目录
一、前言
华为云GaussDB数据库是一款高性能、高安全性的云原生数据库,在GaussDB中,自定义函数是一个不容忽视的重要功能。本文将简单介绍一下自定义函数在GaussDB中的使用场景、使用优缺点、示例及示例解析等,为读者提供指导与帮助。
二、自定义函数(Function)概述
在SQL中,自定义函数(Function)是一种用于执行特定任务并返回结果的可重复使用代码块。Function可以接受参数,并且可以返回指定的结果等。 在GaussDB中,Function是数据库管理和开发人员的重要“工具”。通过Function,可以封装复杂的逻辑,以简化数据处理流程并提高工作效率。
三、使用场景
数据库中Function的使用场景包含但不限于以下,例如:
- 数据处理:可以用于处理数据,如对字符串进行拆分、合并、替换、转换大小写等操作;对日期和时间进行格式化、计算时间差等操作;对数值进行计算、四舍五入、取整等操作;对布尔值进行逻辑操作等。
- 聚合操作:可以用于对数据进行聚合操作,如计算平均值、总和、最大值、最小值等。
- 条件判断:可以用于进行条件判断,如判断某个值是否满足特定条件,并返回相应结果。
- 实现代码的重用和抽象:可以用于实现代码的重用,从而减少程序员编写重复代码的工作量,也可以用于实现代码的抽象。
四、优缺点
1、数据库中Function的使用优点
- 执行速度快:只在创建时进行编译,以后每次执行都不需要再重新编译,而一般SQL语句每执行一次就要编译一次,因此使用函数可以提高数据库执行速度。
- 操作简便:可以封装复杂的数据库操作,只需要一个函数调用就可以完成相应的操作,从而简化了数据库操作。
- 可重用性高:可以重复使用,减少了数据库开发人员的工作量。
- 提高系统安全性:可以设定只有特定用户才具有对指定函数的使用权,增强了数据库的安全性。
2、数据库中Function的使用缺点
- 调试困难:与SQL语句相比,函数在调试过程中更加困难。
- 可移植性差:在不同的数据库系统中,函数的使用和语法可能有所不同,因此函数的可移植性较差。
五、GaussDB中的Function示例与解析
常见Function操作(创建、调用、删除等)
1、示例一:定义函数为SQL查询
--定义函数为SQL查询
CREATE FUNCTION func_add_sql(integer, integer) RETURNS integer
AS 'select $1 + $2;'
LANGUAGE SQL
IMMUTABLE
RETURNS NULL ON NULL INPUT;
--调用
SELECT func_add_sql(1,9);
--DROP
DROP FUNCTION func_add_sql;调用结果:
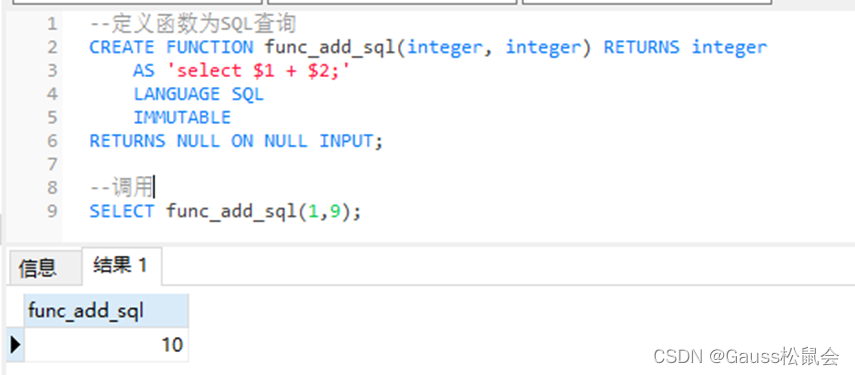
解析说明:
这段代码是在创建一个名为'func_add_sql'的SQL函数,这个函数接受两个整数作为输入参数,并返回它们的和。
- “CREATE FUNCTION”:这是一个SQL命令,用于创建新的函数。
- “func_add_sql”:这是创建的函数的名称。
- “RETURNS integer”:这指定了函数的返回类型为整数。
- “IMMUTABLE”:这是一个特性,表明这个函数总是返回相同的结果,当给定相同的输入时。也就是说,这个函数不依赖于任何外部状态或数据,它的结果不会变化。
- “RETURNS NULL ON NULL INPUT”:表明如果任何一个输入参数为NULL,函数将返回NULL。
- “LANGUAGE SQL”:这指定了函数用SQL语言编写。
- “'select $1 + $2;'”:这是函数的主体。$1和$2是参数引用,分别代表输入的两个参数。
2、示例二:返回一个包含多个输出参数的记录
--返回一个包含多个输出参数的记录。
CREATE FUNCTION func_dup_sql(in int, out f1 int, out f2 text)
AS $$ SELECT $1, CAST($1 AS text) || ' is text' $$
LANGUAGE SQL;
--调用
SELECT * FROM func_dup_sql(10);
--DROP
DROP FUNCTION func_dup_sql;调用结果:
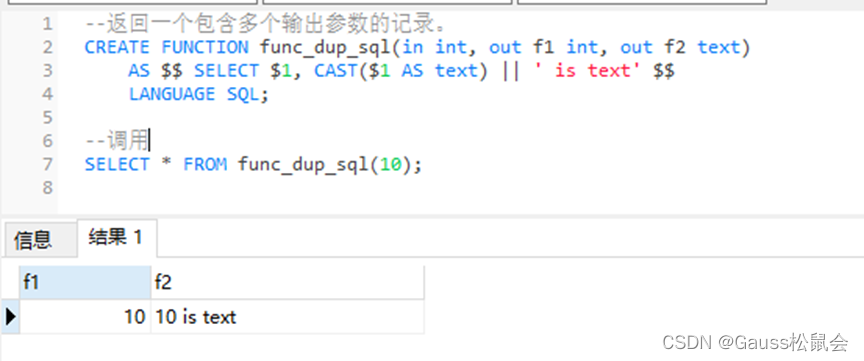
解析说明:
这个函数名为func_dup_sql,它接受一个输入参数(标记为in),并产生两个输出(标记为f1和f2)。
函数体内部使用 $$ 标记代码块,里面是一个SELECT语句,它返回输入参数$1的两个不同形式的值。对于f1,它直接返回输入的整数值。对于f2,它将输入的整数值转换为一个文本字符串,并在其后添加字符串' is text'。这个转换是使用CAST函数完成的,它将$1从整数值转换为文本字符串。
这个函数的语言是SQL,这表示它是在SQL的上下文中执行的。总的来说,这个函数接受一个整数作为输入,然后返回两个值:一个整数和一个由整数生成并添加了文本后缀的字符串。
3、示例三:返回RECORD类型结果集
--返回RECORD类型
CREATE OR REPLACE FUNCTION compute(i int, out result_1 bigint, out result_2 bigint)
returns SETOF RECORD
as $$
begin
result_1 = i + 1;
result_2 = i * 10;
return next;
end;
$$ language plpgsql;
--调用
SELECT compute(10);
--DROP
DROP FUNCTION compute;调用结果:

解析说明:
这是一个GaussDB数据库兼容PL/pgSQL自定义函数的定义。此函数名为compute,它接受一个整数参数i,并返回一个记录集,其中包含两个字段:result_1和result_2,它们都是大整数类型(bigint)。
在函数的主体中,定义了以下操作:
- “result_1 = i + 1;”:将参数i加1后的结果赋值给result_1。
- “result_2 = i * 10;”:将参数i乘以10的结果赋值给result_2。
- “return next;”:返回结果集中的下一行。由于这个函数只返回了一行,所以这行将在第一次调用时返回。
- “$$ language plpgsql;”: 声明这个函数的编程语言是兼容PL/pgSQL。
当调用这个函数时,你可以传入一个整数参数,它将返回一个结果集,其中包含一个记录,其result_1字段的值为输入的整数加1,result_2字段的值为输入的整数乘以10。
六、小结
总的来说,在GaussDB中,函数是一种强大且灵活的工具,它能帮助数据库管理和开发人员更有效地处理和操作数据,提高工作效率,并在数据查询、数据转换、数据过滤等场景中发挥出更大的作用。
当然了,关于GaussDB数据库,除了上面的例子还有很多实践,例如:创建package属性的重载函数、通过语法“ALTER FUNCTION function_name …”修改函数、通过语法“DROP FUNCTION [ IF EXISTS ] function_name …”删除函数等,欢迎大家参考官网资料进行学习、测试!
——结束










