一、整体思路
- 非常简单的一个v1版本
- 利用langchain和pdfminer切分pdf文档为k块,设置overlap等参数
- 先利用prompt1对每个chunk文本块进行摘要生成,然后利用prompt2对多个摘要进行连贯组合/增删
- 模型可以使用chatglm2-6b或其他大模型
- 评测标准:信息是否涵盖pdf主要主题、分点和pdf一二级标题比大体是否一致、摘要是否连贯、通顺
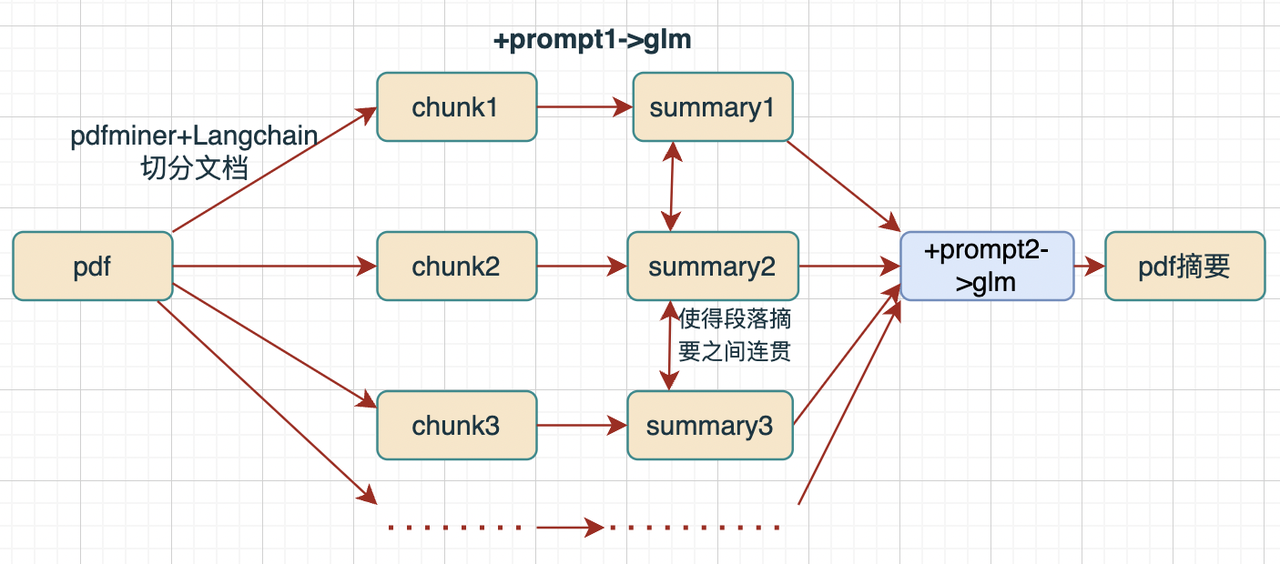
Prompt1:分段总结
prompt1 = '''你是一个摘要生成器。请根据下文进行分段总结,请注意:
1.输入数据为从pdf读入的文本,一句话可能存在跨越多行;
2.要求每段内容不丢失主要信息, 每段的字数在50字左右;
3.每段生成的摘要开头一定不要含有'第几段'的前缀文字;
4.对下文进行分段总结:'''
Prompt2:内容整合
prompt2 = '''你是一个文章内容整合器,请注意:
1.输入数据中含有多个已经总结好的段落;
2.有的段落开头有这是第几段或者摘要的字样;
2.请将每段信息进行优化,使得每段之间显得更加连贯,且保留每段的大部分信息;
4.输入的的文章如下:'''
二、代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Author : andy
@Date : 2023/8/23 10:09
@Contact: 864934027@qq.com
@File : chunk_summary.py
"""
import json
from langchain.text_splitter import CharacterTextSplitter
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams, LTTextBoxHorizontal
from pdfminer.pdfpage import PDFPage
import os
import pandas as pd
def split_document_by_page(pdf_path):
resource_manager = PDFResourceManager()
codec = 'utf-8'
laparams = LAParams()
device = PDFPageAggregator(resource_manager, laparams=laparams)
interpreter = PDFPageInterpreter(resource_manager, device)
split_pages = []
with open(pdf_path, 'rb') as file:
for page in PDFPage.get_pages(file):
interpreter.process_page(page)
layout = device.get_result()
text_blocks = []
for element in layout:
if isinstance(element, LTTextBoxHorizontal):
text = element.get_text().strip()
text_blocks.append(text)
page_text = '\n'.join(text_blocks)
split_pages.append(page_text)
return split_pages
def callChatGLM6B(prompt):
pass
def summary(pdf_path, num):
# 使用示例
# pdf_path = "/Users/guomiansheng/Desktop/LLM/LangChain-ChatLLM/pdf_test.pdf"
# pdf_path = 'example.pdf' # 替换为你的 PDF 文件路径
one_dict = {}
pages = split_document_by_page(pdf_path)
add_page_data = ''
page_ans = ""
print(f"=============这是第{num}个pdf\n")
for i, page_text in enumerate(pages):
# page_ans = page_ans + f"这是第{i}页pdf:\n" + page_text
page_ans = page_ans + page_text
print(f"Page {i + 1}:", "当前page的字数:", len(page_text))
print(page_text)
print("--------------------")
# 文本分片
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=1500,
chunk_overlap=150,
length_function=len
)
chunks = text_splitter.split_text(page_ans)
# chunks
prompt0 = '''请根据下文进行分段总结, 要求每段内容不丢失主要信息, 每段的字数在50字左右:'''
prompt = '''你是一个摘要生成器。请根据下文进行分段总结,请注意:
1.输入数据为从pdf读入的文本,一句话可能存在跨越多行;
2.要求每段内容不丢失主要信息, 每段的字数在50字左右;
3.每段生成的摘要开头一定不要含有'第几段'的前缀文字;
4.对下文进行分段总结:'''
prompt3 = '''你是一个文章内容整合器,请注意:
1.输入数据中含有多个已经总结好的段落;
2.有的段落开头有这是第几段或者摘要的字样;
2.请将每段信息进行优化,使得每段之间显得更加连贯,且保留每段的大部分信息;
4.输入的的文章如下:'''
ans = ""
for i in range(len(chunks)):
# response = callChatGLM66B(prompt + chunks[i])
response = callChatGLM6B(prompt + chunks[i])
if 'data' not in response.keys():
print(response.keys(), "\n")
print("========this chunk has problem=======\n")
continue
temp_ans = response['data']['choices'][0]['content'] + "\n"
ans += temp_ans
ans = ans.replace("\\n", '\n')
# save txt
# save_path = "/Users/guomiansheng/Desktop/LLM/LangChain-ChatLLM/save_6b_ans3_all"
save_path = "/Users/guomiansheng/Desktop/LLM/LangChain-ChatLLM/gpt_diction"
with open(save_path + '/ans' + str(num) + '.txt', 'w', encoding='utf-8') as file:
file.write(ans)
print("======ans========:\n", ans)
one_dict = {'input': page_ans, "output": ans}
return ans, one_dict
def main():
# find 10 file
def find_files_with_prefix(folder_path, prefix):
matching_files = []
for root, dirs, files in os.walk(folder_path):
for file in files:
if file.startswith(prefix) and file.endswith('.pdf'):
matching_files.append(os.path.join(root, file))
return matching_files
# 示例用法
folder_path = '/Users/guomiansheng/Desktop/LLM/LangChain-ChatLLM/pdf_data_all' # 替换为你的大文件夹路径
# prefixes = ['pdf_0', 'pdf_1', 'pdf_2'] # 替换为你想要匹配的前缀列表
prefixes = []
for i in range(10):
prefixes.append('pdf_' + str(i))
matching_files = []
for prefix in prefixes:
matching_files.extend(find_files_with_prefix(folder_path, prefix))
# del matching_files[0]
# del matching_files[0]
ans_lst = []
for i in range(len(matching_files)):
one_ans, one_dict = summary(matching_files[i], i)
ans_lst.append(one_dict)
# pdf_path = "/Users/guomiansheng/Desktop/LLM/LangChain-ChatLLM/pdf_test.pdf"
# summary(pdf_path)
return ans_lst
def preprocess_data(ans_lst):
json_path = "/Users/guomiansheng/Desktop/LLM/LangChain-ChatLLM/summary_ft_data.json"
with open(json_path, "w", encoding='utf-8') as fout:
for dct in ans_lst:
line = json.dumps(dct, ensure_ascii=False)
fout.write(line)
fout.write("\n")
def read_data():
json_path = "/Users/guomiansheng/Desktop/LLM/LangChain-ChatLLM/summary_ft_data.json"
with open(json_path, "r", encodings='utf-8') as f:
lst = [json.loads(line) for line in f]
df = pd.json_normalize(lst)
if __name__ == '__main__':
ans_lst = main()
preprocess_data(ans_lst)
随便找了个介绍某个课程内容的pdf,结果如下,概括了课程的三天主题内容,同时也将pdf中的数据湖理念等概念进行分点概括:
" 教育即将推出名为“数据湖,大数据的下一场变革!”的超强干货课程。该课程分为三天,
第一天的主题是“数据湖如何助力企业大数据中台架构的升级”,内容包括数据处理流程和大数据平台架构,以及数据湖和数据仓库的理念对比和应用;
第二天的主题是“基于 Apache Hudi 构建企业级数据湖”,将介绍三个开源数据湖技术框架比较,Apache Hudi 的核心概念和功能,以及基于 Hudi 构建企业级数据湖的方法;
第三天的主题是“基于 Apache Iceberg 打造新一代数据湖”,将深入探讨 Apache Iceberg 的核心思想、特性和实现细节,以及如何基于 Iceberg 构建数据湖分析系统。该课程由前凤凰金融大数据部门负责人王端阳主讲,他具有多年的大数据架构经验,擅长 Hadoop、Spark、Storm、Flink 等大数据生态技术,授课特点为拟物化编程 + 强案例支撑,旨在帮助学生快速建立完备的大数据生态知识体系。课程将在今晚 20:00 准时开课。"
"
1.开放性:Lakehouse 使用开放式和标准化的存储格式,提供 API 供各类工具和引擎直接访问数据。
2.数据类型支持:Lakehouse 支持从非结构化数据到结构化数据的多种数据类型。
3.BI 支持:Lakehouse 可直接在源数据上使用 BI 工具。
4.工作负载支持:Lakehouse 支持数据科学、机器学习以及 SQL 和分析等多种工作负载。
5.模式实施和治理:Lakehouse 有 Schema enforcement and governance 功能,未来能更好的管理元数据,schema 管理和治理。
6.事务支持:Lakehouse 支持 ACID 事务,确保了多方并发读写数据时的一致性问题。
7.端到端流:Lakehouse 需要一个增量数据处理框架,例如 Apache Hudi。
8.数据湖和数据仓库对比:数据湖采用读时模式,满足上层业务的高效分析需求,且无成本修改 schema。
9.数据湖落地方案:包括基于 Hadoop 生态的大数据方案,基于云平台数据湖方案,基于商业产品的数据湖方案。
10.数据湖助力数仓解决痛点:数据湖可以解决离线数仓和实时数仓的痛点问题,提高数据处理效率。
11.数据湖帮助企业大数据中台升级:数据湖可以实现底层存储标准统一化,构建实时化标准层,提高数据存储的安全性、全面性和可回溯性。
12.大数据中台实时数据建设要求:开源数据湖架构 Day02 基于 Apache Hudi 构建企业级数据湖。"
三、小结与改进
1. 小结
- 之前存在的问题:生成重复、杜撰了事件中的时间、截断现象、每个chunk文本块之间的摘要不太连贯等
- 优化点:使用pdfminer和Langchain切分chunk文本块,对文本块进行摘要生成,然后将分块的摘要结合prompt2进行内容整合,使得语句连贯并且控制字数;top_p=0.5 temperature=0.8等
2. 后续可继续优化的点
- 使用streamlist提取pdf中的表格对象内容、
- 使用篇章分析discourse parsing更加细粒度地切分文档等
- 文档布局解析最为重要,一般的流程是先用一个版面分析模型来检测出扫描图片中每一块的含义,比如某一块是文本段(text),某一块是公式(Equation)等;然后再利用其他模型去单独识别每一块中的内容。
- 参考:专门可以用来识别数学公式的开源项目:Nougat:
https://facebookresearch.github.io/nougat/
因为数学公式和表格在 markdown 里都可以用纯文本表示,其输入是单页 pdf 转成的图片,输出是这页pdf对应的 markdown(MMD,Mathpix MD)格式的纯文本序列。
- 参考:专门可以用来识别数学公式的开源项目:Nougat:
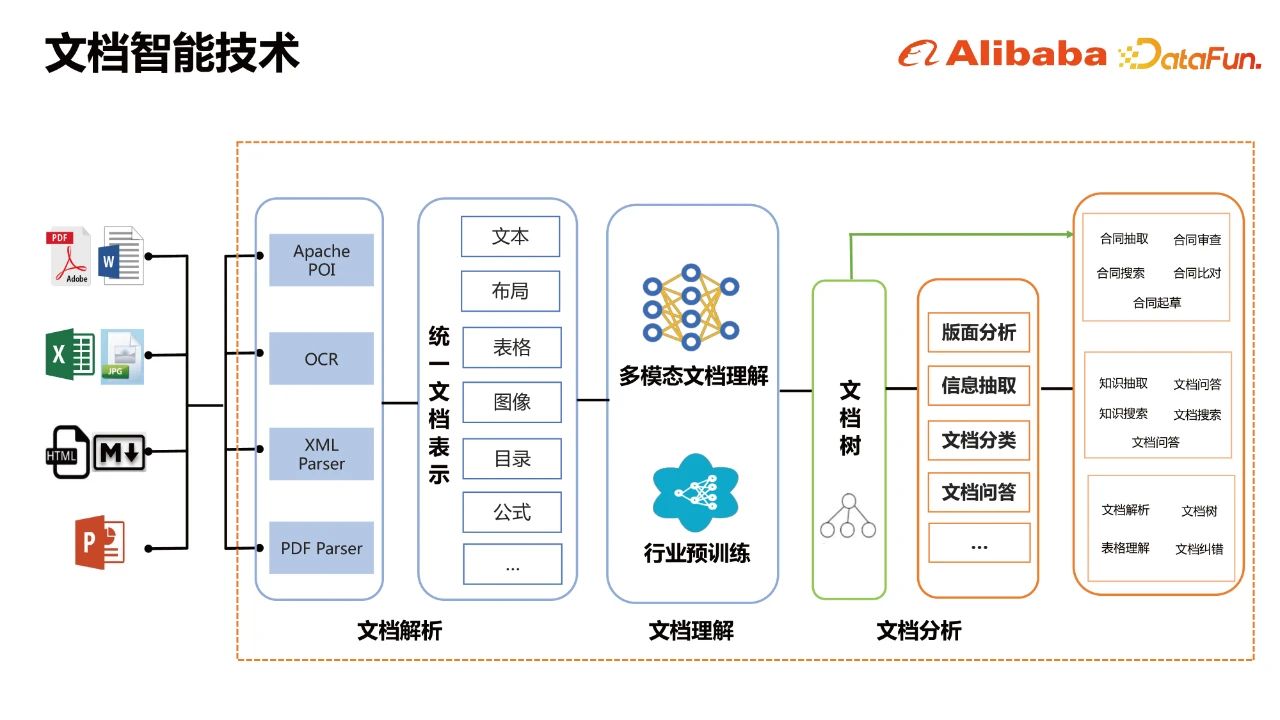
四、智能文档
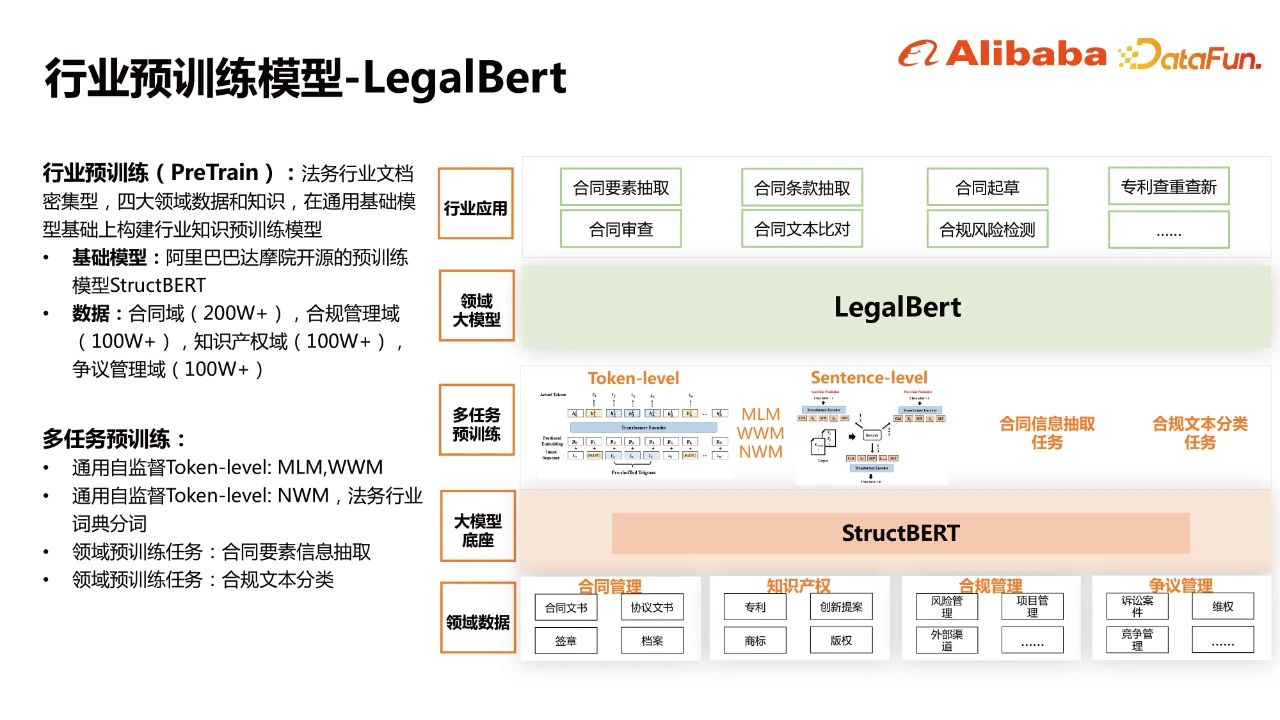
阿里的行业预训练模型legalBert:
- 对于长文档/长文本更友好的Transformer结构——Longformer,提升在长序列方面建模的能力。
- 引入布局信息(Layout),图像信息,是一个逐步迭代的过程。这块的思路还是借鉴了微软2020提出的layoutLM的思路
- 第一版的多模态文档理解预训练模型是基于文本+布局两个模态进行整合编码,模型输入层,包括文本embedding和布局embedding。2-D Position Embedding用于建模文档中的空间相对位置关系,通过对文档使用OCR工具,可以得到每个token的bounding box。预训练阶段有两个目标:Masked Visual-Language Model和Multi-label Document Classification。
Reference
[1] 基于LLM+向量库的文档对话痛点及解决方案
[2] LangChain - 打造自己的GPT(二)simple-chatpdf
[3] 徒手使用LangChain搭建一个ChatGPT PDF知识库
[4] LangChain+ChatGPT三分钟实现基于pdf等文档问答应用
[5] pdfminer: https://euske.github.io/pdfminer/
[6] 兼看知识图谱增强大模型问答的几个方案及CEVAL榜单评测启发
[7] Python+Streamlit在网页中提取PDF中文字、表格对象
[8] 阿里面向企业数字化的文档智能技术与应用.王梦佳 阿里巴巴 高级算法专家
[9] SMP 2023 ChatGLM 金融大模型挑战赛 60 分 Baseline 思路










