📙作者简介: 清水加冰,目前大二在读,正在学习C/C++、Python、操作系统、数据库等。
📘相关专栏:C语言初阶、C语言进阶、C语言刷题训练营、数据结构刷题训练营、有感兴趣的可以看一看。
欢迎点赞 👍 收藏 ⭐留言 📝 如有错误还望各路大佬指正!
✨每一次努力都是一种收获,每一次坚持都是一种成长✨

目录
前言
在二叉树的存储结构中提到堆可以进行排序,也就是今天的主题堆排序,堆的排序还可以解决Topk问题,今天我就向大家解密什么是堆排序和Topk问题,它们的原理又是什么。
1. 堆排序
堆是一种特殊的完全二叉树,堆排序是一种基于二叉堆数据结构的排序算法。堆排序是利用堆的特性来对堆中的数据进行排序,那么问题来了:
如果我们要排升序,需要建大堆还是小堆?绝大多数人的第一反应是建小堆,但建小堆真的可以将数据进行升序排列吗?
我们看下边这棵树,如果是小堆,那如何去找第二小的数?我们需要根据堆的特性,对数据进行调整位置,来达到排序的问题。
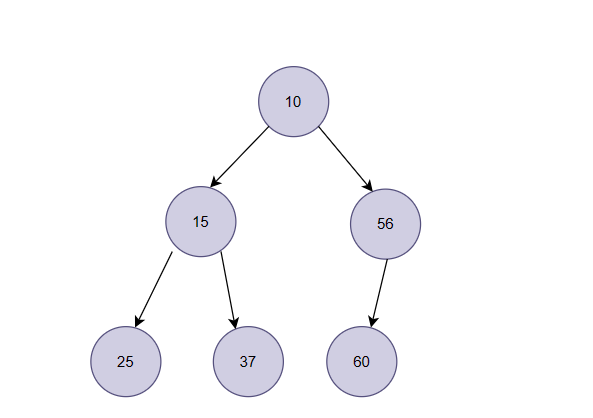
显然小堆是无法做到的,要想排升序就必须要建大堆。大堆排升序思路如下:
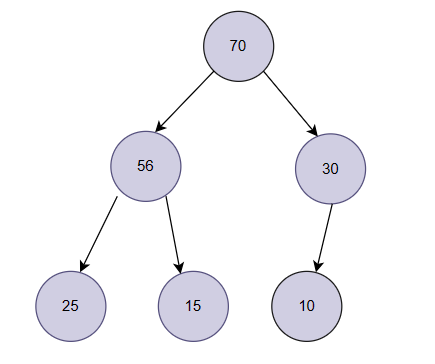
大堆的根是整棵树中最大的值,那我们就可以让根和最后一个节点进行交换(70和10进行交换),然后将剩下的节点进行调整(不包含70),调整后的根就是第二大的数。

然后继续上述操作,将56和15进行交换,然后再进行调整,以此类推,最终数据就会被排为升序。
总结来说,堆排序主要有两大步骤:
- 建堆
- 调整数据
建堆,我们可以选择向上调整或者向下调整。
调整数据部分,必须为向下调整。
1.1 时间复杂度
说到了排序,那就必须要谈一谈它的性能如何?也就是它的时间复杂度。
1.1.1 向上调整(建堆)
向上调整的思路是从孩子(叶子节点)开始调整,最坏调整到根节点,调整情况如下: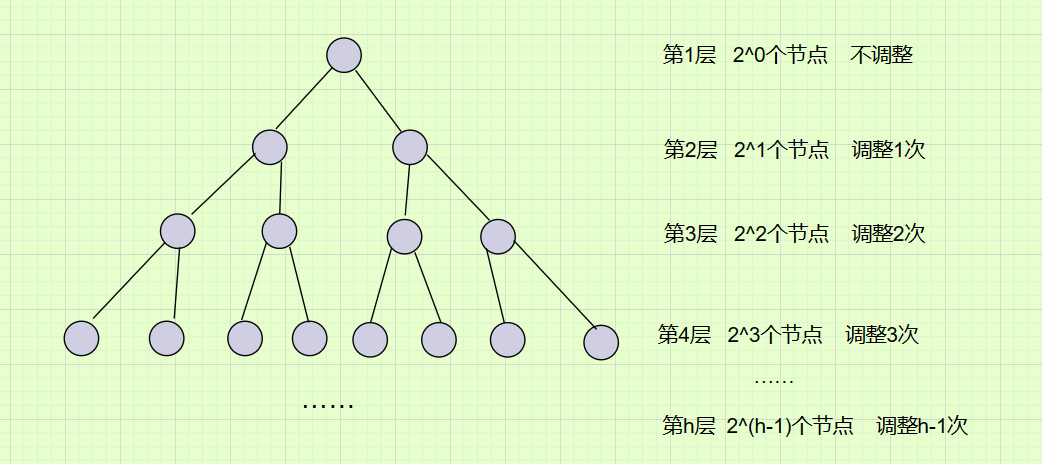
每层的数据个数 * 每层调整次数=一层最多执行的次数。那要求的是总共需要执行的次数就是每层的执行次数之和。我们设总的执行次数为T(h)。
所以:T(h)=2^1*1 + 2^2*2 + 2^3*3 … +2^(h-2)*(h-2) + 2^(h-1)*(h-1) ;
计算部分为高中数学的知识,私下可以验算一下,最终的结果为:T(h)=(h-2)* 2^h+2,
将h代换成N(节点个数),N=2^h-1,h=log(N+1),
T(N)=( log (N+1) - 2 ) * (N+1) + 2(此处的log以2为底),最终就约等于N*log N
所以向上调整建堆的时间复杂度就是O(N*log N)。
1.1.2 向下调整 (建堆)
向下调整是从根节点开始,最坏调整到叶子节点,调整情况如下:
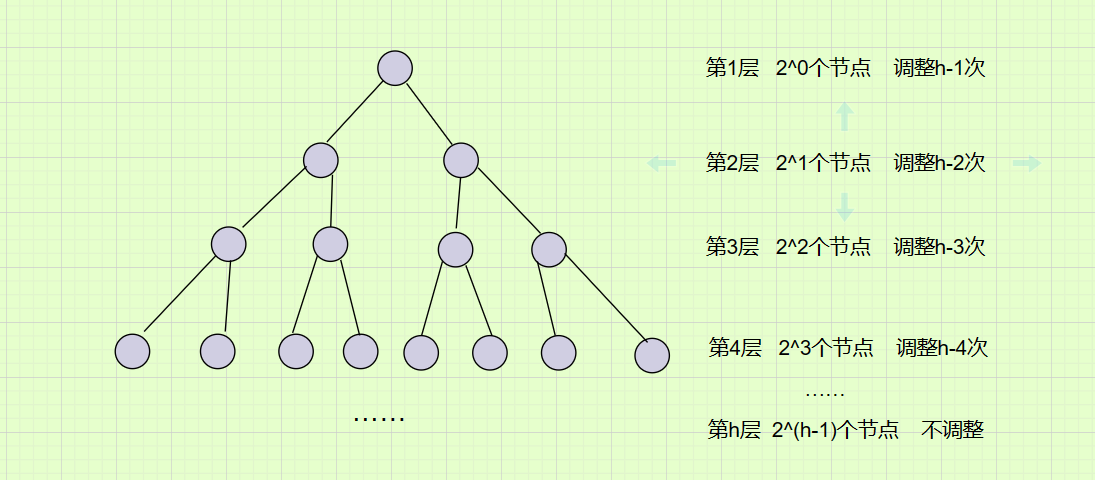
这里我们可以看出,向下调整的时间复杂度和向上调整不同,我们设总的执行次数为T(h)。
T(h)=2^0*(h-1) + 2^1*(h-2) + 2^2*(h-3) … +2^(h-3)*2 + 2^(h-2)*1 ;
最终的结果为:T(h)=2^h-h-1 ;
将h代换成N(节点个数),N=2^h-1,h=log(N+1);
T(N)=N-log(N+1);最终就约等于N;
所以向下调整建堆的时间复杂度就是O(N);
注意:这里要区分清,是建堆操作还是调整操作,单一的执行一次调整,向上调整和向下调整的时间复杂度都是log N。
1. 2 排序实现
void HeapSort(int* arr, int n)
{
//向上调整建堆,时间复杂度O(N*log N)
for (int i = 1; i < n; i++)
{
AdjustUp(arr, i);
}
//向下调整建堆,时间复杂度O(N)
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(arr, n, i);
}
int end = n - 1;
while (end > 0)
{
swap(&arr[0], &arr[end]);
AdjustDown(arr, end, 0);
end--;
}
}注意:
向上调整时我们需要保证上方的数据结构是堆,所以这里我们从头开始读入数据,读一个数据就调整一次。这样就可以确保每次调整时,其他的数据都是堆结构。
向下调整的前提是左右子树都为堆结构,所以我们需要保证左右子树都为堆,这里我们传参时不能从头开始,要从倒数第一个的非叶子节点开始(最后一个父节点),从后向前进行调整建堆。
向上调整
这里我们建的是大堆 。
void AdjustUp(int* arr,int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (arr[parent] < arr[child])//建大堆排升序
{
swap(&arr[parent], &arr[child]);
child = parent;
parent = (parent - 1) / 2;
}
else
{
break;
}
}
}向下调整
void AdjustDown(int* arr, int n,int parent)
{
int child = parent * 2 + 1;
while (child <n )
{
if (child+1<n && arr[child + 1] > arr[child])
{
child++;
}
if (arr[parent] < arr[child])
{
swap(&arr[child], &arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}2. Topk问题
2.1 什么是Topk问题
Top-K问题是指从一组元素中找出前K个最大(或最小)的元素。这个问题在数据处理和算法设计中经常遇到,常见的应用场景包括搜索引擎中的搜索结果排序、推荐系统中的物品推荐、数据分析中的数据筛选等。
Topk问题,我们就可以使用堆来解决,对于Top-K问题,一般有两种情况:
- 找出前K个最大的元素:可以使用最小堆来解决,维护一个大小为K的最小堆,遍历所有元素,将每个元素与堆顶元素进行比较,如果大于堆顶元素,则将堆顶元素替换为当前元素,并进行堆调整。最终堆中的元素即为前K个最大的元素。
- 找出前K个最小的元素:可以使用最大堆来解决,维护一个大小为K的最大堆,遍历所有元素,将每个元素与堆顶元素进行比较,如果小于堆顶元素,则将堆顶元素替换为当前元素,并进行堆调整。最终堆中的元素即为前K个最小的元素。
通过解决Top-K问题,可以快速获取数据中的重要信息,提高算法的效率和性能。
2.2 Topk问题的解决
2.2.1 造数据
为了模拟实现Topk问题在现实生活中的应用,所以在测试时我们需要采用大量的数据进行测试,我们自己手动输入是远远不够的,所以我们这里采用strand函数进行造数据。
void CreateNDate()
{
// 造数据
int n = 1000000;
srand(time(0));
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen error");
return;
}
for (int i = 0; i < n; ++i)
{
int x = rand() % 10000000;
fprintf(fin, "%d\n", x);
}
fclose(fin);
}这里我们造了100万个数据。将数据默认放到了一个data.txt的文件中。我们先运行一下这个函数接口,然后打开在程序的当前路径下找到data.txt文件,将任意的k个数据手动修改(可以前边加4个9,增加辨识度)确保判断找出的数据为前k的最值。这里我们选择找出前k个最大的数据。
注意:造完数据后要将造数据接口注释掉,修改数据后记得将文件保存
2.2.2 Topk的实现
根据上述的思路,要想找到前k个最大的数据,就需要建小堆,这样堆顶就是堆中最小的数据,比堆顶大就置为根入堆,最后将所有数据遍历一遍之后,留在堆里的数据就是前k个最大的数据。
这里我们依然需要前边的调整代码。具体代码如下:
void PrintTopK(const char* filename,int k) {
//打开文件,读取数据
FILE* fout = fopen(filename, "r");
if (fout == NULL)
{
perror("fopen fail");
return;
}
//建堆
int* setHeap = (int*)malloc(sizeof(int) * k);
if (setHeap == NULL)
{
perror("malloc fail");
exit(-1);
}
//读取前k个数据建堆
for (int i = 0; i < k; i++)
{
fscanf(fout, "%d", &setHeap[i]);
}
for (int i = 0; i < k; i++)
{
AdjustUp(setHeap, k);
}
//遍历入堆
int x = 0;
while (fscanf(fout, "%d", &x) != EOF)
{
if (x > setHeap[0]) //比堆顶大就入堆
{
setHeap[0] = x;
AdjustDown(setHeap, k, 0); //入堆之后向下调整
}
}
for (int i = 0; i < k; i++)
{
printf("%d ", setHeap[i]);
}
printf("\n");
fclose(fout);
}建小堆调整代码
void swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void AdjustUp(int* arr, int child)
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (arr[parent] > arr[child])//建大堆排升序
{
swap(&arr[parent], &arr[child]);
child = parent;
parent = (parent - 1) / 2;
}
else
{
break;
}
}
}
void AdjustDown(int* arr, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && arr[child + 1] < arr[child])
{
child++;
}
if (arr[parent] > arr[child])
{
swap(&arr[child], &arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
main接口:
int main()
{
//CreateNDate();
PrintTopK("data.txt", 7);
return 0;
}总结
本篇博客主要介绍了堆排序算法及其在解决TopK问题中的应用。通过对堆排序的原理和实现步骤的详细讲解,我们可以更好地理解和掌握这一经典的排序算法。同时,通过解决TopK问题的实例,我们也可以看到堆排序在实际应用中的价值和优势。希望本篇博客能够为你提供一些有用的思考和启发。最后,感谢阅读!








