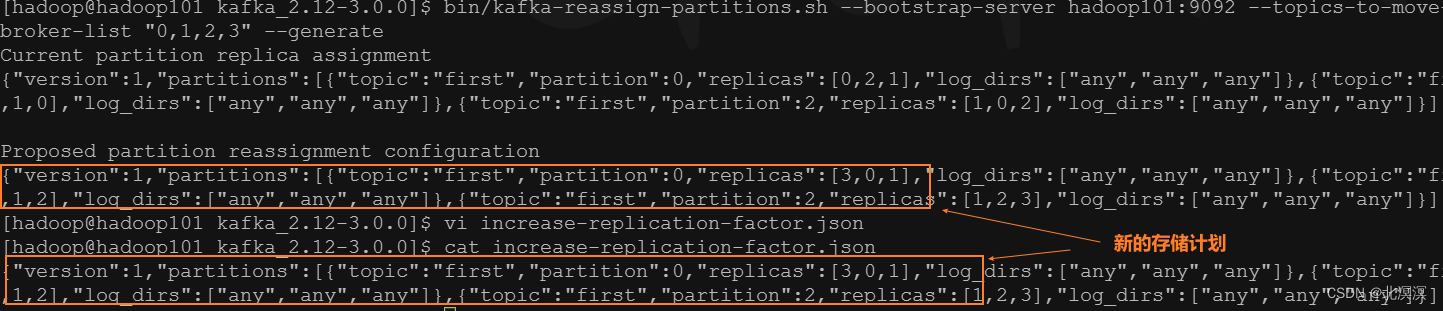
- 执行负载均衡操作,将first主题数据均衡到hadoop104节点
① 在kafka安装目录先创建一个topics-to-move.json文件,如果要均衡多个主题就将多个主题都放入该json文件中
{ "topics": [ { "topic": "first" } ], "version": 1 }
② 生成一个负载均衡的计划
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop101:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate
③ 创建副本存储计划increase-replication-factor.json
{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[3,0,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[1,2,3],"log_dirs":["any","any","any"]}]}
④执行副本存储计划
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop101:9092 --reassignment-json-file increase-replication-factor.json --execute
⑤验证副本存储计划
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop101:9092 --reassignment-json-file increase-replication-factor.json --verify
⑥查看first主题均衡后的数据存储分布,可以看到hadoop104的节点3也参与了主题数据的存储






- kafka集群退役旧节点
①同上生成一个负载均衡计划,注意该计划将要退役的节点3去掉
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop101:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2" --generate
②创建副本存储计划decrease-replication-factor.json
{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[0,2,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[1,0,2],"log_dirs":["any","any","any"]}]}
③执行副本存储计划
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop101:9092 --reassignment-json-file decrease-replication-factor.json --execute
④验证副本存储计划
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop101:9092 --reassignment-json-file decrease-replication-factor.json --verify
⑤查看first主题节点详情,,可以看到节点3已退役完成
bin/kafka-topics.sh --bootstrap-server hadoop101:9092 --describe --topic first





结语
关于kafka集群节点服役与退役案例实战的内容到这里就结束了,我们下期见。。。。。。





