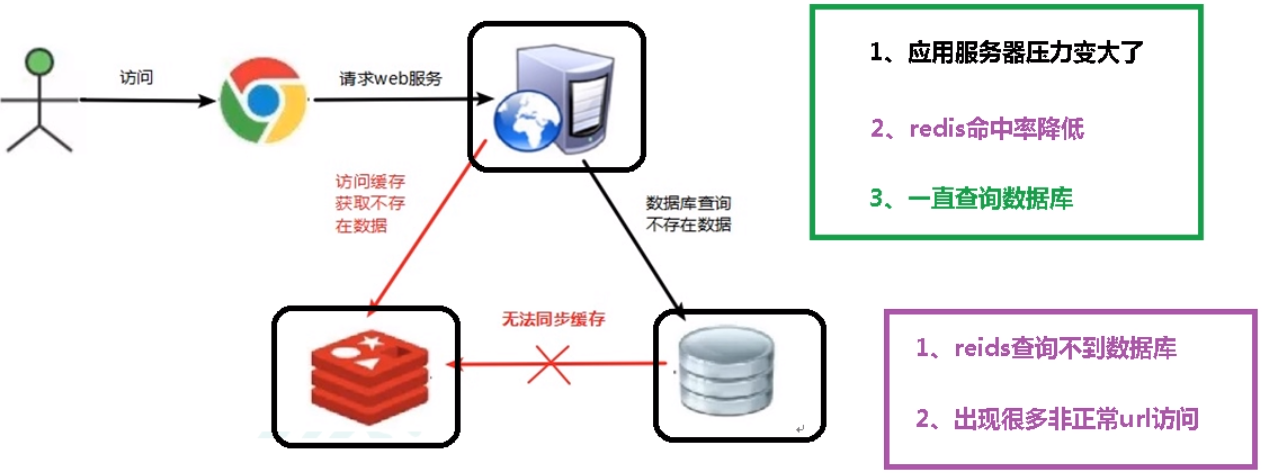
1.缓存穿透
(1)问题描述:缓存穿透是指在高并发场景下,大量的请求访问一个不存在于缓存中也不存在于数据库中的数据,导致每次请求都要查询数据库,增加了数据库的负载。通常发生在恶意攻击、频繁访问不存在的数据或缓存设置不当等情况下。例如查询为 id 为 “-1” 的记录,这时的用户很可能是攻击者,该攻击会导致数据库压力过大。
(2)解决方案:
- 请求校验:有些请求具有一定的规则,因此我们响应这个请求之前可以按照一定的规则进行校验,例如已经明确要查询的课程 id 在某一范围内,那么我们可以对其进行校验。不过该方法具有一定的局限性,例如有些请求的规律不太明显,不太适合进行校验。
- 缓存空值或特殊值:如果一个查询返回的数据为 null(不管是数据是否不存在),我们仍然把这个空结果 (null) 或设置的特殊值进行缓存,但是要注意,如果缓存了空值或特殊值,一定要设置一个短暂的过期时间。
思考:为什么一定要设置一个短暂的过期时间?
回答:例如,我们目前要查询课程 id 为 128 的课程,但该课程目前不存在,因此我们可以将特殊值 <“course:128”, “null”> 存储到 redis 中,如果 <“course:128”, “null”> 这条数据在 redis 中长期存在,并且未来我们增加一门课程 id 为 128 的课,那么在查询这门课时,我们会从缓存中得到 “null” 的结果,但是显然数据库中是存在该课程的数据的。因此为了避免这种缓存数据与数据库数据不一致的情况,我们需要将空值或特殊值设置一个短暂的过期时间。
- 使用布隆过滤器:布隆过滤器是一种数据结构,用于判断一个元素是否可能存在于集合中,可以快速过滤掉不存在的数据。布隆过滤器的特点是,高效地插入和查询,占用空间少;查询结果有不确定性,如果查询结果是存在则元素不一定存在,如果不存在则一定不存在;另外它只能添加元素不能删除元素,因为删除元素会增加误判率。在缓存层中使用布隆过滤器,对每个请求的数据进行判断,如果数据不在布隆过滤器中,则可以直接拒绝访问数据库或后端服务。
有关布隆过滤器的具体知识可以参考:
布隆(Bloom Filter)过滤器——全面讲解,建议收藏
布隆过滤器
- 异常流量监控和限制:通过监控系统中的请求流量,发现异常的高频请求,并对其进行限制或拦截,避免大量的请求直接访问数据库或后端服务。
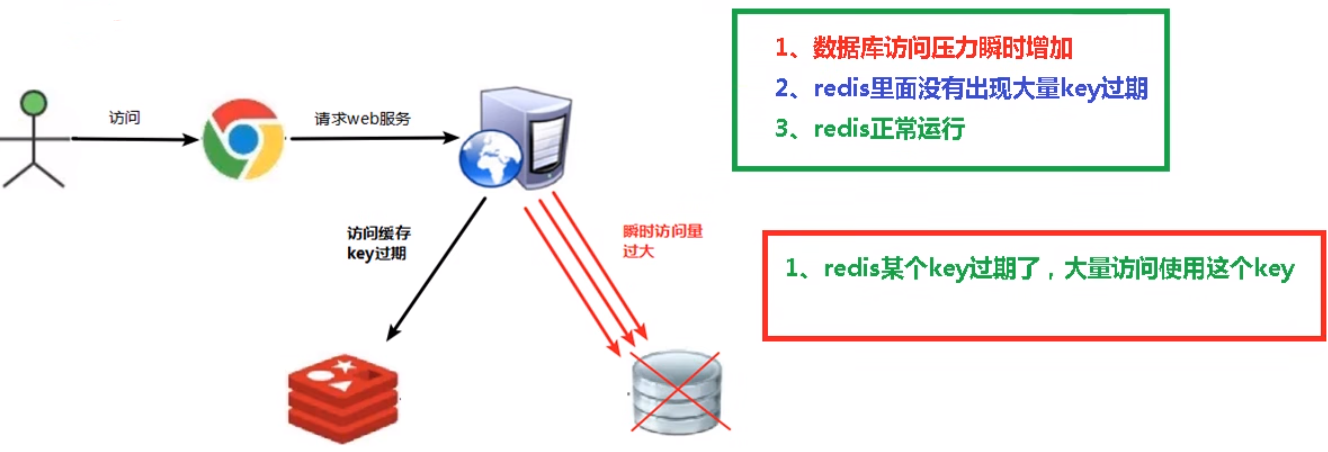
2.缓存击穿
(1)问题描述:缓存击穿是指在高并发的情况下,一个热点数据的缓存过期失效,导致大量的请求直接访问后端服务,对系统造成巨大的压力,甚至导致系统崩溃。
(2)解决方案:
- 使用互斥锁或分布式锁:当缓存过期时,首先尝试获取一个互斥锁或分布式锁,然后再去后端服务中获取数据。其他请求在锁未释放之前,会等待锁的释放,避免了大量请求同时访问后端服务。
- 预加载:在缓存失效前,提前异步加载热点数据到缓存中,确保缓存始终可用。可以使用定时任务或消息队列等方式实现预加载。
- 异步缓存更新:在缓存过期时,不立即从后端服务获取数据更新缓存,而是返回旧的缓存数据,并在后台异步更新缓存。这样可以避免由于大量请求同时获取数据而导致的数据库压力过大。
- 缓存永不过期:对于一些非常重要的热点数据,可以考虑将其缓存设置为永不过期,尽量避免缓存失效的情况。
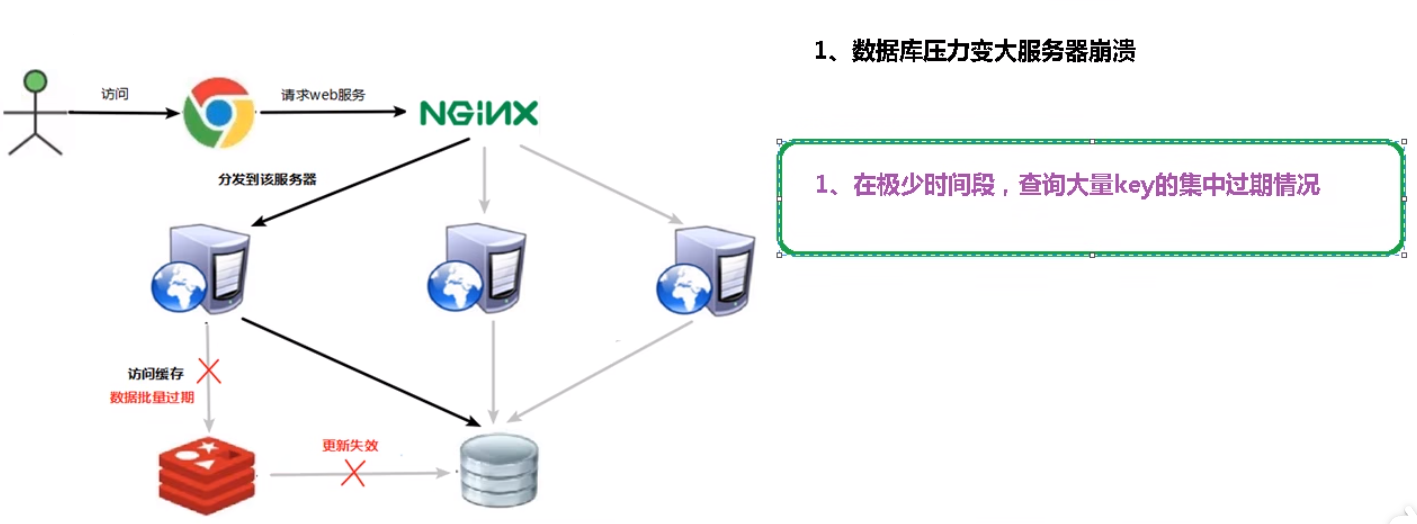
3.缓存雪崩
(1)问题描述:缓存雪崩是指由于缓存中大量的数据同时失效或过期,导致大量请求直接访问后端系统,从而造成后端系统压力过大,甚至系统崩溃的情况。通常发生在缓存中的数据过期时间设置相近或默认过期时间相同的情况下。
(2)解决方案:
- 缓存预热:不用等到请求到来再去查询数据库存入缓存,可以提前将数据存入缓存。使用缓存预热机制通常有专门的后台程序去将数据库的数据同步到缓存。
- 设置随机的缓存过期时间:将缓存失效时间设置为一个随机值,避免大量数据同时过期。可以在原有的过期时间基础上增加一个随机的时间偏移量,使得过期时间分布在一个范围内。
- 限流降级:在缓存失效的情况下,为了保护后端服务的稳定性,可以对请求进行限流或降级处理,例如通过队列或限流算法来控制请求的并发量,保证系统不被大量请求拖垮。
- 多级缓存机制:引入多级缓存,例如本地缓存和分布式缓存,提高系统的可靠性。当一级缓存失效时,可以尝试从二级缓存中获取数据,避免直接访问数据库或后端服务。
- 服务高可用:构建高可用的系统架构,通过横向扩展和负载均衡等方式,降低单个缓存节点失效对整个系统的影响
4.总结
(1)缓存击穿、缓存穿透和缓存雪崩是缓存相关的三个不同问题,它们的原因和影响有所不同:
- 缓存穿透:缓存穿透是指请求的数据在缓存中不存在,导致每次请求都直接访问数据库或后端服务,对系统造成压力。通常是由恶意请求或者频繁请求不存在的数据引起的,比如查询一个不存在的 ID 或者某种类型的非法输入。缓存穿透会带来大量无效的请求和对后端服务的直接访问。
- 缓存击穿:缓存击穿是指在高并发的情况下,一个热点数据的缓存过期失效,导致大量的请求直接访问后端服务,对系统造成压力。通常是因为某个特定的热点数据失效,而其他数据的缓存仍然有效。缓存击穿一般是由于并发请求集中在某个特定的数据上,当该数据的缓存过期时,大量请求直接访问后端服务。
- 缓存雪崩:缓存雪崩是指大量缓存同时失效或过期,导致大量的请求直接访问后端服务,对系统造成巨大的压力。一般是由于缓存系统的故障、过期时间设置不当、或者其他原因导致多个缓存同时失效。缓存雪崩会导致大量请求同时涌入后端服务,造成系统负载过高甚至崩溃。
(2)总结来说,缓存击穿是因为某个热点数据的缓存失效导致并发请求直接访问后端服务,缓存穿透是因为请求的数据在缓存中不存在导致直接访问后端服务,缓存雪崩是由于多个缓存同一时间失效导致大量请求直接访问后端服务。针对这些问题,可以采取不同的解决方案来提高系统的性能和可用性。








