目录
5.1 体验 1:Hive 使用起来和 MySQL 差不多吗?
5.2 体验 2:Hive 如何才能将结构化数据映射成为表?
一、Apache Hive 元数据
1.1 Hive Metadata
元数据(Metadata),又称中介数据、中继数据,为描述数据的数据(data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
Hive Metadata 即 Hive 的元数据。包含用 Hive 创建的 database、table、表的位置、类型、属性,字段顺序类型等元信息。元数据存储在关系型数据库中。如 hive 内置的 Derby、或者第三方如 MySQL 等。
1.2 Hive Metastore
Metastore 即元数据服务。Metastore 服务的作用是管理 metadata 元数据,对外暴露服务地址,让各种客户端通过连接 metastore 服务,由 metastore 再去连接 MySQL 数据库来存取元数据。
有了 metastore 服务,就可以有多个客户端同时连接,而且这些客户端不需要知道 MySQL 数据库的用户名和密码,只需要连接 metastore 服务即可。某种程度上也保证了 hive 元数据的安全。

二、Metastore 三种配置方式
metastore 服务配置有 3 种模式:内嵌模式、本地模式、远程模式。区分 3 种配置方式的关键是弄清楚两个问题:
-
Metastore 服务是否需要单独配置、单独启动?
-
Metadata 是存储在内置的 derby 中,还是第三方 RDBMS,比如 MySQL。
本此使用企业推荐模式--远程模式部署。
 2.1 内嵌模式
2.1 内嵌模式
内嵌模式(Embedded Metastore)是 metastore 默认部署模式。此种模式下,元数据存储在内置的 Derby 数据库,并且 Derby 数据库和 metastore 服务都嵌入在主 HiveServer 进程中,当启动 HiveServer 进程时,Derby 和 metastore 都会启动。不需要额外起 Metastore 服务。但是一次只能支持一个活动用户,适用于测试体验,不适用于生产环境。
 2.2 本地模式
2.2 本地模式
本地模式(Local Metastore)下,Metastore 服务与主 HiveServer 进程在同一进程中运行,但是存储元数据的数据库在单独的进程中运行,并且可以在单独的主机上。metastore 服务将通过 JDBC 与 metastore 数据库进行通信。
本地模式采用外部数据库来存储元数据,推荐使用 MySQL。hive 根据 hive.metastore.uris 参数值来判断,如果为空,则为本地模式。缺点是:每启动一次 hive 服务,都内置启动了一个 metastore。
 2.3 远程模式
2.3 远程模式
远程模式(Remote Metastore)下,Metastore 服务在其自己的单独 JVM 上运行,而不在 HiveServer 的 JVM 中运行。如果其他进程希望与 Metastore 服务器通信,则可以使用 Thrift Network API 进行通信。
远程模式下,需要配置 hive.metastore.uris 参数来指定 metastore 服务运行的机器 ip 和端口,并且需要单独手动启动 metastore 服务。元数据也采用外部数据库来存储元数据,推荐使用 MySQL。
在生产环境中,建议用远程模式来配置 Hive Metastore。在这种情况下,其他依赖 hive 的软件都可以通过 Metastore 访问 hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。
 三、Hive 部署实战
三、Hive 部署实战
3.1 安装前准备
由于 Apache Hive 是一款基于 Hadoop 的数据仓库软件,通常部署运行在 Linux 系统之上。因此不管使用何种方式配置 Hive Metastore,必须要先保证服务器的基础环境正常,Hadoop 集群健康可用。
服务器基础环境:集群时间同步、防火墙关闭、主机 Host 映射、免密登录、JDK 安装等。
Hadoop 集群健康可用:启动 Hive 之前必须先启动 Hadoop 集群。特别要注意,需等待 HDFS 安全模式关闭之后再启动运行 Hive。
Hive 不是分布式安装运行的软件,其分布式的特性主要借由 Hadoop 完成。包括分布式存储、分布式计算。
本次是基于该 Hadoop 集群上部署 Hive:Hadoop YARN HA 集群安装部署详细图文教程_Stars.Sky的博客-CSDN博客
3.2 Hadoop 与 Hive 整合
因为 Hive 需要把数据存储在 HDFS 上,并且通过 MapReduce 作为执行引擎处理数据;因此需要在 Hadoop 中添加相关配置属性,以满足 Hive 在 Hadoop 上运行。修改 Hadoop 中 core-site.xml,并且 Hadoop 集群同步配置文件,重启生效。
(base) [root@hadoop01 ~]# cd /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop/
(base) [root@hadoop01 /bigdata/hadoop/server/hadoop-3.2.4/etc/hadoop]# vim core-site.xml
<!-- 整合 hive -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>3.3 远程模式安装
远程模式最大的特点有两个:
-
需要安装 MySQL 来存储 Hive 元数据;
-
需要手动单独配置启动 Metastore 服务。
3.3.1 安装 MySQL
本次安装 MySQL 5.7 版本:Linux 部署 JDK+MySQL+Tomcat 详细过程_linux上 tomcat 连接mysql_Stars.Sky的博客-CSDN博客
3.3.2 Hive 安装
Hive 官方下载地址:Index of /hive/hive-3.1.2
mysql-connector-java-5.1.32.jar 官方下载地址:MySQL :: Download MySQL Connector/J (Archived Versions)
第三方下载地址:mysql-connector-java-5.1.32.jar下载及Maven、Gradle引入代码,pom文件及包内class -时代Java
#1. 解压安装包
(base) [root@hadoop01 ~]# tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /bigdata/
(base) [root@hadoop01 ~]# mv /bigdata/apache-hive-3.1.2-bin/ /bigdata/apache-hive-3.1.2
#2. 解决 hadoop、hive 之间 guava 版本差异
(base) [root@hadoop01 ~]# cd /bigdata/apache-hive-3.1.2/
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# rm -rf lib/guava-19.0.jar
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# cp /bigdata/hadoop/server/hadoop-3.2.4/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
#3. 添加 mysql jdbc 驱动到 hive 安装包 lib/ 文件下
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2/lib]# pwd
/bigdata/apache-hive-3.1.2/lib
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2/lib]# mv mysql-connector-java-5.1.32-bin.jar mysql-connector-java-5.1.32.jar
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2/lib]# ls mysql-connector-java-5.1.32.jar
mysql-connector-java-5.1.32.jar
#4. 修改 hive 环境变量文件,添加 Hadoop_HOME
(base) [root@hadoop01 ~]# cd /bigdata/apache-hive-3.1.2/conf/
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2/conf]# mv hive-env.sh.template hive-env.sh
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2/conf]# vim hive-env.sh
export HADOOP_HOME=/bigdata/hadoop/server/hadoop-3.2.4
export HIVE_CONF_DIR=/bigdata/apache-hive-3.1.2/conf
export HIVE_AUX_JARS_PATH=/bigdata/apache-hive-3.1.2/lib
#5. 新增 hive-site.xml 配置 mysql 等相关信息
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2/conf]# vim hive-site.xml
<configuration>
<!-- 存储元数据 mysql 相关配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value> jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- mysql 用户 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- mysql 密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>qwe123456</value>
</property>
<!-- H2S 运行绑定 host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop01</value>
</property>
<!-- 远程模式部署 metastore 服务地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop01:9083</value>
</property>
<!-- 关闭元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- 关闭元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration>
#6. 初始化 metadata,初始化成功会在 mysql 中创建 74 张表
(base) [root@hadoop01 ~]# cd /bigdata/apache-hive-3.1.2/
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# bin/schematool -initSchema -dbType mysql -verbos3.4 启动 Hive 服务
提前启动 hadoop 集群!!!
3.4.1 前台启动(不推荐)
关闭 ctrl+c
(base) [root@hadoop01 ~]# /bigdata/apache-hive-3.1.2/bin/hive --service metastore
# 前台启动开启 debug 日志
/bigdata/apache-hive-3.1.2/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console3.4.2 后台启动(推荐)
关闭使用 jps + kill
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# nohup /bigdata/apache-hive-3.1.2/bin/hive --service metastore &
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# jps
3347 QuorumPeerMain
3830 DataNode
5018 NodeManager
3643 NameNode
4827 ResourceManager
4412 DFSZKFailoverController
5676 Jps
4157 JournalNode
5549 RunJar四、Apache Hive 客户端使用
4.1 bin/hive、bin/beeline
Hive 发展至今,总共历经了两代客户端工具。
第一代客户端(deprecated 不推荐使用):$HIVE_HOME/bin/hive,是一个 shell Util。主要功能:一是可用于以交互或批处理模式运行 Hive 查询;二是用于 Hive 相关服务的启动,比如 metastore 服务。
第二代客户端(recommended 推荐使用):$HIVE_HOME/bin/beeline,是一个 JDBC 客户端,是官方强烈推荐使用的 Hive 命令行工具,和第一代客户端相比,性能加强安全性提高。
Beeline 在嵌入式模式和远程模式下均可工作。在嵌入式模式下,它运行嵌入式 Hive(类似于Hive Client);而远程模式下 beeline 通过 Thrift 连接到单独的 HiveServer2 服务上,这也是官方推荐在生产环境中使用的模式。那么问题来了,HiveServer2 是什么?HiveServer1 哪里去了?

4.2 HiveServer、HiveServer2 服务
HiveServer、HiveServer2 都是 Hive 自带的两种服务,允许客户端在不启动 CLI(命令行)的情况下对 Hive 中的数据进行操作,且两个都允许远程客户端使用多种编程语言如 java,python 等向 hive 提交请求,取回结果。
但是,HiveServer 不能处理多于一个客户端的并发请求。因此在 Hive-0.11.0 版本中重写了 HiveServer 代码得到了 HiveServer2,进而解决了该问题。HiveServer 已经被废弃。HiveServer2 支持多客户端的并发和身份认证,旨在为开放 API 客户端如 JDBC、ODBC 提供更好的支持。
4.3 关系梳理
HiveServer2 通过 Metastore 服务读写元数据。所以在远程模式下,启动 HiveServer2 之前必须先首先启动 metastore 服务。
特别注意:远程模式下,Beeline 客户端只能通过 HiveServer2 服务访问 Hive。而 bin/hive 是通过 Metastore 服务访问的。具体关系如下:

4.4 bin/hive 客户端使用
在 hive 安装包的 bin 目录下,有 hive 提供的第一代客户端 bin/hive。该客户端可以访问 hive的 metastore 服务,从而达到操作 hive 的目的。
友情提示:如果您是远程模式部署,请手动启动运行 metastore 服务。如果是内嵌模式和本地模式,直接运行 bin/hive,metastore 服务会内嵌一起启动。可以直接在启动 Hive metastore 服务的机器上使用 bin/hive 客户端操作,此时不需要进行任何配置。
如果需要在其他机器上通过 bin/hive 访问 hive metastore 服务,只需要把 hadoop01 上的 hive 安装目录 scp 发送到其他机器上,并在该机器的 hive-site.xml 配置中添加 metastore 服务地址即可。
(base) [root@hadoop01 /bigdata]# scp -r apache-hive-3.1.2 hadoop02:$PWD
# 到 hadoop02 上操作
(base) [root@hadoop02 ~]# vim /bigdata/apache-hive-3.1.2/conf/hive-site.xml
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop01:9083</value>
</property>
</configuration>
# 启动 metastore 服务
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# nohup /bigdata/apache-hive-3.1.2/bin/hive --service metastore &
# hadoop02 上连接客户端
(base) [root@hadoop02 ~]# /bigdata/apache-hive-3.1.2/bin/hive

4.5 bin/beeline 客户端使用
hive 经过发展,推出了第二代客户端 beeline,但是 beeline 客户端不是直接访问 metastore 服务的,而是需要单独启动 hiveserver2 服务。在 hive 安装的服务器上,首先启动 metastore 服务,然后启动 hiveserver2 服务。
# 先启动 metastore 服务然后启动 hiveserver2 服务
nohup /bigdata/apache-hive-3.1.2/bin/hive --service metastore &
nohup /bigdata/apache-hive-3.1.2/bin/hive --service hiveserver2 &
在 hadoop02 上使用 beeline 客户端进行连接访问。需要注意 hiveserver2 服务启动之后需要稍等一会才可以对外提供服务。
Beeline 是 JDBC 的客户端,通过 JDBC 协议和 Hiveserver2 服务进行通信,协议的地址是:jdbc:hive2://hadoop01:10000
(base) [root@hadoop02 ~]# /bigdata/apache-hive-3.1.2/bin/beeline
beeline> ! connect jdbc:hive2://hadoop01:10000
Connecting to jdbc:hive2://hadoop01:10000
Enter username for jdbc:hive2://hadoop01:10000: root
Enter password for jdbc:hive2://hadoop01:10000:

五、Apache Hive 初体验
5.1 体验 1:Hive 使用起来和 MySQL 差不多吗?
5.1.1 背景
对于初次接触 Apache Hive 的人来说,最大的疑惑就是:Hive 从数据模型看起来和关系型数据库 MySQL 等好像。包括 Hive SQL 也是一种类 SQL 语言。那么实际使用起来如何?
5.1.2 过程
体验步骤:按照 mysql 的思维,在 hive 中创建、切换数据库,创建表并执行插入数据操作,最后查询是否插入成功。
--创建数据库
create database test;
--列出所有数据库
show databases;
--切换数据库
use test;
--建表
create table t_student(id int,name varchar(255));
--插入一条数据
insert into table t_student values(1,"allen");
--查询表数据
select * from t_student;
在执行插入数据的时候,发现插入速度极慢,sql 执行时间很长,为什么?

最终插入一条数据,历史 98 秒的时间。查询表数据,显示数据插入成功:

查询表数据,显示数据插入成功。
5.1.3 验证
首先登陆 Hadoop YARN 上观察是否有 MapReduce 任务执行痕迹。 YARN Web UI:http://hadoop01:8088/cluster

然后登陆 Hadoop HDFS 浏览文件系统,根据 Hive 的数据模型,表的数据最终是存储在 HDFS 和表对应的文件夹下的。
HDFS Web UI: http://hadoop01:9870/
 5.1.4 结论
5.1.4 结论
- Hive SQL 语法和标准 SQL 很类似,使得学习成本降低不少。
- Hive 底层是通过 MapReduce 执行的数据插入动作,所以速度慢。
- 如果大数据集这么一条一条插入的话是非常不现实的,成本极高。
- Hive 应该具有自己特有的数据插入表方式,结构化文件映射成为表。
5.2 体验 2:Hive 如何才能将结构化数据映射成为表?
5.2.1 背景
在 Hive 中,使用 insert+values 语句插入数据,底层是通过 MapReduce 执行的,效率十分低下。此时回到 Hive 的本质上:可以将结构化的数据文件映射成为一张表,并提供基于表的 SQL 查询分析。
假如,现在有一份结构化的数据文件,如何才能映射成功呢?在映射成功的过程中需要注意哪些问题?文件存储路径?字段类型?字段顺序?字段之间分隔符?
5.2.2 过程
在 HDFS 根目录下创建一个结构化数据文件 user.txt,里面内容如下:
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# vim user.txt
1,zhangsan,18,beijing
2,lisi,25,shanghai
3,allen,30,shanghai
4,woon,15,nanjing
5,james,45,hangzhou
6,tony,26,beijing
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# hadoop fs -put user.txt /
在 hive 中创建一张表 t_user。注意:字段的类型顺序要和文件中字段保持一致。
create table t_user(id int,name varchar(255),age int,city varchar(255));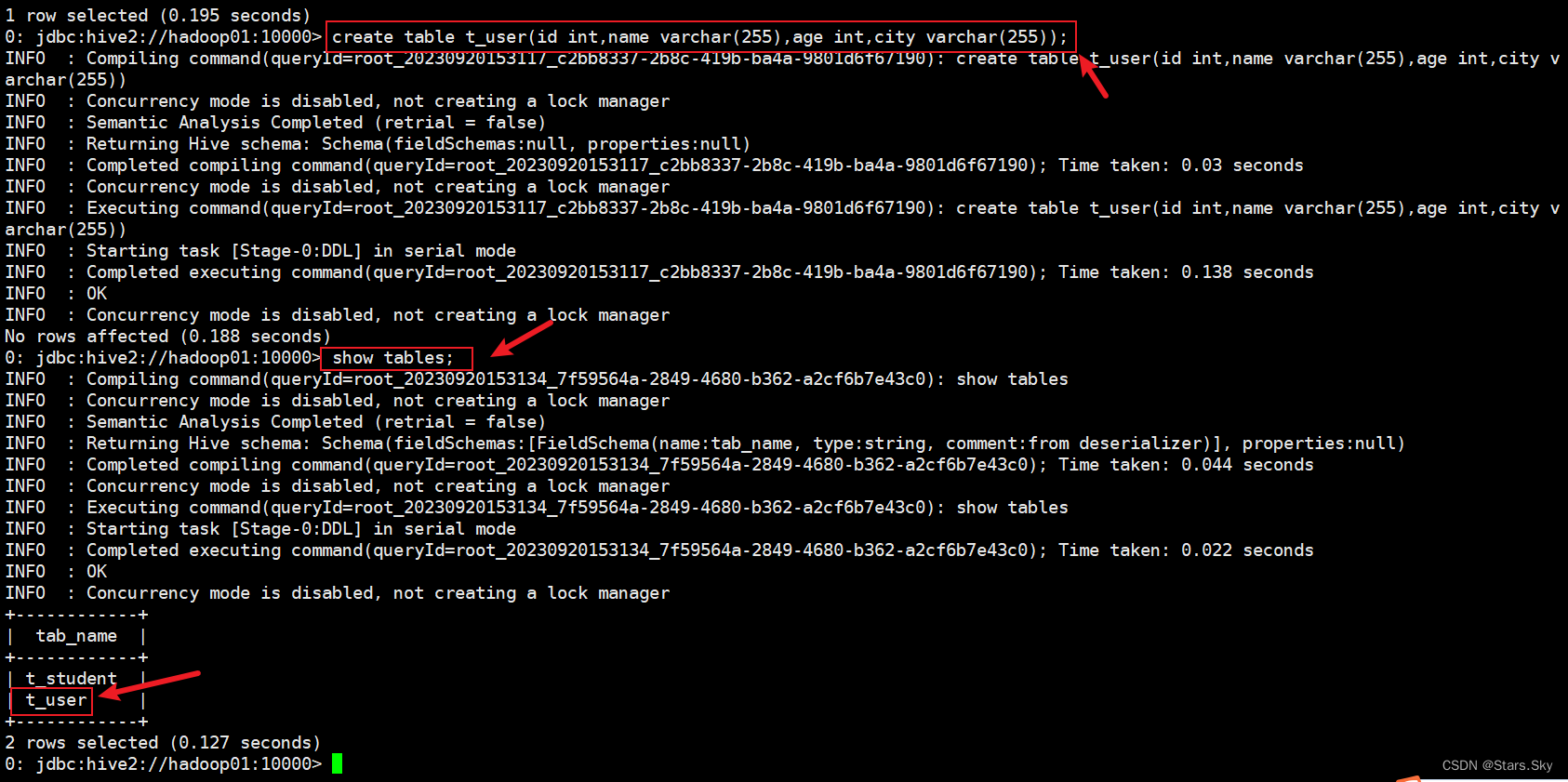
5.2.3 验证
执行数据查询操作,发现表中并没有数据。猜想 1:难道数据文件要放置在表对应的 HDFS 路径下才可以成功?使用 HDFS 命令将数据移动到表对应的路径下。
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# hadoop fs -mv /user.txt /user/hive/warehouse/test.db/t_user
(base) [root@hadoop01 /bigdata/apache-hive-3.1.2]# hadoop fs -ls /user/hive/warehouse/test.db/t_user
Found 1 items
-rw-r--r-- 3 root supergroup 117 2023-09-20 15:28 /user/hive/warehouse/test.db/t_user/user.txt再次执行查询操作,显示如下,都是 null:
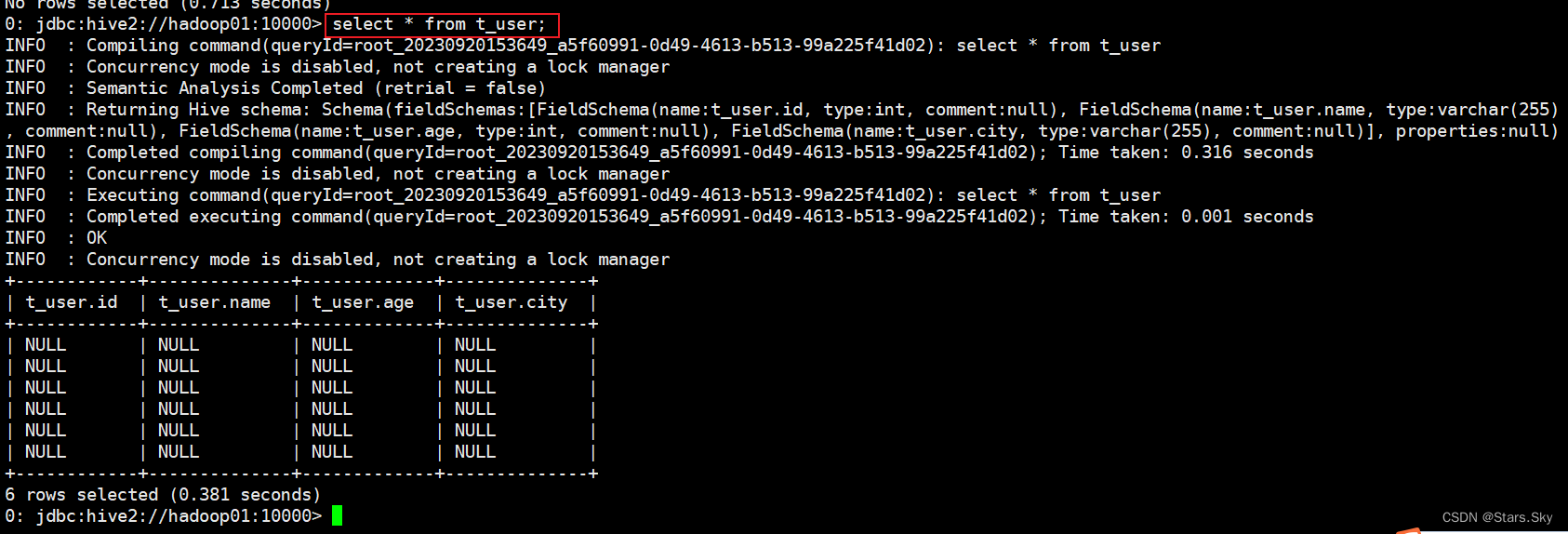
好像表感知到结构化文件的存在,但是并没有正确识别文件中的数据。猜想 2:还需要指定文件中字段之间的分隔符?重建张新表,指定分隔符。
--建表语句 增加分隔符指定语句
create table t_user_1(id int,name varchar(255),age int,city varchar(255))
row format delimited
fields terminated by ',';
# 把 user.txt 文件从本地文件系统上传到 hdfs
hadoop fs -put user.txt /user/hive/warehouse/test.db/t_user_1/
--执行查询操作
select * from t_user_1;
 此时再创建一张表,保存分隔符语法,但是故意使得字段类型和文件中不一致。
此时再创建一张表,保存分隔符语法,但是故意使得字段类型和文件中不一致。
--建表语句 增加分隔符指定语句
create table t_user_2(id int,name int,age varchar(255),city varchar(255))
row format delimited
fields terminated by ',';
# 把 user.txt 文件从本地文件系统上传到hdfs
hadoop fs -put user.txt /user/hive/warehouse/test.db/t_user_2/
--执行查询操作
select * from t_user_2;

此时发现,有的列显示 null,有的列显示正常。name 字段本身是字符串,但是建表的时候指定 int,类型转换不成功;age 是数值类型,建表指定字符串类型,可以转换成功。说明 hive 中具有自带的类型转换功能,但是不一定保证转换成功。
5.2.4 结论
要想在 hive 中创建表跟结构化文件映射成功,需要注意以下几个方面问题:
-
创建表时,字段顺序、字段类型要和文件中保持一致。
-
如果类型不一致,hive 会尝试转换,但是不保证转换成功。不成功显示 null。
-
文件好像要放置在 Hive 表对应的 HDFS 目录下,其他路径可以吗? 值得探讨。
-
建表的时候好像要根据文件内容指定分隔符,不指定可以吗?值得探讨。
5.3 体验 3:使用 Hive 进行小数据分析如何?
5.3.1 背景
因为 Hive 是基于 HDFS 进行文件的存储,所以理论上能够支持的数据存储规模很大,天生适合大数据分析。假如 Hive 中的数据是小数据,再使用 Hive 开展分析效率如何呢?
5.3.2 过程
之前我们创建好了一张表 t_user_1,现在通过 Hive SQL 找出当中年龄大于 20 岁的有几个。

5.3.3 验证
--执行查询操作
select count(*) from t_user_1 where age > 20;
发现又是通过 MapReduce 程序执行的数据查询功能。
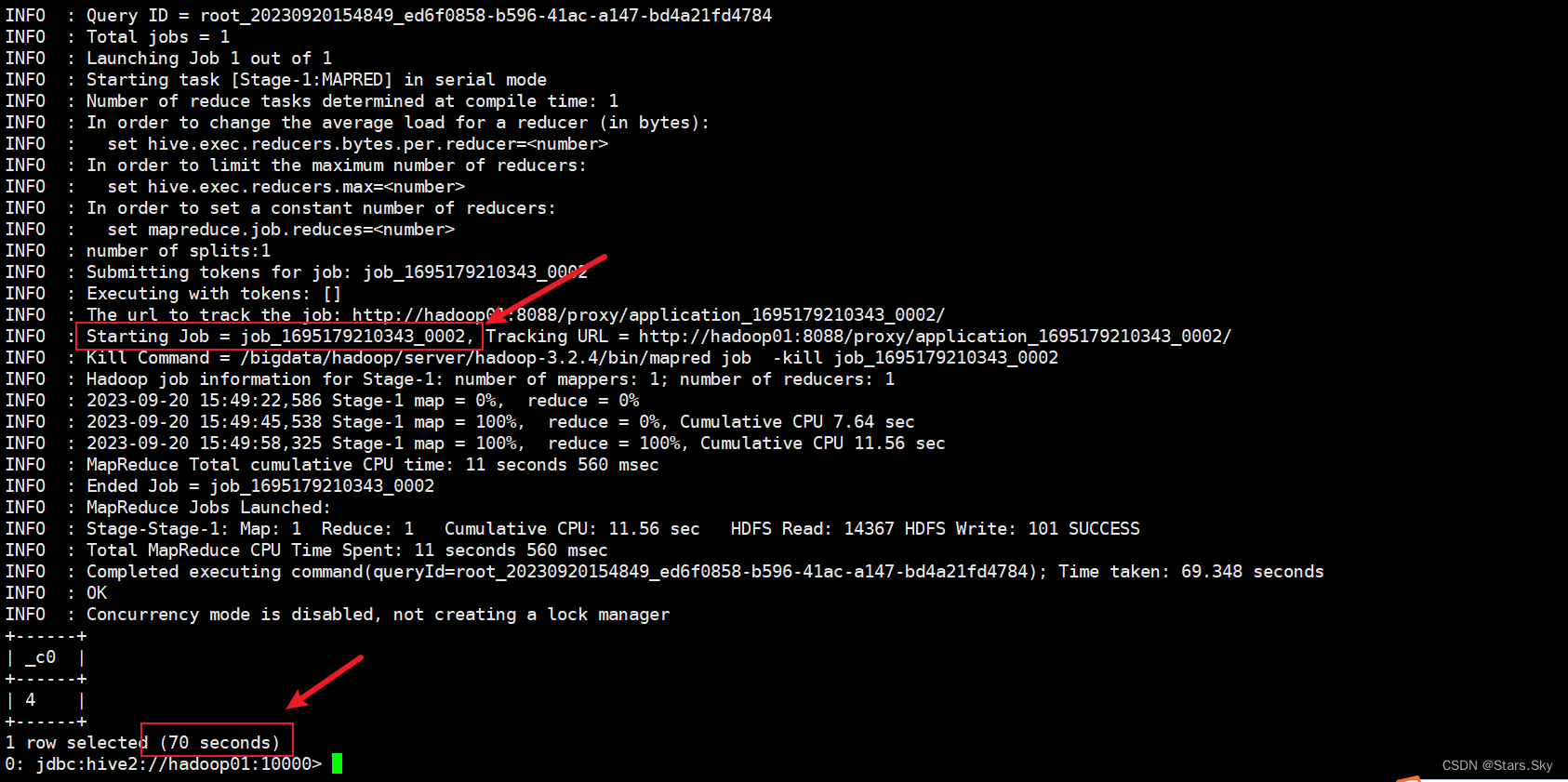
5.3.5 结论
-
Hive 底层的确是通过 MapReduce 执行引擎来处理数据的。
-
执行完一个 MapReduce 程序需要的时间不短。
-
如果是小数据集,使用 hive 进行分析将得不偿失,延迟很高。
-
如果是大数据集,使用 hive 进行分析,底层 MapReduce 分布式计算,会很爽。








