前言
随着电商平台的兴起,越来越多的人开始在网上购物。而对于电商平台来说,商品信息、价格、评论等数据是非常重要的。因此,抓取电商平台的商品信息、价格、评论等数据成为了一项非常有价值的工作。本文将介绍如何使用Python编写爬虫程序,抓取电商平台的商品信息、价格、评论等数据。
一、准备工作
在开始编写爬虫程序之前,我们需要准备一些工具和环境。
Python3.8
PyCharm
二、分析目标网站
在开始编写爬虫程序之前,我们需要先分析目标网站的结构和数据。在本文中,我们选择抓取京东商城的商品信息、价格、评论等数据。
1.商品信息
-
商城的商品信息包括商品名称、商品编号、商品分类、商品品牌、商品型号、商品规格、商品产地、商品重量、商品包装等信息。这些信息可以在商品详情页面中找到。
-
价格
商城的商品价格包括商品原价、商品促销价、商品折扣等信息。这些信息可以在商品详情页面中找到。 -
评论
京东商城的商品评论包括用户评价、用户晒图、用户追评等信息。这些信息可以在商品详情页面中找到。
三、编写爬虫程序
在分析目标网站的结构和数据之后,我们可以开始编写爬虫程序了。在本文中,我们使用Scrapy框架编写爬虫程序,将抓取到的数据保存到MySQL数据库中。
-
创建Scrapy项目
首先,我们需要创建一个Scrapy项目。在命令行中输入以下命令:
scrapy startproject jingdong
这将创建一个名为jingdong的Scrapy项目。
-
创建爬虫
接下来,我们需要创建一个爬虫。在命令行中输入以下命令:
scrapy genspider jingdong_spider jd.com
这将创建一个名为jingdong_spider的爬虫,爬取的网站为jd.com。
-
编写爬虫代码
在创建完爬虫之后,我们需要编写爬虫代码。在Scrapy框架中,爬虫代码主要包括以下几个部分:
(1)定义Item
Item是Scrapy框架中的一个概念,它用于定义要抓取的数据结构。在本文中,我们需要定义一个Item,用于保存商品信息、价格、评论等数据。在项目的items.py文件中,添加以下代码:
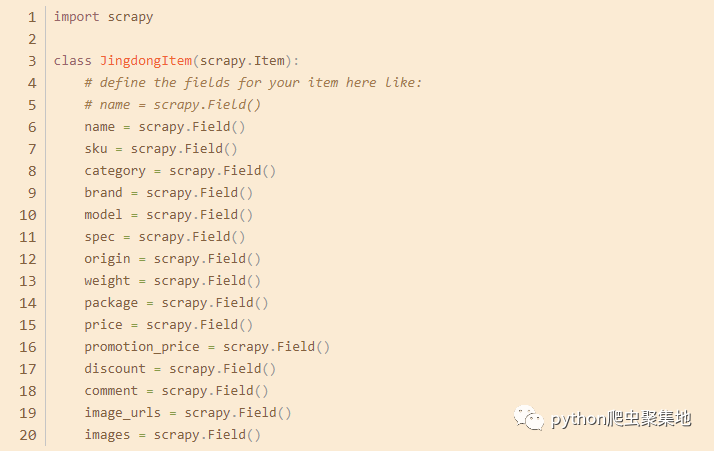
这里定义了一个名为JingdongItem的Item,包括商品名称、商品编号、商品分类、商品品牌、商品型号、商品规格、商品产地、商品重量、商品包装、商品价格、商品促销价、商品折扣、商品评论、商品图片等字段。
(2)编写爬虫代码
在项目的spiders目录下,打开jingdong_spider.py文件,添加以下代码:

这里定义了一个名为JingdongSpider的爬虫,首先获取所有分类链接,然后依次访问每个分类页面,获取所有商品链接,然后依次访问每个商品页面,抓取商品信息、价格、评论等数据,并保存到Item中。
(3)配置数据库
在项目的settings.py文件中,添加以下代码:
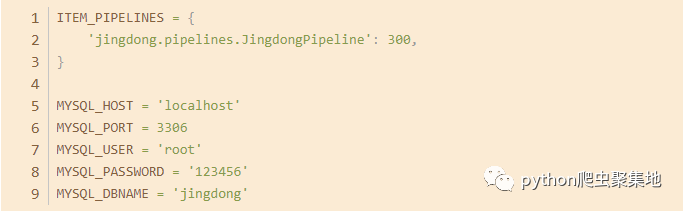
这里定义了一个名为JingdongPipeline的管道,用于将抓取到的数据保存到MySQL数据库中。同时,配置了MySQL数据库的连接信息。
(4)编写管道代码
在项目的pipelines.py文件中,添加以下代码:
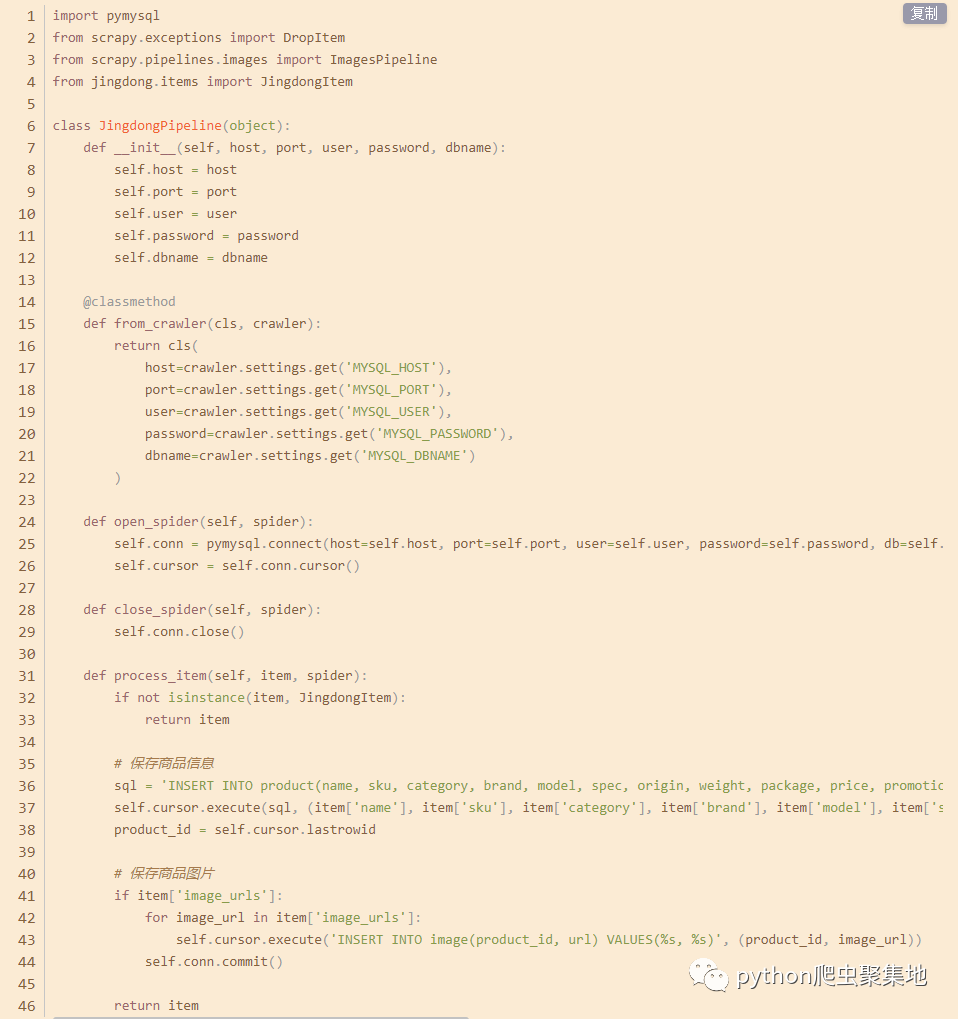
这里定义了一个名为JingdongPipeline的管道,用于将抓取到的数据保存到MySQL数据库中。在process_item方法中,首先保存商品信息到product表中,然后保存商品图片到image表中。
(5)配置图片下载
在项目的settings.py文件中,添加以下代码:
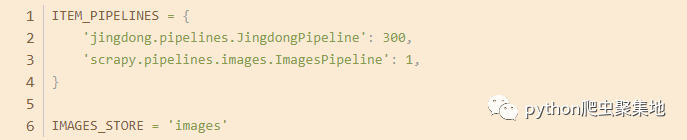
这里配置了图片下载的管道和存储路径。
(6)运行爬虫
在命令行中输入以下命令,运行爬虫:
![]()
这将启动爬虫程序,开始抓取京东商城的商品信息、价格、评论等数据,并保存到MySQL数据库中。
五、总结
本文介绍了如何使用Python编写爬虫程序,抓取电商平台的商品信息、价格、评论等数据。通过本文的学习,您可以了解到Scrapy框架的基本使用方法,以及如何将抓取到的数据保存到MySQL数据库中。同时还可以学习到如何模拟浏览器的行为,抓取动态页面的数据。希望本文对您有所帮助。









