知识点07:Shell调度测试
-
目标:实现Shell命令的调度测试
-
实施
-
需求:使用BashOperator调度执行一条Linux命令
-
代码
-
创建
# 默认的Airflow自动检测工作流程序的文件的目录 mkdir -p /root/airflow/dags cd /root/airflow/dags vim first_bash_operator.py -
开发
# import from airflow import DAG from airflow.operators.bash import BashOperator from airflow.utils.dates import days_ago from datetime import timedelta # define args default_args = { 'owner': 'airflow', 'email': ['airflow@example.com'], 'email_on_failure': True, 'email_on_retry': True, 'retries': 1, 'retry_delay': timedelta(minutes=1), } # define dag dag = DAG( 'first_airflow_dag', default_args=default_args, description='first airflow task DAG', schedule_interval=timedelta(days=1), start_date=days_ago(1), tags=['itcast_bash'], ) # define task1 run_bash_task = BashOperator( task_id='first_bashoperator_task', bash_command='echo "hello airflow"', dag=dag, ) # run the task run_bash_task-
工作中使用bashOperator
bash_command='sh xxxx.sh' -
xxxx.sh:根据需求
- Linux命令
- hive -f
- spark-sql -f
- spark-submit python | jar
-
-
提交
python first_bash_operator.py -
查看
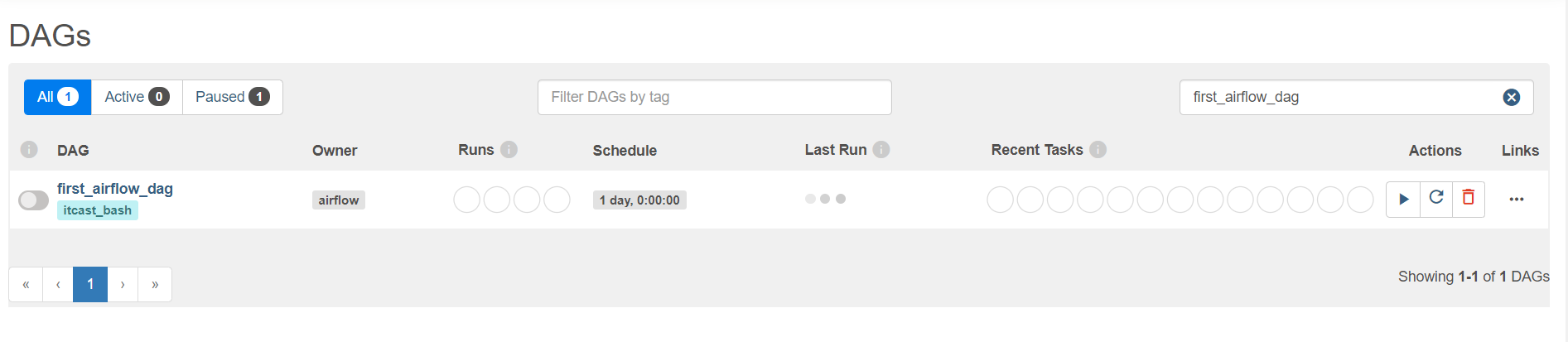
-
执行
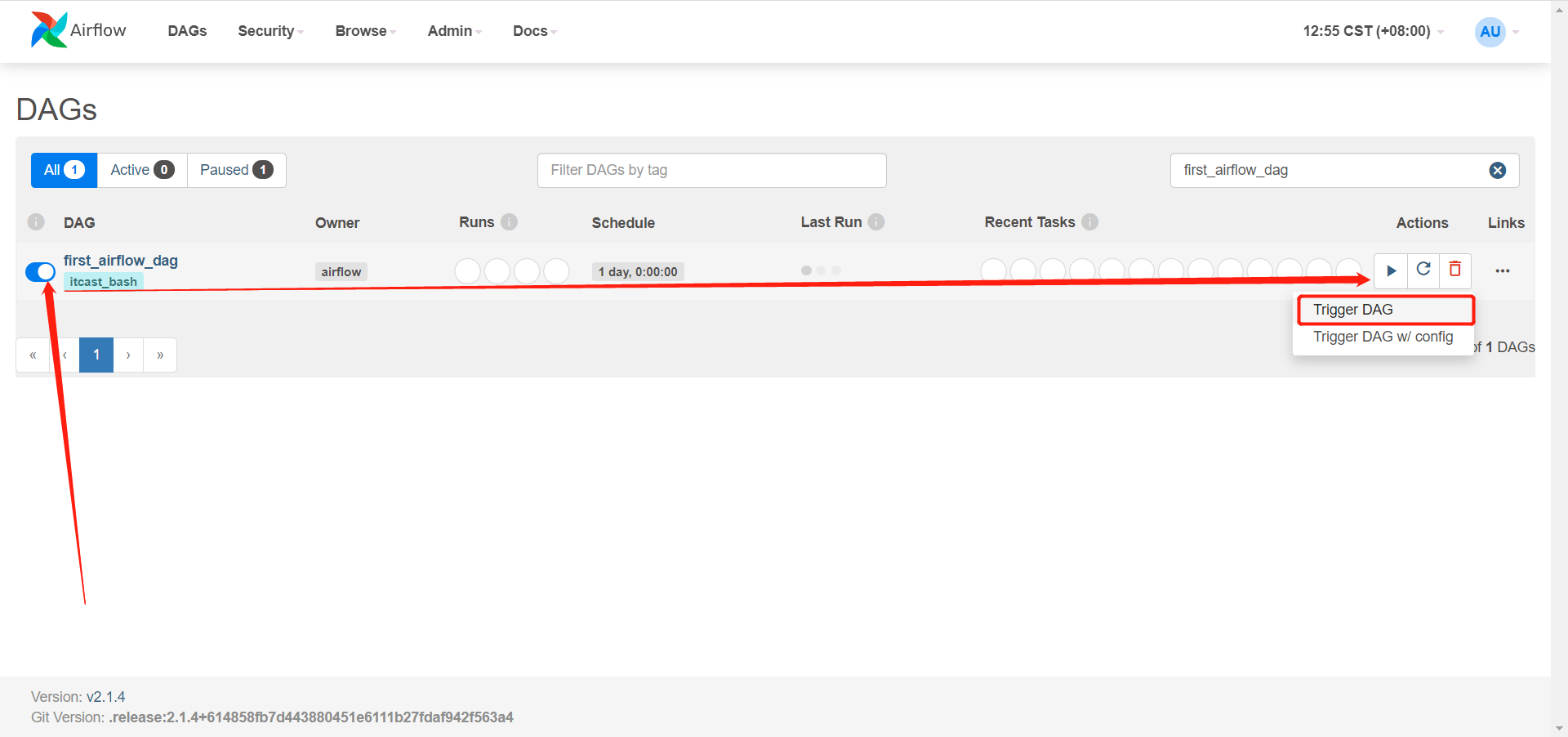
-
-
小结
- 实现Shell命令的调度测试
知识点08:依赖调度测试
-
目标:实现AirFlow的依赖调度测试
-
实施
-
需求:使用BashOperator调度执行多个Task,并构建依赖关系
-
代码
-
创建
cd /root/airflow/dags vim second_bash_operator.py -
开发
# import from datetime import timedelta from airflow import DAG from airflow.operators.bash import BashOperator from airflow.utils.dates import days_ago # define args default_args = { 'owner': 'airflow', 'email': ['airflow@example.com'], 'email_on_failure': True, 'email_on_retry': True, 'retries': 1, 'retry_delay': timedelta(minutes=1), } # define dag dag = DAG( 'second_airflow_dag', default_args=default_args, description='first airflow task DAG', schedule_interval=timedelta(days=1), start_date=days_ago(1), tags=['itcast_bash'], ) # define task1 say_hello_task = BashOperator( task_id='say_hello_task', bash_command='echo "start task"', dag=dag, ) # define task2 print_date_format_task2 = BashOperator( task_id='print_date_format_task2', bash_command='date +"%F %T"', dag=dag, ) # define task3 print_date_format_task3 = BashOperator( task_id='print_date_format_task3', bash_command='date +"%F %T"', dag=dag, ) # define task4 end_task4 = BashOperator( task_id='end_task', bash_command='echo "end task"', dag=dag, ) say_hello_task >> [print_date_format_task2,print_date_format_task3] >> end_task4
-
-
提交
python second_bash_operator.py -
查看
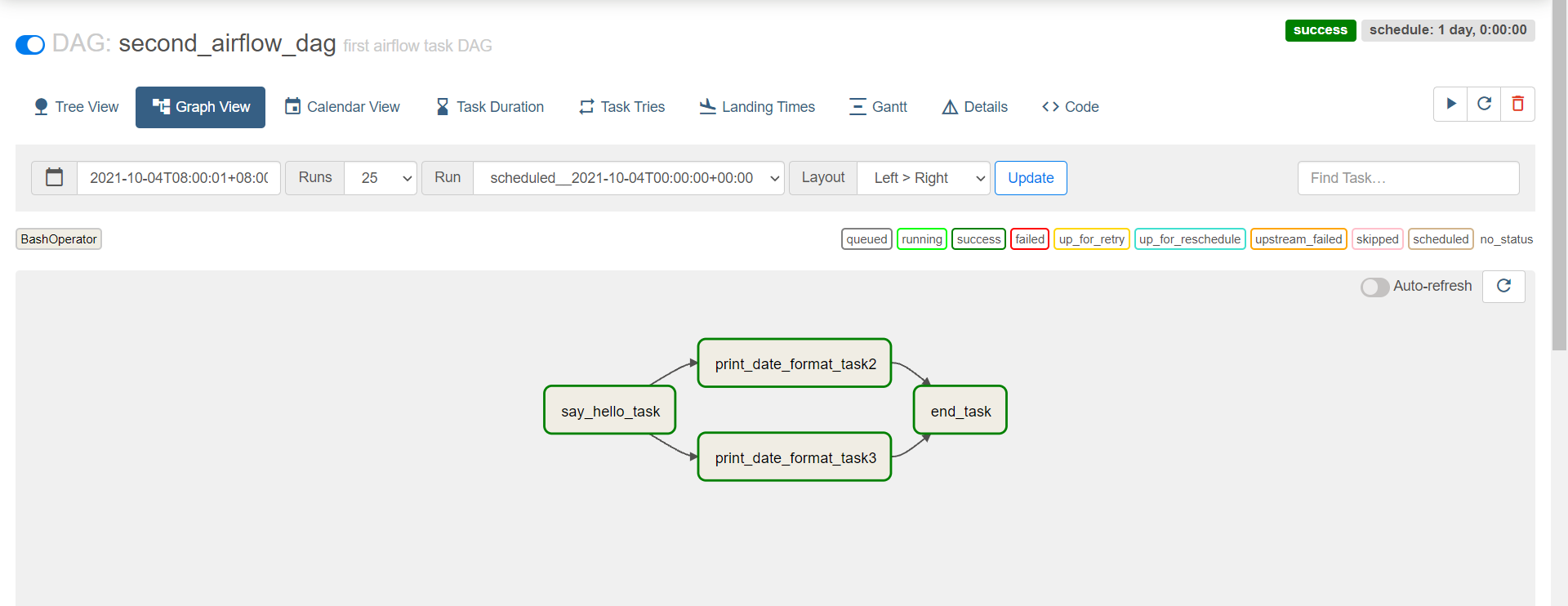
-
-
小结
- 实现AirFlow的依赖调度测试
知识点09:Python调度测试
-
目标:实现Python代码的调度测试
-
实施
-
需求:调度Python代码Task的运行
-
代码
-
创建
cd /root/airflow/dags vim python_etl_airflow.py -
开发
# import package from airflow import DAG from airflow.operators.python import PythonOperator from airflow.utils.dates import days_ago import json # define args default_args = { 'owner': 'airflow', } # define the dag with DAG( 'python_etl_dag', default_args=default_args, description='DATA ETL DAG', schedule_interval=None, start_date=days_ago(2), tags=['itcast'], ) as dag: # function1 def extract(**kwargs): ti = kwargs['ti'] data_string = '{"1001": 301.27, "1002": 433.21, "1003": 502.22, "1004": 606.65, "1005": 777.03}' ti.xcom_push('order_data', data_string) # function2 def transform(**kwargs): ti = kwargs['ti'] extract_data_string = ti.xcom_pull(task_ids='extract', key='order_data') order_data = json.loads(extract_data_string) total_order_value = 0 for value in order_data.values(): total_order_value += value total_value = {"total_order_value": total_order_value} total_value_json_string = json.dumps(total_value) ti.xcom_push('total_order_value', total_value_json_string) # function3 def load(**kwargs): ti = kwargs['ti'] total_value_string = ti.xcom_pull(task_ids='transform', key='total_order_value') total_order_value = json.loads(total_value_string) print(total_order_value) # task1 extract_task = PythonOperator( task_id='extract', python_callable=extract, ) extract_task.doc_md = """\ #### Extract task A simple Extract task to get data ready for the rest of the data pipeline. In this case, getting data is simulated by reading from a hardcoded JSON string. This data is then put into xcom, so that it can be processed by the next task. """ # task2 transform_task = PythonOperator( task_id='transform', python_callable=transform, ) transform_task.doc_md = """\ #### Transform task A simple Transform task which takes in the collection of order data from xcom and computes the total order value. This computed value is then put into xcom, so that it can be processed by the next task. """ # task3 load_task = PythonOperator( task_id='load', python_callable=load, ) load_task.doc_md = """\ #### Load task A simple Load task which takes in the result of the Transform task, by reading it from xcom and instead of saving it to end user review, just prints it out. """ # run extract_task >> transform_task >> load_task
-
-
提交
python python_etl_airflow.py -
查看
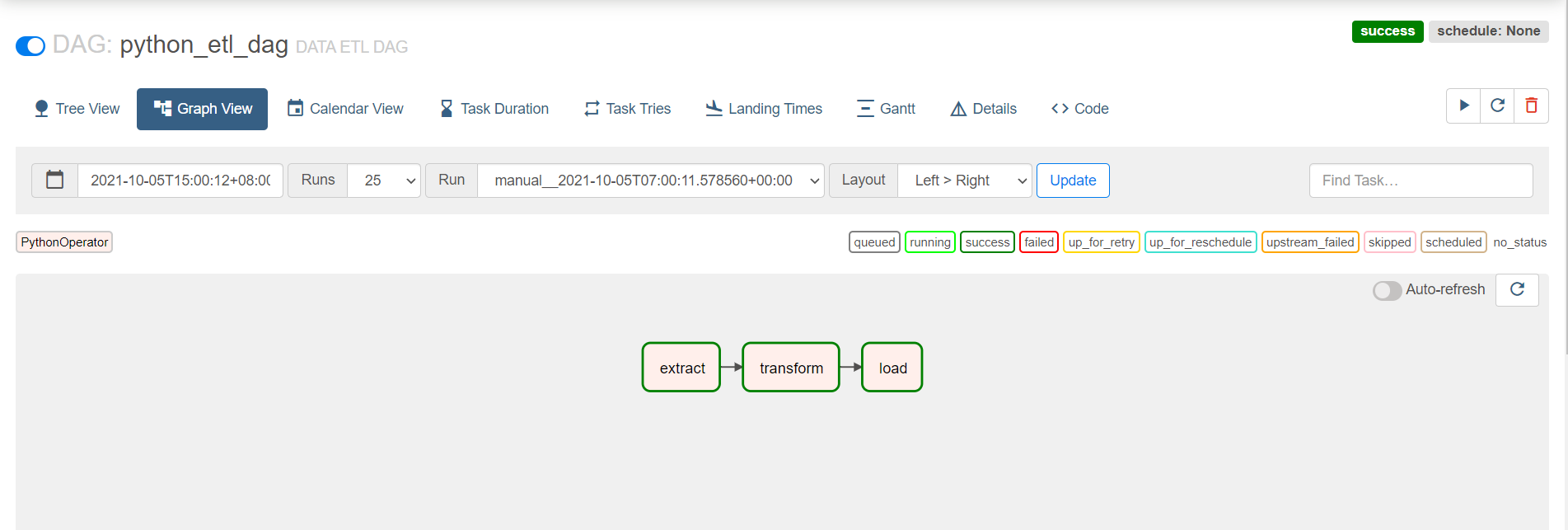
-
-
小结
- 实现Python代码的调度测试
知识点10:Oracle与MySQL调度方法
-
目标:了解Oracle与MySQL的调度方法
-
实施
-
Oracle调度:参考《oracle任务调度详细操作文档.md》
-
step1:本地安装Oracle客户端
-
step2:安装AirFlow集成Oracle库
-
step3:创建Oracle连接
-
step4:开发测试
query_oracle_task = OracleOperator( task_id = 'oracle_operator_task', sql = 'select * from ciss4.ciss_base_areas', oracle_conn_id = 'oracle-airflow-connection', autocommit = True, dag=dag )
-
-
MySQL调度:《MySQL任务调度详细操作文档.md》
-
step1:本地安装MySQL客户端
-
step2:安装AirFlow集成MySQL库
-
step3:创建MySQL连接
-
step4:开发测试
-
方式一:指定SQL语句
query_table_mysql_task = MySqlOperator( task_id='query_table_mysql', mysql_conn_id='mysql_airflow_connection', sql=r"""select * from test.test_airflow_mysql_task;""", dag=dag )-
方式二:指定SQL文件
query_table_mysql_task = MySqlOperator( task_id='query_table_mysql_second', mysql_conn_id='mysql-airflow-connection', sql='test_airflow_mysql_task.sql', dag=dag )
-
-
方式三:指定变量
insert_sql = r""" INSERT INTO `test`.`test_airflow_mysql_task`(`task_name`) VALUES ( 'test airflow mysql task3'); INSERT INTO `test`.`test_airflow_mysql_task`(`task_name`) VALUES ( 'test airflow mysql task4'); INSERT INTO `test`.`test_airflow_mysql_task`(`task_name`) VALUES ( 'test airflow mysql task5'); """ insert_table_mysql_task = MySqlOperator( task_id='mysql_operator_insert_task', mysql_conn_id='mysql-airflow-connection', sql=insert_sql, dag=dag )
-
-
-
-
小结
- 了解Oracle与MySQL的调度方法
知识点11:大数据组件调度方法
-
目标:了解大数据组件调度方法
-
实施
-
AirFlow支持的类型
- HiveOperator
- PrestoOperator
- SparkSqlOperator
-
需求:Sqoop、MR、Hive、Spark、Flink
-
解决:统一使用BashOperator或者PythonOperator,将对应程序封装在脚本中
-
Sqoop
run_sqoop_task = BashOperator( task_id='sqoop_task', bash_command='sqoop --options-file xxxx.sqoop', dag=dag, ) -
Hive
run_hive_task = BashOperator( task_id='hive_task', bash_command='hive -f xxxx.sql', dag=dag, ) -
Spark
run_spark_task = BashOperator( task_id='spark_task', bash_command='spark-sql -f xxxx.sql', dag=dag, ) -
Flink
run_flink_task = BashOperator( task_id='flink_task', bash_command='flink run /opt/flink-1.12.2/examples/batch/WordCount.jar', dag=dag, )
-
-
-
小结
- 了解大数据组件调度方法






