①. 索引的概述
-
①. 索引是帮助MySQL高效获取数据的排好序的数据结构
-
②. mysql数据库的实现原理通过b+树实现的,b+树的原理是先找到所有的数据,然后折半找到中间的数据,比它小的放左边,大的放右边,形成一个树的结构,依次去进行折半,然后将剩余的数据再折半
(索引底层实现原理b+树(二叉树),折半查找)


②. 二叉树和红黑树
- ①. 如果我们要查找89这个元素,经过两次IO就可以获取到(二叉树)

- ②. 这个时候我们以Col1为例,如果要查找6,会变成一种链表的形式,从001开始查看一直到006查看到为止(二叉树)

- ③. 如果我们的索引底层使用的是红黑树,随着数量的增加,深度会非常大(不采取)

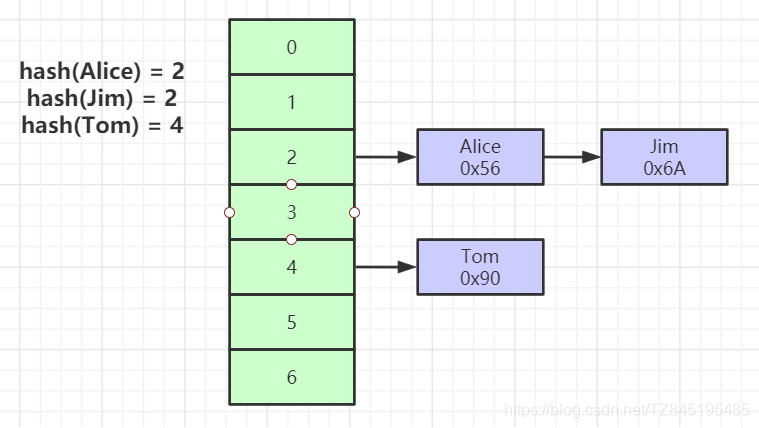
③. Hash建立索引结构
-
①. 在SQL中建立索引的时候,除了可以使用B+树的形式,还可以使用hash的方式

-
②. 对索引的key进行一次hash计算就可以定位出数据存储的位置
-
③. 很多时候Hash索引要比B+ 树索引更高效
-
④. 仅能满足 “=”,“IN”,不支持范围查询
-
⑤. hash冲突问题
④. B树的数据结构
-
①. 叶节点具有相同的深度,叶节点的指针为空
-
②. 所有索引元素不重复
-
③. 节点中的数据索引从左到右递增排列

⑤. MyISAM存储引擎索引实现
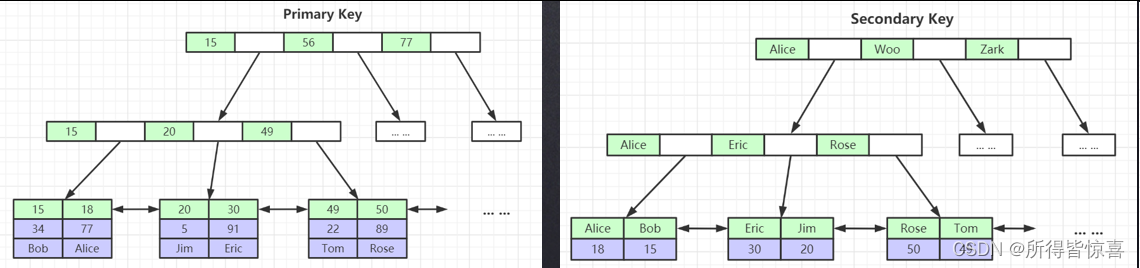
- ①. MyISAM索引文件和数据文件是分离的(非聚集)
非聚集:如下面的15:0x07,通过这个0x07地址找到数据表中实际的数据,需要有回表的方式

- ②. 我们使用MyISAM存储引擎有三种文件生成,第一个frm:表结构、MYD:表数据文件、MYI:表索引文件

⑥. InnoDB索引实现(聚集)
- ①. 聚集索引-叶节点包含了完整的数据记录
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能

- ②. 为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键,而不用UUID?
- 如果没有建立主键,那么mysql会默认将建表的语句中的不重复的列作为主键储存b+树,如果所有列都有重复数据,MYSQL会自动创建一个列出来,建立B+树的关系。建立了主键,MYSQL就可以根据主键来展示B+树的数据结构。
- 使用UUID能让主键唯一,但是在比较时,数据很大,在底层比的是位,如果我们使用简单的主键自增,一下就比较好
- ③. 谈谈你对B树和B+树区别?
- B+的data和索引全部在叶子节点,这样,可以储存更多的数据
- B树和B+树区别二,B+树有用指针链接,B树没有。试想,需要查询大于20的数据,那么B+树就可以根据折半查找找到20这个数据,再根据30储存的箭头找到49、50,依次这样下去。如果换做B树,查找49、50的时候,又需要重新进行扫描全表遍历
- ④. 为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
⑦. 联合索引的设定
- ①. 设置联合索引
key ‘idx_name_age_position’ (‘name’,‘age’,‘position’) USING BTREE

- ②. 下面的只有第一条使用的索引
explain select * from employee where name='TANGZHI' and age=31;
explain select * from employee where age=30 and position='dev';
explain select * from employee where position='dev';







