实验篇——根据群体经纬度提取环境数据(先导)
文章目录
前言
首先得到了一个样本分布点的群体经纬度文件,之后欲提取环境数据。本章将简单介绍一下。
Worldclim官网上提供的数据集是基于历史观测数据和模型推算得出的全球平均值。这些数据集并没有特定的年份标识,而是提供了每个月的平均数据。
因此,这些数据集可以用于研究不同年份或时间段的气候变化趋势,而不是针对特定的年份。你可以根据需要选择适合你研究的时间范围,从中提取相应的月份数据进行分析。
一、获取数据文件
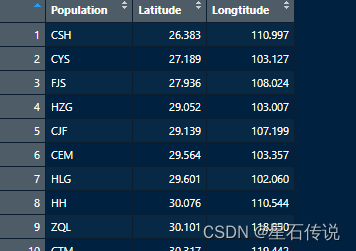
1.1.经纬度文件
1.2. 环境数据的tif文件
从WorldClim官网下载:
https://worldclim.org/data/index.html
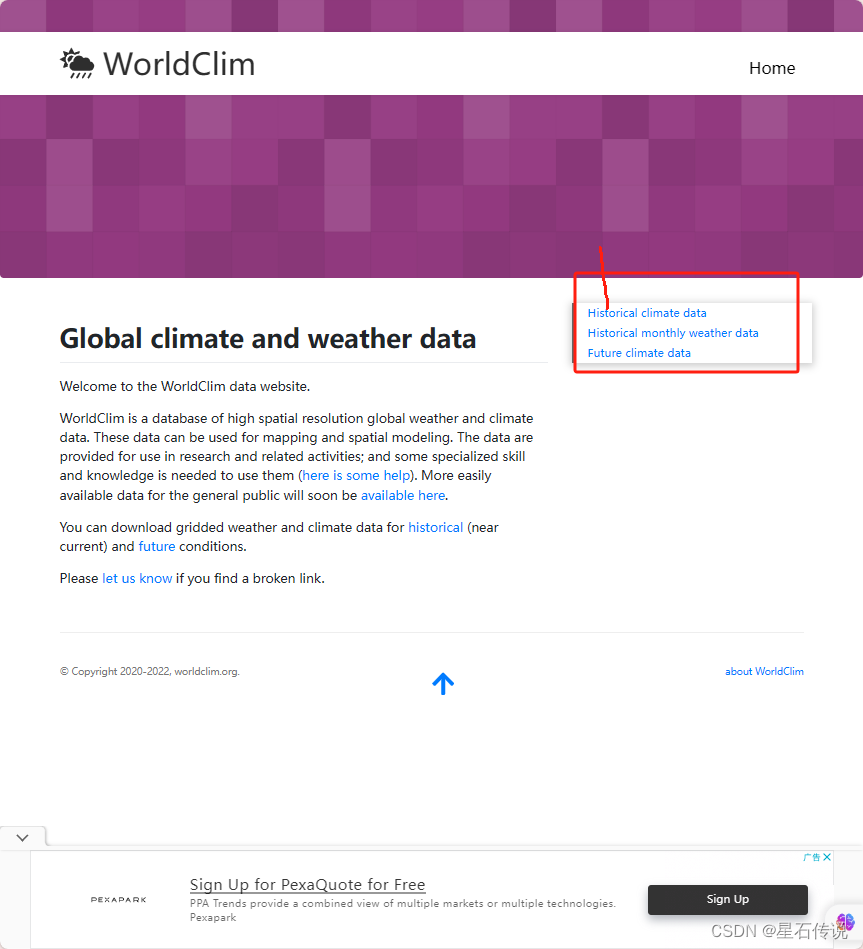
点进 “Historical climate data”
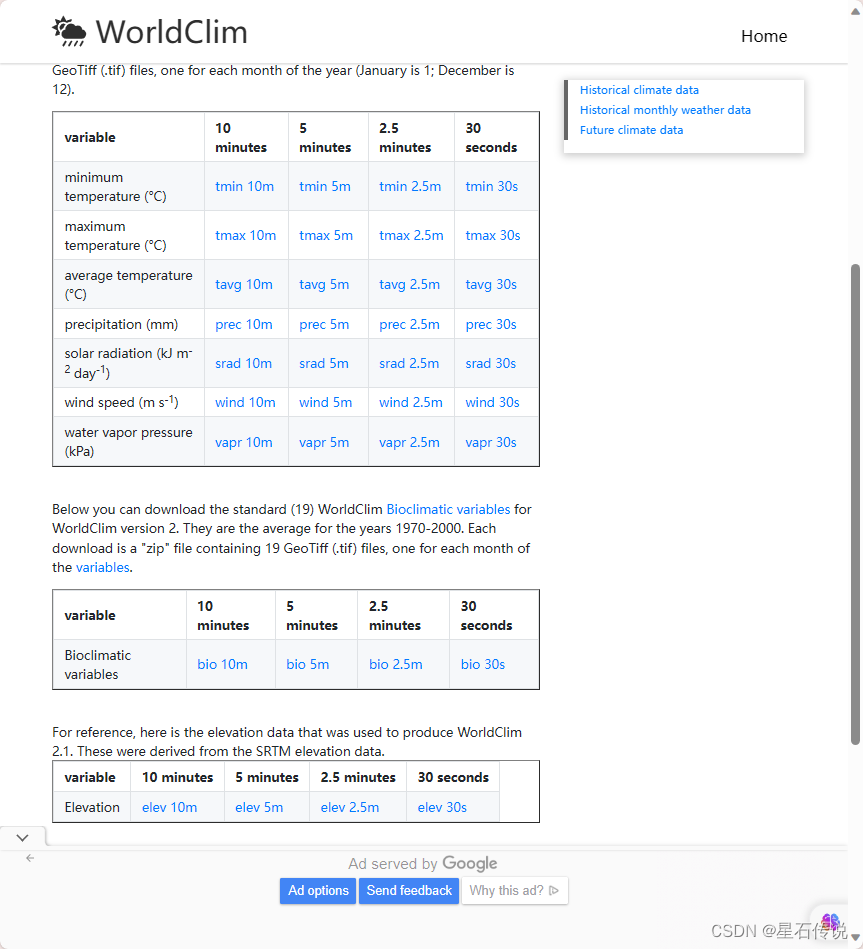
然后根据自己的需求下载数据,并将下载后的文件按不同类别分到不同文件夹,以便后续处理:
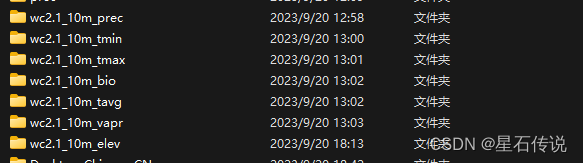
点进去其中一个文件夹,放置的是对应的tif文件:
二、R语言代码实现
这段代码的功能是下载世界气候数据中与温度和降水有关的19个因子、海拔、降水、平均温度、最低温度、最高温度、srad和wind speed数据
library(rgdal)
library(sp)
library(raster)
longla<- read.table("D:/Cja_location.txt",header = T) #读取经纬度文件
#设置你的经、纬度 (!!!,注意经度在前,维度在后!!!)
coordinates(longla)=c("Longtitude","Latitude")
result <- data.frame(row.names = c(1:38)) #先构建一个空数据框(根据样本量设置行数)
#1到12的形式
tiqu_huanjing_shuju <- function(n, lujin, bio) {
for (i in n) {
file <- paste0(lujin, i, ".tif")
print(file) #打印文件路径看一下
worldclim1 <- raster(file) #加载栅格数据
data1 <- extract(x = worldclim1, y = longla) #按照坐标提取值
data_all <- data.frame(longla, data1) #合并
write.csv(data_all, paste0(bio, i, ".csv")) #导出数据
bio_data <- read.csv(paste0(bio, i, ".csv"), as.is = TRUE) #导入每个点的环境数据
bio_col <- bio_data$data1 #提取指定列data1
result <- cbind(result, bio_col) #合并数据
colnames(result)[i] <- paste0(bio, i)
}
write.csv(result, paste0(bio, "zong.csv"), row.names = FALSE) #转化为csv格式导出
}
tiqu_huanjing_shuju(1:19, "D:/wc2.1_10m_bio/wc2.1_10m_bio_", "bio")
我定义了一个提取函数,结果发现bio气候数据的文件后的编号是1到12这样的形式,而其它的数据则都是01到12这样的形式。(所以我就改了一下,干脆分开提取)

#从01到12的形式
tiqu_huanjing_shuju <- function(n, lujin, bio) {
for (i in n) {
file <- sprintf("%s%02d.tif", lujin, i)
print(file)
worldclim1 <- raster(file)
data1 <- extract(x = worldclim1, y = longla)
data_all <- data.frame(longla, data1)
write.csv(data_all, paste0(bio, i, ".csv"))
bio_data <- read.csv(paste0(bio, i, ".csv"), as.is = TRUE)
bio_col <- bio_data$data1
result <- cbind(result, bio_col)
colnames(result)[i] <- paste0(bio, i)
}
write.csv(result, paste0(bio, "zong.csv"), row.names = FALSE)
}
tiqu_huanjing_shuju(1:12, "D:/wc2.1_10m_prec/wc2.1_10m_prec_", "prec")
那个海拔数据:elev文件只有一个tif文件,那就不要循环了,直接提取就行
worldclim1<-raster("D:/wc2.1_10m_elev/wc2.1_10m_elev.tif") #加载栅格数据
data1<-extract(x= worldclim1,y=longla) #按照坐标提取值
data_all<-data.frame(longla,data1) #合并
write.csv(data_all,"elevzong.csv")#导出气候数据
bio_data <- read.csv("elevzong.csv", as.is = TRUE)
bio_col <- bio_data$data1
result <- cbind(result, bio_col)
colnames(result)<- "elev"
write.csv(result,"elevzong.csv" , row.names = FALSE)
三、环境文件介绍
3.1. bio
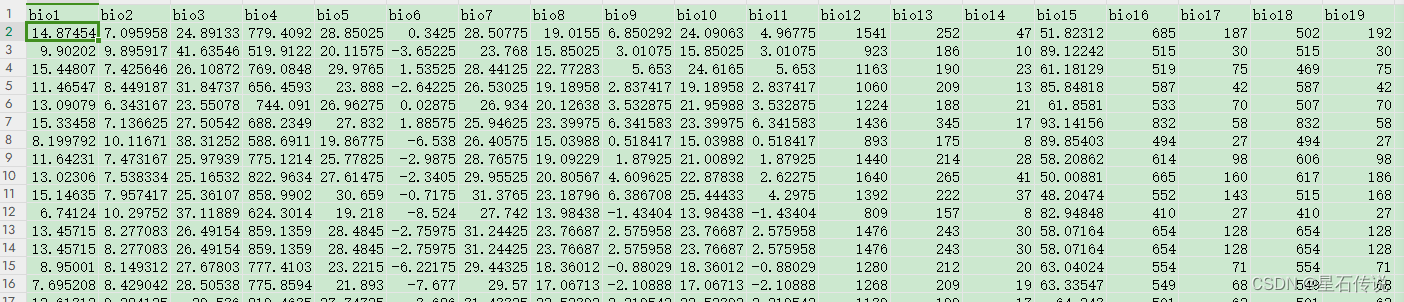
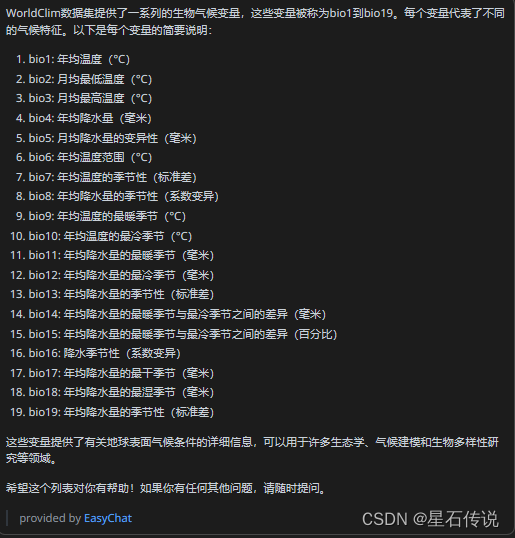
数据介绍:
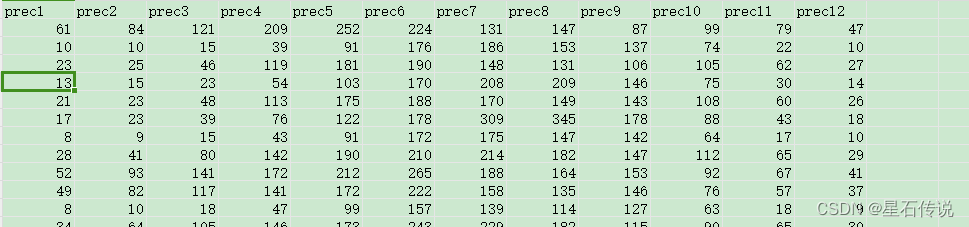
3.2. prec
每个月全球各个地点的降水量
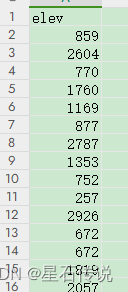
3.3. elev
Worldclim官网上下载的elev数据代表地表高程数据。这些数据提供了全球范围内的地表高程信息,可以用于各种地理和环境研究。(就是海拔高度数据)
3.4. tmin
tmin数据是Worldclim官网上提供的全球最低温度数据集。该数据集提供了每个月全球各个地点的最低温度值。

3.5. tmax
提供了每个月全球各个地点的最高温度值。

3.6. vapr1
Worldclim官网上的vapr1数据代表着全球范围内的蒸汽压数据。vapr1数据集提供了关于大气中水蒸汽含量的信息。

3.7. tavg
tavg数据是Worldclim官网上提供的全球平均温度数据集。该数据集提供了每个月全球各个地点的平均温度值。

3.8. srad
srad数据是Worldclim官网上提供的全球太阳辐射数据集。该数据集提供了每个月全球各个地点的太阳辐射值。

3.9. wind
wind数据是Worldclim官网上提供的全球风速数据集。该数据集提供了每个月全球各个地点的风速值。

四、后续
之前的步骤算是完成了根据群体经纬度提取环境数据的第一步了,我们成功的提取到了许多有关我们的样本分布点的许多环境数据文件,显然这样的数据是极大的,后续对这些环境数据文件的处理也是十分重要的,也是复杂的(这么多不同类别的环境数据,光是它们的单位的处理就比较麻烦,并且降维处理也是必须的…)。
总之,后续的分析才是真正的难点,也是我们获取这些数据的意义所在。
总结
这一章简单介绍了如何根据样本的群体经纬度来提取环境数据,得到了许多不同类别的环境数据。
道沖,而用之或不盈。淵兮,似万物之宗;湛兮,似或存。吾不
–2023-9-20 实验篇










