一、简介
本文主要通过代码实战介绍基础的两种图嵌入方式DeepWalk、Node2Vec。
DeepWalk(KDD 2014):首个影响至今的图的Embedding算法,DeepWalk算法是一种用于学习节点表示的方法,常用于网络图中的节点的嵌入表示。
| 模型 | 目标 | 输入 | 输出 |
| Word2Vec | Word | Sentence | Word Embedding |
| DeepWalk | Node | Node Sequence | Node Embedding |
算法流程:
1.首先,DeepWalk算法会从一个随机的起始节点开始,比如说选择朋友A作为起点。然后,算法会从A的邻居节点中随机选择一个节点,比如说选择了B。接着,算法会再从B的邻居节点中随机选择一个节点,比如说选择了C。这样反复进行直到达到事先设定的步数。
2.一旦完成了一次类似于“走迷宫”的遍历,DeepWalk算法会将这条路径视为一句话,其中包含了A、B和C三个节点。算法会重复这个过程,多次生成不同的句子。
3.然后,DeepWalk算法会将这些句子作为文本输入给Word2Vec算法。
Node2Vec:Node2Vec算法是一种能够学习网络节点表示的算法。它通过优化随机游走过程来最大化网络的邻域节点之间的相似度,从而得到每个节点的有效嵌入。
算法流程:
-
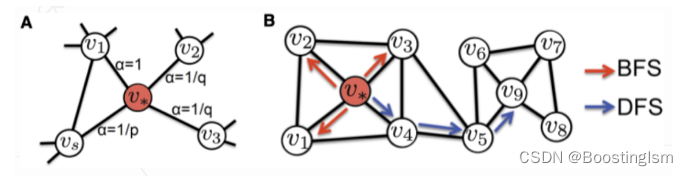
首先,从图中的每个节点开始执行固定长度的随机游走。这个步骤旨在生成每个节点的上下文信息。随机游走的方法包括以一种偏好的方式回到先前访问的节点,或者探索之前未访问的节点。这通过参数p和q来调整,其中p控制返回预先访问节点的可能性,而q控制更偏向于访问较远的节点。
-
得到随机游走序列之后,使用Skip-gram模型训练节点嵌入。在Skip-gram模型中,我们试图预测节点的邻居节点。
-
在训练过程中,使用梯度下降等优化算法最小化预测错误,进而通过迭代更新嵌入向量,使得越相似的节点其嵌入向量越接近。
4.最后经过这样的训练后,我们就可以获得每个节点的向量表示,这个向量反映了节点在网络中的位置和角色。
```
直接刚代码,开箱即用。
二、代码
import torch
import numpy as np
import os
import random
import pandas as pd
import scipy.sparse as sp
from torch_geometric.data import Data
from sklearn.preprocessing import LabelEncoder
from node2vec import Node2Vec
import networkx as nx
from gensim.models import Word2Vec
def seed_everything(seed=2023):
random.seed(seed)
os.environ['PYTHONHASHSEED']=str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
seed_everything()
def load_cora_data(data_path = './data/cora'):
content_df = pd.read_csv(os.path.join(data_path,"cora.content"), delimiter="\t", header=None)
content_df.set_index(0, inplace=True)
index = content_df.index.tolist()
features = sp.csr_matrix(content_df.values[:,:-1], dtype=np.float32)
# 处理标签
labels = content_df.values[:,-1]
class_encoder = LabelEncoder()
labels = class_encoder.fit_transform(labels)
# 读取引用关系
cites_df = pd.read_csv(os.path.join(data_path,"cora.cites"), delimiter="\t", header=None)
cites_df[0] = cites_df[0].astype(str)
cites_df[1] = cites_df[1].astype(str)
cites = [tuple(x) for x in cites_df.values]
edges = [(index.index(int(cite[0])), index.index(int(cite[1]))) for cite in cites]
edges = np.array(edges).T
# 构造Data对象
data = Data(x=torch.from_numpy(np.array(features.todense())),
edge_index=torch.LongTensor(edges),
y=torch.from_numpy(labels))
idx_train = range(140)
idx_val = range(200, 500)
idx_test = range(500, 1500)
# 读取Cora数据集 return geometric Data格式
def index_to_mask(index, size):
mask = np.zeros(size, dtype=bool)
mask[index] = True
return mask
data.train_mask = index_to_mask(idx_train, size=labels.shape[0])
data.val_mask = index_to_mask(idx_val, size=labels.shape[0])
data.test_mask = index_to_mask(idx_test, size=labels.shape[0])
def to_networkx(data):
edge_index = data.edge_index.to(torch.device('cpu')).numpy()
G = nx.DiGraph()
for src, tar in edge_index.T:
G.add_edge(src, tar)
return G
networkx_data = to_networkx(data)
return data,networkx_data
#获取数据:pyg_data:torch_geometric格式;networkx_data:networkx格式
pyg_data,networkx_data = load_cora_data()
#Node2Vec_Embedding方法
def Node2Vec_run(networkx_data, dimensions=128, walk_length=30, num_walks=200):
# 创建一个Node2Vec对象 #dimensions=64 embedding维度, walk_length=30 游走步长, num_walks=200 游走次数, workers=4 线程数
node2vec = Node2Vec(networkx_data, dimensions=dimensions, walk_length=walk_length, num_walks=num_walks, workers=4)
# 训练Node2Vec模型
model = node2vec.fit(window=10, min_count=1, batch_words=4) #获得node2vec的所有内容
nodes = model.wv.index_to_key # 得到所有节点的名字
embeddings = model.wv[nodes] # 得到所有节点的嵌入向量
return model,nodes,embeddings
def DeepWalk_run(networkx_data,dimensions = 128, walk_length = 30, num_walks = 200):
# 使用deepwalk算法进行graph embedding
# DeepWalk算法
def deepwalk(graph, num_walks, walk_length):
walks = []
for node in graph.nodes():
if graph.degree(node) == 0:
continue
for _ in range(num_walks):
walk = [node]
target = node
for _ in range(walk_length - 1):
if len(list(graph.neighbors(target))) == 0: # 判断当前节点是否有邻居,如果为空邻居,则跳过当前节点
continue
target = random.choice(list(graph.neighbors(target)))
walk.append(target)
walks.append(walk)
return walks
walks = deepwalk(networkx_data, num_walks = num_walks, walk_length = walk_length)
# 用Word2Vec训练节点向量
model = Word2Vec(walks, vector_size=dimensions, window=5, min_count=0, sg=1) #参数sg=1表示选择Skip-Gram模型 window 影响着Word2Vec中词和其上下文词的最大距离
nodes = model.wv.index_to_key # 得到所有节点的名字
embeddings = model.wv[nodes] # 得到所有节点的嵌入向量
return model,nodes,embeddings
_,_,node2vec_embeddings = Node2Vec_run(networkx_data,num_walks=1)
print("node2vec_embeddings :",np.array(node2vec_embeddings).shape) # print : "node2vec_embeddings : (2708, 64)"
_,_,DeepWalk_embeddings = DeepWalk_run(networkx_data,num_walks=1)
print("DeepWalk_embeddings :",np.array(DeepWalk_embeddings).shape) # print : "node2vec_embeddings : (2708, 64)"三、结果及展望
上述是针对Cora的数据集做的Node Embedding输出,输出为:node2vec_embeddings : (2708, 128);DeepWalk_embeddings : (2708, 128)
接下来大家就可拿到 (2708, 128)这个Embedding做各种下游了,如聚类、Net Feature等
P.S.这些都是18年以前,NN不发达的Embedding产物,并未挖掘深层feature的embedding,接下来玩一玩NN的Graph Embedding





