为什么写这篇文章?
老东西叫我用vmvare部署hadoop,我觉得这简直蠢毙了,让我们用docker和docker-compose来快速的过一遍如何使用docker-compose来部署简单的hadoop集群范例
写在前面,一定要看我!!!
还有注意!Hadoop中的主机名不能带-或者_
注意了!一定注意存储空间大小,确保机器至少有10G左右的空余,不然跑不起来的
-
如果出现如下问题,请调整docker-compose文件中分给容器的容量,然后删除并重建容器:
-
$ hdfs namenode
WARNING: /export/server/hadoop/logs does not exist. Creating.
mkdir: cannot create directory '/export/server/hadoop/logs': No space left on device
ERROR: Unable to create /export/server/hadoop/logs. Aborting.
Hadoop HDFS 简摘
Hadoop HDFS需要三个角色:
- NameNode,主节点管理者
- DateNode,从节点工作者
- SecondaryNameNode,主节点辅助
我们需要三个容器:
暂且称之为
masternode,slavenode1,slavenode2
这三个容器扮演的角色分别是
- masternode:NameNode,DateNode,SecondaryNameNode
- slavenode1:DateNode
- slavenode2: DateNode
使用脚本跳过所有的前置工作(假设你已经对Hadoop有了解)
注意!建立在你会的基础上,不会的话看着脚本敲命令
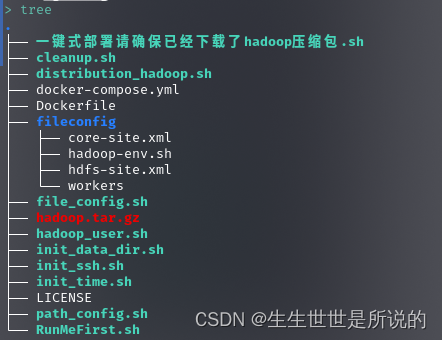
克隆项目后确保目录如:
git clone https://github.com/rn-consider/Hadoop_docker.git
然后确保使用docker-compose up -d 创建的容器也可以运行
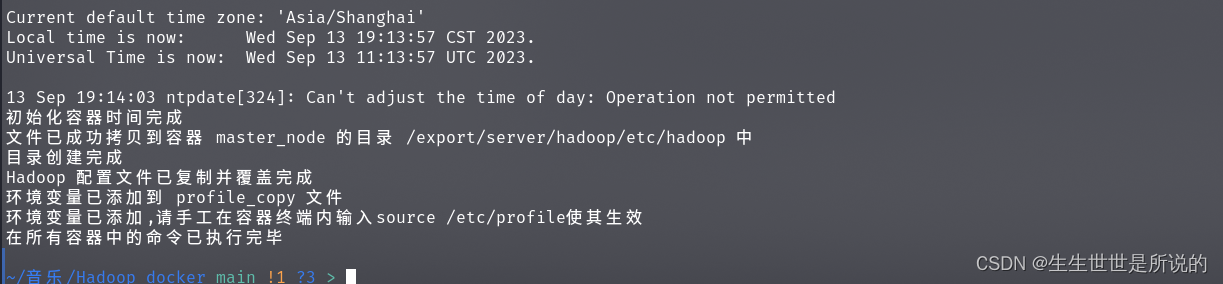
给所有sh脚本附加执行权限,然后运行./一键式部署请确保已经下载了hadoop压缩包.sh,然后等待脚本执行完成像是:
,完成后直接跳转到运行hadoop章节
前置工作
我们需要三个docker容器来实现masternode,slavenode1,slavenode2,它们需要一些基本的配置,比如说固定的Ip,ssh的安装,jdk8的安装等,所幸我们可以使用docker-compose来大大简化这些基本的配置工作,新建一目录假设命名为hadoop_t,然后按照以下命令,(注意!因为我们使用的是docker所以只需要按照我的步骤来且docker,docker-compose版本号满足要求,那么环境配置必然会成功)
-
git clone https://github.com/rn-consider/Hadoop_docker.git - 项目结构应该如,其中hadoop压缩包也可从官方获得,或者使用RumMeFirst下载在项目结构如下时在往下阅读:

- 确保机器上docker版本大于等于20.10.25,docker-compose版本大于等于2.20.3,不清楚docker-compose二进制安装方式可以看
- 为Linux安装软件包时后面标注的arm,aarch到底是什么玩意儿以二进制安装docker-compose为例_生生世世是所说的的博客-CSDN博客
- 运行docker-compose up -d 后运行docker ps可以看到:

- 接下来我们所有的环境设置都将在这三个容器中进行
环境配置
基本配置
主机名以及IP地址映射
docker-compose会自动创建docker网络和dns映射让各个容器可以通过容器的服务名来访问各自的容器,我们可以愉快的跳过这个配置
防火墙关闭
Docker 使用官方的 Ubuntu 镜像默认情况下不会启动防火墙,因为容器通常被设计成相对独立的环境。这意味着容器内的网络通信通常是不受防火墙限制的。
所以这一步我们也可以愉快的跳过.
SSH免密登录-注意是Hadoop用户间的免密登录
传统方式下我们进入每一台虚拟机并使用ssh-copy-id node1,node2...类似的方式,在docker下我们可以编写一个简单的shell脚本解决这个问题,只需要执行项目中的脚本就行:

时区同步设置
简单的执行shell脚本即可,我们使用
ntpdate来同步阿里云的ntp服务器
JDK以及HADOOP安装
我们的Dockerfile构建的镜像已经自动的安装了JDK8并将本地目录下的HADOOP压缩包复制解压到了容器中的/etc/export/hadoop下,我们也可以愉快的跳过这一步
masternode环境配置
也可直接运行脚本,直接拷贝放置在fileconfig目录下的配置文件:

-
我们可以看下HADOOP的文件夹结构:

我们要配置的文件在/etc/hadoop文件夹下,配置HDFS集群,我们主要涉及到以下文件的修改:
- workers: 配置从节点(DateNode)有哪些
- hadoop-env.sh: 配置Hadoop相关的环境变量
- core-site.xml: Hadoop核心配置文件
- hdfs-site.xml : HDFS核心配置文件
这些文件均存在于$HADOOP_HOME/etc/hadoop文件夹中.
ps:$HADOOP_HOME我们将在后续设置它,其指代Hadoop安装文件夹即/export/server/hadoop
-
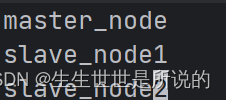
workers文件的修改
- 根据我们上面为三个容器分配的角色,我们在workers文件中填入:
-
hadoop-env.sh文件配置
- 如果使用我的项目,那么我们的配置都应该如,不用动脑复制粘贴即可:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64 # where we use apt download
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
- 配置core-site.xml文件
- 在configures中填入:

-
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://masternode:8020</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> </configuration>
- hdfs://masternode:8020为整个HDFS内部的通讯地址,应用协议为hdfs://(HADOOP内置协议)
- 表明DataNode将与masternode的8020端口通讯,masternode是NameNode所在机器
- 此配置固定了masternode必须启动NameNode进程
hdfs-site.xml配置
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>masternode,slavenode1,slavenode2</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>-
masternode配置结束,恭喜
准备数据目录
- 在masternode节点:
- mkdir -p /data/nn
- mkdir /data/dn
- 在剩余两个节点:
- mkdir -p /data/dn
脚本运行
分发Hadoop文件夹
- 使用vmvare这个步骤将会耗费很长时间,但使用docker的情况下我们使用一个简单的shell脚本解决问题

配置环境变量
- 为了方便操作HADOOP可以将HADOOP的一些脚本和程序配置到PATH中,方便后续使用
- 此处直接运行脚本,注意!由于docker容器的特性,你需要在进入容器终端时手动source以激活环境变量:

授权HADOOP用户-用户密码是123456
- 在Dockerfile中我们已经加上了创建Hadoop用户的代码
- 让我们来对Hadoop用户进行授权
- 依次进入每个容器并执行,并等待命令执行完成
-
chown -R hadoop:hadoop /data chown -R hadoop:hadoop /export chown -R hadoop:hadoop /home - 或者使用,这个脚本需要比较长的等待时间

运行HADOOP
所有前期准备全部完成,现在对整个文件系统执行初始化
进入masternode

别忘了source一下

- 格式化namenode
-
su - hadoop hdfs namenode -format - 出现这个对话框,输入Y

- 成功
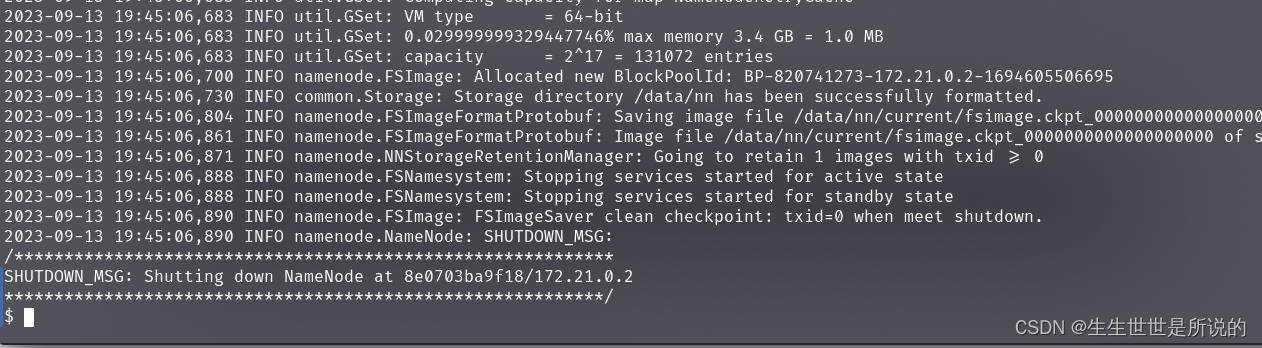
- 启动hadoop
- start-dfs.sh 启动

- 可以在/data/nn/current目录下看到数据这就说明hadoop启动成功

- 可以用JPS看到当前的进程

- 可以看下slavenode1,成功

- stop-dfs.sh 停止
使用docker inspect可以看到docker容器的ip地址:
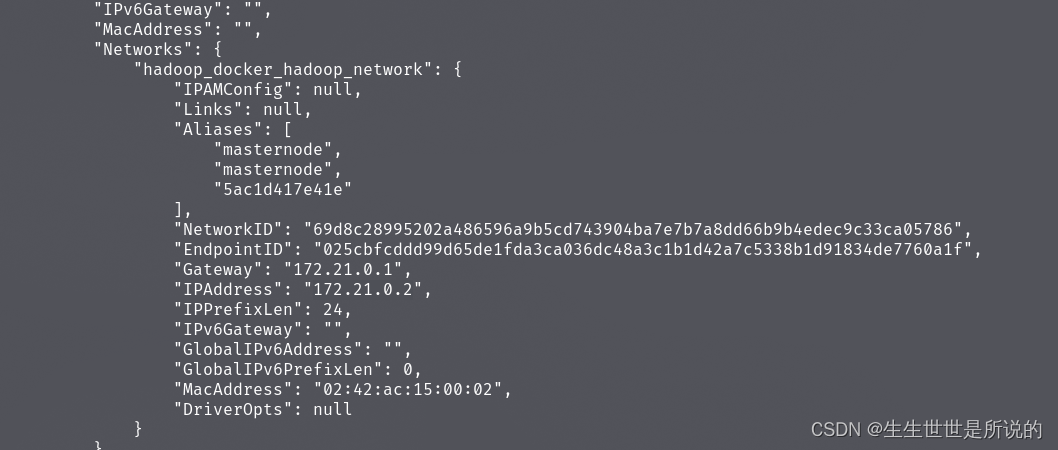
docker-compose文件定义了桥接网络到宿主机,直接在宿主机访问172.21.0.2:9870(就是masternode被分配的子网地址)就能看到HDFS WEBUI: 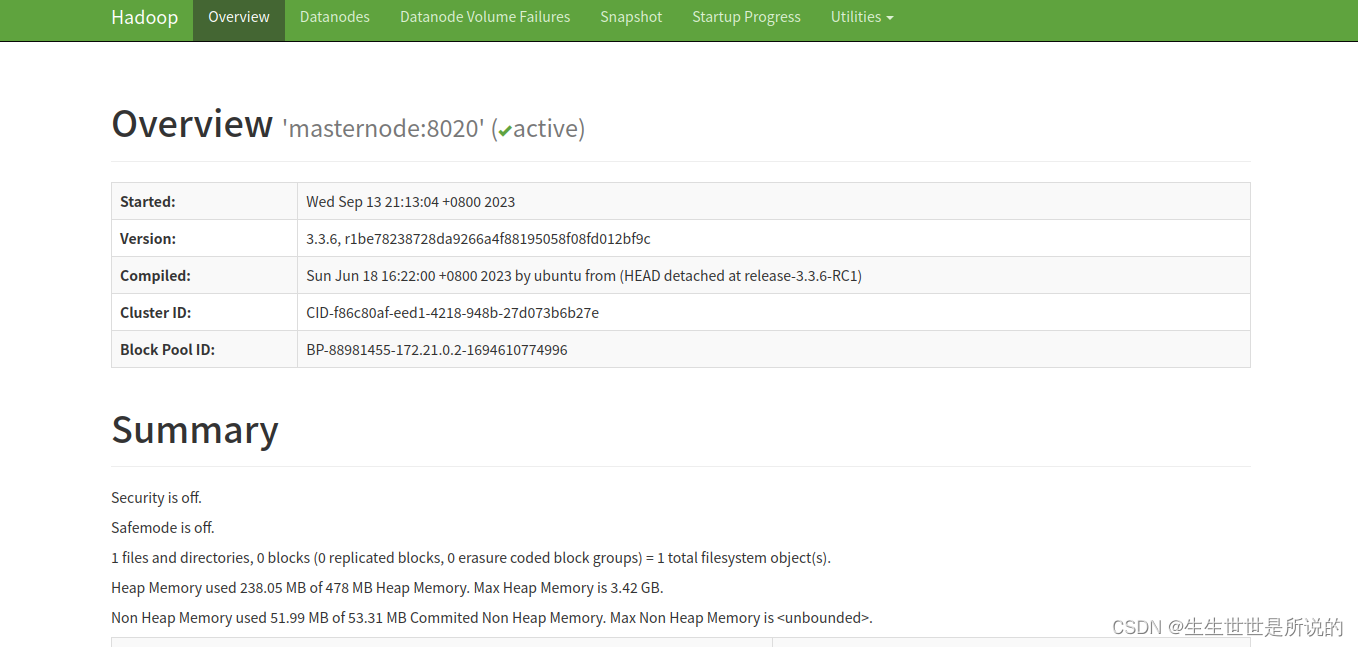
在ubuntu上获取hadoop压缩包
获取压缩包
wget -b https://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
查看进度
cat wget-log









