有需要项目的可以私信博主!!!!!
一、选题的目的、意义及研究现状
(1)选题的目的和意义
随着人们对道路安全性的重视和城市交通量的不断增加,交通标志牌作为道路交通安全的重要组成部分之一,扮演着十分重要的角色。然而,交通标志牌的数量庞大、种类繁多,人工巡视的方式存在效率低、漏检率高等问题,对道路交通的安全性带来了一定的隐患。因此,研究一种基于Yolov5的交通标志牌目标检测方法,能够快速准确地检测出道路上的交通标志牌,提高道路交通的安全性,降低交通事故的发生率。随着目前智能化交通和自动驾驶的领域兴起,交通标志的目标检测对未来的智能化领域有着重要的升级和拓展。
1.提高道路交通的安全性
通过研究基于Yolov5的交通标志牌目标检测方法,可以快速准确地检测出道路上的交通标志牌,有效地提高道路交通的安全性。当司机未能及时发现路上的交通标志牌,就可能会发生交通事故,这对司机和其他行人都是一种潜在的威胁。通过使用基于Yolov5的交通标志牌目标检测方法,可以提高交通标志牌的识别率,从而减少交通事故的发生率。
2.提高交通标志牌的检测效率
目前,人工巡视的方式存在效率低、漏检率高等问题,不能够及时地发现所有的交通标志牌。使用基于Yolov5的交通标志牌目标检测方法,可以提高交通标志牌的检测效率。与人工检测相比,该方法可以更快速地检测出交通标志牌,同时还能够减少漏检的情况。
3.促进计算机视觉技术的发展
目标检测是计算机视觉领域中的重要研究方向,而交通标志牌的检测和识别是其中的一个重要应用场景。基于yolov5的交通标志牌目标检测研究不仅可以提高交通安全性,也可以促进计算机视觉技术的发展,使其更好地服务于人类社会的发展。
4.推动自动驾驶技术的发展
自动驾驶技术是未来交通领域的重要发展方向之一,而交通标志牌的自动化检测和识别是自动驾驶技术中的一个重要环节。基于yolov5的交通标志牌目标检测研究可以为自动驾驶技术的发展提供重要的技术支持,推动自动驾驶技术的应用和发展。
5.提升城市管理水平
交通标志牌的检测和识别不仅可以提高道路交通安全性,也可以提升城市管理水平。交通标志牌的缺失或错误往往是城市管理中的一个重要问题,通过自动化的交通标志牌检测和识别技术,可以有效地提高城市管理的效率和水平。
(2)课题的研究现状
随着智能交通系统的发展,交通标志牌的识别和检测成为了研究的热点。在计算机视觉领域,目标检测是一项重要的任务,它可以在图像或视频中准确地检测出指定的目标物体。其中,基于深度学习的目标检测方法因为其准确性和可扩展性而备受关注。其中,YOLOv5是一种基于深度学习的目标检测算法,被广泛应用于交通标志牌的检测。
目前,交通标志牌的检测方法可以分为两种:传统方法和基于深度学习的方法。传统方法主要包括边缘检测、颜色空间分割、形状分析等技术。这些方法通常需要手动提取特征并使用传统的机器学习算法进行分类。虽然这些方法可以实现一定的效果,但在复杂场景下仍存在一定的缺陷。
基于深度学习的方法则利用深度神经网络模型,可以自动学习图像中的特征,避免了传统方法中需要手动提取特征的繁琐过程,因此具有更好的性能和泛化能力。目前,基于深度学习的方法已经在交通标志牌的检测中得到了广泛的应用。
其中,以YOLO(You Only Look Once)为代表的实时目标检测算法在交通标志牌检测领域取得了显著的成果。YOLO算法是一种端到端的目标检测算法,其基本思路是将图像划分为S × S个网格,并在每个网格上预测目标的类别、位置和置信度。与其他目标检测算法相比,YOLO具有高速度和高精度的优势,因此在交通标志牌检测领域受到了广泛关注。
在YOLO算法的基础上,YOLOv5在检测精度和速度方面都有了显著的提升。与YOLOv4相比,YOLOv5采用了更轻量级的网络结构,同时增加了多尺度训练和数据增强等技术,进一步提高了检测精度和速度。
二、研究方案及预期结果
(3)课题研究的基本内容
本课题研究,通过利用提供的公开数据集TT100K图标进行筛选和整理,最终得到TT100K数据中的45类交通标志牌数据。并将数据集进行分割,其中训练集:6664条;验证集:1919条,测试集:986条数据集。
然后进行数据的清洗和数据标注工作,采用labelimg标注工具进行手动标注。由于标签的格式都是VOC(xml格式)的,而yolov5训练所需要的文件格式是yolo(txt格式)的,这里就需要编写代码对xml格式的标签文件转换为txt文件。最后将数据划分为训练集和验证集以及测试集,最终利用yolov5-6.0的框架,选取对应的预训练权重,设置相应的参数进行深度学习训练,生成最好best权重文件,最后利用测试集进行推理测试,可以通过打开摄像头,或者视频以及图片的方式进行测试和验证模型。
1.数据源的获取
通过利用提供的公开数据集TT100K图标进行筛选和整理,最终得到TT100K数据中的45类交通标志牌数据。TT100K它是由清华与腾讯的联合实验室整理并公布的,提供的10万张图像包含了30000个交通标志,图像来源于由6个像素很高的广角单反相机在中国的多个城市拍摄的全景图,拍摄地点的光照条件、天气条件有所不同。原始的街景全景图分辨率为 8192x2048,再将全景图裁剪分为四份,最终数据集的尺寸为 2048x2048。TT-100K 数据集所含交通标志的类别较为全面。
|
|
|
|
|
|
|
|






图 1 源数据展示
2.数据的清洗与筛选
得到的数据,有一些目标比较少,可以说是没有,所有我们需要将数据集进行清洗,得到一些干净的数据集,在实际的数据中总会有一些图片比较的模糊或者缺失,所以数据的清洗和预处理是非常有必要的,只是本次我们通过获取开源的数据集,有很多的数据都已经是清洗干净的,但是还是需要对其进行一部分的清洗和观察。一般来说数据清洗,包括去除到噪声很大的数据,比如完全就没有的标识牌的图片,或者模糊不清的图片,或者不存在的图片数据。最终选取了8583条带有标签的数据,986条测试所用的数据。
3.数据的标注
将所清洗好的数据,需要利用anaconda所提供的标注工具labelimg对图片中的标志牌进行手动的标注,然后将所有的标注保存为对应的格式,一般的我们保存的格式都是VOC(XML)格式的文件,但是由于YOLO训练的时候所需的是TXT格式的标注文件格式。所以需要利用代码对标注的数据进行转换为相应的TXT格式。
基于yolov5的深度学习模型,构建的是一个监督学习,我们需要有标签,这里的标签和传统的机器学习的标签不一样,他们是一个特定的类别,这里他是通过一些标注工具,通过标注好的图片,最后生成一些固定的格式,其中yolov5模型需要的格式就是txt格式。
这里我们使用的是anaconda自带的一个标注工具,通过提前安装好,我们就可以使用了。
首先这里需要准备我们需要打标注的数据集。这里我新建一个名为VOC2007的文件夹,里面创建一个名为JPEGImages的文件夹存放我们需要打标签的图片文件;再创建一个名为Annotations存放标注的标签文件;最后创建一个名为 predefined_classes.txt 的txt文件来存放所要标注的类别名称。
VOC2007的目录结构为:
├── VOC2007
│├── JPEGImages 存放需要打标签的图片文件
│├── Annotations 存放标注的标签文件
│├── predefined_classes.txt 定义自己要标注的所有类别
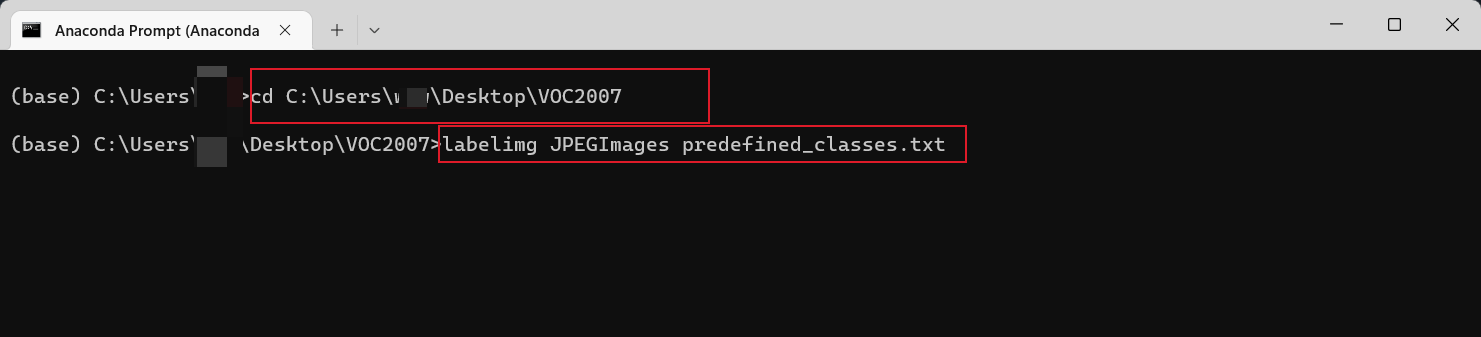
打开cmd命令终端(快捷键:win+R)。进入到刚刚创建的这个VOC2007路径(这个很重要,涉及到能不能利用predefined_classes.txt 这个txt文件中定义的类别)。
执行如图中的命令进入到VOC2007路径下(每个人的路径都不一样,按个人的路径去写)如下图所示:可以看到进入到相应的目录了。
|
图 2 labelimg标注工具的使用 |
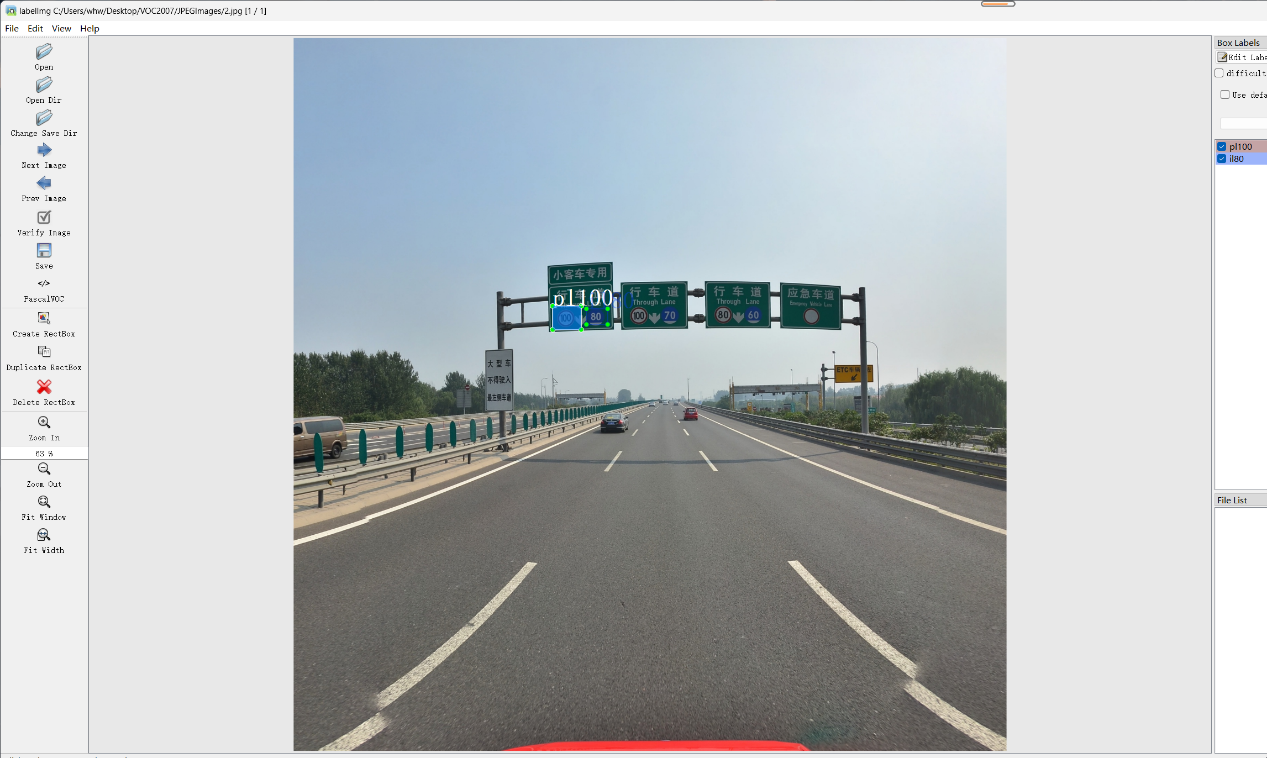
然后在标注的时候,对于该工具,可以使用了快捷键,帮助在后续的标注工作中,提升效率。
A:切换到上一张图片
D:切换到下一张图片
W:调出标注十字架
del :删除标注框框
Ctrl+u:选择标注的图片文件夹
Ctrl+r:选择标注好的label标签存在的文件夹
由于标注的时候,需要一个对应的ID,也就是说,当我们具体的标志牌有具体的意义的时候,我们在进行展示的时候,或者测试数据集的时候,很长的文字或编码会导致我们视觉上感觉不是很好,所以这里就一一对应了一些ID。
|
图 3 豆瓣电影网站JSON数据包探索 |
|
图 4 交通标志牌的数据标注 |
|
图 5 ID部分对应展示 |

4.数据分割
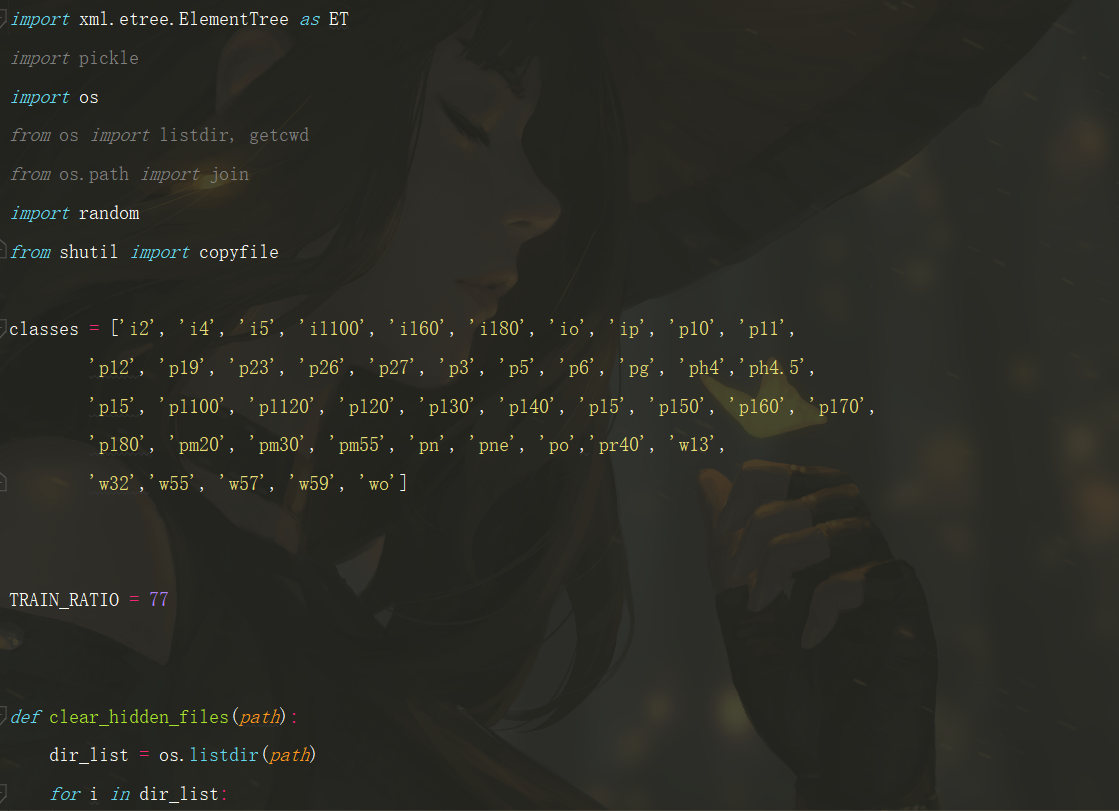
对于很多目标检测的数据集标签的格式都是VOC(xml格式)的,而yolov5训练所需要的文件格式是yolo(txt格式)的,这里就需要对xml格式的标签文件转换为txt文件。同时训练自己的yolov5检测模型的时候,数据集需要划分为训练集和验证集。这里提供了一份代码将xml格式的标注文件转换为txt格式的标注文件,并按比例划分为训练集和验证集。
特别要注意的是,classes里面必须正确填写xml里面已经标注好的类,要不然生成的txt的文件是不对的。TRAIN_RATIO是训练集和验证集的比例,当等于77的时候,说明划分77%给训练集,23%给验证集。
|
图 6 数据分割代码展示 |
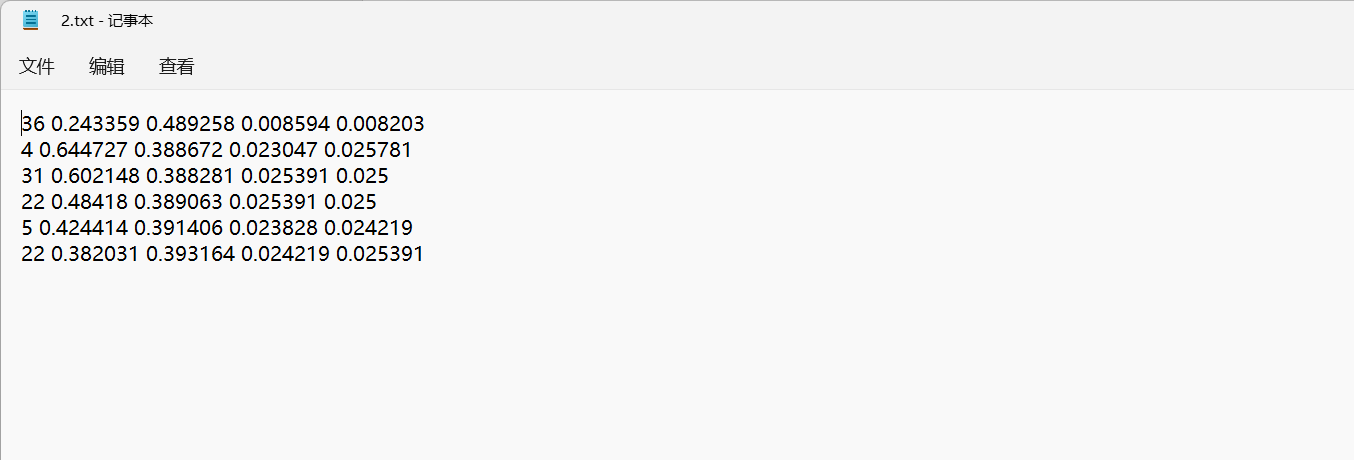
|
图 7 TXT标注数据展示 |
5.YOLO模型构建
准好数据集之后,就需要开始进行模型的构建,这里的深度学习yolov5,我们可以通过直接去官网下拉取一个仓库就可以了,将代码克隆到本地,深度学习是一个框架,它和机器学习的差别就是,它拥有一套比较全面的架构,我们可以不用自己写代码就可以进行构建深度学习的工程项目。
预期使用的是yolov5-6.0版本的仓库代码,通过下载好权重之后,这里选择的yolov5s.pt权重,它具有快速的特点,但是可能准确率和其他的权重相比不是很高,为了保证我们的训练符合本地电脑配置,所以我选取的这个比较“短小精悍”,通过增大其迭代次数也可以保证我们的准确率。
|
图 8 不同权重文件的特点 |
|
图 9 YOLO工程展示 |
首先修改的就是,这个权重文件,在模型进行训练的时候,我们根据官方所提供的几个版本进行选择,其中不同的权重文件的大小代表着其效果,但是也不是绝对的,唯一的,我们还是要根据自己的数据集来选择自己的权重。
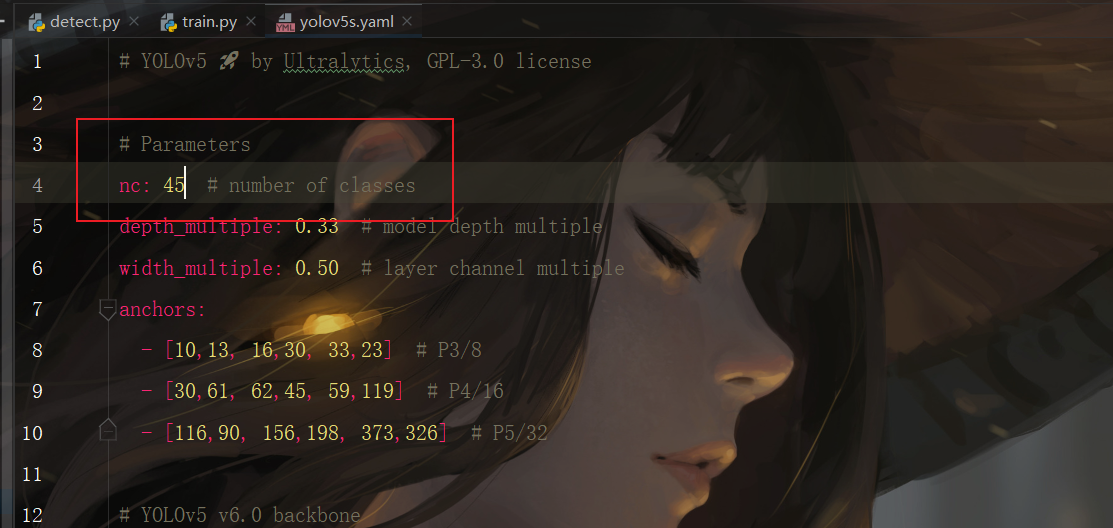
将GitHub下载好的权重文件放到我们的代码仓库中之后,其次我们就需要修改我们model下的yaml文件,这里的东西我去查询了一下,其代表的是我们模型的超参数集,也就是时候我们在选择对应的权重文件下,就会有一个对应的模型参数集,这里对应好之后,还要特别注意,修改里面的类别数目,我这里选择是,45类,所以需要修改为对应的
|
图 10 参数修改 |
|
图 11 训练集参数修改 |
其他的参数都是不需要修改的,这里对应的一些含义我们都可以通过手册进行查询到
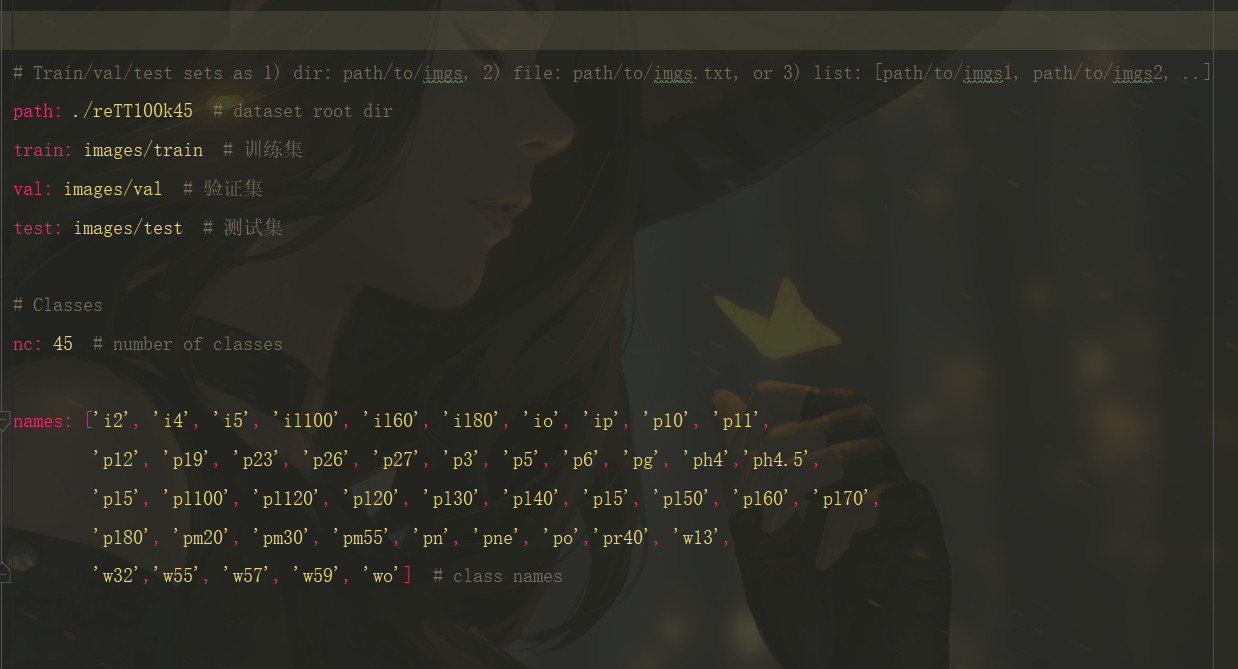
之后就要去修改一下data下的yaml文件,这个里面的参数也比较的重要,对应的就是我们的数据集的路径,分别为训练集和测试集,以及验证集,其中包括的45类的交通标识,所对应的ID,因为这里的ID所对应的目标含义有的比较长,且不好展示出来,所以我就按照其ID给他进行一个对应,其对应表在上面的数据标注的部分。
|
图 12 参数设置展示 |
6.模型的训练
修改之后,我们将其迭代次数修改为200次,然后就让模型自己去慢慢的训练,由于我使用的显卡是3060,所以设置batch-size为40次,预计在此数据集下训练需要几天的时长。
大致的参数修改和配置都是这样,这样我们可以快速的搭建好一个深度学习的环境,并且可以跑通一个模型,特别注意的是,在我们选择权重的时候,以及修改对应的参数,YOLO提供了很多的版本,有些版本和参数是需要一一对应的。
|
图 13 参数详解 |

7.模型的评估推理
为了比较的直观的展现出模型训练过程中的效果,我们可以使用其可视化的功能。在YOLO工程中提供了一个Tensorboard方法,可以对训练的过程中展示其实时的一个效果。最后,运行其detect.py文件可以对测试数据进行测试。
|
图 14 测试代码展示 |

|
图 15 研究路线 |
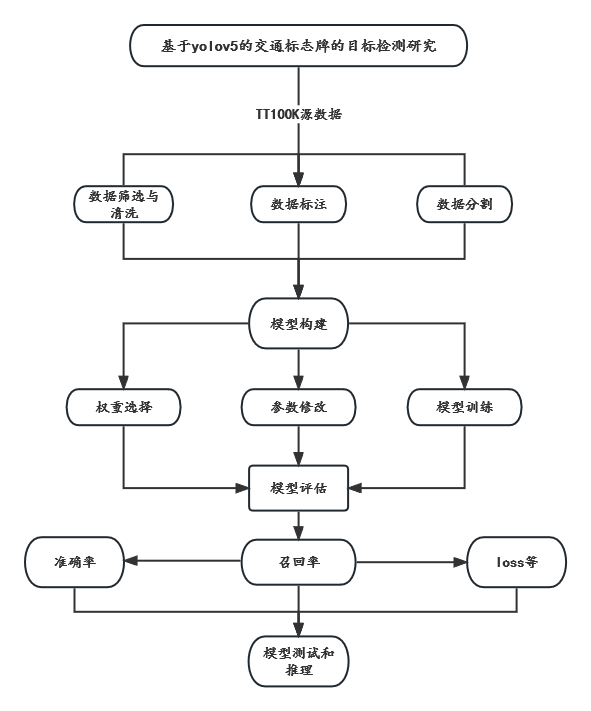
(4)研究方案及预期达到的目标
研究方案:
本研究旨在利用公开数据集TT100K图标进行筛选和整理,最终得到TT100K数据中的45类交通标志牌数据。然后进行数据清洗和标注工作,将数据集分割为训练集、验证集和测试集,并编写代码将VOC(xml格式)的标签文件转换为yolo(txt格式)。最后利用yolov5-6.0的框架进行深度学习训练,生成最佳的权重文件,并利用测试集进行推理测试。具体步骤如下:
数据预处理:对TT100K数据集进行筛选和整理,选择45类交通标志牌数据作为研究对象,并将数据集分割为训练集、验证集和测试集。
数据标注:利用labelimg标注工具对数据集进行手动标注,并将标签文件转换为yolo(txt格式)。
模型训练:使用yolov5-6.0的框架进行深度学习训练,选择适当的预训练权重,设置相应的参数,生成最佳的权重文件。
模型测试:利用测试集进行推理测试,可以通过打开摄像头,或者视频以及图片的方式进行测试和验证模型。
预期达到的目标:
1.成功将TT100K数据集中的45类交通标志牌数据进行清洗和标注,并将其转换为yolo(txt格式)的标签文件;
2.将数据集成功划分为训练集、验证集和测试集;
3.成功利用yolov5-6.0框架进行深度学习训练,并生成最佳(best)权重文件;
4.成功利用测试集进行模型的推理测试,测试模型在摄像头、视频和图片等不同数据源下的表现;
5.模型的测试结果能够达到预期的性能指标,并能够满足实际应用需求。
(5)课题研究已具备和所需的条件
本课题已具备的条件:
(1)提供的公开数据集TT100K,包含大量交通标志牌图像
(2)图像数据已经进行了清洗、整理和标注使用了标准的标注工具labelimg,并将标签格式转换为yolo的txt格式
(3)采用了yolov5-6.0框架进行深度学习训练
(4)训练集、验证集和测试集已经划分好,并用于训练和测试深度学习模型
所需的条件:
(1)一台能够支持深度学习训练的计算机,例如拥有GPU的服务器或者个人电脑
(2)适合的深度学习框架,例如PyTorch或TensorFlow
(3)熟悉深度学习训练的知识和技能,包括网络结构的选择、超参数的调整、数据增强技巧、损失函数的选择等
(4)具有一定的编程能力,例如Python编程,能够编写代码将标注文件转换为训练所需的格式,并编写训练脚本
(5)具有良好的数据分析和处理能力,能够对训练和测试结果进行评估和分析
(6)研究过程中可能遇到的困难和问题、解决措施
(1)数据清洗和标注困难:由于数据集中可能存在一些异常值、错误的标签或者缺失的标签等问题,这可能会影响到模型的训练效果。解决此问题的办法是利用数据可视化工具,例如LabelImg、CVAT、VGG Image Annotator等,对数据进行手动的清洗和标注,确保数据集的质量和准确性。
(2)标签格式转换问题:由于不同的深度学习框架可能需要不同的标签格式,因此需要将数据集的标签格式转换为模型所需的格式。解决此问题的办法是编写相应的脚本代码,将VOC格式的标签文件转换为Yolo格式的标签文件。
(3)数据集划分问题:在进行深度学习模型的训练时,需要将数据集划分为训练集、验证集和测试集。如何划分数据集是一个关键的问题,需要考虑到数据集的大小、样本的分布情况、数据集的平衡性等因素。解决此问题的办法是将数据集随机划分为多个子集,并对每个子集进行训练和测试,从而得到更加准确的模型。
(4)模型选择和参数调整问题:选择合适的深度学习模型,并对模型的参数进行调整,是一个重要的问题。不同的模型有不同的适用场景和特点,需要根据实际需求选择合适的模型。同时,对模型的参数进行调整可以提高模型的性能和准确性。
(5)硬件设备不足,由于电脑的性能或者环境的部署,深度学习的环境部署比较麻烦,需要对其进行详细的部署,这里需要安装好Pytorch的深度学习环境,是可能比较困难的。解决措施:通过官方的文档进行环境的部署和安装,进一步的为后续的模型训练提供支持。
三、研究进度
以下是研究进度安排:
- 数据收集和预处理
- 收集TT100K公开数据集,并从中筛选和整理出45类交通标志牌数据。
- 将数据集分割为训练集(6664条)、验证集(1919条)和测试集(986条)。
- 使用labelimg标注工具手动标注数据,并将标签文件从VOC(xml格式)转换为yolo(txt格式)。
- 深度学习模型训练
- 利用yolov5-6.0框架,选取对应的预训练权重。
- 设置相应的参数进行深度学习训练,生成最好的权重文件。
- 使用验证集来评估模型性能并进行参数调整,直到达到最佳模型性能。
- 模型测试和应用
- 利用测试集进行推理测试,验证模型的准确性和鲁棒性。
- 通过打开摄像头、视频和图片的方式进行模型的应用和测试。
- 根据测试结果,对模型进行进一步的优化和调整。
...........................
四、参考文献
.........................
每文一语
道不同不相为谋








