前言
前几天的时候,项目里有一个需求,需要一个开关控制代码中是否执行一段逻辑,于是理所当然的在yml文件中配置了一个属性作为开关,再配合nacos就可以随时改变这个值达到我们的目的,yml文件中是这样写的:
switch:
turnOn: on
程序中的代码也很简单,大致的逻辑就是下面这样,如果取到的开关字段是on的话,那么就执行if判断中的代码,否则就不执行:
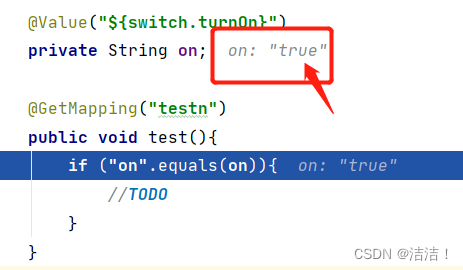
@Value("${switch.turnOn}")
private String on;
@GetMapping("testn")
public void test(){
if ("on".equals(on)){
//TODO
}
}
但是当代码实际跑起来,有意思的地方来了,我们发现判断中的代码一直不会被执行,直到debug一下,才发现这里的取到的值居然不是on而是true。
看到这,是不是感觉有点意思,首先盲猜是在解析yml的过程中把on作为一个特殊的值进行了处理,于是我干脆再多测试了几个例子,把yml中的属性扩展到下面这些:
switch:
turnOn: on
turnOff: off
turnOn2: 'on'
turnOff2: 'off'
再执行一下代码,看一下映射后的值:
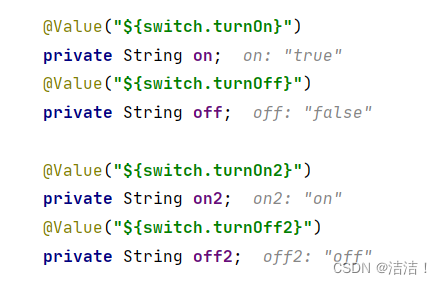
可以看到,yml中没有带引号的on和off被转换成了true和false,带引号的则保持了原来的值不发生改变。
到这里,让我忍不住有点好奇,为什么会发生这种现象呢?于是强忍着困意翻了翻源码,硬磕了一下SpringBoot加载yml配置文件的过程,终于让我看出了点门道,下面我们一点一点细说!
因为配置文件的加载会涉及到一些SpringBoot启动的相关知识,所以如果对SpringBoot启动不是很熟悉的同学,可以先提前先看一下Hydra在古早时期写过一篇Spring Boot零配置启动原理预热一下。下面的介绍中,只会摘出一些对加载和解析配置文件比较重要的步骤进行分析,对其他无关部分进行了省略。
加载监听器
当我们启动一个SpringBoot程序,在执行SpringApplication.run()的时候,首先在初始化SpringApplication的过程中,加载了11个实现了ApplicationListener接口的拦截器。
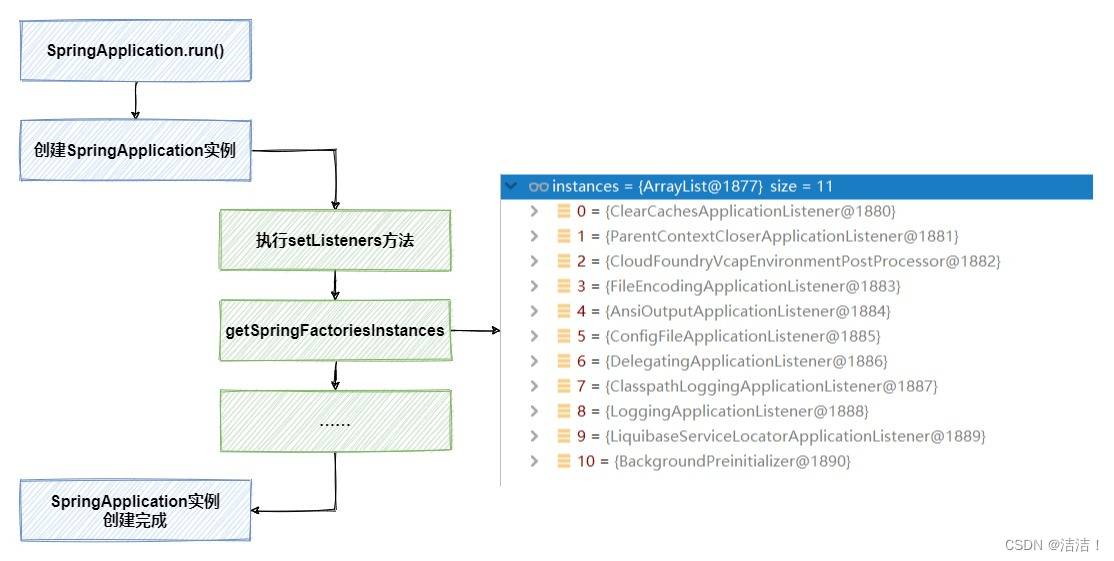
这11个自动加载的ApplicationListener,是在spring.factories中定义并通过SPI扩展被加载的:
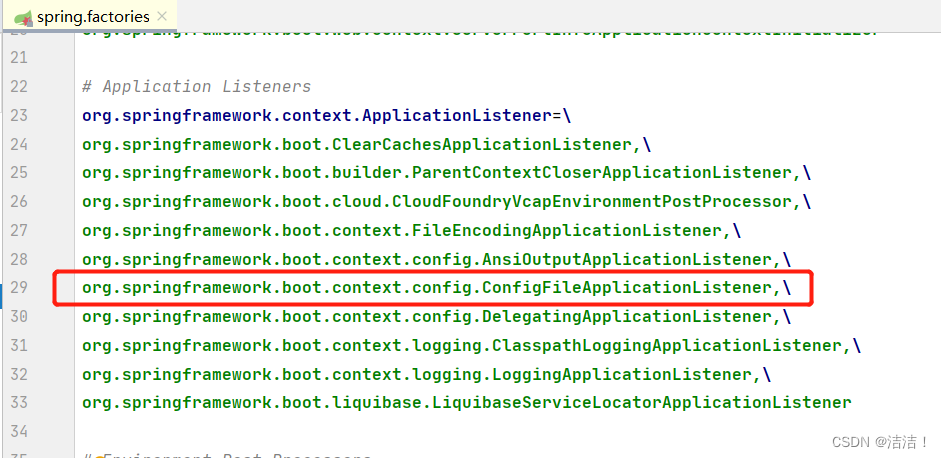
这里列出的10个是在spring-boot中加载的,还有剩余的1个是在spring-boot-autoconfigure中加载的。其中最关键的就是ConfigFileApplicationListener,它和后面要讲到的配置文件的加载相关。
执行run方法
在实例化完成SpringApplication后,会接着往下执行它的run方法。
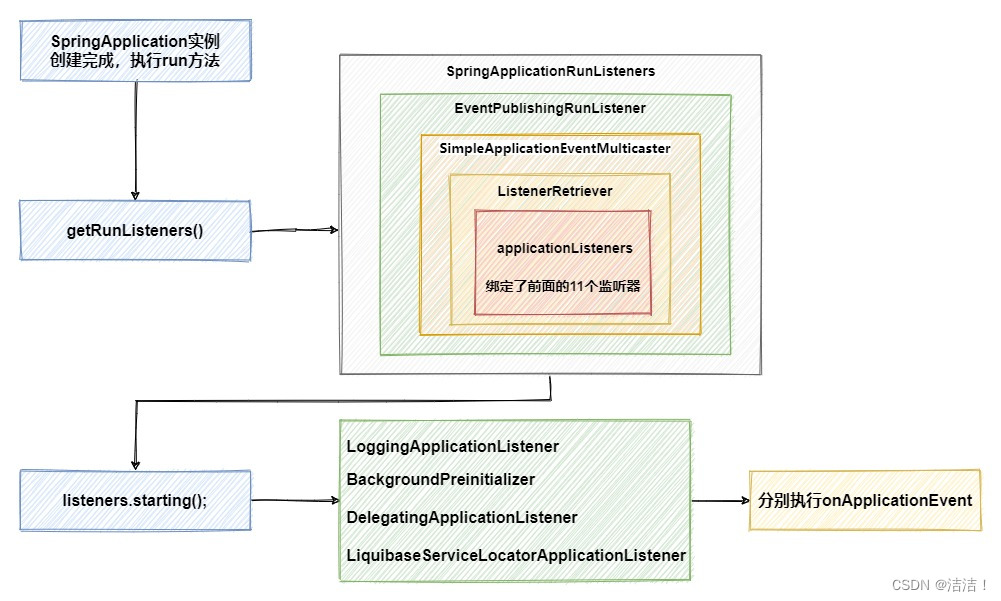
可以看到,这里通过getRunListeners方法获取的SpringApplicationRunListeners中,EventPublishingRunListener绑定了我们前面加载的11个监听器。但是在执行starting方法时,根据类型进行了过滤,最终实际只执行了4个监听器的onApplicationEvent方法,并没有我们希望看到的ConfigFileApplicationListener,让我们接着往下看。
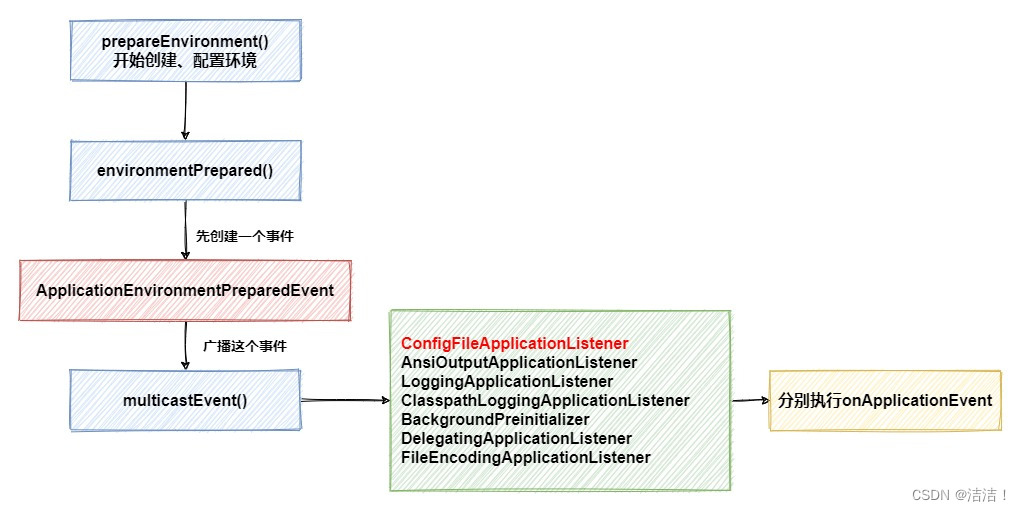
当run方法执行到prepareEnvironment时,会创建一个ApplicationEnvironmentPreparedEvent类型的事件,并广播出去。这时所有的监听器中,有7个会监听到这个事件,之后会分别调用它们的onApplicationEvent方法,其中就有了我们心心念念的ConfigFileApplicationListener,接下来让我们看看它的onApplicationEvent方法中做了什么。
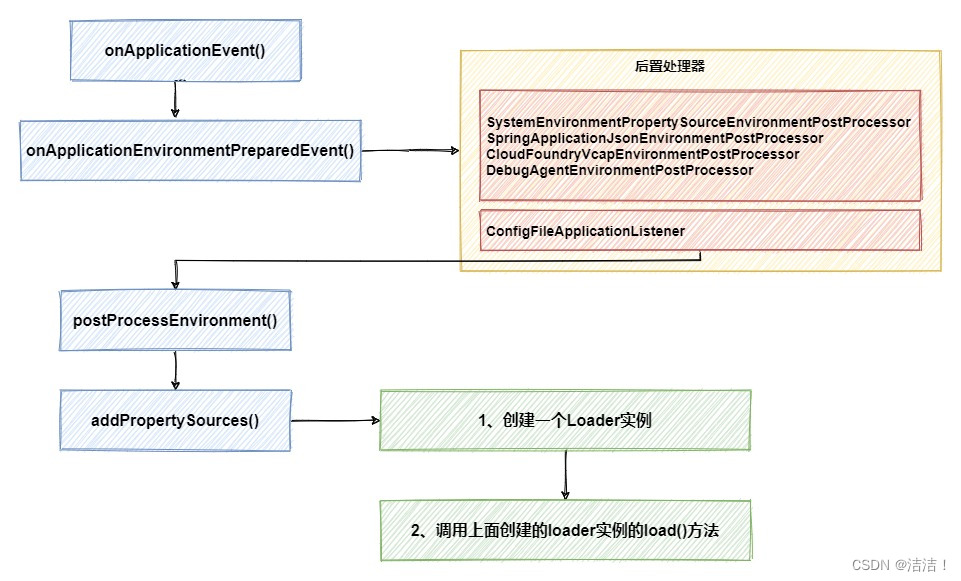
在方法的调用过程中,会加载系统自己的4个后置处理器以及ConfigFileApplicationListener自身,一共5个后置处理器,并执行他们的postProcessEnvironment方法,其他4个对我们不重要可以略过,最终比较关键的步骤是创建Loader实例并调用它的load方法。
加载配置文件
这里的Loader是ConfigFileApplicationListener的一个内部类,看一下Loader对象实例化的过程:
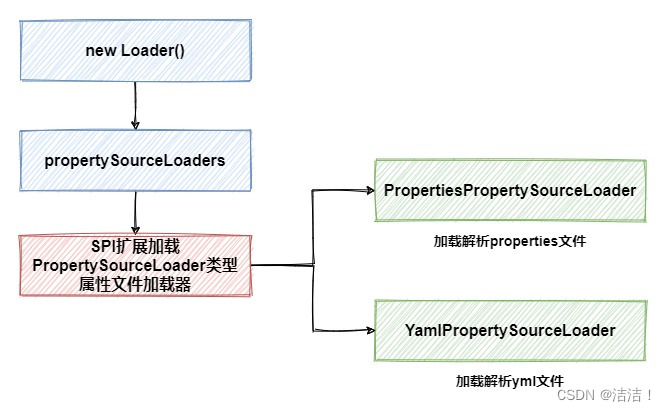
在实例化Loader对象的过程中,再次通过SPI扩展的方式加载了两个属性文件加载器,其中的YamlPropertySourceLoader就和后面的yml文件的加载、解析密切关联,而另一个PropertiesPropertySourceLoader则负责properties文件的加载。创建完Loader实例后,接下来会调用它的load方法。
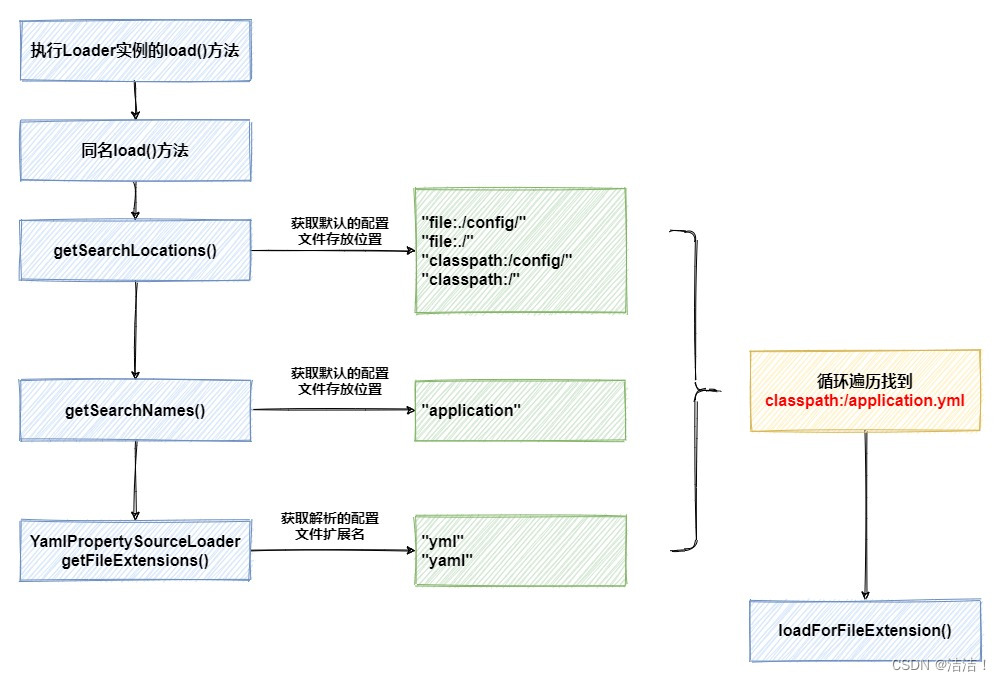
在load方法中,会通过嵌套循环方式遍历默认配置文件存放路径,再加上默认的配置文件名称、以及不同配置文件加载器对应解析的后缀名,最终找到我们的yml配置文件。接下来,开始执行loadForFileExtension方法。
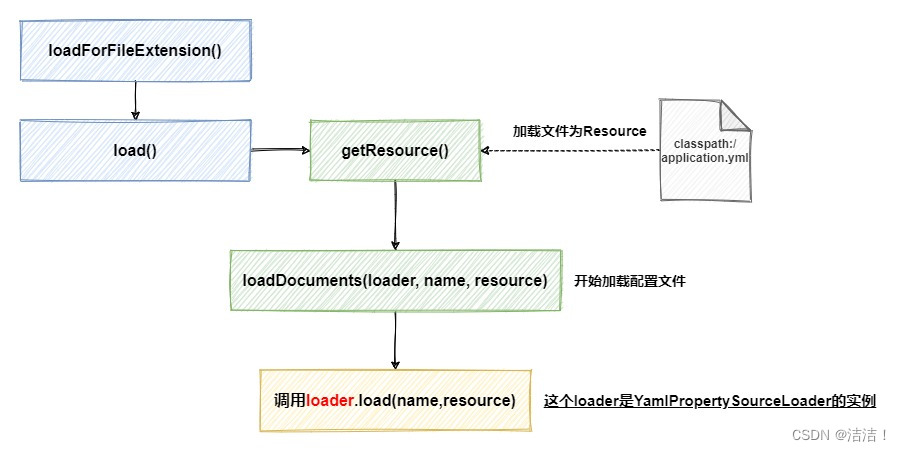
在loadForFileExtension方法中,首先将classpath:/application.yml加载为Resource文件,接下来准备正式开始,调用了之前创建好的YamlPropertySourceLoader对象的load方法。
封装Node
在load方法中,开始准备进行配置文件的解析与数据封装:
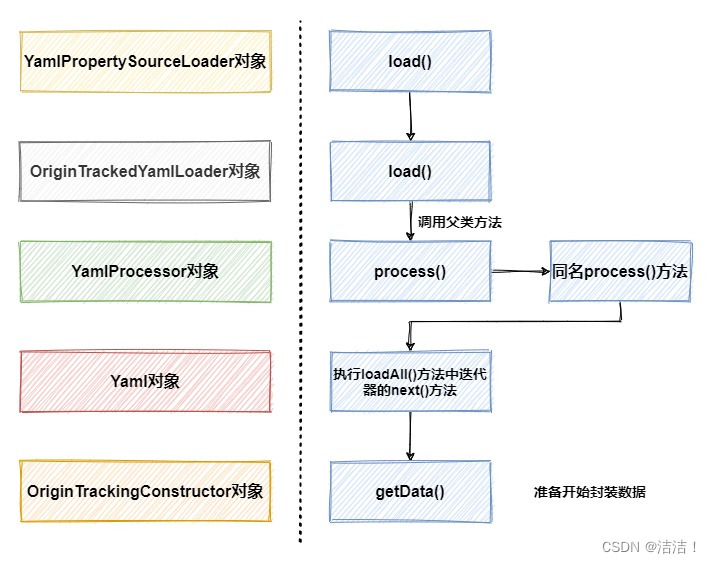
load方法中调用了OriginTrackedYmlLoader对象的load方法,从字面意思上我们也可以理解,它的用途是原始追踪yml的加载器。中间一连串的方法调用可以忽略,直接看最后也是最重要的是一步,调用OriginTrackingConstructor对象的getData接口,来解析yml并封装成对象。
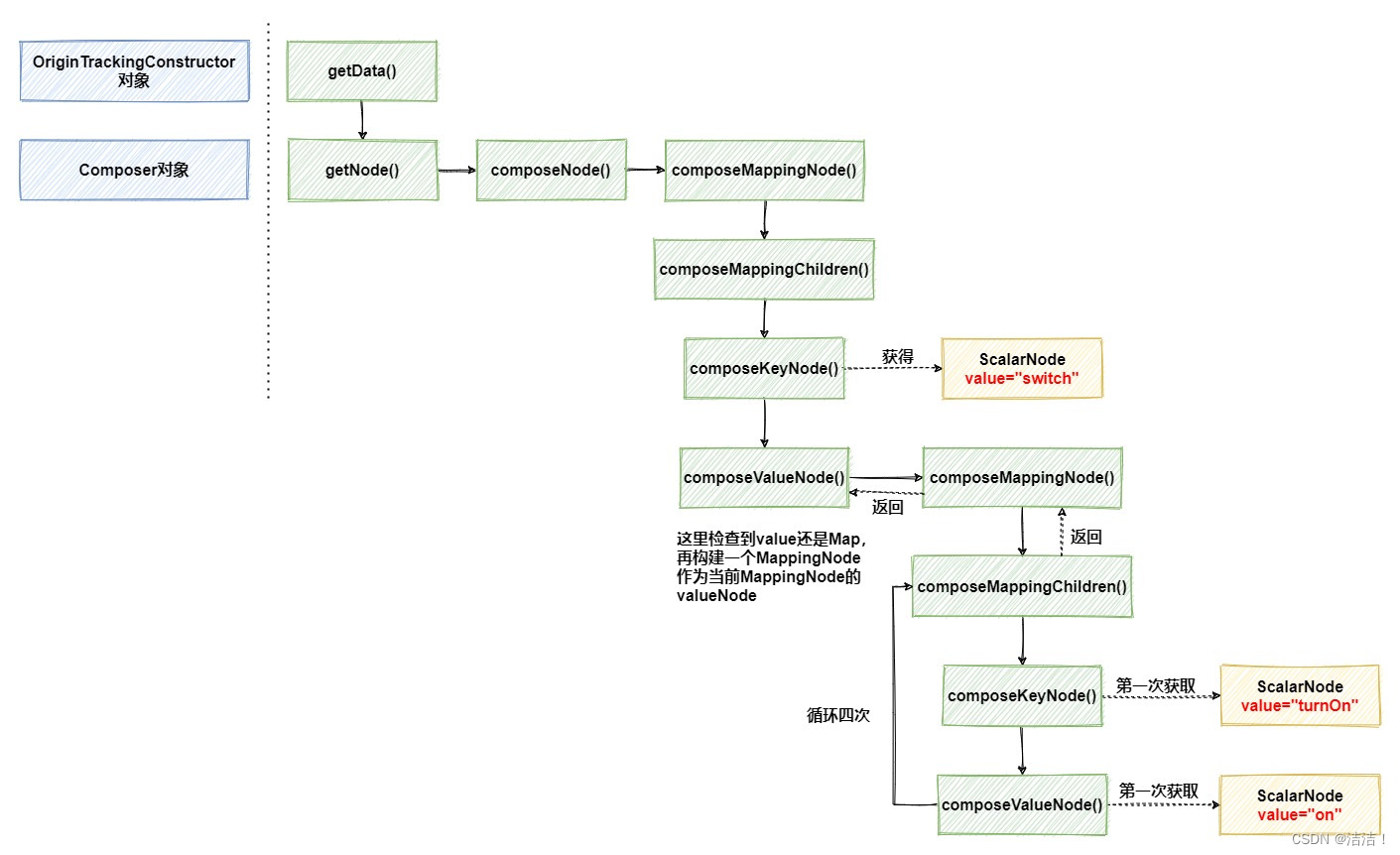
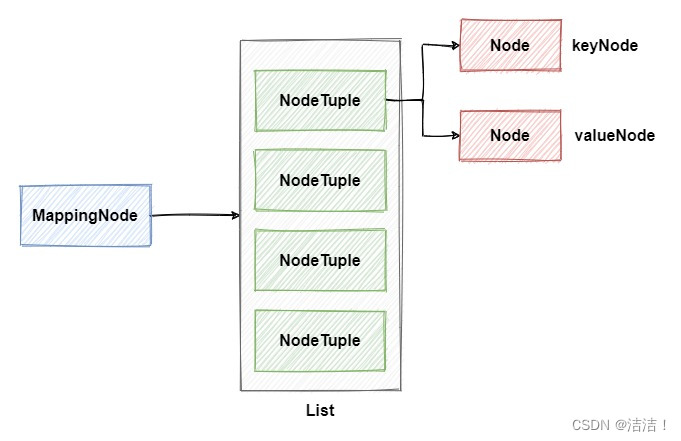
在解析yml的过程中实际使用了Composer构建器来生成节点,在它的getNode方法中,通过解析器事件来创建节点。通常来说,它会将yml中的一组数据封装成一个MappingNode节点,它的内部实际上是一个NodeTuple组成的List,NodeTuple和Map的结构类似,由一对对应的keyNode和valueNode构成,结构如下:
好了,让我们再回到上面的那张方法调用流程图,它是根据文章开头的yml文件中实际内容内容绘制的,如果内容不同调用流程会发生改变,大家只需要明白这个原理,下面我们具体分析。
首先,创建一个MappingNode节点,并将switch封装成keyNode,然后再创建一个MappingNode,作为外层MappingNode的valueNode,同时存储它下面的4组属性,这也是为什么上面会出现4次循环的原因。如果有点困惑也没关系,看一下下面的这张图,就能一目了然了解它的结构。
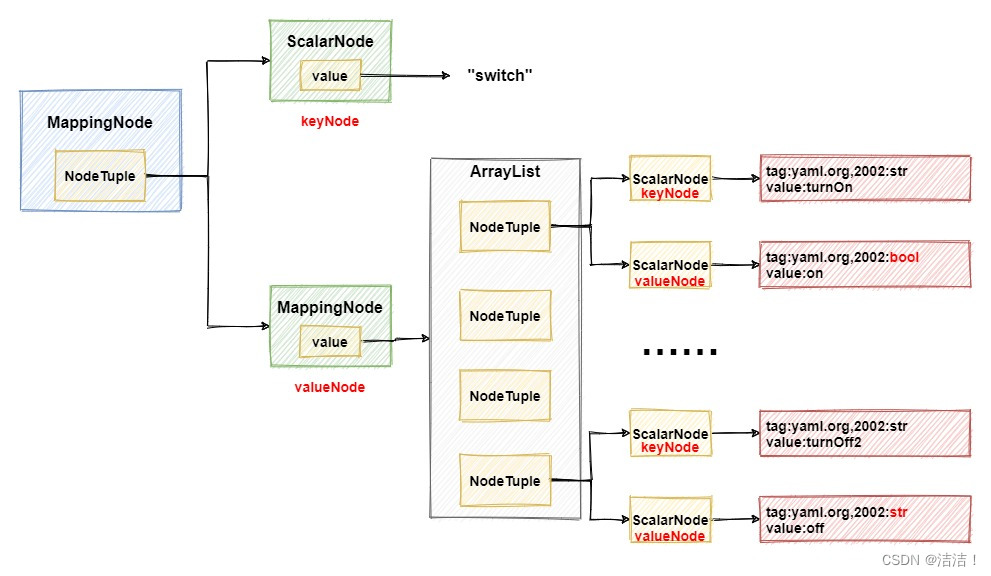
在上图中,又引入了一种新的ScalarNode节点,它的用途也比较简单,简单String类型的字符串用它来封装成节点就可以了。到这里,yml中的数据被解析完成并完成了初步的封装,可能眼尖的小伙伴要问了,上面这张图中为什么在ScalarNode中,除了value还有一个tag属性,这个属性是干什么的呢?
在介绍它的作用前,先说一下它是怎么被确定的。这一块的逻辑比较复杂,大家可以翻一下ScannerImpl类fetchMoreTokens方法的源码,这个方法会根据yml中每一个key或value是以什么开头,来决定以什么方式进行解析,其中就包括了{、[、’、%、?等特殊符号的情况。以解析不带任何特殊字符的字符串为例,简要的流程如下,省略了一些不重要部分:

在这张图的中间步骤中,创建了两个比较重要的对象ScalarToken和ScalarEvent,其中都有一个为true的plain属性,可以理解为这个属性是否需要解释,是后面获取Resolver的关键属性之一。
上图中的yamlImplicitResolvers其实是一个提前缓存好的HashMap,已经提前存储好了一些Char类型字符与ResolverTuple的对应关系:
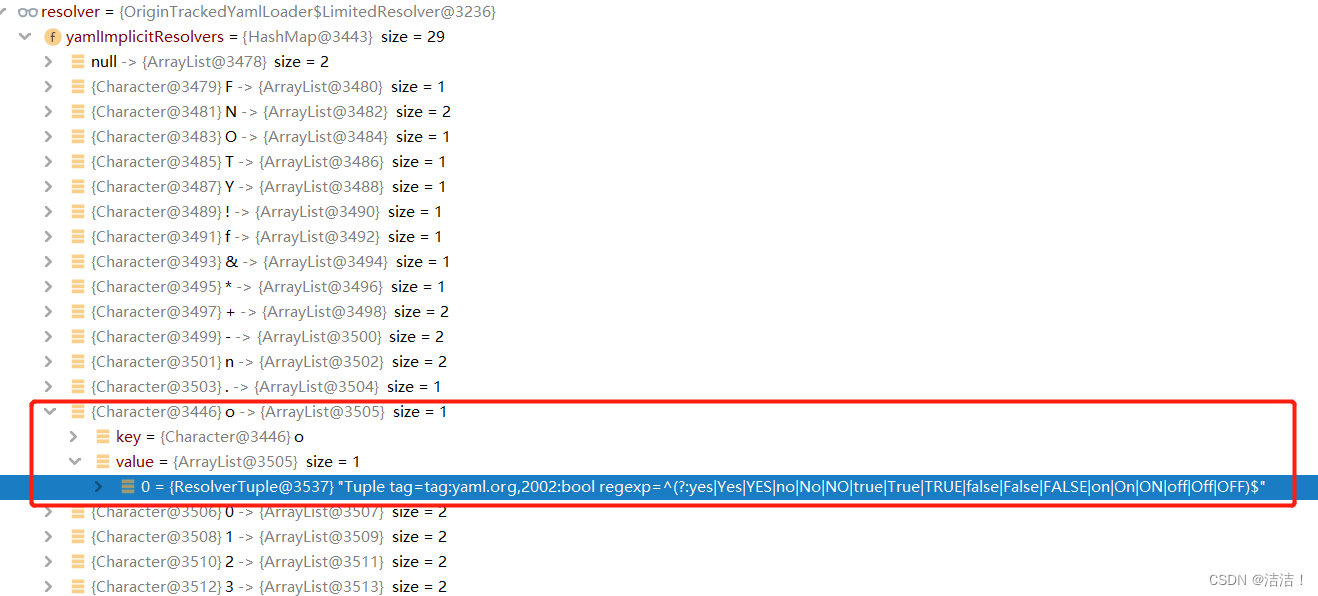
当解析到属性on时,取出首字母o对应的ResolverTuple,其中的tag就是tag:yaml.org.2002:bool。当然了,这里也不是简单的取出就完事了,后续还会对属性进行正则表达式的匹配,看与regexp中的值是否能对的上,检查无误时才会返回这个tag。
到这里,我们就解释清楚了ScalarNode中tag属性究竟是怎么获取到的了,之后方法调用层层返回,返回到OriginTrackingConstructor父类BaseConstructor的getData方法中。接下来,继续执行constructDocument方法,完成对yml文档的解析。
调用构造器
在constructDocument中,有两步比较重要,第一步是推断当前节点应该使用哪种类型的构造器,第二步是使用获得的构造器来重新对Node节点中的value进行赋值,简易流程如下,省去了循环遍历的部分:
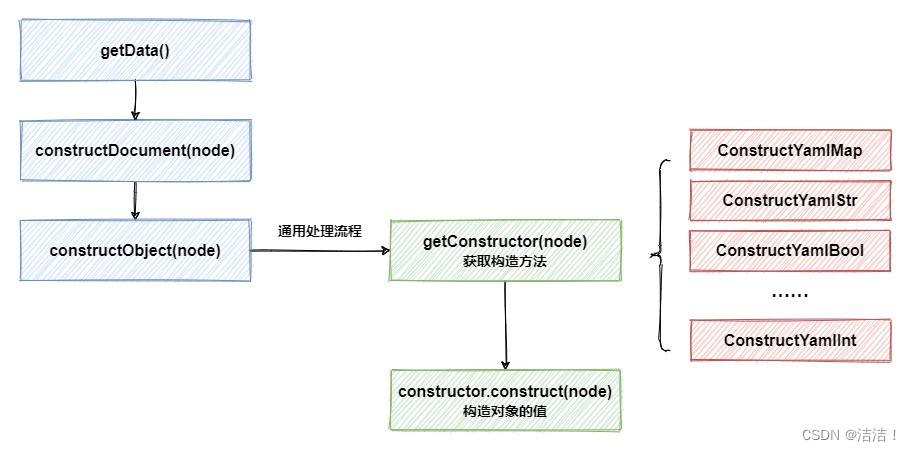
推断构造器种类的过程也很简单,在父类BaseConstructor中,缓存了一个HashMap,存放了节点的tag类型到对应构造器的映射关系。在getConstructor方法中,就使用之前节点中存入的tag属性来获得具体要使用的构造器:

当tag为bool类型时,会找到SafeConstruct中的内部类 ConstructYamlBool作为构造器,并调用它的construct方法实例化一个对象,来作为ScalarNode节点的value的值:

在construct方法中,取到的val就是之前的on,至于下面的这个BOOL_VALUES,也是提前初始化好的一个HashMap,里面提前存放了一些对应的映射关系,key是下面列出的这些关键字,value则是Boolean类型的true或false:

到这里,yml中的属性解析流程就基本完成了,我们也明白了为什么yml中的on会被转化为true的原理了。至于最后,Boolean类型的true或false是如何被转化为的字符串,就是@Value注解去实现的了。
思考
那么,下一个问题来了,既然yml文件解析中会做这样的特殊处理,那么如果换成properties配置文件怎么样呢?
sw.turnOn=on
sw.turnOff=off
执行一下程序,看一下结果:

可以看到,使用properties配置文件能够正常读取结果,看来是在解析的过程中没有做特殊处理,至于解析的过程,有兴趣的小伙伴可以自己去阅读一下源码。








