
文章目录
- 线程的概念
- 创建线程
- 线程退出
一、线程的概念
线程在进程内部执行,是OS调度的基本单位。
- 在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列” 。
- 一切进程至少都有一个执行线程。
- 线程在进程内部运行,本质是在进程地址空间内运行。
- 在Linux系统中,在CPU眼中,看到的PCB都要比传统的进程更加轻量化 。
- 透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形成了线程执行流。
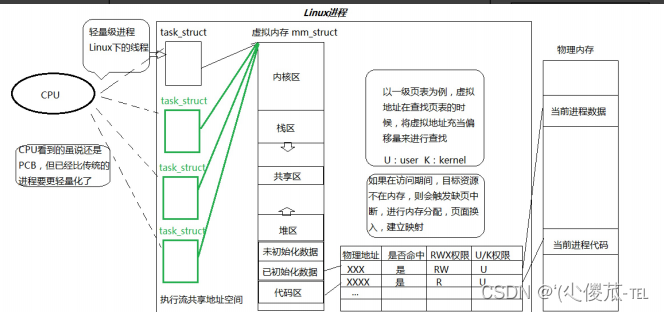
在堆上面存在vm_area_struct这种数据结构
/*
* This struct defines a memory VMM memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address
within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
/*
* Largest free memory gap in bytes to the left of this VMA.
* Either between this VMA and vma->vm_prev, or between one of the
* VMAs below us in the VMA rbtree and its ->vm_prev. This helps
* get_unmapped_area find a free area of the right size.
*/
unsigned long rb_subtree_gap;
/* Second cache line starts here. */
struct mm_struct *vm_mm; /* The address space we belong to. */
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* Flags, see mm.h. */
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap interval tree.
*/
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_chain; /* Serialized by mmap_sem &
* page_table_lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
};
如果堆区中申请了比较多的空间,然后我们的vm_area_struct就是用来记录我们每一小块的地址空间的起始和结束。然后这些小的内存快就通过双向链表的形式串联起来。
OS可以让相应的进程进行细粒度的划分!
用户级页表+MMU(是集成在CPU当中的)
如何从虚拟地址映射到物理地址?
由于.exe就是一个文件,我们的可执行程序本来就是按照地址空间方式进行编译的,可执行程序,其实按照区域也已经被划分了以4KB为单位的空间,通过先描述再组织的方式来进行管理这里每一个4KB的空间,
利用struct page结构体来进行描述
struct page
{
int flag;
}内核想要管理这么多物理内存,我们就需要创建一个数组struct page mem[100w+],然后操作系统想要管理对应的物理内存的时候,就可以通过这一个数组进行管理。所以操作系统对于物理内存的管理,就变成了对于对应的数据结构的管理。
磁盘中的可执行文件是按照4KB划分的,我们的物理内存也是按照4KB划分的,其中我们将磁盘当中以4KB为单位的,我们的代码的数据的内容,称之为页帧,我们物理内存这里的4KB大小称之为页框。
IO的基本单位是4KB,IO就是将页帧装进页框里
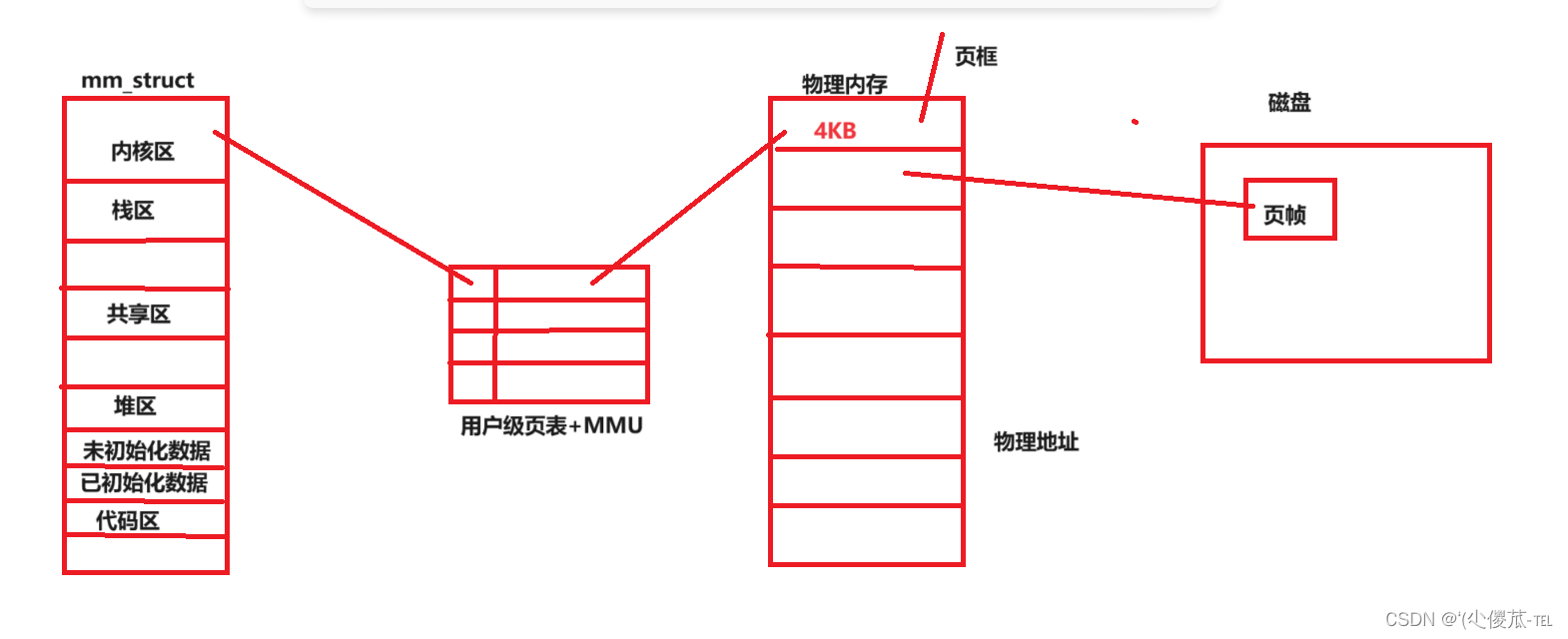
缺页中断:如果我们的操作系统在寻值的时候,发现对应的数据不在我们的内存中,我们就需要去磁盘中读取对应的数据到我们的内存中,然后通过页表映射,获取到我们的数据。
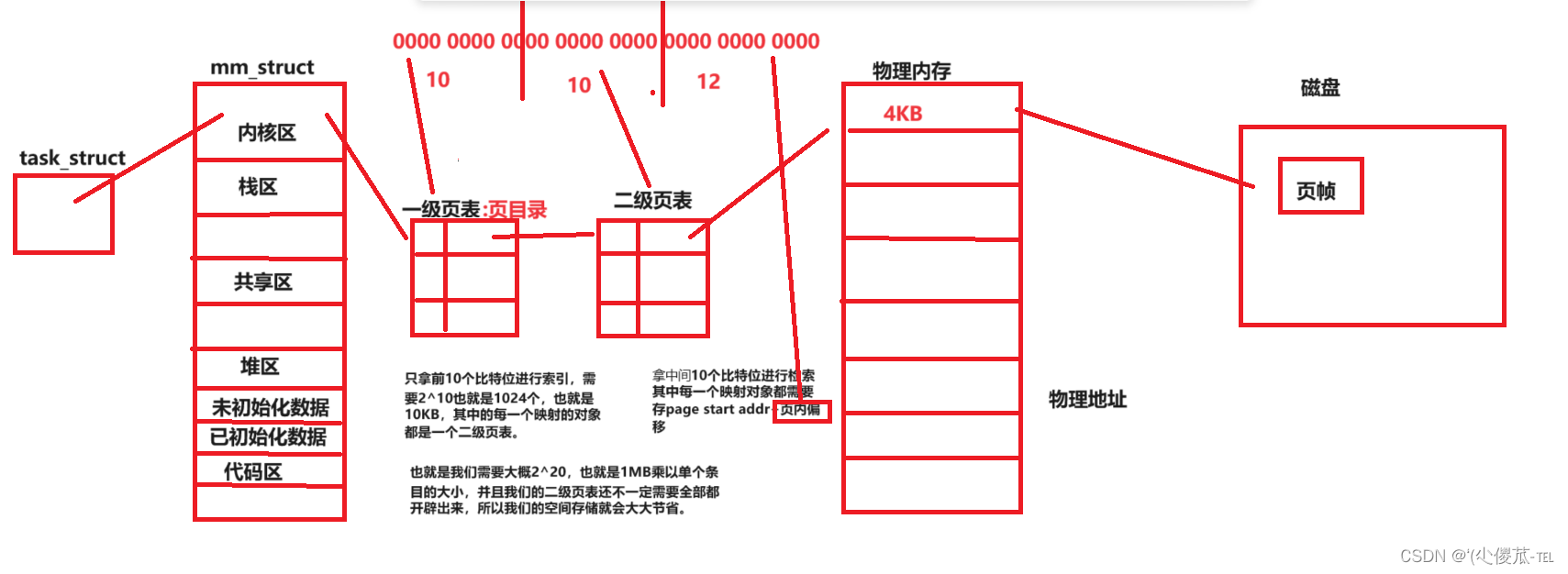
我们的虚拟地址有个(4GB,页表是保存在物理内存当中的),也就是说如果想要保存我们的一整张页表的话,需要的大小为页表的条目的大小×4GB,这样空间占用就会非常大。
但是我们可以按照下图建立一级页表和二级页表,来简化我们的索引。
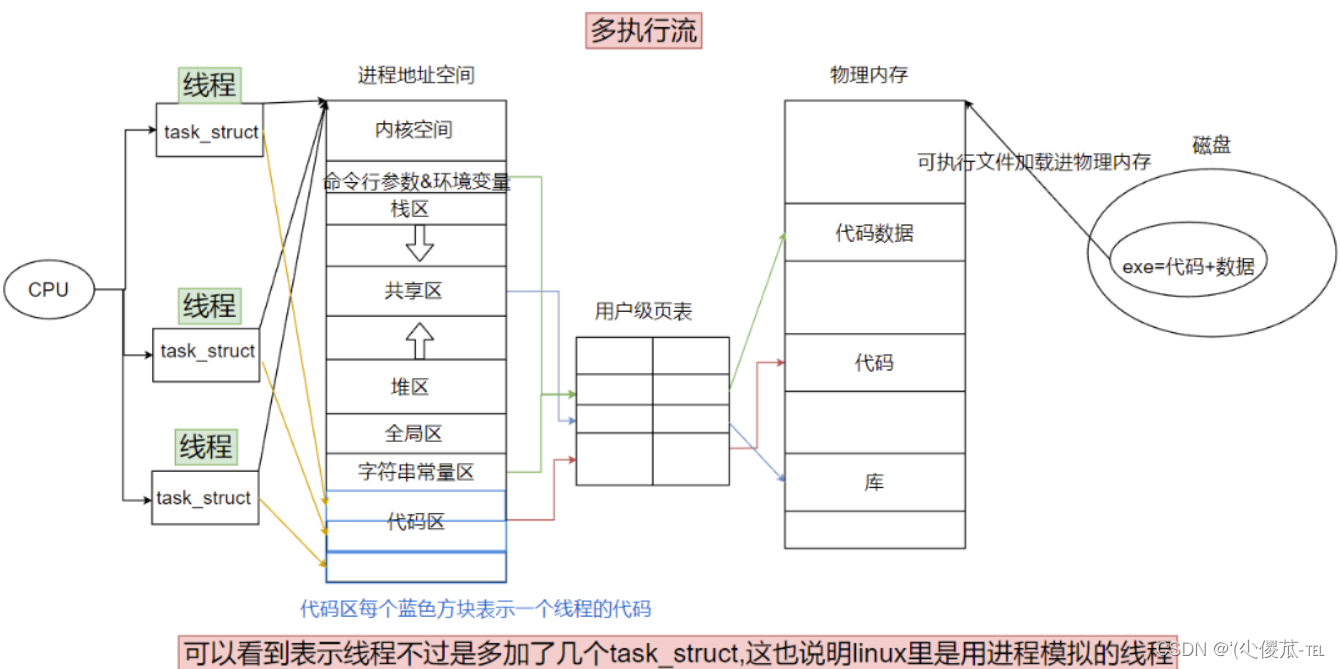
如何理解线程:
通过我们创建了多个task_strcu指向同一个mm_struct,通过一定的技术手段,将当前进程的“资源”,以一定的方式划分给不同的task_struct。也就是说我们再创建task_struct的时候,不再去开辟新的资源了。我们就将这里的每一个task_struct就称为线程。
什么是线程在进程内部执行?
线程在进程的地址空间内进行运行。
为什么线程是OS调度的基本单位?
因为CPU并不关心执行流是线程还是进程,只关心PCB。这只是Linux下的维护方案,没有为线程设计专门的数据结构。但只要比进程更轻量,粒度更轻,就是线程。而在Windows下有为线程设计专门的数据结构。
什么是进程(资源角度)?
进程就是我们对应的内核数据结构,再加上该进程所对应的代码和数据。一个进程可能会有多个PCB。在内核的视角中,进程是承担系统分配资源的基本实体。
所以我们创建线程的时候,只有第一个需要申请资源,也就是我们上面图中红框的那一个task_struct,也就是一个进程,后面所创建的线程不是想操作系统索要资源,而是向我们的进程共享了资源。
之前写的代码由于内部只有一个执行流的进程。而我们现在就可以创建内部具有多个执行流的进程。而我们的task_struct仅仅是我们的进程内部的一个执行流。
- 在CPU的视角,CPU其实不怎么关心当前是进程还是线程这样的概念,只认识stask_struct。我们的CPU的调度其实还是task_struct.
- 在Linux下,PCB<=其他操作系统的PCB的。Linux下的进程:统一称之为轻量级进程。当CPU拿到一个PCB的时候,可以是单执行流的进程的PCB,也可能是多执行流的其中一个线程的PCB,所以比那些别的操作系统单独给线程和进程设计的数据结构更加轻量化。所以Linux没有真正意义上的线程结构,Linux上是用进程PCB模拟线程的。
- 所以Linux并不能直接给我们提供线程相关的接口,只能提供轻量级进程的接口(在用户层实现了一套用户层多线程方案,以库的方式提供给其他用户进行使用,pthread线程库–原生线程库)。
线程如何看待进程内部的资源呢?
原则上线程能够看到进程的所有资源,在进程的上下文中进行操作。
进程 vs 线程
调度层面:上下文(调度一个线程的成本比调度进程的成本更低)
线程的优点
- 创建一个新线程的代价要比创建一个新进程小得多
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
- 线程占用的资源要比进程少很多
- 能充分利用多处理器的可并行数量
- 在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
- 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
- I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
线程的缺点
- 性能损失
- 一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
- 健壮性降低
- 编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
- 缺乏访问控制
- 进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
- 编程难度提高
- 编写与调试一个多线程程序比单线程程序困难得多
线程异常
- 单个线程如果出现除零,野指针问题导致线程崩溃,进程也会随着崩溃。
- 线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出 。
- 合理的使用多线程,能提高CPU密集型程序的执行效率
- 合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们一边写代码一边下载开发工具,就是多线程运行的一种表现)
线程是不是越多越好?
线程越多,线程之间的切换也回更加频繁,这会导致系统的开销变大,导致我们的效率反而下降。一般我们创建线程的数量等于CPU的核心数。
二、创建线程
1.pthread_create
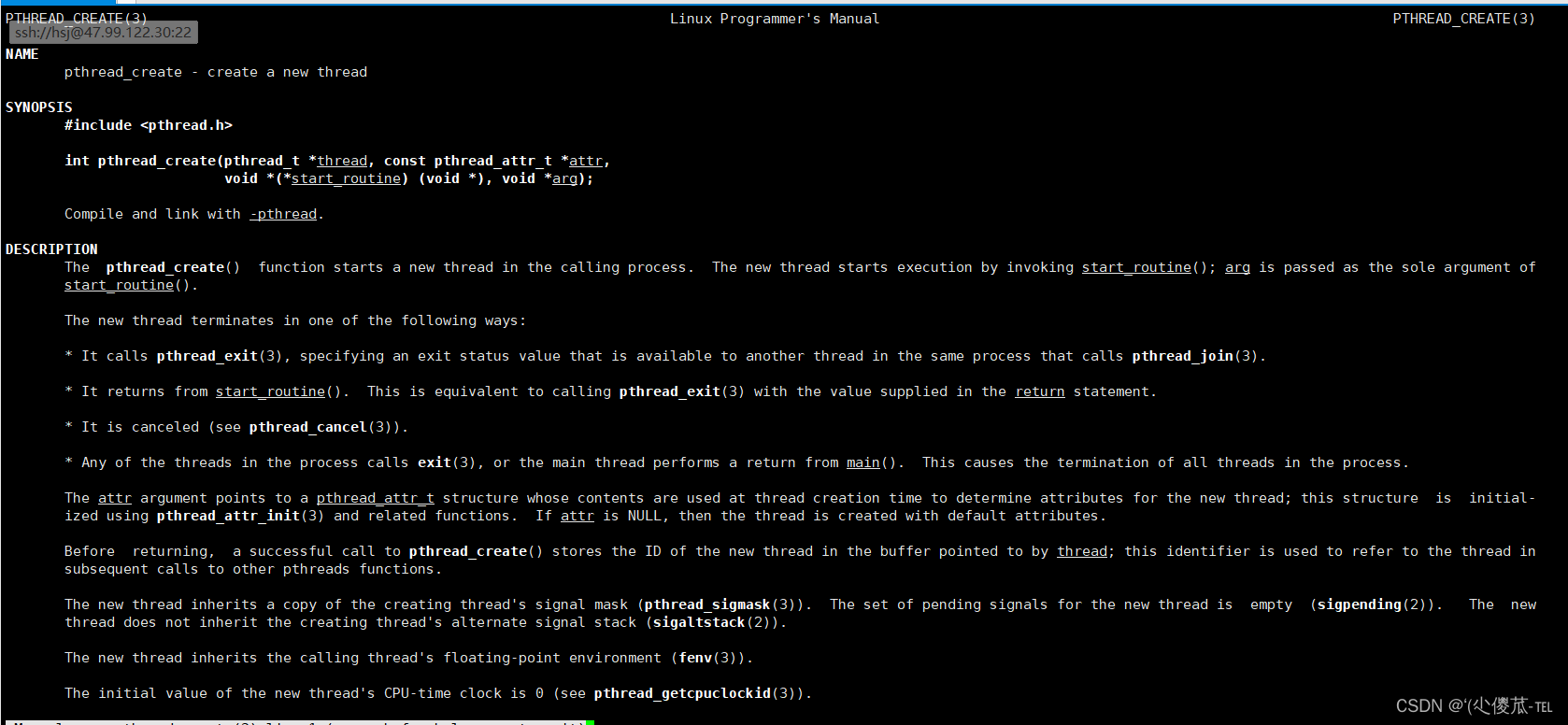
- 功能:创建一个新的线程
- 原型
- int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void * (*start_routine)(void*), void *arg);
- 参数
- thread:返回线程ID
- attr:设置线程的属性,attr为NULL表示使用默认属性
- start_routine:是个函数地址,线程启动后要执行的函数
- arg:传给线程启动函数的参数
- 返回值:成功返回0;失败返回错误码
利用ldd命令来查看当前程序是否已经链接上我们的原生线程库。
Makefile
mythread:mythread.cc
g++ -o mythread mythread.cc -std=c++11 -lpthread
.PHONY:clean
clean:
rm -f mythread这里需要注意在编译时需要加上-lpthread选项
thread.cc
#include <iostream>
#include <pthread.h>
#include <string>
#include <cstdio>
#include <unistd.h>
void *threadRun(void *args)
{
const std::string name=(char*)args;
while(true)
{
//如果线程属于进程的话,我们这里获取的pid应该和我们的线程是同一个pid
std::cout<<name<<", pid: "<<getpid()<<std::endl;
std::cout<<std::endl;
sleep(1);
}
}
int main()
{
pthread_t tid[5];
char name[64];
for(int i=0;i<5;i++){
//格式化我们线程的名字
snprintf(name,sizeof(name),"%s-%d","thread",i);
//创建线程
pthread_create(tid+i,nullptr,threadRun,(void*)name);
sleep(1);
}
while(true){
std::cout<<"main thread,pid: "<<getpid()<<std::endl;
sleep(3);
}
return 0;
}
上图我们只能发现只能看到同一个进程,如何查看这个进程里面的线程呢?
利用 ps -aL | head |head -1 && ps -aL| grep mythread来监控脚本
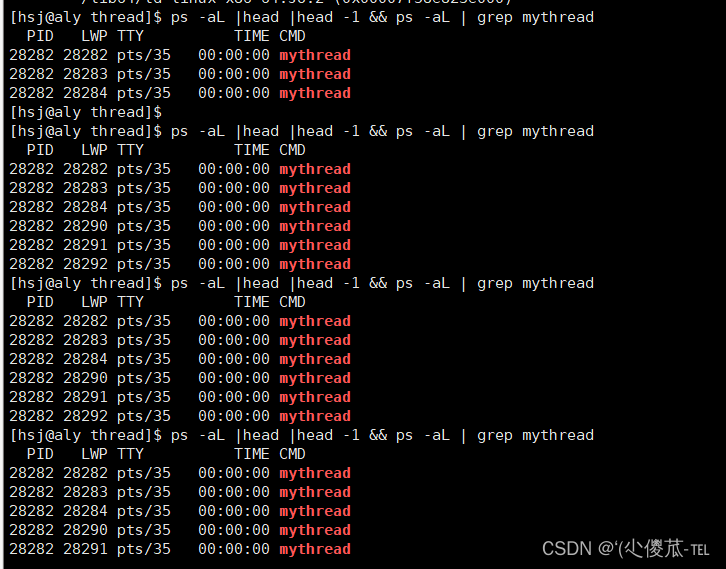
这里我们发现在Linux内部看到的一定是LWP,不是PID。如果只是单线程的话,那么此时进程的PID和LWP是相同的。如果我么将此时的进程全部终止的话,我们的线程都会终止。因为我们的线程的资源全部都是来自于我们的进程,没有了代码和数据,当然会退出。
线程的共享资源
- 文件描述符表
- 每种信号的处理方式(SIG_ IGN、SIG_ DFL或者自定义的信号处理函数)
- 当前工作目录
- 用户id和组id
- 堆区可以被共享
- 共享区也是被所有线程共享的
- 栈区也是可以共享的,但我们一般不这么做。
线程的私有资源
- 线程ID
- 一组寄存器(线程的上下文)
- 栈
- errno
- 信号屏蔽字
- 调度优先级
进程和线程切换,我们为什么说线程的切换成本更低?
如果我们调度的一个进程内的若干个线程,我们的地址空间不需要切换,页表也不需要切换。如果是进程切换的话,地址空间,页表等等都需要切换。并且我们的CPU内是有硬件级别的缓存的(cache)(L1-L3),我们只要将相关的数据加载到我们CPU内部的缓存,对内存的代码和数据,根据局部性原理(一条指令如果被使用了,它附近的代码也有很大的可能被使用),预读取到我们的CPU的缓存中,这样我们的CPU就不需要访问内存,直接到缓存中访问就可以了。但是如果进程切换,那么我们的cache立即失效,新进程过来的时侯,只能重新缓存。所以我们的线程切换比我们的进程切换更加轻量化。
#include <iostream>
#include <pthread.h>
#include <string>
#include <cstdio>
#include <unistd.h>
void *threadRoutine(void *args)
{
while(true)
{
std::cout<<"新线程: "<<(char*)args<<"running..."<<std::endl;
int a=100;
a/=0;
sleep(1);
}
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,threadRoutine,(void*)"thread 1");
while(true)
{
std::cout<<"main线程: "<<"running..."<<std::endl;
sleep(1);
}
return 0;
}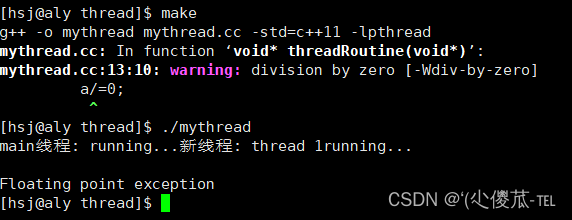
上图发现,如果线程异常退出,那么该进程也会退出。
这里我们发现线程在创建并执行的时候,线程也是需要进行等待的。如果主线程不等待,就会引起类似于进程的僵尸问题导致内存泄漏。
2.pthread_join
- 功能:等待线程结束
- 原型
- int pthread_join(pthread_t thread, void **value_ptr);
- 参数
- thread:线程ID
- value_ptr:它指向一个指针,后者指向线程的返回值
- 返回值:成功返回0;失败返回错误码
测试代码:
#include<iostream>
#include<pthread.h>
#include<string>
#include<cstdio>
#include<unistd.h>
using namespace std;
void *threadRoutine(void *args)
{
int i=0;
while(true)
{
cout<<"新线程: "<<(char*)args<<"running...."<<endl;
sleep(1);
if(i++==10)
{
break;
}
}
}
int main()
{
pthread_t tid;
pthread_create(&tid ,nullptr,threadRoutine,(void*)"thread 1");
pthread_join(tid,nullptr);//默认会阻塞等待新线程的退出。
cout<<"main thread wait done"<<endl;
while(true)
{
cout<<"main线程: "<<"running...."<<endl;
sleep(1);
}
return 0;
}
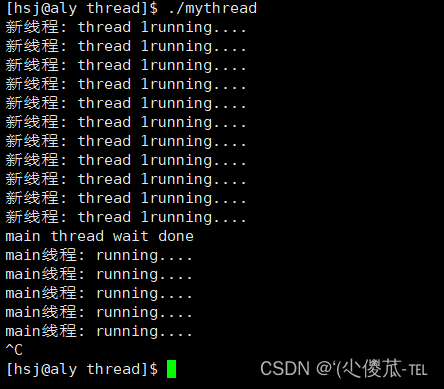
新线程的返回值返回给谁呢?
一般是给主线程,main_thread,main如何获取到呢?
#include <iostream>
#include <pthread.h>
#include <string>
#include <cstdio>
#include <unistd.h>
void *threadRoutine(void *args)
{
int i=0;
while(true)
{
std::cout<<"新进程: "<<(char*)args<<"running..."<<std::endl;
sleep(1);
if(i++==10)
break;
}
std::cout<<"new thread quit..."<<std::endl;
return (void*)10;//返回给pthread_join
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,threadRoutine,(void*)"thread 1");
void *ret=nullptr;
pthread_join(tid,&ret);
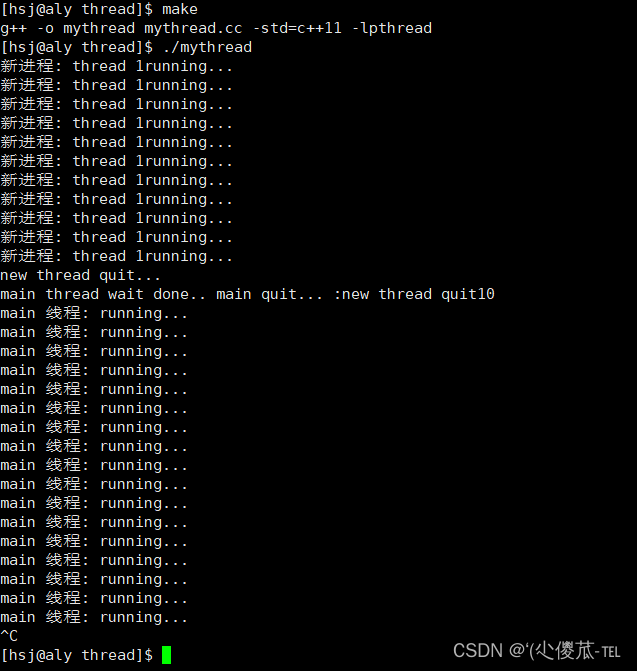
std::cout<<"main thread wait done.. main quit... :new thread quit"<<(long long)ret<<std::endl;//64位下是long long ,32位下是int
while(true)
{
std::cout<<"main 线程: "<<"running..."<<std::endl;
sleep(1);
}
return 0;
}
多线程可以在新线程和主线程之间传递信息
这里我们可以传递一整个数组或者别的数据
#include <iostream>
#include <pthread.h>
#include <string>
#include <cstdio>
#include <unistd.h>
void *threadRoutine(void *args)
{
int i=0;
int *data=new int[10];
while(true)
{
data[i]=i;
std::cout<<"新进程: "<<(char*)args<<"running..."<<std::endl;
sleep(1);
if(i++==10)
break;
}
std::cout<<"new thread quit..."<<std::endl;
return (void*)data;//返回给pthread_join
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,threadRoutine,(void*)"thread 1");
int* ret=nullptr;
pthread_join(tid,(void**)&ret);
std::cout<<"main thread wait done.. main quit... :new thread quit"<<std::endl;//64位下是long long ,32位下是int
for(int i=0;i<10;i++){
std::cout<<ret[i]<<std::endl;
}
return 0;
}
我们的主进程为什么没有获取新线程的退出码之类的接口?
一个线程崩了,整一个进程就崩掉了,获取退出码没有意义。
- 线程谁先运行与调度器有关
- 线程一旦异常,都可能导致整个进程整体退出
- 现成的输入和返回值问题
- 线程异常退出的理解








