这是Mysql系列第23篇。
环境:mysql5.7.25,cmd命令中进行演示。
代码中被[]包含的表示可选,|符号分开的表示可选其一。
关于索引的,可以先看一下前2篇文章:
本文主要介绍mysql中索引常见的管理操作。
索引分类
分为聚集索引和非聚集索引。
聚集索引
每个表有且一定会有一个聚集索引,整个表的数据存储在聚集索引中,mysql索引是采用B+树结构保存在文件中,叶子节点存储主键的值以及对应记录的数据,非叶子节点不存储记录的数据,只存储主键的值。当表中未指定主键时,mysql内部会自动给每条记录添加一个隐藏的rowid字段(默认4个字节)作为主键,用rowid构建聚集索引。
聚集索引在mysql中又叫主键索引。
非聚集索引(辅助索引)
也是b+树结构,不过有一点和聚集索引不同,非聚集索引叶子节点存储字段(索引字段)的值以及对应记录主键的值,其他节点只存储字段的值(索引字段)。
每个表可以有多个非聚集索引。
mysql中非聚集索引分为
单列索引
即一个索引只包含一个列。
多列索引(又称复合索引)
即一个索引包含多个列。
唯一索引
索引列的值必须唯一,允许有一个空值。
数据检索的过程
看一张图:
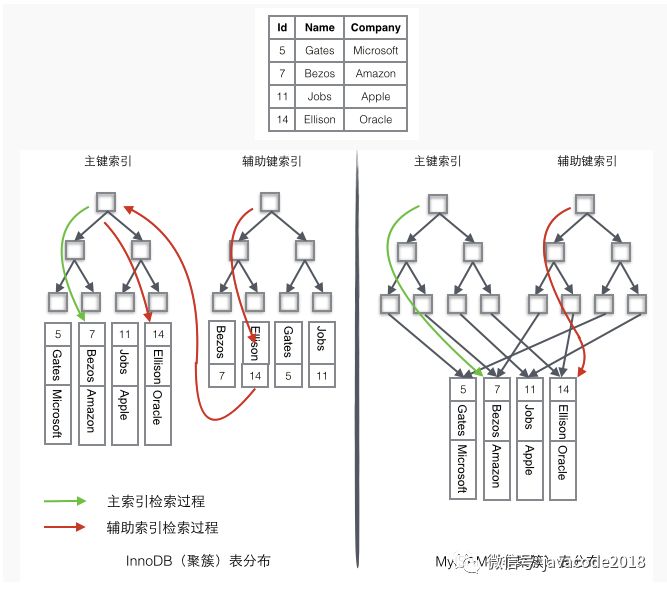
上面的表中有2个索引:id作为主键索引,name作为辅助索引。
innodb我们用的最多,我们只看图中左边的innodb中数据检索过程:
如果需要查询id=14的数据,只需要在左边的主键索引中检索就可以了。
如果需要搜索name='Ellison'的数据,需要2步:
-
先在辅助索引中检索到name='Ellison'的数据,获取id为14
-
再到主键索引中检索id为14的记录
辅助索引相对于主键索引多了第二步。
索引管理
创建索引
方式1:
create [unique] index 索引名称 on 表名(列名[(length)]);
方式2:
alter 表名 add [unique] index 索引名称 on (列名[(length)]);
如果字段是char、varchar类型,length可以小于字段实际长度,如果是blog、text等长文本类型,必须指定length。
[unique]:中括号代表可以省略,如果加上了unique,表示创建唯一索引。
如果table后面只写一个字段,就是单列索引,如果写多个字段,就是复合索引,多个字段之间用逗号隔开。
删除索引
drop index 索引名称 on 表名;
查看索引
查看某个表中所有的索引信息如下:
show index from 表名;
索引修改
可以先删除索引,再重建索引。
示例
准备200万数据
/*建库javacode2018*/
DROP DATABASE IF EXISTS javacode2018;
CREATE DATABASE javacode2018;
USE javacode2018;
/*建表test1*/
DROP TABLE IF EXISTS test1;
CREATE TABLE test1 (
id INT NOT NULL COMMENT '编号',
name VARCHAR(20) NOT NULL COMMENT '姓名',
sex TINYINT NOT NULL COMMENT '性别,1:男,2:女',
email VARCHAR(50)
);
/*准备数据*/
DROP PROCEDURE IF EXISTS proc1;
DELIMITER $
CREATE PROCEDURE proc1()
BEGIN
DECLARE i INT DEFAULT 1;
START TRANSACTION;
WHILE i <= 2000000 DO
INSERT INTO test1 (id, name, sex, email) VALUES (i,concat('javacode',i),if(mod(i,2),1,2),concat('javacode',i,'@163.com'));
SET i = i + 1;
if i%10000=0 THEN
COMMIT;
START TRANSACTION;
END IF;
END WHILE;
COMMIT;
END $
DELIMITER ;
CALL proc1();
SELECT count(*) FROM test1;
上图中使用存储过程循环插入了200万记录,表中有4个字段,除了sex列,其他列的值都是没有重复的,表中还未建索引。
插入的200万数据中,id,name,email的值都是没有重复的。
无索引我们体验一下查询速度
mysql> select * from test1 a where a.id = 1;
+----+-----------+-----+-------------------+
| id | name | sex | email |
+----+-----------+-----+-------------------+
| 1 | javacode1 | 1 | javacode1@163.com |
+----+-----------+-----+-------------------+
1 row in set (0.77 sec)
上面我们按id查询了一条记录耗时770毫秒,我们在id上面创建个索引感受一下速度。
创建索引
我们在id上面创建一个索引,感受一下:
mysql> create index idx1 on test1 (id);
Query OK, 0 rows affected (2.82 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from test1 a where a.id = 1;
+----+-----------+-----+-------------------+
| id | name | sex | email |
+----+-----------+-----+-------------------+
| 1 | javacode1 | 1 | javacode1@163.com |
+----+-----------+-----+-------------------+
1 row in set (0.00 sec)
上面的查询是不是非常快,耗时1毫秒都不到。
我们在name上也创建个索引,感受一下查询的神速,如下:
mysql> create unique index idx2 on test1(name);
Query OK, 0 rows affected (9.67 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from test1 where name = 'javacode1';
+----+-----------+-----+-------------------+
| id | name | sex | email |
+----+-----------+-----+-------------------+
| 1 | javacode1 | 1 | javacode1@163.com |
+----+-----------+-----+-------------------+
1 row in set (0.00 sec)
查询快如闪电,有没有,索引是如此的神奇。
创建索引并指定长度
通过email检索一下数据
mysql> select * from test1 a where a.email = 'javacode1000085@163.com';
+---------+-----------------+-----+-------------------------+
| id | name | sex | email |
+---------+-----------------+-----+-------------------------+
| 1000085 | javacode1000085 | 1 | javacode1000085@163.com |
+---------+-----------------+-----+-------------------------+
1 row in set (1.28 sec)
耗时1秒多,回头去看一下插入数据的sql,我们可以看到所有的email记录,每条记录的前面15个字符是不一样的,结尾是一样的(都是@163.com),通过前面15个字符就可以定位一个email了,那么我们可以对email创建索引的时候指定一个长度为15,这样相对于整个email字段更短一些,查询效果是一样的,这样一个页中可以存储更多的索引记录,命令如下:
mysql> create index idx3 on test1 (email(15));
Query OK, 0 rows affected (7.67 sec)
Records: 0 Duplicates: 0 Warnings: 0
然后看一下查询效果:
mysql> select * from test1 a where a.email = 'javacode1000085@163.com';
+---------+-----------------+-----+-------------------------+
| id | name | sex | email |
+---------+-----------------+-----+-------------------------+
| 1000085 | javacode1000085 | 1 | javacode1000085@163.com |
+---------+-----------------+-----+-------------------------+
1 row in set (0.00 sec)
耗时不到1毫秒,神速。
查看表中的索引
我们看一下test1表中的所有索引,如下:
mysql> show index from test1;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| test1 | 0 | idx2 | 1 | name | A | 1992727 | NULL | NULL | | BTREE | | |
| test1 | 1 | idx1 | 1 | id | A | 1992727 | NULL | NULL | | BTREE | | |
| test1 | 1 | idx3 | 1 | email | A | 1992727 | 15 | NULL | YES | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 rows in set (0.00 sec)
可以看到test1表中3个索引的详细信息(索引名称、类型,字段)。
删除索引
我们删除idx1,然后再列出test1表所有索引,如下:
mysql> drop index idx1 on test1;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from test1;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| test1 | 0 | idx2 | 1 | name | A | 1992727 | NULL | NULL | | BTREE | | |
| test1 | 1 | idx3 | 1 | email | A | 1992727 | 15 | NULL | YES | BTREE | | |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
2 rows in set (0.00 sec)
本篇主要是mysql中索引管理相关一些操作,属于基础知识,希望大家掌握。
下篇文章介绍:
-
一个表应该创建哪些索引?
-
有索引时sql应该怎么写?
-
我的sql为什么不走索引?需要知道内部原理
-
where条件涉及多个字段多个索引时怎么走?
-
多表连接查询、子查询,怎么去利用索引,内部过程是什么样的?
-
like查询中前面有%的时候为何不走索引?
-
字段中使用函数的时候为什么不走索引?
-
字符串查询使用数字作为条件的时候为什么不走索引?、
-
索引区分度、索引覆盖、最左匹配、索引排序又是什么?原理是什么?
关于上面各种索引选择的问题,我们会深入其原理,让大家知道为什么是这样?而不是只去记一些优化规则,而不知道其原因,知道其原理用的时候更加得心应手一些。









