
需要本项目的可以私信博主!!!
本项目包含:PPT,可视化代码,项目源码,配套Hadoop环境(解压可视化),shell脚本,MapReduce代码,文档以及相关说明教程,大数据集!
本文介绍了一种基于Hadoop的网站日志大数据分析方法。本项目首先将网站日志上传到HDFS分布式文件系统,然后使用MapReduce进行数据预处理。通过使用Hive进行大数据分析,我们能够对网站的PV、独立IP、用户注册数和跳出用户数等重要指标进行统计分析。最后,我们使用Sqoop将分析结果导出到MySQL数据库,并使用Python搭建可视化界面,以方便用户对分析结果进行更直观的理解。
通过使用Hadoop分布式计算框架,本项目可以高效地处理大量的网站日志数据。使用MapReduce进行预处理能够有效地减少数据量,并进行初步的数据清洗和筛选。在使用Hive进行大数据分析时,我们可以通过编写复杂的SQL查询语句,快速地获取需要的数据,并对这些数据进行深入的统计分析。
通过本项目,我们可以快速准确地获取网站的关键指标数据,帮助企业更好地了解用户行为,优化网站运营策略,提升用户体验。同时,本项目的数据导出和可视化功能也为用户提供了更方便、直观的数据展示方式,使得数据分析结果更易于理解和使用。
此处省略......
1.1 研究背景
随着互联网技术的发展,越来越多的企业将其业务转移到了线上。网站是企业展示自身品牌形象,提供产品或服务的重要平台,而网站日志是记录网站活动的重要数据源。
此处省略......
1.2 研究目的
本文旨在探讨基于Hadoop对网站日志进行大数据分析的研究目的。随着互联网的普及,网站的流量日益增大,大量的网站日志数据被生成。这些数据包含了大量的信息,可以帮助网站管理者了解用户的行为和需求,为网站的优化和改进提供有价值的参考。
此处省略......
1.3 研究意义
本文旨在探讨基于Hadoop对网站日志进行大数据分析的研究意义。随着互联网的不断发展,越来越多的网站日志数据被生成,这些数据包含了大量的信息,可以为网站的优化和改进提供有价值的参考。因此,本文研究的意义在于:
此处省略......
1.4 国内外研究现状分析
随着大数据时代的到来,越来越多的企业开始关注如何利用大数据进行网站日志分析,以从中获得商业价值。而Hadoop作为一种分布式计算框架,可以用于对大规模数据进行处理和分析。本文将对基于Hadoop对网站日志进行大数据分析的国内外研究现状进行分析。
一、国内研究现状:
此处省略......
二、国外研究现状:
此处省略......
2 研究过程
2.1 总体研究路线
本文基于Hadoop对网站日志大数据集进行离线分析,最初首先必须要搭建一个Hadoop分布式系统,安装好本研究所需要的各类组件。在部署好Hadoop之后,首先将日志数据上传到hdfs分布式文件系统上,采用MapReduce的思想,利用Python编写Map和Reduce脚本程序,对原始数据进行清洗。
将网站日志数据清洗为结构化的数据之后,然后保存在hdfs中,之后在hive里面进行建表和数据导入操作,借助大数据分析组件hive对其进行统计学分析,挖掘出常用的一些业务指标,其次利用Hadoop中的sqoop组件将hive中的分析结果表导入到mysql中,或者将结果存入到hbase中。最终通过Python的Pyecharts的可视化库对其进行可视化,在web页面展示出统计出来的业务指标。
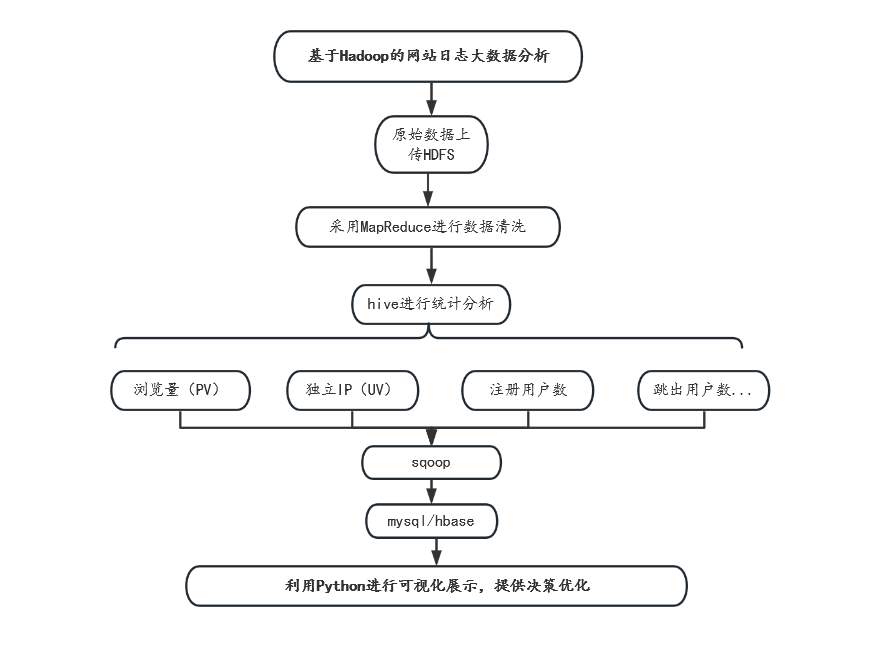 图1.1 总体研究路线图
图1.1 总体研究路线图
如下图所示,通过这样一系列的操作和流程,可以将大数据分析展现到决策者的眼前。
图1.2 技术开发流程图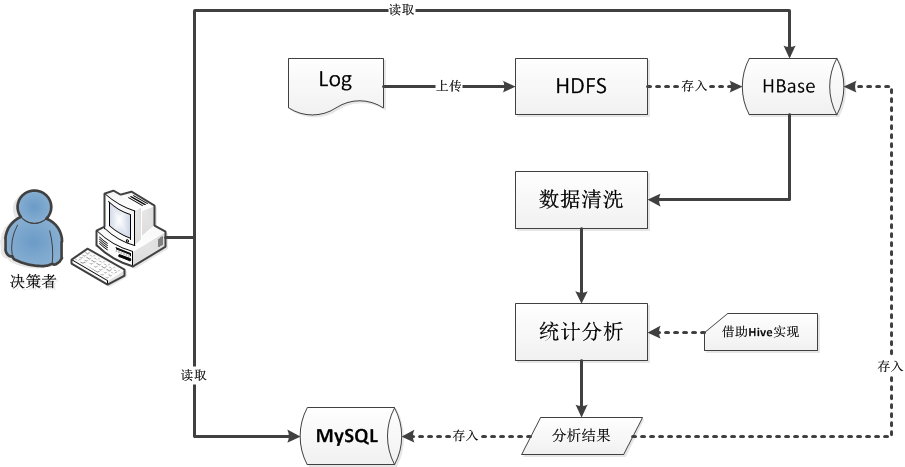
2.2 搭建Hadoop环境系统
本研究通过搭建Hadoop伪分布式系统,对其进行大数据分析。可以学习Hadoop的基本原理和架构,对Hadoop的运行机制有更深入的了解。能够在单机上模拟多节点的分布式环境,可以更好地测试和开发分布式应用程序。可以充分利用自己的计算资源,提高数据处理效率。
2.2.1 Hadoop部署及各类组件安装
由于Hadoop的部署和安装各类组件比较繁琐,这里就不作具体的详细的安装部署描述了。本研究通过前期花费时间对其进行各类组件安装,并将其结果图展示如下所示:

图2.1 Hadoop安装展示
|
|
|

图2.2 Hadoop集群启动及hive安装展示
Hadoop中的各类结点特点及解释如下:
(1)NameNode它是Hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问。
(2)Secondary NameNode是一个用来监控HDFS状态的辅助后台程序。
(3)DataNode它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个 datanode守护进程。
(4)NodeManager:YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点,包括与ResourceManger保持通信,监督Container的生命周期管理,监控每个Container的资源使用(内存、CPU等)情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务(auxiliary service)。
(5)ResourceManager:在YARN中,ResourceManager负责集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是ApplicationManager)RM与每个节点的NodeManagers (NMs)和每个应用的ApplicationMasters (AMs)一起工作。
|
|
|

图2.3 mysql及sqoop安装展示
Hadoop是一个分布式计算框架,可以存储和处理大规模数据集。Sqoop和MySQL是两个常用于Hadoop生态系统中的组件。
Sqoop是一个用于将关系型数据库中的数据导入到Hadoop生态系统中的工具。它支持多种关系型数据库(如MySQL、Oracle、PostgreSQL等),可以将关系型数据库中的数据转换为Hadoop生态系统中的数据格式(如HDFS、Hive、HBase等)。Sqoop还支持增量导入和导出,以及自定义导入查询。
MySQL是一种开源的关系型数据库管理系统,被广泛应用于Web应用程序的开发。在Hadoop生态系统中,MySQL通常用于存储与Hadoop数据相关的元数据和其他信息。MySQL可以通过Hadoop的MapReduce作业来查询和处理数据,也可以与Sqoop一起使用,将关系型数据导入到Hadoop生态系统中。
上述就已经对本次研究所需要的基本组件完成了安装和部署,旨在为后续的研究过程准备良好的环境基础。
2.3 数据集介绍
本次研究的数据日志来源于国内某技术学习论坛,该论坛由某培训机构主办,汇聚了众多技术学习者,每天都有人发帖、回帖。通过获取开源的数据集日志,其中包括2013-05-30和2013-05-31这两天的网站日志数据,其中每行记录有5部分组成:访问者IP、访问时间、访问资源、访问状态(HTTP状态码)、本次访问流量。
 图3.1 日志数据展示
图3.1 日志数据展示
该数据字段具有不规则的特点,基于Hadoop大数据分析hive进行结构化统计分析,需要进一步对数据进行预处理,由于本数据量非常大,从数据的容量来看两天的日志文件大小一共是200MB,30号的数据量约是55W左右,31号的数据量是140W左右,总数据量约接近200W的数据,从大数据的角度来看,已经符合了大数据模拟分析的要求,传统的分析软件对其进行处理已经达不到高效率的特点了。
通过Python进行编写MapReduce脚本,对数据日志进行数据流处理和清洗,最终解决数据的不规则。
2.4 MapReduce数据预处理
2.4.1 MapReduce原理介绍
MapReduce是一种分布式计算模型,由Google公司于2004年提出,旨在通过将大规模数据集分解为小的数据块,然后在分布式计算集群中进行并行计算,以实现高效的大规模数据处理。MapReduce模型的核心思想是将数据分成小的块进行处理,以及将计算分成两个阶段,即“映射”和“归约”。
此处省略......
图4.1 MapReduce编程模型图
MapReduce的主要特点包括以下几点:
此处省略......
MapReduce是一种高效、稳定、可扩展的分布式计算模型,已被广泛应用于各种大数据处理场景中。
图4.2 Mapper.Py展示
上述代码的思想就是对日志文件中的每一行进行解析
此处省略......
图4.3 Reducer.Py展示
这段代码是一个Hadoop中Reducer的Python实现。
此处省略......
图4.4 数据预处理结果 
处理好的数据用于后续的大数据分析,在执行对应的shell文件之后
此处省略......
图4.5 MapReduce执行shell脚本展示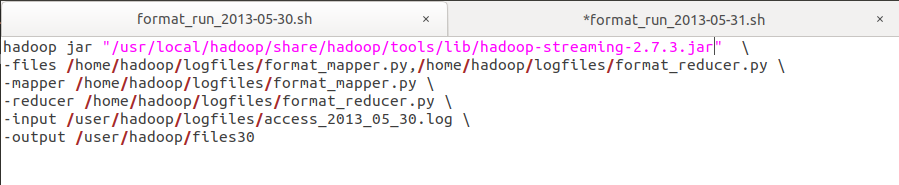
最终通过执行我们的脚本文件,可以用source或者./ 命令
图4.6 MapReduce执行结果展示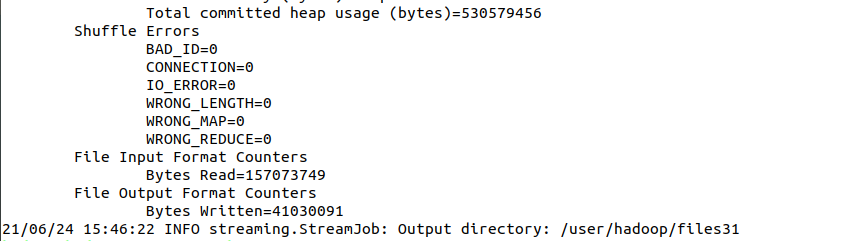
2.4 Hadoop基本组件及其介绍
2.4.1 Hive的基本概念
此处省略......
2.4.2 HDFS的基本概念
此处省略......
2.4.3 Sqoop的基本概念
此处省略......
2.4.4 MySQL的基本概念
此处省略......
2.5 建立数据库表与导入
根据结果文件结构建立hive数据库表,在结果文件上创建分区表。首先把清洗后的文件放在我们自己设定的文件夹里面,在hive里面进行创建表格,这里创建一个分区表,create external table 表名(字段 字段类型…..)partitioned by (分区字段 字段类型) rowformat delimted fields terminated by ‘分割符’,location 数据路径的祖文件夹(不包含数据的直接存储文件夹)。
建表语句如下:
CREATE EXTERNAL TABLE whw(ip string, atime string, url string) PARTITIONED BY (logdate string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LOCATION '/user/hadoop/data';
2.5.1 分区分桶的概念
在Hive建立数据表时,为了提高查询效率和降低查询成本,常常会选择建立分区表。分区表是将数据按照某一列进行分区,将相同的数据分组存储在不同的文件夹或目录中,以实现更加高效的数据查询和处理。
分区的概念是将数据按照某一列的值进行分组,可以将数据存储在不同的文件夹或目录中,以提高查询效率。在Hive中,常用的分区字段包括日期、时间、地区、城市、性别等。例如,如果将销售数据按照日期进行分区,可以将每一天的销售数据存储在不同的目录中,以便快速查询每一天的销售情况。
除了分区之外,Hive还提供了另外一种数据组织方式,即分桶。分桶是将数据按照某一列的哈希值进行分组,将相同哈希值的数据存储在同一个文件中,以实现更加高效的数据查询和处理。分桶相对于分区来说,更适用于数据量较大,且数据分布较为均匀的场景。
分区和分桶的优势在于可以提高数据查询和处理的效率,降低查询成本。通过将数据按照某一列进行分组存储,可以减少查询时需要扫描的数据量,提高查询速度。此外,分区和分桶还可以用于优化数据的存储和压缩,减少存储和传输成本。分区和分桶可以根据实际数据的特点来选择使用,以实现更加高效的数据查询和处理。
本次研究,我们就是按照日期进行分区,最终可以提高我们的查询效率。
2.5.2 分区数据集的导入
建立分区语句:
Alter table 表名 add partition(分区字段=‘分区标签’)location 数据路径(数据文件的父文件夹)
ALTER TABLE whw ADD PARTITION(logdate='2022_05_30') LOCATION '/user/hadoop/data/datas';
图5.1 分区表导入执行结果展示
图5.2 查询数据导入结果展示
分别按照上述的思想和步骤,对其两天的数据导入到hive中,接下来我们就是通过hive查询我们需要的数据。
2.6 Hive统计分析
使用Hive对结果表进行数据分析统计,在这之前我们需要这几个网页指标进行了解,清除这些指标具体代表的含义和意义,以及对其网站的优化建设提出对应的措施。
2.6.1 PV指标介绍以及统计
PV(Page View)是指网站页面的浏览量,即网站上所有页面被访问的次数总和。在网站分析中,PV是最基本的指标之一,用来衡量网站的流量和受众规模。
在网站场景中,PV的含义是指用户访问网站的页面次数,每打开一个页面都算作一次PV。例如,一个用户在访问某个网站时,浏览了首页、文章列表、文章详情等多个页面,这些页面的浏览次数总和即为PV。
|
|
| 图6.1 PV指标查询统计 |


2.6.2 注册用户数指标介绍与统计
此处省略......
|
|
| 图6.2 注册用户数指标查询统计 |


2.6.3 独立IP数指标介绍与统计
此处省略......
|
|
| 图6.3 独立IP数指标查询统计 |


2.6.4 跳出用户数指标介绍与统计
跳出用户数是指在访问网站的某个页面后没有继续访问其他页面而直接离开网站的用户数量。这个指标通常用于衡量网站的用户体验和吸引力。如果跳出用户数过高,说明用户对网站的内容或体验不感兴趣或不满意,需要进行优化。
此处省略......
|
|
| 图6.4 跳出用户数指标查询统计 |


2.6.5 数据表汇总
内连接表示查询两个表的交集,而且ON的条件为 1=1 就表示连接条件永远成立,这里使用将所有的查询结果汇总到一张数据表里面。
|
|
| 图6.5 数据表汇总操作展示 |


2.7 数据导出与数据展示
2.7.1 MySQL中创建表格
使用mysql -u root -p(启动MySQL,需要输入密码,不显示),在使用mysql进行数据的创建的时候需要使用数据库。创建命令如下:
create table whw_logs_stat(logdate varchar(10) primary key,pv int,reguser int,ip int,jumper int);
图7.1 mysql数据表的创建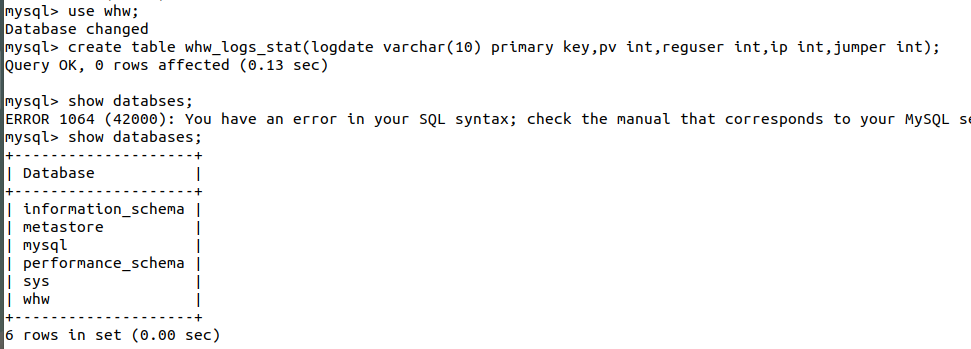
2.7.2 Sqoop将hive表导入mysql
使用sqoop将我们的hive里面的结果表导入到我们的MySQL里面,使用sqoop export –connect jdbc:mysql://localhost:3306/数据库 –username root -p –table MySQL里面的表名 –export-dir hive里面结果表的存储位置 -m 1 –input -fields-terminated -by ‘\001’
注意的是,这里需要在终端新开一个,然后使用该命令的方法,将hive数据表导入到mysql中。并且需要提前知道我们的hive数据表存在的位置,也就是在hdfs中hive数据表存在的位置。
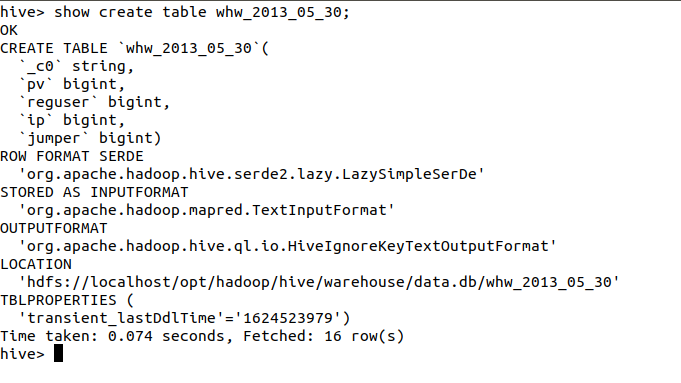
图7.2 hive数据表的位置
图7.3  sqoop执行结果展示
sqoop执行结果展示
最后我们在进入到mysql终端界面查看 数据已经导入成功了。

mysql最终表展示
2.7.3 数据可视化
使用数据可视化工具,将数据转换成图表、表格、地图等可视化形式,可以让数据更加直观、易于理解和分析,避免了仅依靠数字和文字所带来的困难。
此处省略......
 数据可视化展示
数据可视化展示
代码省略,请私信博主!!!
3 总结与分析
3.1 本研究创新之处
此处省略......
3.2 本研究有待改进之处
此处省略......
4 结论
本项目基于Hadoop平台,通过MapReduce进行网站日志数据的预处理,利用Hive进行大数据分析,实现了对网站PV、独立IP、用户注册数、跳出用户数等指标的统计分析。最后,将统计结果通过Sqoop导出到MySQL数据库,并利用Python搭建可视化平台,展示数据分析结果。
此处省略......
每文一语
与其满而溢,不如适可而止







