简介
JMeter中的定时器(Timer)是一种重要的元件,用于模拟用户在不同时间间隔内发送请求的场景。通过使用定时器,可以模拟负载、并发和容量等不同情况下的请求发送频率。
使用定时器
- 可以在取样器下添加定时器,这样定时器只会作用于当前取样器
- 也可以在线程组下添加多个定时器,统计定时器的总和,然后作用于线程组下的所有取样器
定时器的作用域
- 定时器是在每个sampler(采样器)之前执行的,而不是之后(无论定时器位置在sampler之前还是下面);
- 当执行一个sampler之前时,所有当前作用域内的定时器都会被执行;
- 如果希望定时器仅应用于其中一个sampler,则把定时器作为子节点加入;
定时器介绍
1、固定定时器
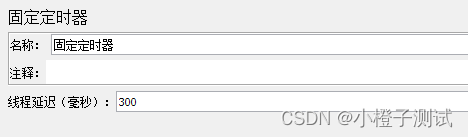
1、如果你需要让每个线程在请求之前按相同的指定时间停顿,那么可以使用这个定时器;需要注意的是,固定定时器的延时不会计入单个sampler的响应时间,但会计入事务控制器的时间。
2、固定定时器放到线程组下其作用域是所有请求都会延迟固定器设置的时间,如果放到请求内,作用域是单个请求延迟时间(常用)。
3、对于“java请求”这个sampler来说,定时器相当于loadrunner中的pacing(两次迭代之间的间隔时间);
4、对于“事务控制器”来说,定时器相当于loadrunner中的think time(思考时间:实际操作中,模拟真实用户在操作过程中的等待时间)。
2、统一随机定时器
它产生的延迟时间是个随机值,而各随机值出现的概率均等。总的延迟时间等于一个随机延迟时间加上一个固定延迟时间,用户可以设置随机延迟时间和固定延迟时间。
总延迟时间=指定范围内的随机时间 + 固定延迟时间。
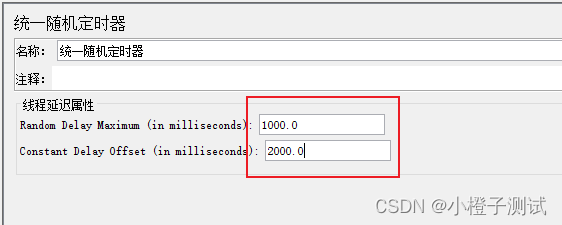
andom Delay Maximum(in milliseconds):随机延迟最大的时间 单位毫秒,比如我这里设置为1000ms
Constant Delay Offset(in milliseconds):固定延迟时间 单位毫秒,我这里设置为2000ms
那么总的延迟时间范围是2000毫秒~3000毫秒之间的值。
3、精准吞吐量定时器(Precise Throughput Timer)
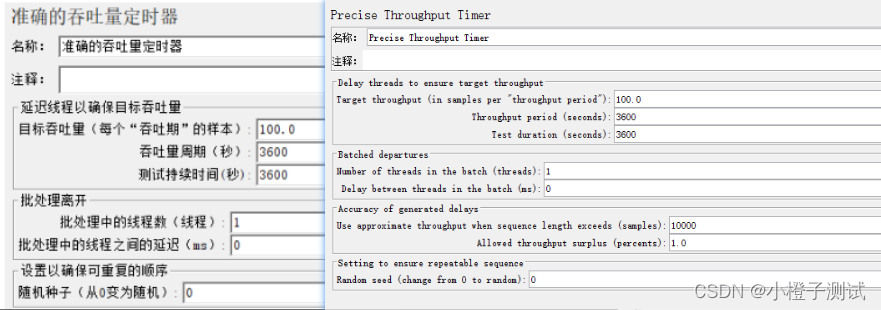
用来控制吞吐量的定时器。和 Constant Throughput Timer 类似,但是能更精准的控制请求。区别就是 Constant Throughput Timer 根据时间来做定时器(到了多少秒就发请求);Precise Throughput Timer 是根据吞吐量在做计时器(到了多少量就发请求)。也就是能做到控制请求的速度和个数。
参数介绍
线程以确保目标吞吐量(Delay threads to ensure target throughput)
- 目标吞吐量(每个“吞吐期”的样本)(Target throughput (in samples per “throughput period”)):期望测试的TPS,可以精确到多位小数(不过最终报告只会有1位小数)
- 吞吐量周期(秒)(Throughput period (seconds)):在多少秒内执行测试的TPS(因为TPS单位是秒,这里固定使用1秒即可)
- 测试持续时间(秒)(Test duration (seconds)):测试时长,与前面线程组的数值保持一致即可
批处理离开
- 批处理中的线程数(线程)(Number of threads in the batch (threads)):是指准备好了多少个线程后一起发起请求(即集合点),取与TPS保持一致的数值(如果TPS是小数,则这里向上取整)
- 批处理中的线程之间的延迟(ms)(Delay between threads in the batch (ms)):第一批与第二批处理之间的延迟时间;默认即可
设置以确保可重复的顺序
- 随机种子(从0变为随机)(Random seed (change from 0 to random)):非0随机种子可以重复;0不可重复,默认即可
4、固定吞吐量定时器(Constant Throughput Timer)
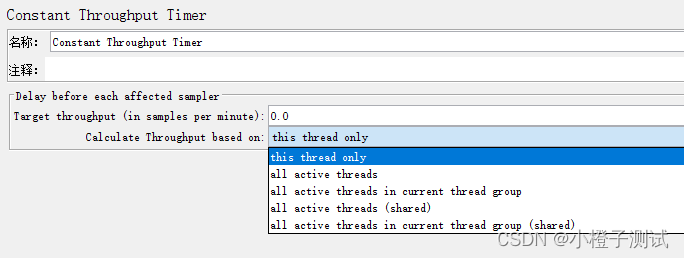
可以让JMeter以指定数字的吞吐量(即指定TPS)执行,注意的是这里要求指定每分钟的执行数,而不是每秒。在控制对服务器施压非常实用,如已知服务器每分钟最大能处理多少线程数的情况下,要对服务器进行长时的疲劳强度测试。
Calculate Throughput based on 有5个选项,分别是:
-
this thread only:控制每个线程的吞吐量,选择这种模式时,总的吞吐量 = Target throughput * 线程的数量 。
-
all active threads:设置的Target throughput将分配在每个活跃线程上,每个活跃线程在上一次运行结束后等待合理的时间后再次运行。活跃线程指同一时刻同时运行的线程。
-
all active threads in current thread group:设置的Target throughput将分配在当前线程组的每一个活跃线程上,当测试计划中只有一个线程组时,该选项和all active threads选项的效果完全相同。
-
all active threads (shared ):与All active threads 的选项基本相同,唯一的区别是,每个活跃线程都会在所有活跃线程上一次运行结束后等待合理的时间后再次运行。
-
all cative threads in current thread group (shared ):与All active threads in current thread group 基本相同,唯一的区别是,每个活跃线程都会在所有活跃线程的上一次运行结束后等待合理的时间后再次运行。
5、JSR223定时器(JSR223 Timer)
JSR定时器,在jemter最新的版本中,新增了这个定时器,可以这么理解,这个定时器相当于BeanShell定时器的“父集”,它可以使用java、JavaScript、beanshell等多种语言去实现你希望完成的事情。
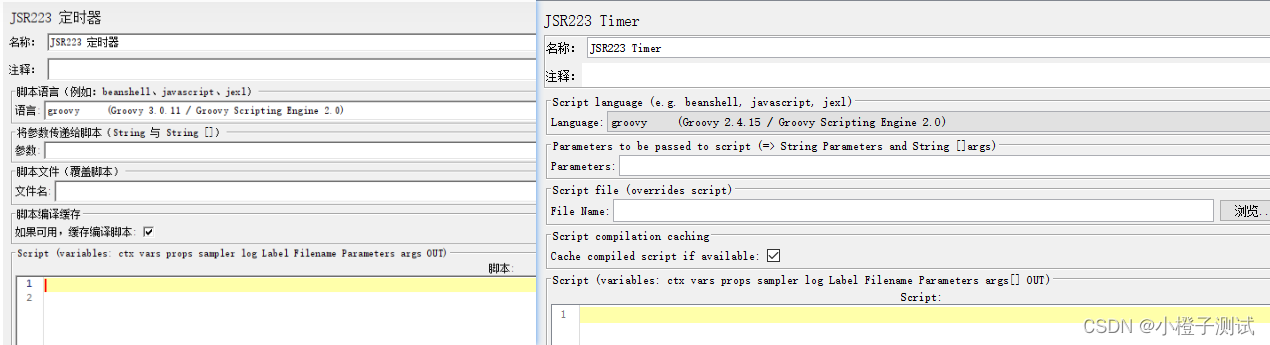
参数说明
- Language(脚本语言): 选择脚本语言;
- Parameters(参数:String/String[] 类型参数): 传递给脚本的参数;
- Script file: 脚本文件路径,脚本执行后返回值为定时器的延迟时间(单位为毫秒);
- Script compilation caching(如果可用,缓存编译脚本): 如果使用的语言支持可编译接口(Groovy是其中之一,Java、BeanShell和javascript不是),JMeter将使用跨测试计划的唯一字符串来缓存脚本编译的结果。
- Script: 手动编写脚本。
使用
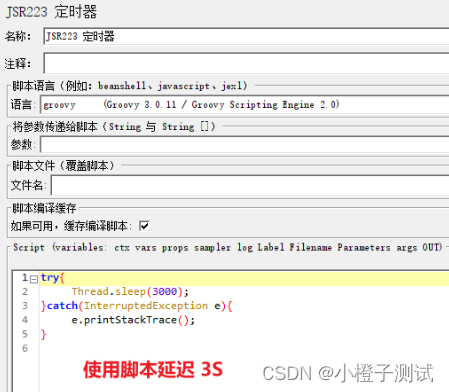
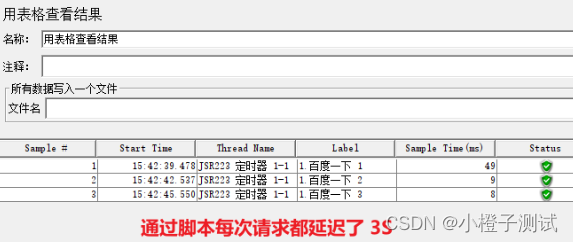
6、同步定时器(Synchronizing Timer)
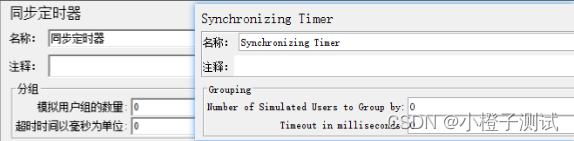
同步计时器,用来模拟多用户并发,或者说更严格的并发场景。
用来设置集合点,阻塞线程,同步虚拟用户,直到指定的线程数量到达后,恰好在同一时刻执行任务,再一起释放,可以瞬间产生很大的压力。
注意:一般情况,并发用户数多少,同步定时器就写多少。(多少并发就要等多少个人到齐一起释放
参数说明
Number of Simulated Users to Group by(模拟用户组数量):
集合点个数 (执行的线程数),如果设置为0,等于设置为线程租中的线程数量。
Timeout in milliseconds(超时时间):
指定线程数多少秒没集合到算超时(以毫秒为单位),默认为0。
如果设置为0,该定时器将会等待线程数达到了 "模拟用户组数量" 中设置的值才释放,不够的话就死等。
如果大于0,那么如果超过 "超时时间" 中设置的最大等待时间后还没达到 "模拟用户组数量" 中设置的值,Timer 将不再等待,释放已到达的线程。
(1)上面两个参数如果都设置了值,则在实际中是哪个条件先达到,定时器先执行哪个,如第一个参数释放线程数量先达到,则不会管超时时间的值,timer 会释放;如果第二个参数超时时间先达到,则不会再等线程数量,按照目前超时的时间点集合的线程数,timer 释放。
(2)同步定时器(Synchronizing Timer)的超时时间设置要求: 超时时间 > 请求集合数量 * 1000 / (线程数 / 线程加载时间)。
7、泊松随机定时器(Poisson Random Timer)
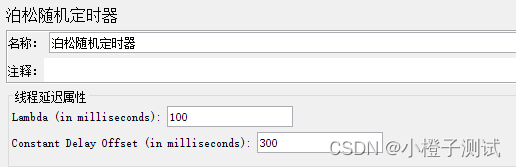
这个定时器在每个线程请求之前按随机的时间停顿,大部分的时间间隔出现在一个特定的值,总的延迟就是泊松分布值和偏移值之和。
上面表示暂停时间会分布在 100到400毫秒之间:
(1)Lambda(in milliseconds):兰布达值(以毫秒为单位);
(2)Constant Delay Offset(in milliseconds):固定延迟偏移(以毫秒为单位),暂停的毫秒数减去随机延迟的毫秒数。
8、高斯随机定时器(Gaussian Random Timer)
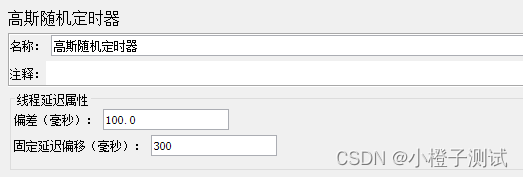
高斯定时器,生成一个呈高斯分布的时间间隔。
如需要每个线程的延迟时间是符合标准正态分布的随机时间停顿,那么使用这个定时器,总延迟 = 高斯分布值(平均0.0和标准偏差1.0)* 指定的偏差值+固定延迟偏移(计算参考:Math.abs((this.random.nextGaussian() * 偏差值) + 固定延迟偏移))。
总延迟时间 = 高斯分布值(平均0.0和标准差1.0)* 指定的偏差值 + 固定延迟偏移。
参数说明
- Deviation(偏差):偏差值,是一个浮动范围;
- Constant Delay Offset(固定延迟偏移):固定延迟时间。
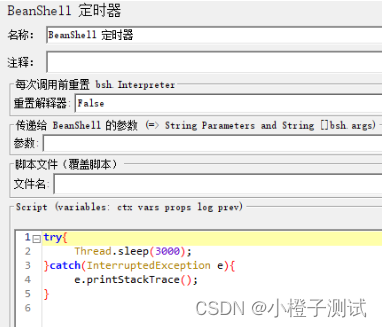
9、BeanShell定时器(BeanShell Timer)
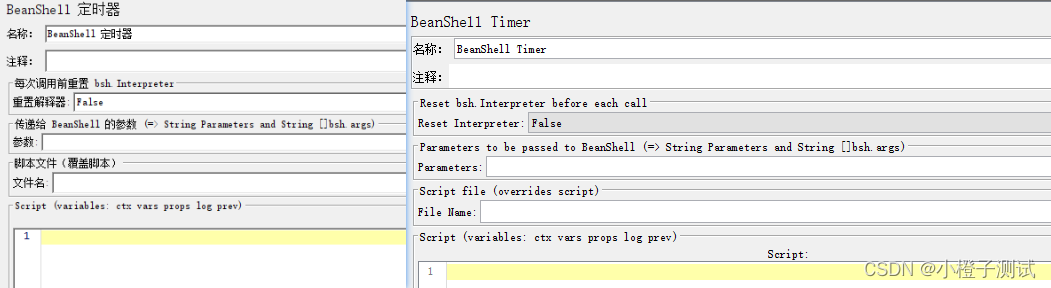
Bean Shell定时器,顾名思义是:互相交替,其节点下的取样器交替执行。根据被控制器触发执行次数,去依次执行控制器下的子节点<逻辑控制器、采样器>。被触发执行可以由线程组的线程数、循环次数、逻辑控制器触发。
参数说明
Reset Interpreter(重置解释器):
每次迭代是否重置解析器,默认为 false;在长时间运行的脚本中建议设置为 true。
Parameters(参数:String 或者 String[] ):
BeanShell 脚本的入参。入参可以是单个变量(字符串);也可以是(字符串)数组,若是字符串数组,两个元素之间用空格隔开;也可以是常量。
File Name(文件名):
BeanShell 脚本可以从脚本文件中读取。
Script(脚本):
在 Script 区直接写 BeanShell 脚本。
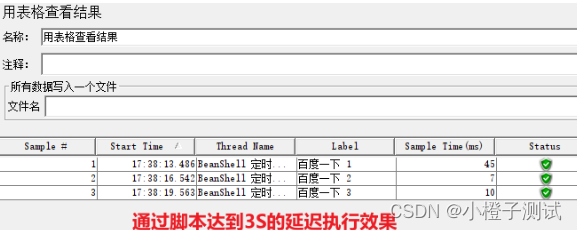
演示