
前言
本项目专注于MovieLens数据集,并采用TensorFlow中的2D文本卷积网络模型。它结合了协同过滤算法来计算电影之间的余弦相似度,并通过用户的交互方式,以单击电影的方式,提供两种不同的电影推荐方式。
首先,项目使用MovieLens数据集,这个数据集包含了大量用户对电影的评分和评论。这些数据用于训练协同过滤算法,以便推荐与用户喜好相似的电影。
其次,项目使用TensorFlow中的2D文本卷积网络模型,这个模型可以处理电影的文本描述信息。模型通过学习电影的文本特征,能够更好地理解电影的内容和风格。
当用户与小程序进行交互时,有两种不同的电影推荐方式:
-
协同过滤推荐:基于用户的历史评分和协同过滤算法,系统会推荐与用户喜好相似的电影。这是一种传统的推荐方式,通过分析用户和其他用户的行为来推荐电影。
-
文本卷积网络推荐:用户可以通过点击电影或输入文本描述,以启动文本卷积网络模型。模型会分析电影的文本信息,并推荐与输入的电影或描述相匹配的其他电影。这种方式更注重电影的内容和情节相似性。
综合来看,本项目融合了协同过滤和深度学习技术,为用户提供了两种不同但有效的电影推荐方式。这可以提高用户体验,使他们更容易找到符合他们口味的电影。
总体设计
本部分包括系统整体结构图和系统流程图。
系统整体结构图
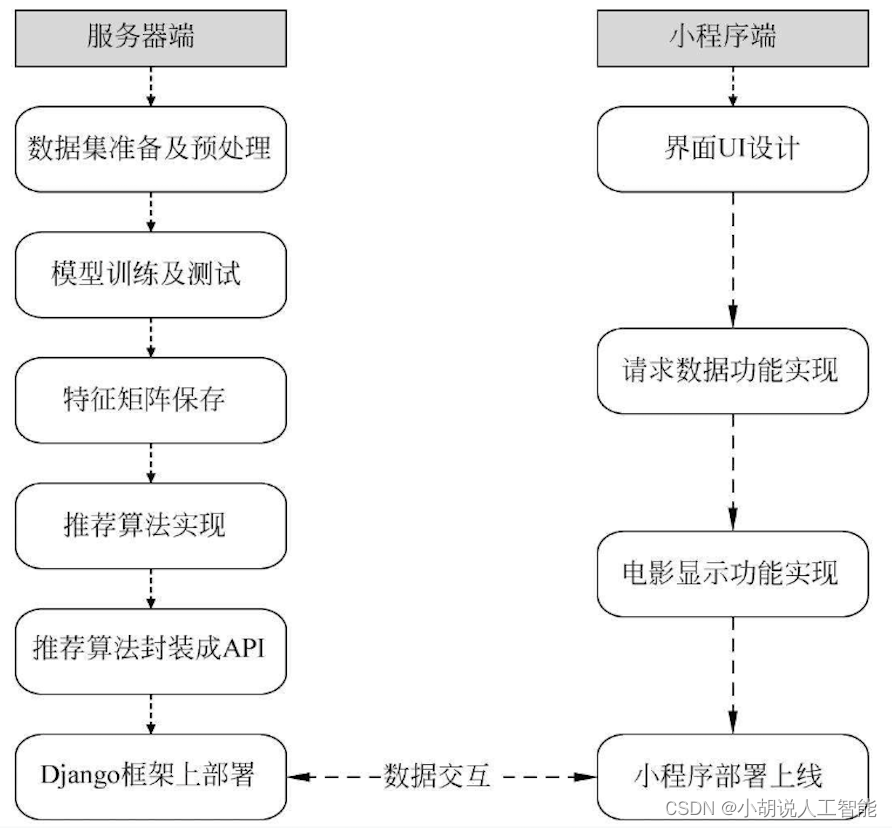
系统整体结构如图所示。
系统流程图
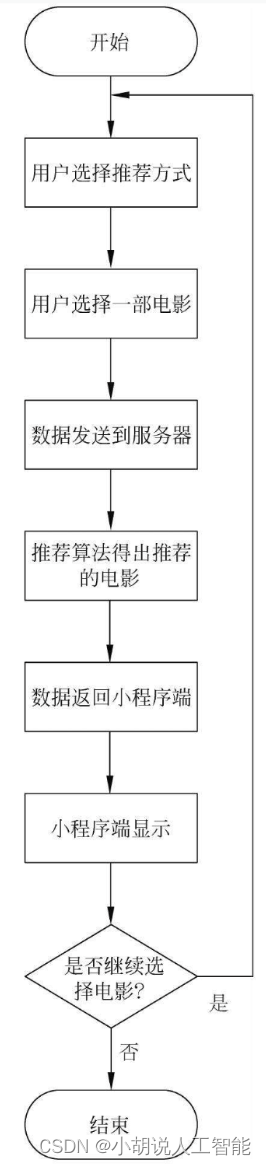
系统流程如图所示。
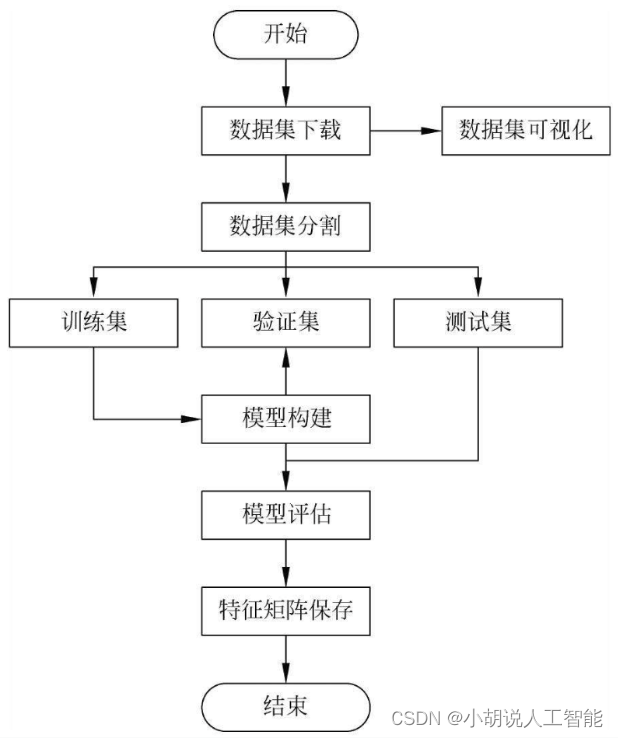
模型训练流程如图所示。
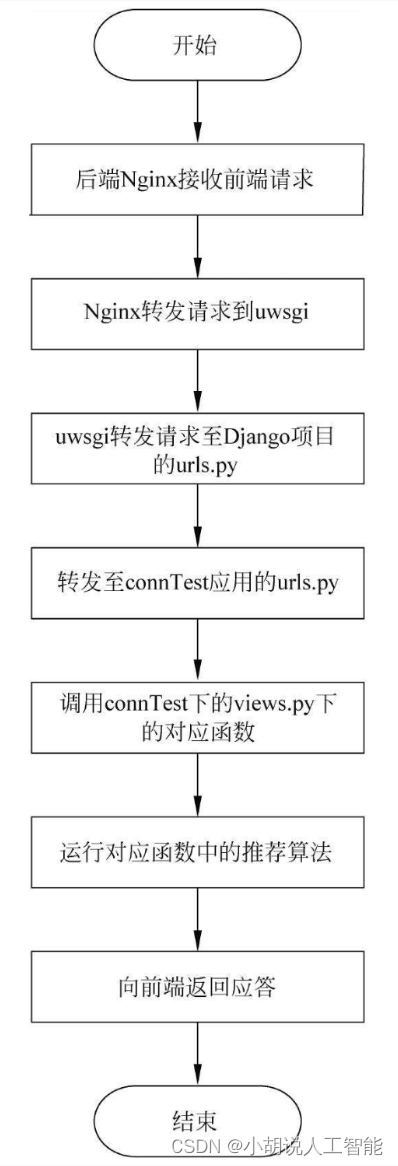
服务器运行流程如图所示。
运行环境
本部分包括Python环境、TensorFlow环境、 后端服务器、Django和微信小程序环境。
模块实现
本项目包括3个模块:模型训练、后端Django、 前端微信小程序模块,下面分别给出各模块的功能介绍及相关代码。
1. 模型训练
下载数据集,解压到项目目录下的./ml-1m文件夹下。数据集分用户数据users.dat、电影数据movies.dat和评分数据ratings.dat。
1)数据集分析
user.dat:分别有用户ID、性别、年龄、职业ID和邮编等字段。
数据集网站地址为http://files.grouplens.org/datasets/movielens/ml-1m-README.txt对数据的描述:
使用UserID、Gender、Age、Occupation、Zip code分别表示用户ID、性别、年龄、职业和邮政编码,M表示男性,F表示女性。年龄范围表示:
- 1: “Under 18”
- 18: “18-24”
- 25: “25-34”
- 35: “35-44”
- 45: “45-49”
- 50: “50-55”
- 56: “56+”
职业表示:
- 0: “other” or not specified
- 1: “academic/educator”
- 2: “artist”
- 3: “clerical/admin”
- 4: “college/grad student”
- 5: “customer service”
- 6: “doctor/health care”
- 7: “executive/managerial”
- 8: “farmer”
- 9: “homemaker”
- 10: “K-12 student”
- 11: “lawyer”
- 12: “programmer”
- 13: “retired”
- 14: “sales/marketing”
- 15: “scientist”
- 16: “self-employed”
- 17: “technician/engineer”
- 18: “tradesman/craftsman”
- 19: “unemployed”
- 20: “writer”
查看user.dat中的前5个数据,相关代码如下:
# 查看 users.dat
users_title = ['UserID', 'Gender', 'Age', 'OccupationID', 'Zip-code']
users = pd.read_table('./ml-1m/users.dat', sep='::', header=None, names=users_title, engine = 'python')
users.head()
结果如图所示。
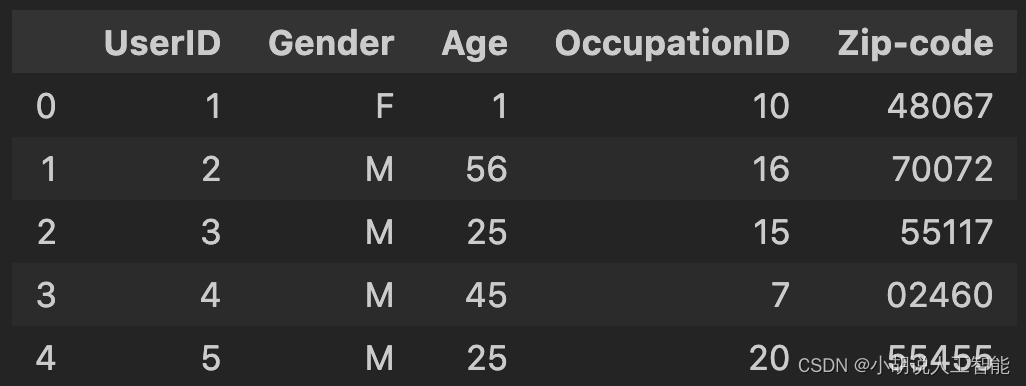
UserID、Gender、 Age和Occupation都是类别字段,其中邮编字段不使用。rating.dat数据分别有用户ID、电影ID、评分和时间戳等字段。数据集网站的描述: UserID范围为1~6040;MovieID范围 为1~3952;Rating表示评分,最高5星;Timestamp 为时间戳,每个用户至少20个评分。查看ratings.dat的前5个数据,结果如图所示,相关代码如下:
# 查看 ratings.dat
ratings_title = ['UserID','MovieID', 'Rating', 'timestamps']
ratings = pd.read_table('./ml-1m/ratings.dat', sep='::', header=None, names=ratings_title, engine = 'python')
ratings.head()
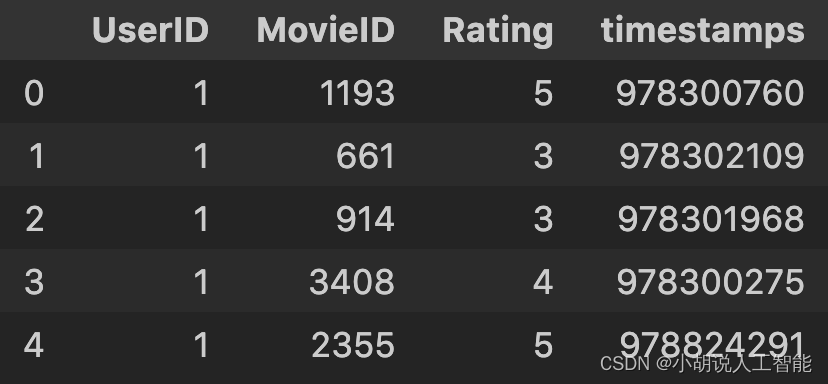
评分字段Rating是监督学习的目标,时间戳字段不使用。movies.dat数据集分别有电影ID、电影名和电影风格等字段。数据集网站的描述:
使用MovieID、Title和Genres ,其中MovieID和Genres是类别字段,Title是文本。Title与IMDB提供的标题相同(包括发行年份),Genres是管道分隔, 并且选自以下流派:

查看movies.dat中前3个数据,结果如图所示,相关代码如下:
# 查看 movies.dat
movies_title = ['MovieID', 'Title', 'Genres']
movies = pd.read_table('./ml-1m/movies.dat', sep='::', header=None, names=movies_title, engine = 'python')
movies.head()
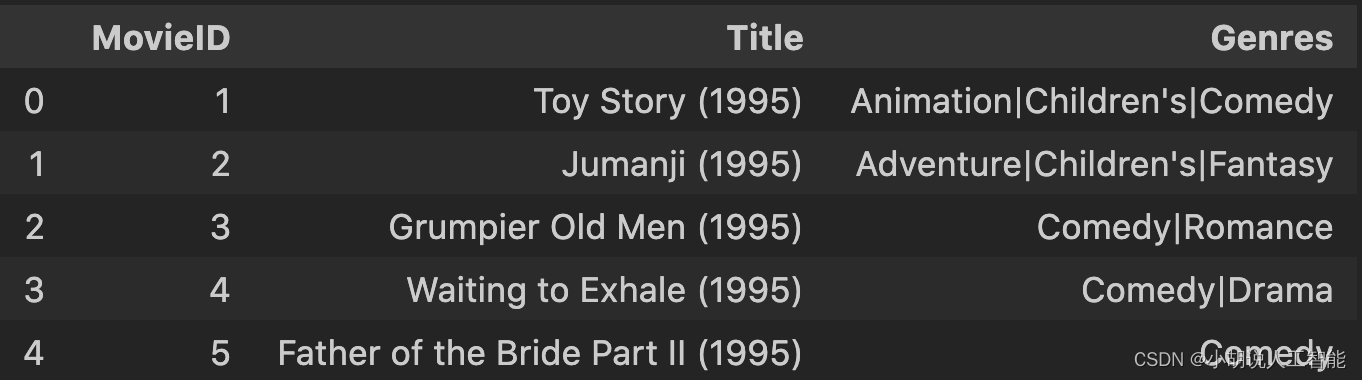
2)数据预处理
通过研究数据集中的字段类型,发现有一些是类别字段,将其转成独热编码,但是UserID、MovieID的字段会变稀疏,输入数据的维度急剧膨胀,所以在预处理数据时将这些字段转成数字。操作如下:
- UserID、Occupation和MovieID不变 。
- Gender字段:需要将F和M转换成0和1。
- Age字段:转成7个连续数字0~6。
Genres字段:是分类字段,要转成数字。将Genres中的类别转成字符串到数字的字典,由于部分电影是多个Genres的组合,将每个电影的Genres字段转成数字列表。
Title字段:处理方式与Genres-一样,首先,创建文本到数字的字典;其次,将Title中的描述转成数字列表,删除Title中的年份。
统一Genres和Title字段长度,这样在神经网络中方便处理。空白部分用PAD对应的数字填充。实现数据预处理相关代码如下:
#数据预处理
def load_data():
#处理 users.dat
users_title = ['UserID', 'Gender', 'Age', 'JobID', 'Zip-code']
users = pd.read_table('./ml-1m/users.dat', sep='::', header=None, names=users_title, engine = 'python')
#去除邮编
users = users.filter(regex='UserID|Gender|Age|JobID')
users_orig = users.values
#改变数据中的性别和年龄
gender_map = {'F':0, 'M':1}
users['Gender'] = users['Gender'].map(gender_map)
age_map = {val:ii for ii,val in enumerate(set(users['Age']))}
users['Age'] = users['Age'].map(age_map)
#处理 movies.dat
movies_title = ['MovieID', 'Title', 'Genres']
movies = pd.read_table('./ml-1m/movies.dat', sep='::', header=None, names=movies_title, engine = 'python')
movies_orig = movies.values
#去掉Title中的年份
pattern = re.compile(r'^(.*)\((\d+)\)$')
title_map = {val:pattern.match(val).group(1) for ii,val in enumerate(set(movies['Title']))}
movies['Title'] = movies['Title'].map(title_map)
#电影类型转数字字典
genres_set = set()
for val in movies['Genres'].str.split('|'):
genres_set.update(val)
genres_set.add('<PAD>')
genres2int = {val:ii for ii, val in enumerate(genres_set)}
#将电影类型转成等长数字列表,长度是18
genres_map = {val:[genres2int[row] for row in val.split('|')] for ii,val in enumerate(set(movies['Genres']))}
for key in genres_map:
for cnt in range(max(genres2int.values()) - len(genres_map[key])):
genres_map[key].insert(len(genres_map[key])+ cnt,genres2int['<PAD>'])
movies['Genres'] = movies['Genres'].map(genres_map)
#电影Title转数字字典
title_set = set()
for val in movies['Title'].str.split():
title_set.update(val)
title_set.add('<PAD>')
title2int = {val:ii for ii, val in enumerate(title_set)}
#将电影Title转成等长数字列表,长度是15
title_count = 15
title_map = {val:[title2int[row] for row in val.split()] for ii,val in enumerate(set(movies['Title']))}
for key in title_map:
for cnt in range(title_count - len(title_map[key])):
title_map[key].insert(len(title_map[key]) + cnt,title2int['<PAD>'])
movies['Title'] = movies['Title'].map(title_map)
#处理 ratings.dat
ratings_title = ['UserID','MovieID', 'ratings', 'timestamps']
ratings = pd.read_table('./ml-1m/ratings.dat', sep='::', header=None, names=ratings_title, engine = 'python')
ratings = ratings.filter(regex='UserID|MovieID|ratings')
#合并三个表
data = pd.merge(pd.merge(ratings, users), movies)
#将数据分成X和y两张表
target_fields = ['ratings']
features_pd, targets_pd = data.drop(target_fields, axis=1), data[target_fields]
features = features_pd.values
targets_values = targets_pd.values
return title_count, title_set, genres2int, features, targets_values, ratings, users, movies, data, movies_orig, users_orig
#加载数据并保存到本地
#title_count:Title字段的长度(15)
#title_set:Title文本的集合
#genres2int:电影类型转数字的字典
#features:是输入X
#targets_values:是学习目标y
#ratings:评分数据集的Pandas对象
#users:用户数据集的Pandas对象
#movies:电影数据的Pandas对象
#data:三个数据集组合在一起的Pandas对象
#movies_orig:没有做数据处理的原始电影数据
#users_orig:没有做数据处理的原始用户数据
#调用数据处理函数
title_count, title_set, genres2int, features, targets_values, ratings, users, movies, data, movies_orig, users_orig = load_data()
#保存预处理结果
pickle.dump((title_count, title_set, genres2int, features,
targets_values, ratings, users, movies, data,
movies_orig, users_orig), open('preprocess.p', 'wb'))
查看预处理后的数据,如图所示。
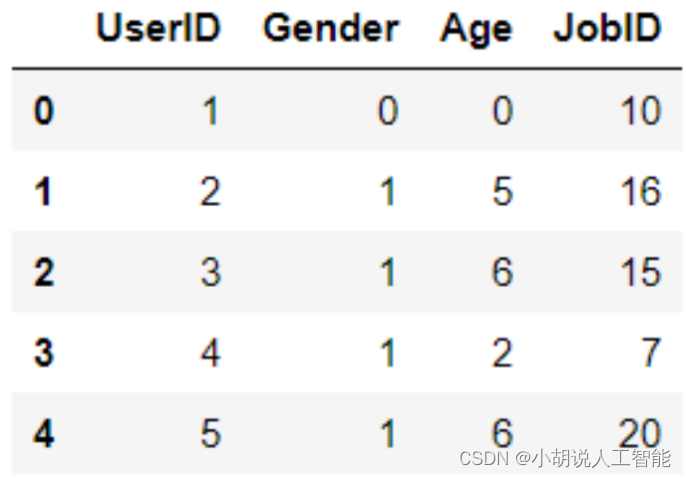
处理后的movies数据如图所示。

相关其它博客
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(一)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(三)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(四)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(五)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(六)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(七)
工程源代码下载
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。







