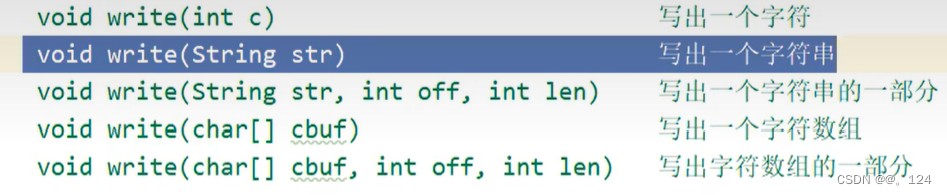
字节输出流
1.创建字节输出流对象 FileOutputStream 变量名 = new FileOutputStream(name:);
①参数是字符串表示的路径或者是file对象都是可以的
②如果文件不存在会创造一个新的文件,但是要保证父级路径是存在的。
③如果文件已经存在,则会清空文件
2.写数据 write(int b) 一次写一个字节 / (byte []b)一次写一个字节数组 / (byte []b,int f,int l) 一次写一个字节数组中的部分字节
①write方法的参数是整数,但是实际上写到本地文件夹里的是整数在ASCII上对应的字符
②如果要输出一串字符串,那么就可以使用getBytes,例如:byte []byes = str.getBytes();此时就是吧str字符串转成了字节数组
③要是想换行写入

④如果想要续写的话,则在加一个参数true,例如:FileOutputStream(路径,true);
3.释放资源
①每次使用完之后都要释放资源
字节输入流
FileInputStream();
①不存在就报错
read(); 返回值为int类型
①都到末尾,返回值为-1
②第一次调用read,读到的是第一个字节,第二次就是第二个字节,以此类推
③read读取文件的方式是通过指针,每调用一次read,就相当于移动一次指针;
循环读取:
while(int b = fis.read()!=-1){
System.out.println((char)b);
}close();
拷贝(小文件,一个一个字节拷贝的)
1.创建对象
2.边读边写
3.关闭(先开的后关)
(大文件,通过字节数组进行批量拷贝)
//若此时的txt里面的数据为 abcde
FileInputStream fis = new FileInputStream("文件名");
FileOutputStream fos = new FileOutputStream("文件名");
/*
byte []a = new byte[2];
int len = fis.read(a);//每次读取的时候是用覆盖
System.out,println(len);//输出2,如果第三次读取的话,len就是只输出1,第四次读取len就为-1
*/
byte []bytes = new byte[2];
while((int len = fis.read(bytes) != -1){
fos.write(bytes);
}
fos.close();
fis.close();
计算机的存储规则
GBK(ANSI)(遇到中文读取俩个字节)
汉字存储:
①汉字俩个字节存储
②高位字节二进制一定以1开头,转成十进制之后就是一个负数

Unicode(遇到中文读取三个字节)
乱码
1.读取数据时未读完整个汉字
2.编码和解码的方式不统一

字符流
FileReader
1.创建字符流输入对象
2.读取数据
read();
空参:
①默认也是一个字节一个字节进行读取,如果遇到中文就会一次读取多个字节
②在读取之后,底层还是将其转成十进制,最后把十进制作为返回
read(char[])
3.释放资源
FileWriter

------------------------------------------------------------------------------------------------------------------
字节缓冲流
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("文件名"));
BufferedOutPutStream bos = new BufferedOutputStream(new FileOutputStream("文件名"));
使用时会把自动将基本流关闭,只需关闭缓冲流
字符缓冲流
字符缓冲输入流
pubilic String readLine(); 读取一行数据,如果没有数据可读了,会返回null(不会将换行符读到)
public void newLine(); 跨平台的换行
字符缓冲输出流
public String writeLine();
public void newLine();
-------------------------------------------------------------------------------------------------
转换流
字符流和字节流之间的桥梁
FileReader()
FileReader fr = new FileReader("文件路径",Charset.forName("字符编码"));
FileWriter fw = nwe FileWriter("文件路径",Charset.forName("字符编码"));
以上都是在jdk11之后的版本
将本地的GBK文件转化为UTF-8
FileReader fr = new FileReader("",Charset.forName("GBK"));
FileWriter fw = nwe FileWriter("",Charset.forName("UFT-8"));
int b;
While(b = fr.read() != -1){
fw.write(b);
}
fw.close();
fr.close();利用字节流读取文件中的数据,每次读一整行,而且不能出现乱码
字节流读取中文的时候,是会出现乱码的,但是字符流可以解决
字节流里面是没有读一整行的方法的,只有字符缓冲流才能搞定
--------------------------------------------------------------------------------------------------------------------
序列化流
ObjectOutputStream();
ObjectInputStream();
把一个对象写到本地文件中
例如:
//创建对象
Student stu = new Student("姓名","年龄");
//创建序列化流的对象
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("文件路径"));
//写出数据
oos.writeObject(stu);
//释放资源
oos.close();

Serializable接口里面是没有抽象方法,标记型接口
一旦实现了这个接口,那么就表示当前的Student类可以被序列化
简单来说就是:有了这个接口就可以被序列化,没有就不行
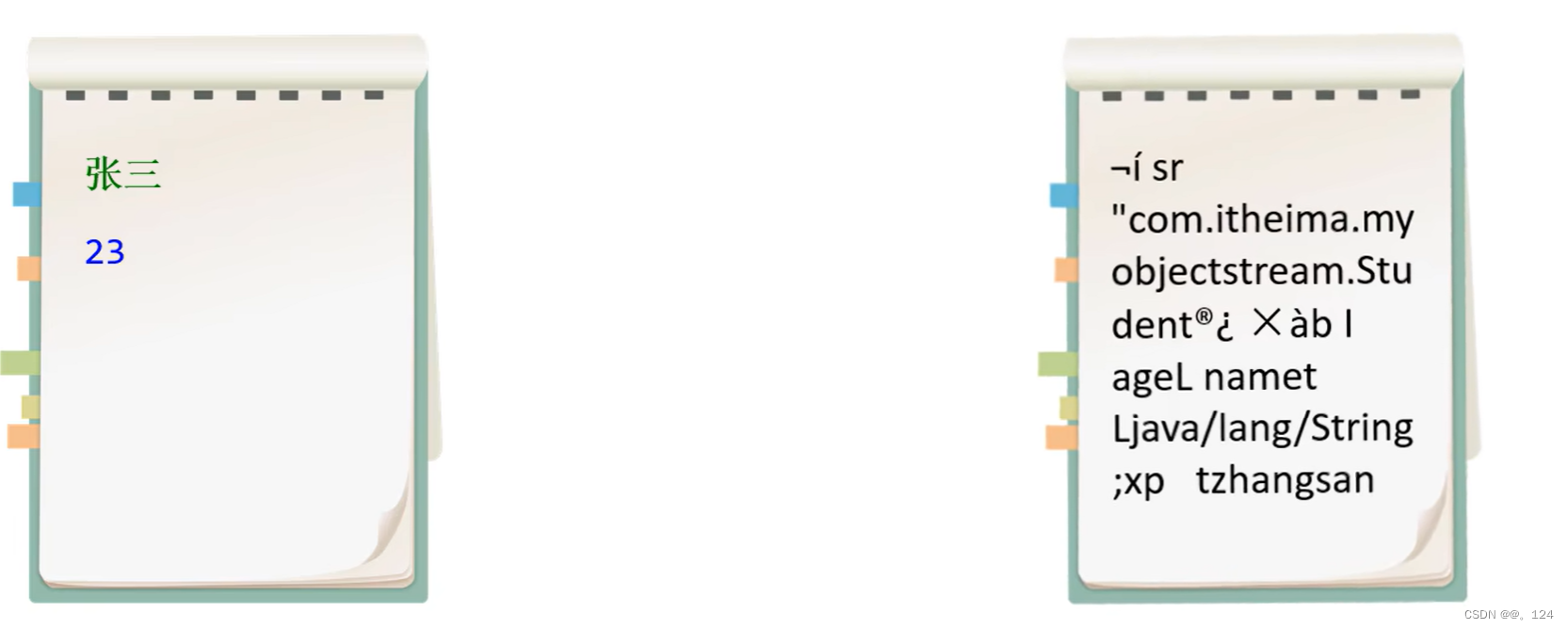
左边是正常存入数据,右边是序列化流存入







