
在实现进度条之前我们要了解一些有关实现进度条的知识。例如回车和makefile的使用
自动化构建工具:makefile
makefile实现的目的就是可以进行自动化的编译与自动化清理,即实现好了makefile之后,仅仅使用make指令就可以直接完成程序的编译过程。
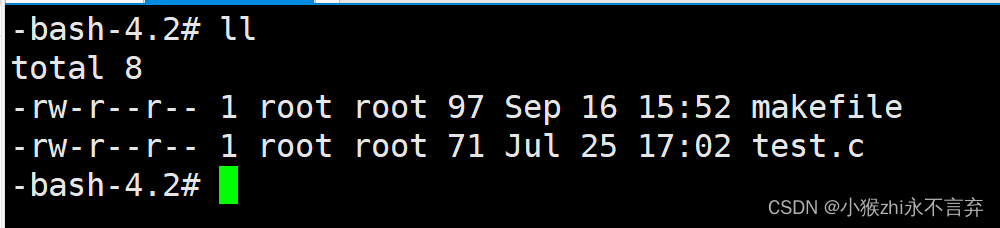
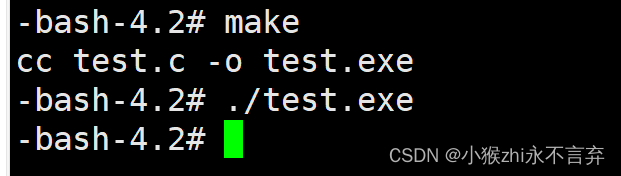
先看一看咱们实现makefile之后得到的效果截图:
这里make指令的过程就相当于代替了gcc test.c -o test.exe 这一条指令。然后就是就得到了可执行程序test.exe。
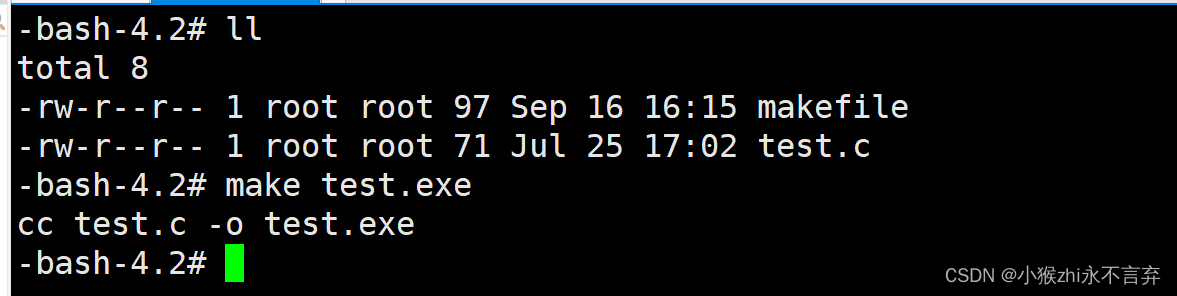
接下来进行清理:
此时就删除了新生成的可执行程序test.exe

makefile的实现
先将目光 聚集到前三行,这三行就相当于是C语言中typedef进行的重命名工作,但是vim中在使用时区别的就是形式上:$(typedef_name)。而这里需要了解一下依赖关系和依赖方法,看到有数据的第四行和第五行:$(dest):$(src),这里表示的含义就是:test.exe的实现是依赖于test.c,而$(dest)就被称作目标文件,$(src)被称作依赖文件。依赖的方法也就是将依赖文件变成目标文件的,也就是:cc $^ -o $@也就是编译的过程,而 $^ 和 $@有分别代表的是什么呢???
$^代表的是上一行的依赖文件(右边),$@代表的是上一行的目标文件(左边)。
但是有些过程是不需要依赖文件的,列入clean:的过程,仅仅是进行可执行程序的删除功能,所以并不需要依赖什么文件去执行这一过程。
还有一点就是为什么编译文件时输入make指令就行,而清除的过程需要,make clean,这其实就关乎于你makefile中的实现顺序,因为我是先实现编译的过程,所以就可以省略make后面的文件名,加上也行:
所以这里不用太在意谁先谁后。
最后再谈谈.PHONY:clean这一行命令是干啥的???
先看一下下面的两个场景:
1.
当我在已经形成好了可执行程序test.exe之后,再次想要编译就拒绝了。
2.
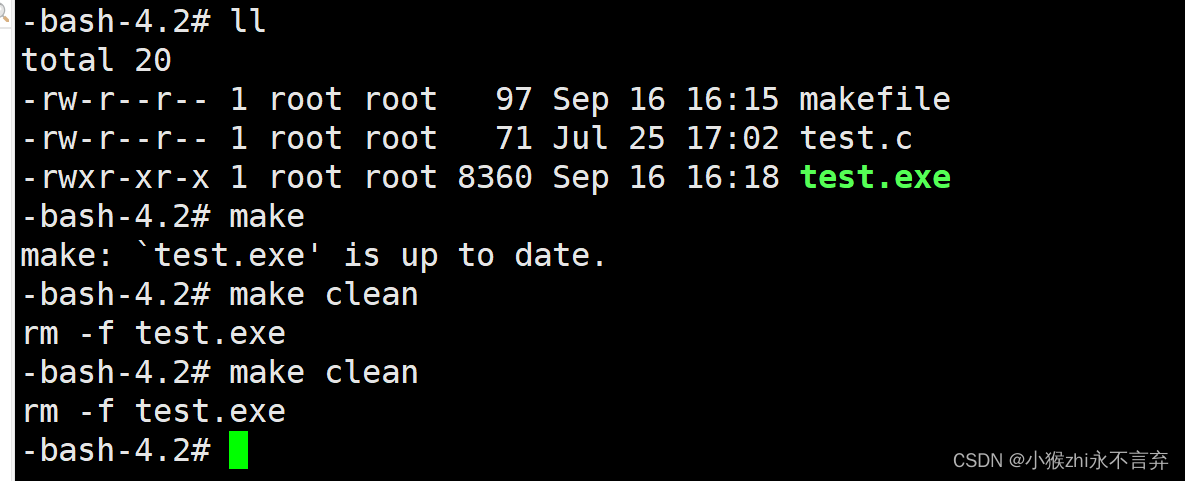
而make clean命令就可以一直被执行,尽管已经删除了该文件,可是依旧可以一直执行该命令。其实这就与.PHONY的功能有关。(所以给文件编译也加上该行指令)
所以你会发现:.PHONY的作用就是(总是被执行的)也就是说,当执行到该命令时不会判断,而是始终执行(这里用到了判断,后面会进行概括)
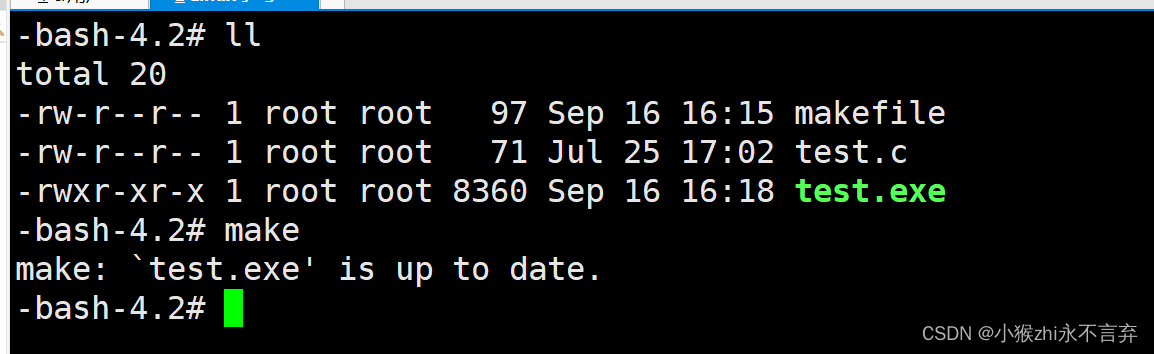
如果你细心的话,将.PHONY:clean删除的话,所能够执行的效果是不是就不会总是被执行呢??其实还是会的,进行清除的时候不需要做任何的判断,但是编译一个文件需要,这取决于文件的新旧:
也就是说只有新文件才能被编译,旧文件(也就是被编译过的文件并不会进行二次编译的过程)
但是既然要判断新旧的话,那自然是少不了进行对比,只有进行对比才可以判断出文件的新旧,所以就引入了文件的时间属性:



文件的时间属性
一个文件具有三种时间:
- Access time:文件的最近一次的访问时间
- Modify time:文件的最近一次的内容修改时间
- Change time:文件的最近一次属性修改的时间
可以用stat+file_name进行查看文件的三个时间属性:

Modify
而我们对文件进行 ll(ls-l) 命令时查看到的是文件的什么时间呢??(可以采用控制变量的方法去逐一改变各个时间)
其实ll+文件的时候展开的其实就是Modify time,也就是文件最近一次的内容修改时间。
所以这里可想而知作为一个文件最具有代表性的时间肯定就是Modify time(文件最近一次内容修改的时间)
所以回归到问题,一个文件什么时候可以再次被进行编译呢??当然是一个新文件,也就是文件的Modify time进行更新过,也就是源文件与可执行程序对比时间(Modify time)。

touch+一个现有文件: 更行文件的各个时间,如果想改变某一个特定时间就-a(访问)-m(内容)-c(属)。
Change
还有一点就是文件的属性时间是比较特别的,也就是不论什么时间改变的话,文件的属性时间都会陪同一起进行更改

Assess
文件的访问时间也是一个特别的存在,访问文件可以说是对一个文件最频繁的操作,所以说,文件的Assess time经常会进行更改,但是实际上并不是这样。
我们知道文件是存放在硬盘当中,而硬盘又属于外设,所以相较于内设的访问效率会低很多,这就是为啥我们在打开文件时不直接在硬盘中进行而是将文件加载进入cpu,通过cou进行文件的访问,所以说,我们并不会实时的访问硬盘设备,也不会频繁的将文件加载进cpu,更不会没访问一次文件就更改一下文件的访问时间,什么时候更改可以说看你的计算机心情,每个计算机的心情肯定都不是一样的。
回车与换行
回车(\n):光标回到该行的起始位置处
换行(\r):光标换到下一行
回车换行(\n\r):光标进入下一行的行首位置处
其实windows下的回车键的功能就是执行的回车换行的功能
回车键(\r)的认识
但是还是得测试一下\r回车符(这里用到sleep休眠函数):
Test_1:
运行结果: 啥都没有输出
Test_2:
运行结果:字符‘h’数量变少了而且接下来的输入会覆盖调字符串h
结论:回车符(\r)的作用是使得光标回到该行的起始位置处,并且如果当下还有输出的数据会将原输出的内容逐一覆盖掉,Test_1中什么数据都没有输出是因为输出的字符串太短以至于被命令行给覆盖(就是下面这玩意)
所以导致啥结果输出都没有。





换行键(\n)的认识.
换行键其实还有一个隐藏功能:对缓冲区的数据进行行刷新
其实我们在键盘上进行输入的数据会先进入输入缓冲区里,而输出的数据也同样会先进入输出缓冲区,并不是直接在终端显示出来。但是换行符(\n)的作用恰恰就是对缓冲区的数据进行行刷新,所以会直接显示在终端中。
Test_1:
执行结果:会先将数据输出,然后休眠两秒再显示命令行
Test_2:
执行结果:先进行停顿两秒,再将缓冲区的数据打印到命令行中。
Test_3:
其实还有一种函数可以刷新缓冲区(流):fflush
我们缓冲区的数据其实默认放在流中,像输入缓冲区的数据就放在输入流(stdin),输出缓冲区的数据默认放在输出流(stdout)
执行结果:
所以相较于Test_1而言,该fflush可以满足不用输出不必要的换行符。








粗略实现进度条代码
其实实现进度条所用到的主要就是以上两大重点:makefile与换行键的使用。
同VS一样,也是使用不同的文件实现该进度条:

先看一下自动化构建工具makefile:

因为头文件会自动调用,所以在编译时就不需要编译头文件了。
主要就是看一下代码的实现了


这里其实是有很多可以改进的地方的,例如进度百分比可以用分数的形式 ,或者进度框里的字符换一下,卡顿一下等等
优化代码

这一版的优化就存在小数占比
再次优化


这次的效果就是可以模拟加载卡顿的情况

最终实现的代码完整版 (会的话可以直接跳过前面看这个)

这次不仅布局上优化,而且还会卡顿一下








