基于WIN10的64位系统演示
一、写在前面
上一期,我们讲了多步滚动预测的第一种策略:对于重复的预测值,取平均处理。例如,(1,2,3)预测出3.9和4.5,(2,3,4)预测出5.2和6.3,那么拼起来的结果就是3.9,(4.5 + 5.2)/2, 6.3。
这一期,我们来介绍第二种策略:删除一半的输入数据集。例如,4,5由(1,2,3)预测,6,7由(3,4,5)预测,删掉输入数据(2,3,4)。
2、多步滚动预测 vol-2
所谓的删除一半的输入数据集,大家看下表即可:
| 输入 | 输出 |
| 1,2,3 | 4,5 |
| 3,4,5 | 6,7 |
| 5,6,7 | 8,9 |
| ... | ... |
4,5由(1,2,3)预测,6,7由(3,4,5)预测,8,9由(5,6,7)预测,删掉输入数据(2,3,4),(4,5,6),以此类推。
2.1 数据拆分
import pandas as pd
import numpy as np
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_absolute_error, mean_squared_error
data = pd.read_csv('data.csv')
data['time'] = pd.to_datetime(data['time'], format='%b-%y')
n = 6 # 使用前6个数据点
m = 2 # 预测接下来的2个数据点
# 创建滞后期特征
for i in range(n, 0, -1):
data[f'lag_{i}'] = data['incidence'].shift(n - i + 1)
data = data.dropna().reset_index(drop=True)
train_data = data[(data['time'] >= '2004-01-01') & (data['time'] <= '2011-12-31')]
validation_data = data[(data['time'] >= '2012-01-01') & (data['time'] <= '2012-12-31')]
# 只对X_train、y_train、X_validation取奇数行
X_train = train_data[[f'lag_{i}' for i in range(1, n+1)]].iloc[::2].reset_index(drop=True)
# 创建m个目标变量
y_train_list = [train_data['incidence'].shift(-i) for i in range(m)]
y_train = pd.concat(y_train_list, axis=1)
y_train.columns = [f'target_{i+1}' for i in range(m)]
y_train = y_train.iloc[::2].reset_index(drop=True).dropna()
X_train = X_train.head(len(y_train))
X_validation = validation_data[[f'lag_{i}' for i in range(1, n+1)]].iloc[::2].reset_index(drop=True)
y_validation = validation_data['incidence']核心部分在于:只对X_train、y_train、X_validation取奇数行。也就是我们说的删除一半的输入数据集。
2.2 建模与预测
tree_model = DecisionTreeRegressor()
param_grid = {
'max_depth': [None, 3, 5, 7, 9],
'min_samples_split': range(2, 11),
'min_samples_leaf': range(1, 11)
}
grid_search = GridSearchCV(tree_model, param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(X_train, y_train)
best_params = grid_search.best_params_
best_tree_model = DecisionTreeRegressor(**best_params)
best_tree_model.fit(X_train, y_train)
# 预测验证集
y_validation_pred = []
for i in range(len(X_validation)):
pred = best_tree_model.predict([X_validation.iloc[i]])
y_validation_pred.extend(pred[0])
y_validation_pred = np.array(y_validation_pred)[:len(y_validation)]
mae_validation = mean_absolute_error(y_validation, y_validation_pred)
mape_validation = np.mean(np.abs((y_validation - y_validation_pred) / y_validation))
mse_validation = mean_squared_error(y_validation, y_validation_pred)
rmse_validation = np.sqrt(mse_validation)
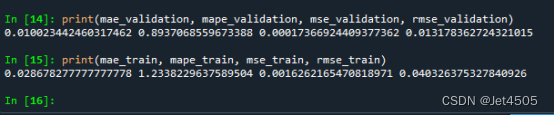
print(mae_validation, mape_validation, mse_validation, rmse_validation)
# 预测训练集
y_train_pred = []
for i in range(len(X_train)):
pred = best_tree_model.predict([X_train.iloc[i]])
y_train_pred.extend(pred[0])
# 因为预测了多步,为了与y_train的形状相匹配,只取第一列
y_train_pred = np.array(y_train_pred)[:y_train.shape[0]]
mae_train = mean_absolute_error(y_train.iloc[:, 0], y_train_pred)
mape_train = np.mean(np.abs((y_train.iloc[:, 0] - y_train_pred) / y_train.iloc[:, 0]))
mse_train = mean_squared_error(y_train.iloc[:, 0], y_train_pred)
rmse_train = np.sqrt(mse_train)
print(mae_train, mape_train, mse_train, rmse_train)核心代码,把每一个输出的结果(2个输出)按照顺序拼接形成最终的预测结果:
for i in range(len(X_validation)):
pred = best_tree_model.predict([X_validation.iloc[i]])
y_validation_pred.extend(pred[0])
这段代码通过循环对X_validation中的每一行数据进行预测,并将每次的预测结果依次添加到y_validation_pred中,体现了结果的依次拼接。
其中:
pred = best_tree_model.predict([X_validation.iloc[i]]) 是对第 i 行数据进行预测。
y_validation_pred.extend(pred[0]) 是将预测结果pred[0]依次添加到y_validation_pred列表中。
因此,y_validation_pred列表最后的内容是将每一次预测的结果依次拼接而成。
2.3 输出
三、数据
链接:https://pan.baidu.com/s/1EFaWfHoG14h15KCEhn1STg?pwd=q41n
提取码:q41n





