在 9 月 15 日的第七届 CSN 大会上,思码逸研发效能专家王艳萍受邀分享了《汽车行业研发效能提升的挑战与实践案例》。演讲包含了思码逸对多家汽车企业服务过程中总结出的行业痛点、解决方案,以及实践案例。

以下为演讲实录:
思码逸与很多知名汽车企业都有合作。我们这次的演讲会先简单介绍一下思码逸,然后重点分享我们与汽车企业在研发效能层面的实践,汽车软件研发效能与传统软件研发效能的差异,以及在汽车行业中,软件研发效能度量的痛点与解决方案等。
思码逸成立于 2018 年,专注于软件研发效能度量与分析。基于深度代码分析技术,思码逸产品从代码和 DevOps 工具链中提取数据,呈现研发效率、软件工程质量、组织与人才发展等多视角数据洞察,提高研发过程可见性,辅助团队决策,推动开发者自驱成长。
思码逸独有的研发效能指标“代码当量”已经作为核心指标,被信通院采纳。我们也受信通院邀请,与京东、腾讯、百度、网易等等 40 多家公司,一起起草了《软件研发效能度量规范》。
我们目前服务了上百家企业,其中来自汽车行业的包括理想、蔚来、宝马、保时捷、沃尔沃等。
汽车行业的软件研发效能特征与挑战
相比传统的软件研发,汽车软件的研发会更加复杂,主要体现在两方面,一方面是项目复杂,另一方面是人员复杂。
首先,项目方面存在以下特点:
体量大:规模大、交付周期长,子项目类型多
版本众多:为了适配各种硬件,需要更多版本,所以每个版本中的模块复用度高。一旦模块底层需要修改,那么带来的技术维护难度大,所以有更高的质量要求。
嵌入式开发:软硬结合的开发方式,在软件测试时,需要适应物理环境及硬件接口,所以会导致测试效率比传统软件开发要慢。
安全性要求高:相比传统软件开发,汽车软件对安全的要求非常高, 包括功能安全、网络安全等,一旦出现问题,就可能危及用户生命。
由于项目的复杂度高,所以相应地会在人员上带来更高的复杂度,主要体现在两方面。一方面是人员构成比较复杂,不仅有公司内部的研发团队,还有外包团队。在人员岗位上,除了传统的前端、后端、算法,还会包含嵌入式开发等硬件相关的研发人员。

基于以上特点,汽车软件研发对效能度量的要求会比较高。我们总结了一下我们客户经常遇到的研发效能度量的诉求。
首先由于研发项目体量大,所以即使效率提升一个百分点,也可以节省巨大的成本。所以第一个诉求就是“提升整体效率,做更准确的需求预估”。另一个诉求,就是“及时判断卡点,找到影响交付速度的关键因素”,从而提升项目整体的效率。
因为整个软汽车行业对安全可靠性的要求非常高,这就要求我们能在整个研发过程中及时地发现问题,保证可以在最终测试和交付之前解决掉关键问题,而不是在最后发现问题,再回过头去修改。
在人员管理方面,主要诉求就是“建立考核标准,制定研发流程规范”,通过科学的方法来管理复杂的团队。
最后从项目和人员管理两个角度综合来看,还有一个诉求就是“合理调配资源,避免忙闲不均或者资源错配带来的浪费”。
由这些诉求出发,结合我们与多个汽车企业合作的经验来看,我们可以看到汽车行业做研发效能度量的四个难点:
-
第一,数据分散。研发数据可能分散在多个不同的工具中,整合数据是一个难点。
-
第二,缺少可靠的数据基础指标。例如要统计这个工时内完成了多少需求、功能点,这些数据的填写大多是依赖个人主观判断的,所以没有统一的标准,那么这就给后续的数据分析带来难题。同时,还有大量的代码复用、功能点大小不一等问题,都是由于缺少基础的指标。
-
第三,分析维度、视角多。一个项目可能会涉及到多个子项目、版本,每个子项目背后可能还有不同的团队、不同的人。在团队中,高层、中层对项目的关注点都不同,所以会涉及到非常多的维度和视角。我们有很多客户都是说“我们有很多指标,但就是用不起来”,其背后的原因就是因为你给出分析结果,并不一定是这个管理者或角色他想看到的。高管不希望看到那么多细节信息,而基层管理者却希望从细节中发现改进点。
-
第四,定位问题困难。由于项目周期长、项目复杂度高,甚至可能还会涉及到较多的外包资源,所以很难快速地定位问题。
解决方案与实践案例
我们为汽车行业提供了这样一套解决方案,如下图所示。我们从数据采集、建模、指标体系,到分析,提供了一套全流程的度量与分析平台。我们已经把常用的代码仓库、项目管理工具、质量扫描工具和 CI/CD工具的数据接口打通了,可以通过简单配置就将数据接入进来。如果你使用的是我们还未支持的工具,也可以通过 CSV 的形式将数据导入到平台中。我们的平台会清洗数据,并基于数据建模输出事务管理、代码效率、质量管理等模型。

在平台中,我们根据对上百家企业的服务经验,默认预置了 100+研发效能指标,根据你的模型会推荐一些指标,并支持用户自定义指标。

在分析层面,我们支持根据不同角色进行多维度的数据展示和分析。如果是需要了解更多细节信息的管理者,还可以针对数据进行下钻分析,直至找到问题的根源。

另外,我们还提供一些行业基线和组织基线,让你可以知道目前团队的研发效能、项目质量在行业中所处的水平是怎样的,以及与自身相比是否在持续进步,甚至于公司内其他团队相比处于什么样的位置。为了让管理者更容易去分析数据,我们还在平台中提供了智能专家系统,来辅助解读数据指标和现状。
 我们已经把大部分的高频指标都放在平台中了。我们简单介绍一下核心指标“代码当量”。大家可以将它理解为与“代码行数”对标的一个指标。但是代码行数可能会遇到空行、注释、第三方引用等。这让代码行数无法真实体现产出效率。“代码当量”是基于深度代码分析专利算法产生的,它会将代码书写过程中这些“水分”挤掉,而且这套算法的计算机制较为复杂,所以很难造假,可以提供更客观的度量数据。
我们已经把大部分的高频指标都放在平台中了。我们简单介绍一下核心指标“代码当量”。大家可以将它理解为与“代码行数”对标的一个指标。但是代码行数可能会遇到空行、注释、第三方引用等。这让代码行数无法真实体现产出效率。“代码当量”是基于深度代码分析专利算法产生的,它会将代码书写过程中这些“水分”挤掉,而且这套算法的计算机制较为复杂,所以很难造假,可以提供更客观的度量数据。
 下面我们举几个例子。我们平台提供了 30 多种图表的展示,图中的一些异常点都可以直接点击进去看更深层的数据,进行下钻分析。用户可以根据不同管理者的需求定制自己的看板。比如高层关注整体的指标,可以看 ROI、整体交付速度、交付效率,以及资源配置是否均衡等。
下面我们举几个例子。我们平台提供了 30 多种图表的展示,图中的一些异常点都可以直接点击进去看更深层的数据,进行下钻分析。用户可以根据不同管理者的需求定制自己的看板。比如高层关注整体的指标,可以看 ROI、整体交付速度、交付效率,以及资源配置是否均衡等。
 对于项目经理或团队 Leader,可以关注团队的项目进展等更细的数据。例如下图左边的交付效率中,处于右下角的“后端团队”的交付效率就比较低,那么点击它,就可以进一步下钻寻找原因。那这个原因到底是什么?有可能是某一个地方遇到了卡点,或者是这个需求涉及的产品设计时间比较长,也有可能是需求颗粒度不稳定,所以他交付的需求少,还有可能是遇到了比较大的 Bug 需要较长的时间修复。这些问题都可以从下钻分析中发现。
对于项目经理或团队 Leader,可以关注团队的项目进展等更细的数据。例如下图左边的交付效率中,处于右下角的“后端团队”的交付效率就比较低,那么点击它,就可以进一步下钻寻找原因。那这个原因到底是什么?有可能是某一个地方遇到了卡点,或者是这个需求涉及的产品设计时间比较长,也有可能是需求颗粒度不稳定,所以他交付的需求少,还有可能是遇到了比较大的 Bug 需要较长的时间修复。这些问题都可以从下钻分析中发现。
 从质量层面,我们可以看整体项目上线的 bug、事故数量,代码的内建质量,以及bug 的修复工作量。我们也会推荐一些重点关注的函数,比如某些代码的圈复杂度比较高或被引用次数比较多,那么会优先推荐进行一些测试。
从质量层面,我们可以看整体项目上线的 bug、事故数量,代码的内建质量,以及bug 的修复工作量。我们也会推荐一些重点关注的函数,比如某些代码的圈复杂度比较高或被引用次数比较多,那么会优先推荐进行一些测试。
 以上就是对于思码逸解决方案的一个大致的介绍。接下来,我们来看一个汽车行业的实践案例。
以上就是对于思码逸解决方案的一个大致的介绍。接下来,我们来看一个汽车行业的实践案例。

这个案例源自某个车企,他们的研发规模有 200 多人,他们有很大比例的外包人员,所以他们希望可以准确预估整体的工作量,并建立对外包供应商的评估体系。他们原先使用“事故点”、“工时”去评估需求颗粒度,这对于资源需求以及如何调配来讲,缺少客观参考信息。针对这个问题,我们基于代码当量,量化了需求颗粒度,保证需求颗粒度的稳定性,并且估算研发交付的带宽。
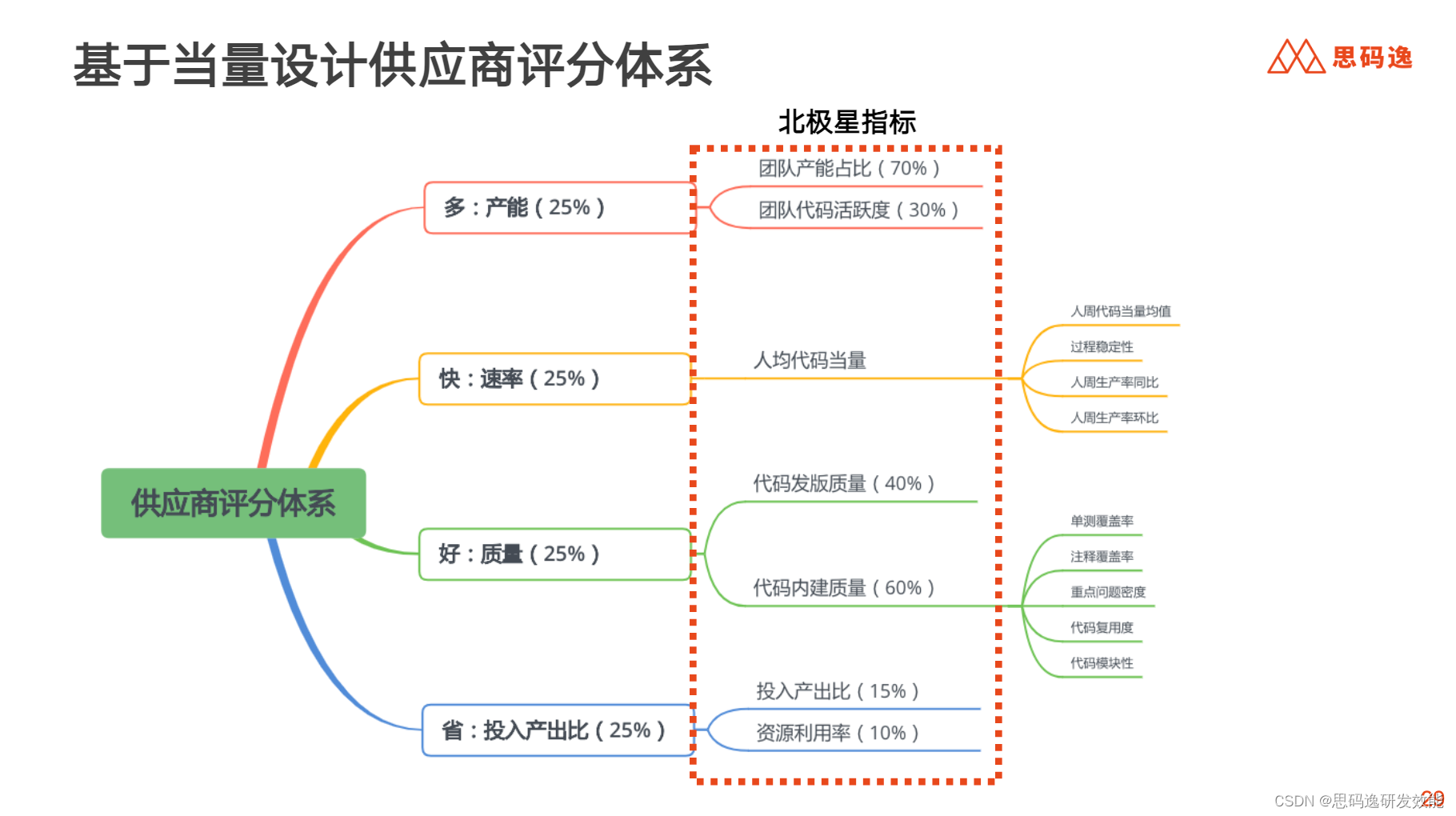
另一个问题就是,他们有大量的外包团队,他们对这些团队的管理不是很到位,缺少体系化的度量,无法准确判断外包整体的效率。针对这个问题,我们基于代码当量,帮助他们设计了一个供应商评分体系。
如下图显示,我们可以理解为这就是通过代码当量来计算出的研发产能。图中显示的是代码产能与需求个数的拟合曲线。拟合优度大于 60%的时候,就代表这个团队的工作产能是可预测的。对于不可预测的团队,我们可能要去找原因,为什么这周产出多,下周产出少。如果大家都处于比较稳定的水平时,就可以知道每个团队交付的贷款是多少。
 另外一点是从需求的角度进行分析。如下图右侧所示,你可以看到一些稳定性较高的需求,我们可以通过他们来预估各个需求的工作量。根据刚刚的交付贷款和工作量的预测,就可以计算出应该怎么做资源的配比。
另外一点是从需求的角度进行分析。如下图右侧所示,你可以看到一些稳定性较高的需求,我们可以通过他们来预估各个需求的工作量。根据刚刚的交付贷款和工作量的预测,就可以计算出应该怎么做资源的配比。
 下面这张图是我们基于客户的需求设计的评分体系。比如在产能方面,我们不只是看代码当量的产出,还会看代码活跃度;在质量方面会看发版的质量、底层的质量,这样可以一目了然每个供应商的表现如何。
下面这张图是我们基于客户的需求设计的评分体系。比如在产能方面,我们不只是看代码当量的产出,还会看代码活跃度;在质量方面会看发版的质量、底层的质量,这样可以一目了然每个供应商的表现如何。
 现场Q&A
现场Q&A
提问 对于需求工作量的预测,你们是基于什么逻辑来做的?如果要预测需求的工作量,对我们的要求是什么?
回答 这里讲的需求更多是开发的需求。由于每个产品经理拆需求的时候大小不一。所以我们的逻辑是,基于代码当量,来度量一遍历史的需求,能看出每个需求的代码当量是多少,比如这个需求是 1000 当量,另一个是 500 当量。如果需求的当量相对稳定,那就可以预估之后这个需求大概是怎样的量级,它的偏差幅度在 10%-20%以内,是可以评估这个需求大概需要多少工作量。然后结合我们对团队交付能力的评估,比如一个团队一周能交付 500 当量,或 1000 当量的代码,那么这个需求就需要这个团队一周的时间来完成。
如果发现需求拆分的颗粒度大小不一,那么就需要溯源,查找原因,调节拆分需求的逻辑和方法。
可访问 链接 获取 演讲PDF









