当大多数人听到 "机器学习 "时,他们会联想到机器人:一个可靠的管家或一个致命的终结者,这取决于你问谁。但是,机器学习并不只是未来主义的幻想,它已经存在了。事实上,在一些特殊的应用中,如光学字符识别(OCR)等,已经有了几十年的历史。但是第一个真正主流的ML应用是在20世纪90年代:垃圾邮件过滤器,它改善了数亿人的生活,并迅速得到了广泛的使用。它不完全是一个有自我意识的天网,但是严格来说,其技术上可以被称为机器学习(因为实际上它已经学得很好,你很少需要自己将邮件标记为垃圾邮件)。随后,又有数百个 ML应用现在已悄悄地为数百种产品和功能提供了动力,这些产品和功能包括你经常使用的,从推荐系统到语音搜索。
1.什么是机器学习
让计算机像人一样能从数据中学习出规律的一类算法。
人工智能>机器学习>深度学习
人工智能具体应用场景
- 计算机视觉(Computer Vision,CV):
指让计算机和系统能够从图像、视频和其他视觉输入中获取有意义的信息,并根据该信息采取行动或提供建议。
什么是计算机视觉 - 自然语言处理(Natural Language Processing,NLP):
是计算机科学、人工智能和语言学领域的一个交叉学科,主要研究如何让计算机能够理解、处理、生成和模拟人类语言的能力,从而实现与人类进行自然对话的能力。通过自然语言处理技术,可以实现机器翻译、问答系统、情感分析、文本摘要等多种应用。
什么是自然语言处理 - 推荐系统(Recommender System,RS):
推荐系统是一种信息过滤系统,手段是预测用户(user)对物品(item)的评分和偏好。
推荐系统
数据决定模型的上限,而算法则是让模型无限逼近上限!
what:
研究关于一类能从数据中学习出其背后潜在规律的算法的一门学科。
机器学习的三要素
数据、算法、模型
“机器学习是让计算机像人类一样学习和行动的科学,通过以观察和现实世界互动的形式向他们提供数据和信息,以自主的方式改善他们的学习。”
why:
可以从事相关研究与开发,迁移到自己的研究领域
下面这个想法我觉得很稀奇很有意思我觉得你可以试一试读读它,把机器学习的过程比喻成炼丹,在过程感受艺术的美妙,在过程中感受人生哲理,在过程中寻找自己~
为什么建议人都学机器学习
how:
如何学习机器学习,每个人的方法也许不同,但Datawhale绝对是一个很好的学习社区!见过许多方法不是要很多钱就是需要很自觉但Datawhale真的是既免费又耐心又负责!
假设空间:
“由输入空间到输出空间的映射的集合”
我理解的假设空间是根据数据你自己假设出来的函数、算法和模型所构成的集合能较好的拟合该数据集。
版本空间:
版本空间就是与训练集一致的所有假设所构成的集合,也就是假设空间的一个最大子集,该子集内的每一个元素都不与训练集相冲突。
我理解的是因为训练样本数量有限,假设空间含有很多假设,最终筛选后有可能剩下多个假设是符合训练样本的,这些剩下的假设组成的集合就称为版本空间。
2、基本术语
数据集:表示包含m个样本的数据集。
算法:指的是从数据中学得“模型”的具体方法。如线性回归、决策树、支持向量机、神经网络等。
“算法产出的结果称为“模型””~
模型:在机器学习范式中,模型是指模型参数的数学表达式,以及分别用于回归,分类和加固类别的每个预测,类别和动作的输入占位符。
在机器学习中,模型是重心,一切都围绕模型旋转。尽管不同的人对模型有不同的定义。但是我认为,这是我们最好的定义模型的方法,“机器学习中的模型是试图拟合数据并学习预测未知数据的假设”。
例如样本是⼀堆好⻄⽠和坏⻄⽠时,我们默认的便是好⻄⽠和坏⻄⽠背后必然存在某种规律能将其区分开。
样本:也称为“示例”,是关于一个事件或对象的描述。
样本空间:表示样本的特征向量所在的空间为样本空间。
标记:机器学习的本质就是在学习样本在某个方面的表现是否存在潜在的规律,我们称为该方面的信息称为“标记”。
例如,一条西瓜样本:x=(青绿;蜷缩;清脆),y=好瓜。
标记空间:标记所在空间,每个输出也可以看做一个向量,也可叫做标记空间。
监督学习:监督学习是根据已有数据集,知道输入和输出结果之间的关系,然后根据这种已知关系训练得到一个最优模型,可以划分为回归和分类如k-近邻算法、决策树、朴素贝叶斯等。
**无监督学习:**需要用某种算法去训练无标签的训练集从而能让我们我们找到这组数据的潜在结构,k-均值聚类,BIRCH聚类,高斯混合模型(GMM)等
泛化:由于机器学习的⽬标是根据已知来对未知做出尽可能准确的判断,因此对未知事物判断的准确与否才是衡量⼀个模型好坏的关键,我们称此为泛化能⼒。
举个例子,高中生每天各种做题,五年高考三年模拟一遍遍的刷,为的什么,当然是想高考能有个好成绩。高考试题一般是新题,谁也没做过,平时的刷题就是为了掌握试题的规律,能够举一反三、学以致用,这样面对新题时也能从容应对。这种规律的掌握便是泛化能力,有的同学很聪明,考上名校,很大程度上是该同学的泛化能力好。
考试成绩差的同学,有这三种可能:一、泛化能力弱,做了很多题,始终掌握不了规律,不管遇到老题新题都不会做;二、泛化能力弱,做了很多题,只会死记硬背,一到考试看到新题就蒙了;三、完全不做题,考试全靠瞎蒙。机器学习中,第一类情况称作欠拟合,第二类情况称作过拟合,第三类情况称作不收敛。
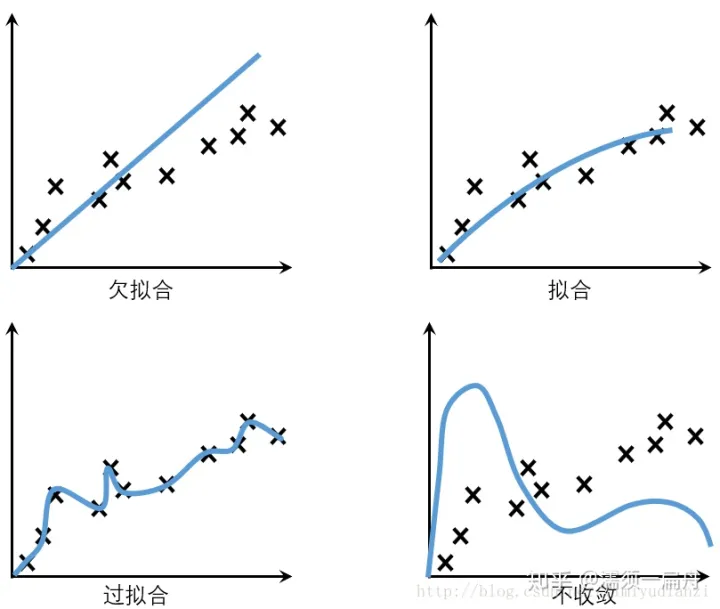
分布:指的是概率论中的概率分布,通常假设样本空间服从⼀个未知分布,⽽我们收集到的每个样本都是独⽴地从该分布中采样得到,即独⽴同分布。通常收集到的样本越多,越能从样本中反推出的信息,即越接近真相。
众算法生而平等
- 机器学习不是各种算法的堆砌,应当把它当做看待世界的世界观,解决问题的方法论,应该思考机器学习的思维方式而不是所谓的推导过程和各种细节,在掌握所有算法后忘记所有“招数”,融会贯通,整合甚至形成新的算法,无招胜有招。因为问题是无限的,算法是有限的,解决问题时,像裁缝一样量体裁衣,按需设计,度身定制,而不是生搬硬套,各种取巧和一劳永逸~
- 在机器学习过程中,不要总问哪一种算法最好,哪一种评估方法最好,记住天下没有免费的午餐,具体问题具体对待,机器学习不是在求精确的最优解,而是概率上的近似正确解。
3、模型评估与选择
那么如何评估模型的优劣和选择最适合自己业务场景的模型呢?
如何评估模型的优劣
添加链接描述
3.1 经验误差与过拟合
名词解释:
- 错误率:

- 精度:精度=1-错误率。
- 误差:学习器的实际预测输出与样本的真实输出之间的差异。
- 经验误差:学习器在训练集上的误差,又称为“训练误差”。
- 泛化误差:学习器在新样本(测试集)上的误差。
- 过拟合:是由于模型的学习能力相对于数据来说过于强大
- 欠拟合:是因为模型的学习能力相对于数据来说过于低下
根据大数定律,经验误差会收敛于泛化误差,两者(在一定容忍下)相近是由hoeffding不等式作为理论保证的,两者相差过大说明模型的欠拟合或者过拟合,而学习的一致收敛性说的正是这一特性:当训练集足够大,两者的结果就会足够相近,这样我们通过样本的“管中窥豹”的目的才能达到,最终才能获得一个目标假设。
偏差大,说明模型欠拟合;方差大,说明模型过拟合
经验误差与泛化误差欠拟合和过拟合
3.2评估方法
主要有3种模型评估方法:留出法、交叉验证法、自助法。
1.留出法
直接将数据集D划分为两个互斥集合S(训练集)和T(测试集)。D=S∪T,S∩T=∅,在S上训练出模型后,用T来评估测试误差,并将其作为泛化误差的估计。
举例:
采用方法:二分类任务
样本集:D包含1000个样本,其中500个正例,500个反例
S与T的划分方法:S包含700个样本,正例350,反例350;T包含300个样本,正例150,反例150
错误率与精度的计算:假设T上有90个样本分类错误,其错误率为(90/300)*100%=30%;精度为[(300-90)/300]*100%=1-30%=70%
补充:单次使用留出法得到的估计误差往往不够稳定,一般要采用若干次随机划分、重复进行实验评估后取平均值作为留出法的评估结果。如对上述1000个样本,可反复随机划分S和T,使用模型方法后,计算精度,求取平均值。
2.交叉验证法
交叉验证法本质上是在进行多次留出法,且每次都换不同的子集做测试集,最终让所有样本均至少做1次测试样本。
在样本量足够大的理想情况下,应当把数据集分割为三部分:训练集(training set)、验证集(validation set)和测试集(testing set),分别用于模型训练、模型选择和模型评估,用于评估模型泛化能力的测试集只出现在最后的模型评估环节。但很多时候数据不够充足,这种时候可以取消验证集,采用交叉验证方法,通过反复划分训练集和测试集来避免用同一批数据训练和评估一个模型,相当于将验证集和测试集合二为一了。
算法参数是指算法本身的一些参数(也称超参数),例如k近邻的近邻个数k、支持向量机的参数C,算法配置好相应参数后进行训练,训练结束会得到一个模型,例如支持向量机最终会得到w和b的具体数值(此处不考虑核函数),这就是模型参数,模型配置好相应模型参数后即可对新样本做预测。
模型的评估方法
模型评估(model assessment)是指对于一种具体方法输出的最终模型,使用一些指标和方法来评价它的泛化能力。
混淆矩阵,F1score
3.自助法
给定包含m个样本的数据集D,对其进行采样产生数据集D‘:每次随机从D中挑选一个样本,将其拷贝到D‘,然后将该样本放回到D中,使该样本在下次采样中人可能被采到;重复m次后,便得到了包含m个样本的数据集D‘。
举例:
采用方法:二分类任务
采样集:D包含1000个样本,其中500个正例,500个反例
S和T的划分方法:
随机可放回的抽取700个样本作为训练集,在这700个样本中会存在重复的样本。其中样本在700次采样中始终不被采到的概率为(1-1/700)700=0.3676。(当采样数为m时,始终不被采到的某样本概率为(1-1/m)m,取极限得到limm→∞(1-1/m)^m→1/e≈0.368)。
测试集中有0.36概率的样本未在训练集中出现,可选择D\D’中的300个样本作为测试集。并计算测试集中模型的精度。
补充:自助法在数据集较小,难以有效划分训练和测试集时方法较为有用。但通过自助法产生的数据集改变了初始数据集的分布,会出现估计偏差.
参考







